A quick experiment on LMs’ inductive biases in performing search
post by Alex Mallen (alex-mallen) · 2024-04-14T03:41:08.671Z · LW · GW · 2 commentsContents
Three different ways to compute an argmax The Task Results What does this tell us about inductive biases of various internal behaviors? Appendix Prompts for the “compute-value” baselines: None 2 comments
TL;DR: Based on a toy setting, GPT-3.5-turbo and GPT-4-turbo are best at search (by which I mean computing an argmax) when using chain-of-thought, but neither of them can do internal search when forced to work from memory over only a few token positions. Only GPT-4-turbo is to some extent able to do internal search, and only when given instructions before being shown the list of candidates it is tasked with argmaxing over.
Thanks to Jiahai Feng, Eli Lifland, and Fabien Roger for feedback and discussions that led to this experiment. This experiment was run and the post was written in a day, so some things may be rough around the edges.
One worry is that future AI systems might perform consequentialist reasoning internally (in “neuralese”), which may not be understandable to humans or other (trusted) AIs. We might not know if it is picking an action because it rates best according to what its operator would want, because it’s instrumentally useful for another goal [LW · GW], because it would lead to the best-looking tampered measurement [LW · GW], or because of some process other than search.
Three different ways to compute an argmax
This is a small toy experiment that tries to measure inductive biases of transformers regarding some of these capabilities. I attempt to measure to what extent RLHF’d LMs are capable of performing search in different settings. I consider only simple, brute-force, non-tree search here, because current LMs are not very capable at search. Given some collection of candidates, the kind of search we are interested in involves:
- Computing a value for each candidate
- Selecting an argmax
While it is hard to test whether a model is doing this via interpretability, we can devise behavioral experiments whose results can inform us about what the model is doing internally. I consider three settings:
- Externalized search/chain-of-thought
- Internal search in which value computation can be done at the token position(s) of the corresponding candidate
- Internal search which must be done “from memory” over a small number of token positions
The Task
A. (2, [3, 2, 1])
B. (0, [2, 1, 3])
C. (1, [2, 3, 1])Given a list of `(idx, digits)` pairs like the above, the model is tasked with picking out which one has the highest value of `digits[idx]`. There is never a tie, and `digits` is always a shuffled list with the same length as the number of pairs.
I implement the three settings described above as follows:
1. Externalized search: I prompt the model to explain before answering in a specific format.
A. (1, [3, 2, 1])
B. (2, [3, 2, 1])
C. (2, [2, 1, 3])
Given the list of `(idx, digits)` pairs, tell me for which pair is the `idx`th digit of `digits` largest (indexing from 0). Explain and conclude your answer with "Answer: " and the letter.2. Internal search distributed over token positions: I give the model instructions, and then provide the list of pairs, and request it to answer only with one letter.
Given the list of `(idx, digits)` pairs, tell me for which pair is `digits[idx]` largest (indexing from 0).
A. (0, [2, 1, 3])
B. (0, [1, 2, 3])
C. (1, [1, 3, 2])
Answer only with the letter.3. Internal search “from memory”: I first give the model the list of pairs, then give it instructions, asking it to answer only with a single token. It seems implausible that the model has already computed `digits[idx]` before being given the instructions (which is why I decided on this task), so it is forced to implement the whole search process from memory in the last few token positions.
A. (2, [2, 1, 3])
B. (0, [1, 2, 3])
C. (0, [2, 1, 3])
Given the list of `(idx, digits)` pairs, tell me for which pair is `digits[idx]` largest (indexing from 0). Answer only with the letter.One reason the model might be failing at this is because implementing the value computation `digits[idx]` is too hard, so I also report a baseline (“compute value”) where I simply ask the model to compute the value for one pair (with a variant using instructions first and last).
Prompts weren’t particularly tuned, which is a significant limitation for assessing absolute capability, and a slight limitation for assessing relative capability because the prompts are very similar.
