AISC team report: Soft-optimization, Bayes and Goodhart
post by Simon Fischer (SimonF), benjaminko (benjamink), jazcarretao, DFNaiff (danilo-naiff), Jeremy Gillen (jeremy-gillen) · 2023-06-27T06:05:35.494Z · LW · GW · 2 commentsContents
The Bayesian view on Goodhart's law Setup and notation Goodhart's law How Bayes could beat Goodhart Why Bayes can't beat Goodhart What if the agent can access the ideal belief distribution? The scenario Example: Generalized normal distributions Example: Normally distributed error term with randomly drawn standard deviations Example: Laplace-distributed error term with randomly drawn scale parameters Example: Goodhart's rollercoaster What if the agent can't access the ideal belief distribution? The naive algorithm and a second-level Goodhart's law A simulated toy example with difference between ideal and estimated belief distribution Conclusion Other Results Stochastic gradient descent as a soft optimizer High probability soft optimizer alternative formulation and proof None 2 comments
This is a report on our work in AISC Virtual 2023.
For AISC 2023, our team looked into the foundations of soft optimization. Our goal at the beginning was to investigate variations of the original quantilizer algorithm, in particular by following intuitions that uncertainty about goals can motivate soft optimization. We ended up spending most of the time discussing the foundations and philosophy of agents, and exploring toy examples of Goodhart’s curse.
Our discussions centered on the form of knowledge about the utility function that an agent must have, such that expected utility maximization isn’t the correct procedure (from the designer's perspective). With well-calibrated beliefs about the true utility function, it’s always optimal to do Expected Utility maximization. However, there are situations where an agent is very sensitive to prior specification, and getting this wrong can have a large impact on the true utility achieved by the agent. Several other unrelated threads were pursued, such as an algorithm with high probability of above-threshold utility, and the relationship between SGD and soft optimization.
The Bayesian view on Goodhart's law
Goodhart's Law states that when maximizing an approximation of a true utility function, which we call proxy utility function, this leads to outcomes that are much less valuable than predicted by the proxy utility function. There is a Bayesian perspective from which it doesn't look like Goodhart's law will be a problem at all, namely if the agent has correct beliefs about the quality of the approximation. An ideal rational agent would represent the information they have about the world with a probability distribution that they arrived at by Bayesian reasoning. We assume that they represent their goals as a utility function over world states or as a belief distribution over such utility functions. Thus, they select actions by maximizing the expected utility over goals and world models.
If the agent was able to perfectly capture all available information about goals into an "ideal"[1] belief distribution, maximizing the utility in expectation over this distribution would be optimal.[2] It would avoid Goodhart’s law as much as possible given the agent's knowledge by anticipating any overestimation of the true utility function by the proxy utility function. In this section, we try to formalize this intuition. Sadly, Bayesian reasoning is intractable in practice, both because specifying the prior is difficult and because updating the distribution is computationally hard. This framing is explained in more detail in Does Bayes Beat Goodhart?. [LW · GW][3]
Beliefs about values are difficult to deal with, because you may not have a reliable way to update these beliefs after deployment. In this situation the agent's behavior is heavily dependent on the way we specify the priors.
Setup and notation
We generally consider situations where an agent can choose a single action from some space . For that choice, we are interested in knowledge about the (true) utility function , that we want the agent to maximize. The situation might include observed variables and hidden variables . The agent models each of them respectively by random variables , and . We denote the ideal prior belief distribution, without prior misspecification or compute limitation, by . We denote the belief distribution that the agent estimated by .[4] Hidden variables are used in some of our toy examples to provide better intuition about the problem. The observed variables could for example be a dataset such as that containing human preferences used to train the reward model in RLHF. But in this post the observed variable is always a proxy utility function . We write for the "error" random variable that indicates the error between the proxy utility and true utility functions.
Goodhart's law
Goodhart’s law can be formalized in different ways; here we focus on “regressional Goodhart”. We will model the situation where the difference between the true and proxy utilities for a given action is given by an error term :
We will now assume that the proxy utility function is an unbiased estimator of the true utility function, i.e. , or equivalently that the error function is the zero function in expectation, i.e. .
In expectation over and evaluated at any action , this yields
.
However, this equality is not true if the fixed action is replaced with the action that optimizes , that is . Note here that is itself now a random variable.
Now, we find that
and the inequality is strict under mild assumptions[5], e.g. in all of our toy examples. Intuitively, selects for positive error so that is positive in expectation.
So, the expected value of the action selected by proxy maximization is lower than the proxy prediction , even though we assumed that U was an unbiased estimator. This is one way of stating the regressional variant of Goodhart's law.
How Bayes could beat Goodhart
From a Bayesian perspective, the situation after observing the proxy utility function is best described by the conditional distribution . We will therefore look at the conditional expected true utility and write it as .
The Bayes-optimal action for belief is . While maximizes the proxy utility , maximizes the conditional expected true utility .
Just as is the case for , this maximization objective also has the same expectation over , as the true utility function . We can see this for any action as follows:
But, in contrast to , this equation also holds for the optimal action :
Intuitively, this is due to the fact that the distribution used in the Bayesian maximization objective, which we used as approximation of , is the same as the distribution from which is indeed sampled (at least according to the agent's best knowledge).
In this sense, "Bayes beats Goodhart". The Bayesian maximization objective does not have the problem that by maximizing it, it ceases to be a good approximation of the true utility function . As a consequence, the Bayesian maximization objective also doesn't suffer from Goodhart's law.
As a consequence of stochasticity in the belief distribution , the selected action might still turn out to perform poorly according to V, but it was the best the agent could have selected with its knowledge.
Why Bayes can't beat Goodhart
However, we think that in practice an agent would not be able to access the ideal belief distribution . This is firstly because specifying priors is notoriously difficult, and because optimal actions usually require pushing away from regions of action-space where we (the designers) have a lot of data about the true value, so an agent is always heavily reliant on prior information about the reliability of the proxy. And secondly, computational limitations might mean that the distribution can't be computed exactly.
See Abram Demski’s post, Does Bayes Beat Goodhart? [LW · GW], for a more detailed discussion. We found that this topic was difficult to think about, and very philosophical.
Our best guess is that the prior has to capture all the meta-knowledge that is known to the designer, for instance about boundaries in action-space or outcome-space where there is a possibility of breaking the relationship between your proxy value and true value. One extreme example of such knowledge is deontological rules like "don't kill people". We are confused about exactly what are the desiderata for such a "correct" prior specification.
We explored examples related to this below, but don't feel like we have resolved our confusion completely yet. In the next sections we look at different types of concrete examples both with and without "objectively correct" beliefs.
What if the agent can access the ideal belief distribution?
In this section, we consider the scenario of an agent that is able to represent its beliefs about the true values and the errors of the proxy variable with an ideal belief distribution. We worked through several examples, some more general and some more specific, to get a better intuition about when and why regressional Goodhart can cause the most damage, and how the Bayesian approach fares.
The recent post When is Goodhart catastrophic? [LW · GW] by Drake Thomas and Thomas Kwa contains an in-depth analysis of a similar scenario with emphasis on how errors are distributed in heavy-tailed vs light-tailed distributions.
The scenario
For various actions, we observe the proxy values . Our goal is to use this information to choose the action with the highest expected value of . We will now assume that we know the prior distribution of the true values and the distribution of the error term, and that they are independent for each action.
By Bayes’ theorem, we can calculate then the distribution of given an observed value , using :
Given this distribution, it is now possible to calculate the expected value and use this value to compare policies instead of the naive method of optimizing the proxy . In other words, the rational choice of the action is
Example: Generalized normal distributions
Here, we assume that both the true values as well as the error term are distributed according to the generalized normal distribution with standard deviation . The shape parameter of these distribution determines their "tailedness"; distributions with a smaller shape parameter have a heavier tail. We vary the shape parameters of both the error and the true value distribution and calculate the expected true value conditional on the proxy value, , using numerical integration. The plots show the expected conditional values as a function of as well as the identity function for comparison as a dashed line.
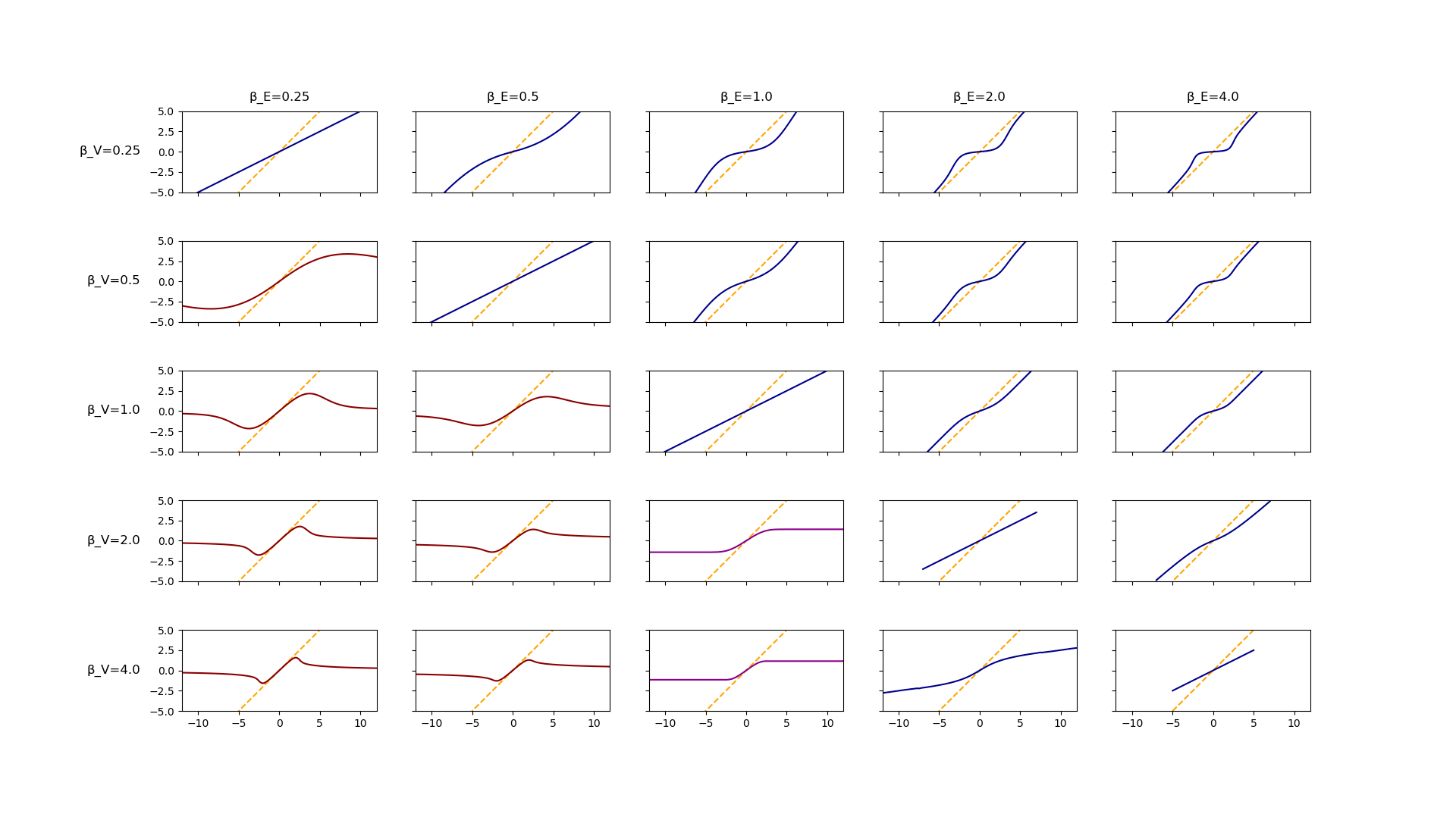
Only in the case where and do we observe that the expected value graph does not go to infinity for large values of the proxy value. That is, only in these cases to we observe Goodhart's curse. This seems to be in agreement with the result proven in Catastrophic Regressional Goodhart: Appendix [LW · GW].
Example: Normally distributed error term with randomly drawn standard deviations
We wanted a concrete example where the error distribution had a free parameter that controls the variance, which we can think of as being upon observing the proxy value, which intuitively should create a situation where maximizing the proxy reduces the correlation. In this example, we assume the error is normally distributed with mean 0, but for each action the standard deviation itself is randomly drawn from an exponential distribution with rate parameter . For concreteness, the error values can be sampled using the following Python code:
def create_error_vector(n):
std_dev = np.random.exponential(0.3, size=n)
return np.random.normal(0, std_dev, size=n)The resulting distribution of the error term can be calculated as
We will now look at two cases for the distribution of the true values.
In the first case, we assume that the prior values are uniformly distributed in the interval [-0.5, 0.5]. Here, the graph of the expected true values look like this:
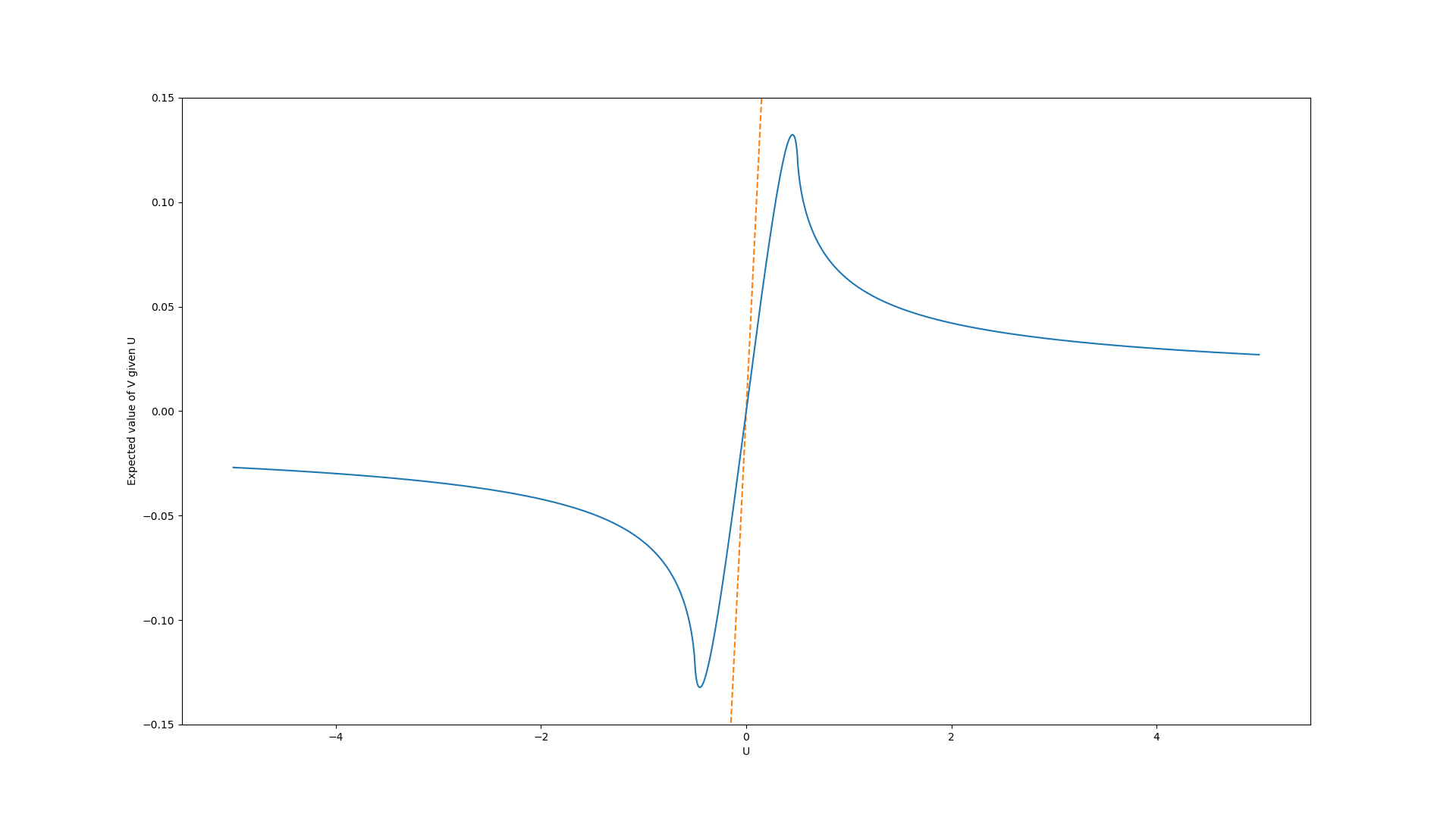
In the second case, we assume a standard Gaussian distribution (i.e. with mean and standard deviation ). The graph of the expected true values looks very similar:
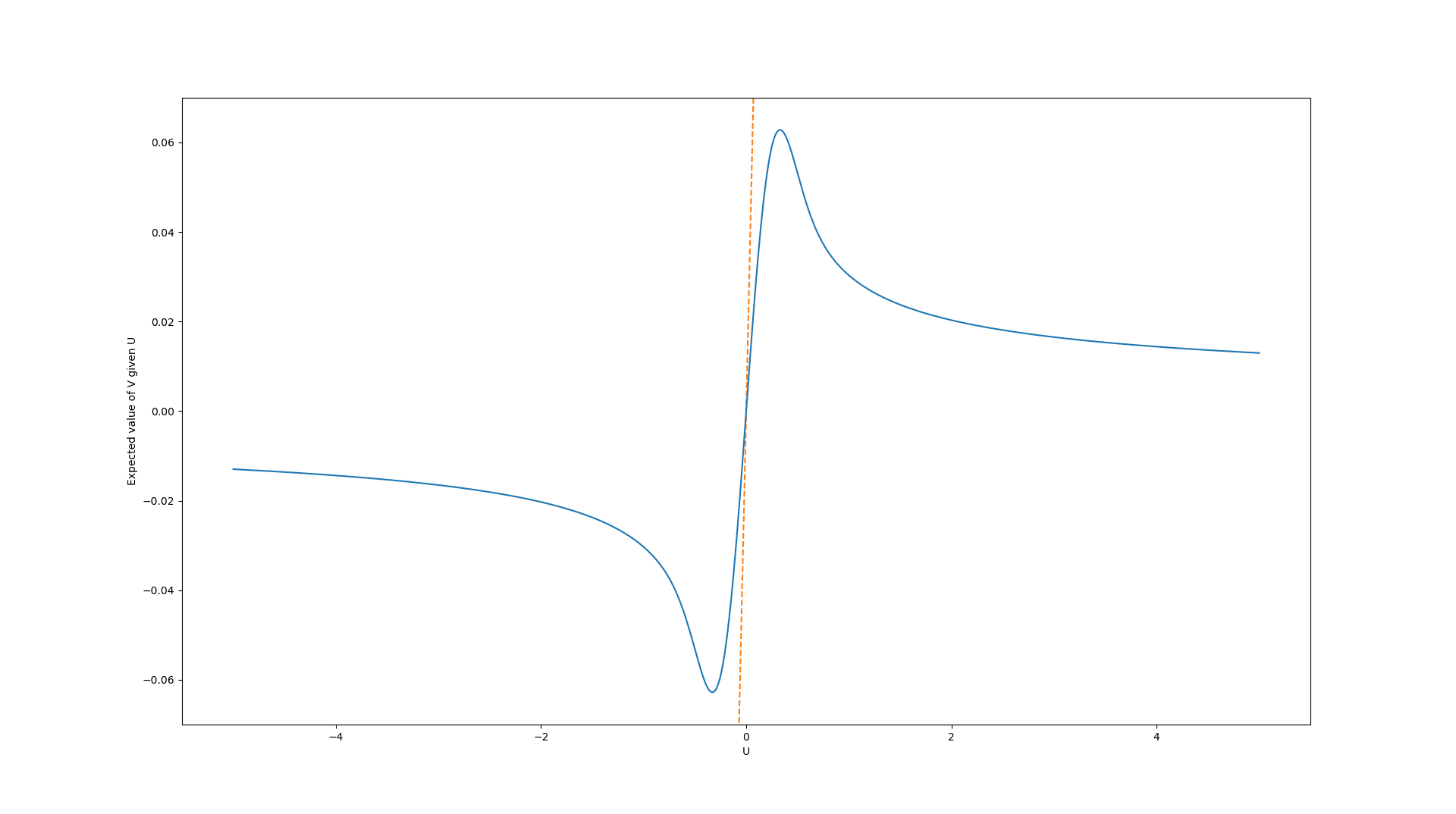
In both cases, it is clearly not optimal to choose the policies with the largest proxy values. Instead, values quite close to have much higher expected value and the expected value decays towards (the mean of the prior distribution) for very high values.
Example: Laplace-distributed error term with randomly drawn scale parameters
In this example, we assume the error is Laplace-distributed with mean and scale parameter , but the error is “stretched” by multiplying it with a random value from an exponential distribution (with rate parameter ) taken to the power of . This was done in an attempt to make the Goodhart effect much stronger. In other words, the error values can be sampled using the following Python code:
def create_error_vector(n):
scale_factor = np.random.exponential(1, size=n) ** 6
return np.random.laplace(0, 0.9 * scale_factor, size=n)The resulting distribution can be calculated similarly to the previous example.[6]
We again calculated the resulting graph of the expected true values for the case of a uniform and a Gaussian distribution of the error term (both with the same parameters as before).
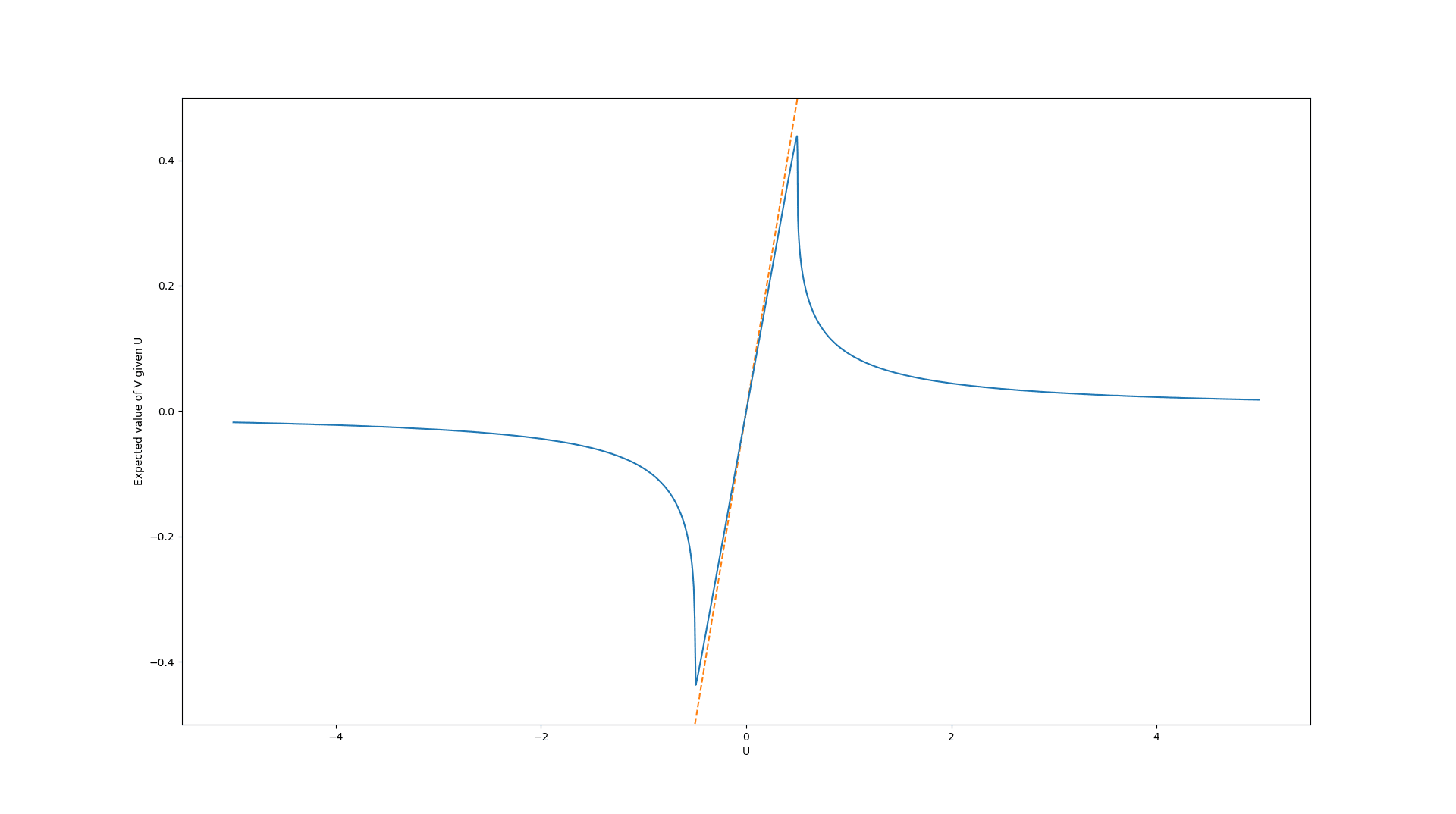
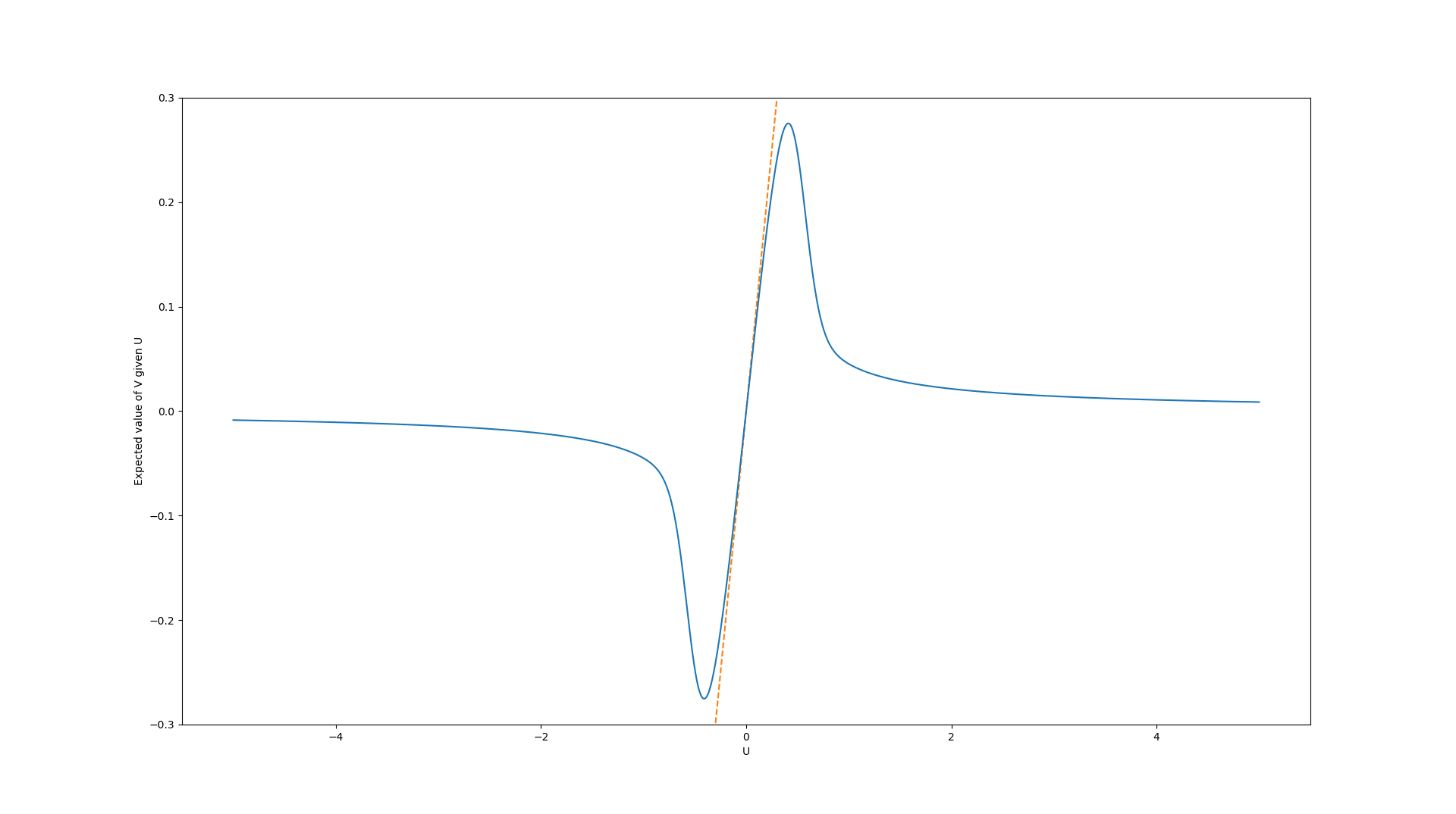
Example: Goodhart's rollercoaster
A fun phenomenon occurs when the distribution of the error term has multiple modes. Here we combined three heavy-tailed distributions and generated the error values using the code:
def create_error_vector(n):
locations = np.random.choice([-1, 0, 1], size = n)
return scipy.stats.gennorm.rvs(beta = 0.25, scale = 0.0001, loc = locations)Combined with uniformly-distributed true values, this results in an expected true value graph like this:
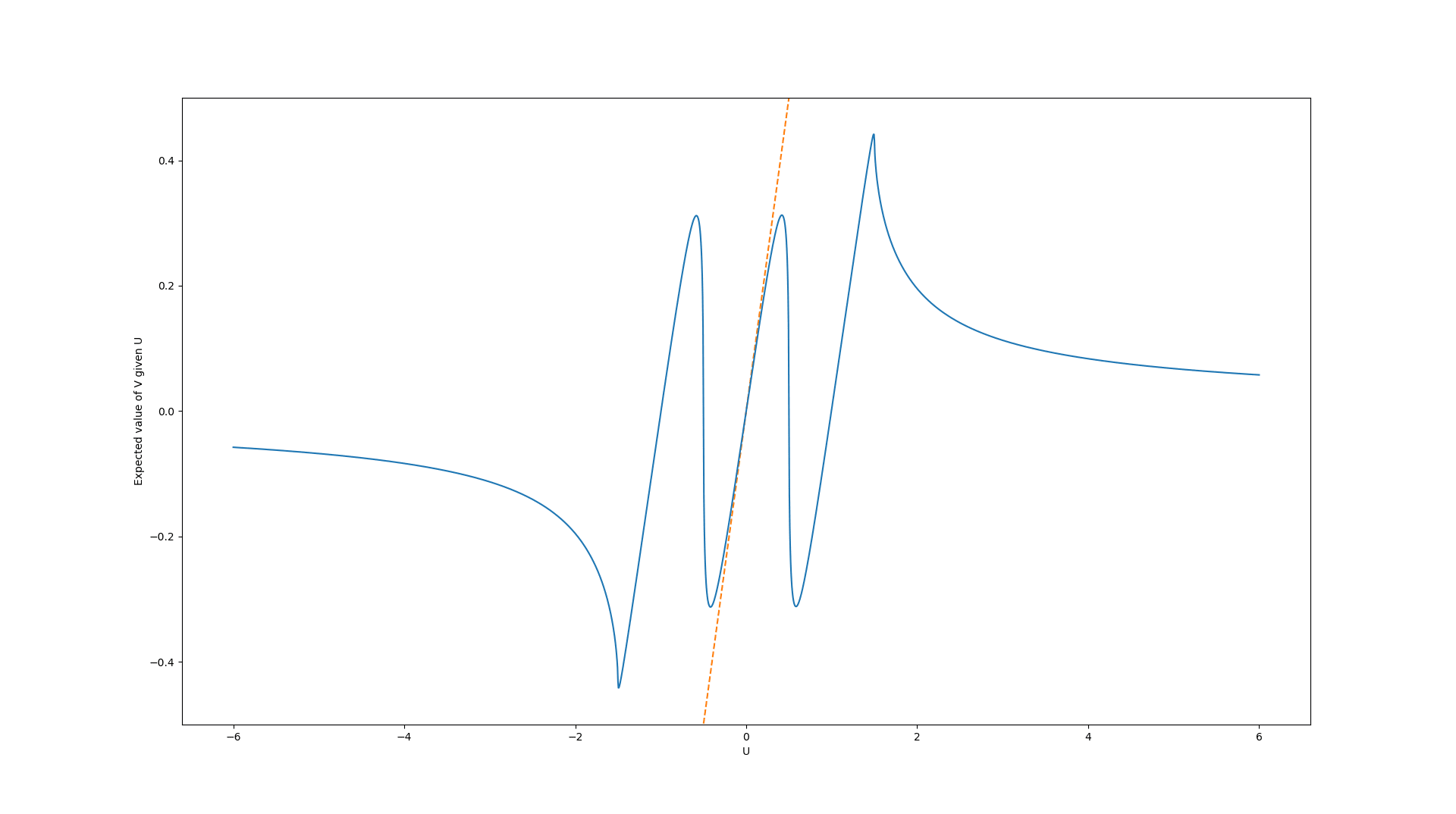
This illustrates that if there are different sources of errors, each with different mean, regressional Goodhart can occur not only in the extreme values, but also in intermediate values in the domain of the proxy function.
What if the agent can't access the ideal belief distribution?
As discussed, we think that action selection by EU maximization with ideal belief, , is the best thing to do if feasible, but is infeasible in realistic situations, due to the unavailability of . This raises the question what action selection procedure (algorithm) to employ instead. We search for algorithms with performance (as potentially evaluated by the true value functions for a set of representative situations) as close to the optimal performance reached by EU maximization with ideal belief as possible. In other words: We search for good approximations of action selection by EU maximization with ideal belief.
The naive algorithm and a second-level Goodhart's law
A salient candidate for the approximation of action selection by EU maximization with ideal belief is what we call the naive algorithm or naive EU maximization: Action selection by EU maximization with an approximate/estimated belief :
Curiously, and as observed in Does Bayes Beat Goodhart? [LW · GW], this brings us back into a familiar situation: We found that, in order to optimize when just knowing , the correct objective to maximize is . However, we noticed that the agent can't typically access this objective and proposed it might maximize instead. Just as in the original situation involving and , the agent ends up maximizing a proxy of the true objective. This is the recipe for Goodhart's law. Regardless, we hope that Bayesian reasoning would still reduce the extent of Goodhart's law in the sense that a solution that avoids it needs to "bridge less of a gap".
With , this situation arises in the context of trying to beat Goodhart's law by Bayesian reasoning, so in some sense on a second level. We could of course attempt to also capture this situation by Bayesian modelling of a meta distribution over and , but that would just give us a third level Goodhart's law. Generally, for any meta level of Bayesian reasoning, there is Goodhart's law one level above. While we hope the Bayesian reasoning on the first level alleviates Goodhart's law to some degree, our intuition is that further levels of Bayesian reasoning are not helpful. An attempt at an argument for this intuition is that already captures all the agent's prior knowledge and already approximates to the agent's best ability. So, if, by replacing with an expected value of over the (approximate, not ideal) meta distribution, the agent captures it's knowledge better, then it must have done a poor job with computing .
In the next section, we will describe a toy example that we will use to test the robustness of the naive approach to Goodhart's law.
A simulated toy example with difference between ideal and estimated belief distribution
In this example we will analyze how an agent can utilize the true belief distribution to choose actions to avoid Goodhart's law, and whether we need this.
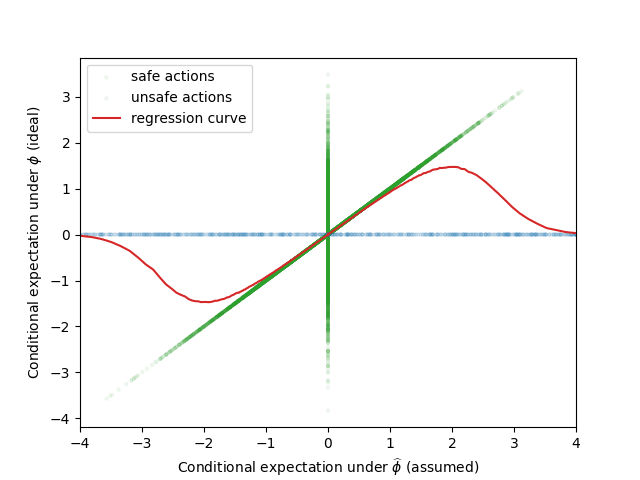
If we knew the true belief distribution we could label actions as safe or unsafe depending on how correlated V and U are according to . In the figure below we show the extreme example where the true value of “safe actions” are distributed with low variance around the true value mean, while unsafe actions are distributed with high-variance around the true value mean. This is illustrated in the figure below.
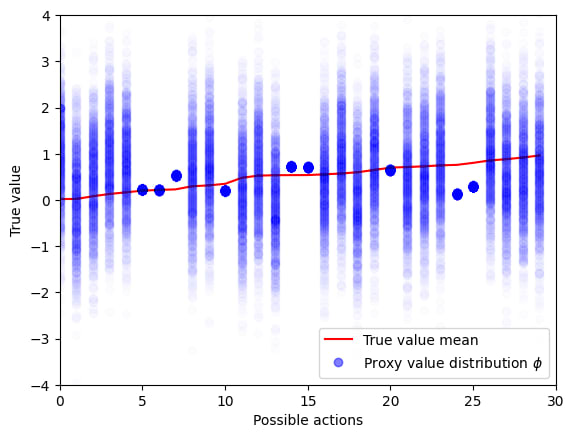
The red curve is a “regression curve” which represents the expected conditional true utility for each proxy utility. This expectation is calculated locally across bins of the proxy utility for visualization purposes.
We can observe that unsafe actions can have two unintended consequences. First, obviously the proxy utilities of unsafe actions are useless as they do not correlate significantly with true utilities. However, the second consequence is that unsafe actions can introduce extremal Goodhart, as the expected true utility (regression curve) decreases for extremal values of the proxy utility.
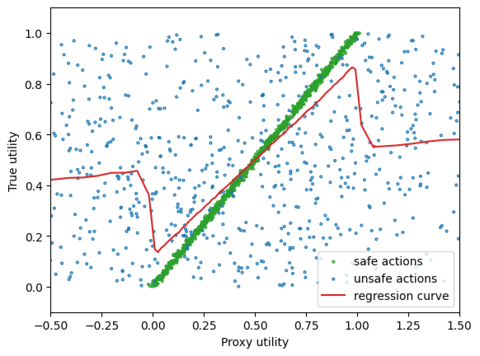
By knowing , we can avoid taking actions for which proxy utilities do not correlate with true utility. Since we do not have knowledge about , we must rely on an estimated belief distribution .
If we assume is distributed in the same way as , we can observe that, while and correlate for safe actions, there is still a Goodhart effect due to the unsafe actions. This example illustrate that approximating by a prior belief can still introduce Goodhart. This observations made us consider the usage of soft-optimizers to deal with imperfect information about the prior beliefs.
Conclusion
We investigated concrete examples to build intuitions about Goodhart's law and found a Bayesian perspective to be helpful for that. We concluded that Goodhart's law can indeed be beaten by Bayesian reasoning, but that belief misspecification can reintroduce Goodhart's law. As future work, we are still working on empirical evaluations of soft optimization as an alternative to naive Bayesian expected utility maximization.
Other Results
Stochastic gradient descent as a soft optimizer
Although soft optimizers seem somewhat artificial at first, in fact, a very common soft optimizer is the simplest of optimizers, the standard stochastic gradient descent with a constant time step. The reason for that is exactly because stochastic gradient descent is stochastic, so we can think of it as a sequence of random variables, such that it converges to a stationary distribution around the minimum.
To make this more clear, consider a loss function , with being a random loss function whose distribution depends on the data. Then, assume we are doing SGD with a step size , starting from some . Letting be i.i.d. minibatch samples of , then the SGD update forms a Markov chain defined as
The following is a standard result, which we briefly recap here. We can analyze better this chain by considering
- The CLT approximation , where be the covariance matrix of , and .
- That is small enough so that we can consider the stochastic differential limit , with denoting the Wiener process.
- That, around the minimum (and under a suitable change of variables) the quadratic approximation , with being the Hessian at the minimum, is valid.
- Finally, around the minimum, is a constant.
Then our SDE limit becomes , which we recognize as an OU process, whose stationary distribution is distributed according to , where is the solution of the equation . We can solve this equation for by letting be the eigendecomposition of , defining , and letting[7]
We then conclude that SGD with a constant time step is a soft optimizer that, at convergence, approximately follows a Gaussian distribution whose covariance is proportional to the step size and to the innate covariance of , and inversely proportional to and the eigenvalues of .
An interesting phenomenon arising in high-dimensional probability is that, under usual conditions, the distribution gets highly concentrated in a shell around the mode, called the typical set. In the case of the distribution , we can find this typical set by noticing that, if , then , so we find that , with being the chi-squared distribution with degrees of freedom, and the dimension of the parameter space. Therefore, we find that and, using Markov inequality, , so the typical set becomes the ellipsoid , and the relative distance to that set is inversely proportional to .[8] This implies that, in very high dimensions, not only is constant step SGD soft optimizing the minima, but it in fact rarely gets very near the minima, and just hovers around the typical set.
Of course, SGD with a constant time step is rarely used in real situations, and instead, we use adaptations such as Adam with a schedule for varying the time step. Although the analysis in these cases is somewhat harder, we can conjecture that the general idea still holds, and we still have the same proportionality results. If true, this shows that, when thinking about soft optimizers, we should always remember that soft optimizers are "out there", already being used all the time.
High probability soft optimizer alternative formulation and proof
Another soft optimizer, that explicitly tries to be a soft optimizer (unlike constant step SGD) is the quantilizer, as proposed by Jessica Taylor. Here, we give an alternative formulation for the quantilizer, one that we believe is more intuitive and slightly more general. To maintain continuity with the previous section, we use a minimization framing, consistent with the SGD discussion, and contrasting to the maximization framing used in the original paper.
Let be a function[9] to be soft minimized on the state space . We can, for any , consider the sublevel-set given by . Now, assume a prior probability measure on . With it, we can define a function given by . This function has the following properties:
- For , , therefore is non-decreasing.
- , and .
Therefore, we can define a function , working as a "generalized inverse" of ( if is invertible), by defining . With it, we can define the -quantilizer set by letting and . Of course, this defines a quantilizer function defined as . Moreover, we can define the quantilizer distribution function by restricting to , such that .
How is this a reformulation? In the original work, the desiderata used is "choosing an action from the set ". In our language (under suitable change to a minimization framing), this is exactly one of the subset levels, and the reordering of the action set and choosing a random variable from is exactly sampling one of the -best actions based on the prior , that is, sampling one of . We find this explicit reordering of the action space is both awkward, lacking geometric intuition, and hard to generalize to continuous spaces. Instead, we argue that the above reformulation is more intuitive while having the same properties as the original formulation.
We can gain some geometric intuition on quantilizers in , by assuming again, that around the minima, we have Then, our quantilizer sets become (approximately) the ellipsoids . For large , we again have concentration phenomena in quantilizers. In fact, letting be the -dimensional volume of , we find that, for some , that . So, if is approximately uniform around the minima, then for large , and small , almost all of the measure of is concentrated around the set . In this case, we conclude that the quantilizer becomes an almost exact quantilizer sampling from the exact -best values of . Of course, unlike in the case of SGD, is not clear that the action set in the original framing should be modeled as a subset of with all its geometric structure, so whether this result is relevant depends on what is being modeled.
- ^
By "ideal" we mean that the agent has arrived at the distribution by Bayesian updates from a well-specified prior, and it includes all the explicit and implicit knowledge available to the agent. From the subjective perspective of the agent, the variables appear (according to some notion that is not very clear to us) to be sampled from this distribution. In the simplest case, the world literally samples from this distribution, e.g. by rolling a die, and the agent has knowledge about the probabilities involved in that sampling process. We are still philosophically confused about what exactly characterizes this ideal distribution and whether there is really only one such distribution in any situation.
- ^
With respect to the true value function, which is the value function the designer intends for the agent.
- ^
“One possible bayes-beats-goodhart argument is: "Once we quantify our uncertainty with a probability distribution over possible utility functions, the best we can possibly do is to choose whatever maximizes expected value. Anything else is decision-theoretically sub-optimal." Do you think that the true utility function is really sampled from the given distribution, in some objective sense? And the probability distribution also quantifies all the things which can count as evidence? If so, fine. Alternatively, do you think the probability distribution really codifies your precise subjective uncertainty? Ok, sure, that would also justify the argument.”
- ^
Note that we regard and as denoting probability measures, joint, conditional and marginal distributions, probability density functions or probability mass functions as convenient.
- ^
To show this, we first show and then take the expectation over . Define . With that, we have .
The strict version of this inequality clearly holds if or .
- ^
The exponential distribution has pdf (for ):
When values drawn from this distribution are transformed by , the pdf of the transformed variable is given by:
Our noise function is Laplace-distributed with location parameter and scale parameter and therefore has the pdf (given )
Therefore, if we integrate out , we have
where the last substitution is useful to simplify numerical integration.
- ^
This can be shown that the general equation , for positive-definite, can be solved using the eigendecomposition , and letting
- ^
Much sharper exponential bounds can be derived, see here.
- ^
We assume everything to be well-behaved enough (measurable functions and measurable sets) so we don't need to do measure theory here.
2 comments
Comments sorted by top scores.
comment by beren · 2024-03-08T15:00:53.756Z · LW(p) · GW(p)
I like this post very much and in general I think research like this is on the correct lines towards solving potential problems with Goodheart's law -- in general Bayesian reasoning and getting some representation of the agent's uncertainty (including uncertainty over our values!) seems very important and naturally ameliorates a lot of potential problems. The correctness and realizability of the prior are very general problems with Bayesianism but often do not thwart its usefulness in practice although they allow people to come up with various convoluted counterexamples of failure. The key is to have sufficiently conservative priors such that you can (ideally) prove bounds about the maximum degree of goodhearting that can occur under realistic circumstances and then translate these into algorithms which are computationally efficient enough to be usable in practice. People have already done a fair bit of work on this in RL in terms of 'cautious' RL which tries to take into account uncertainty in the world model to avoid accidentally falling into traps in the environment.
Replies from: mateusz-baginski↑ comment by Mateusz Bagiński (mateusz-baginski) · 2024-03-11T09:08:46.374Z · LW(p) · GW(p)
People have already done a fair bit of work on this in RL in terms of 'cautious' RL which tries to take into account uncertainty in the world model to avoid accidentally falling into traps in the environment.
I would appreciate some pointers to resources