Results
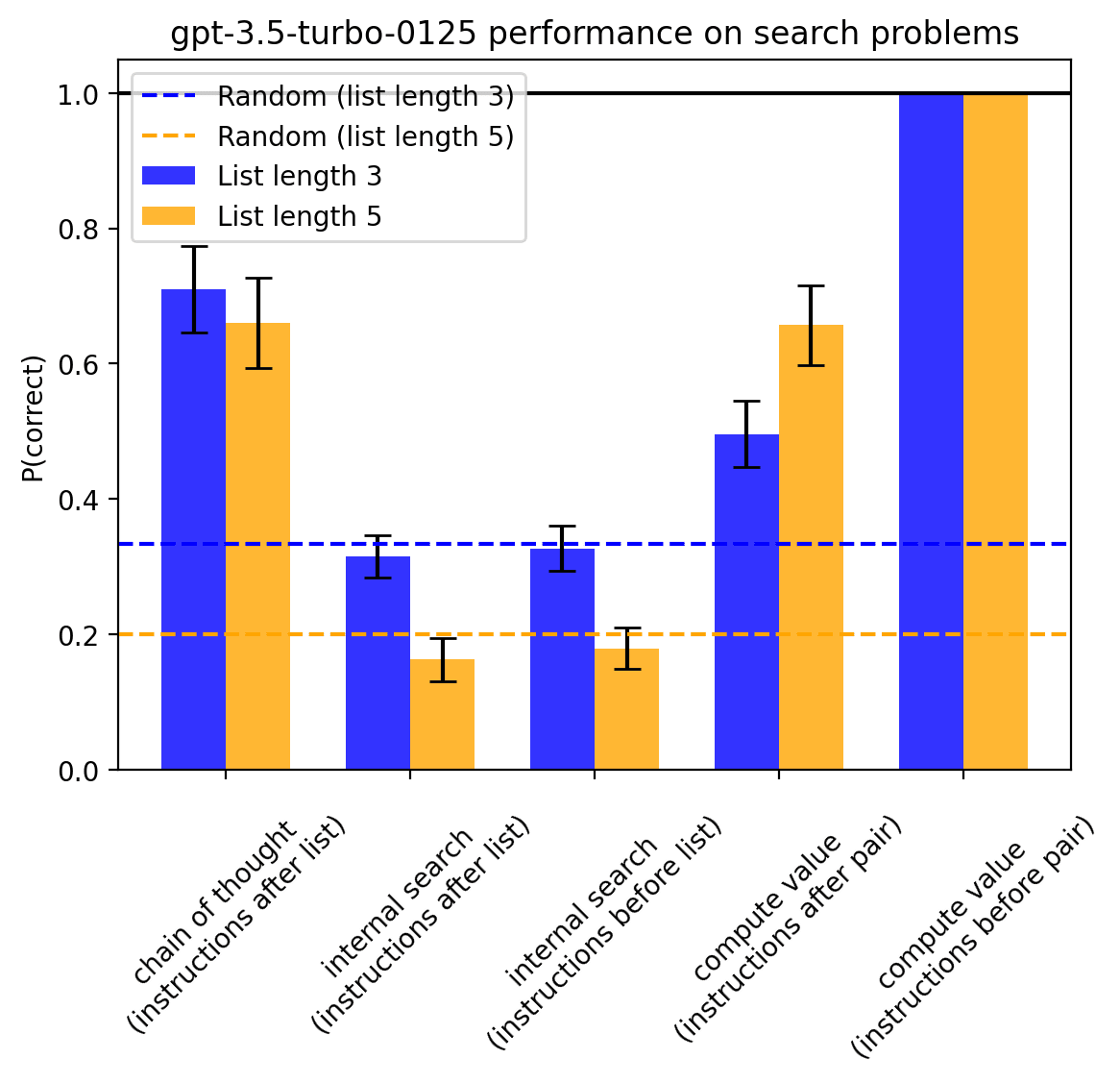
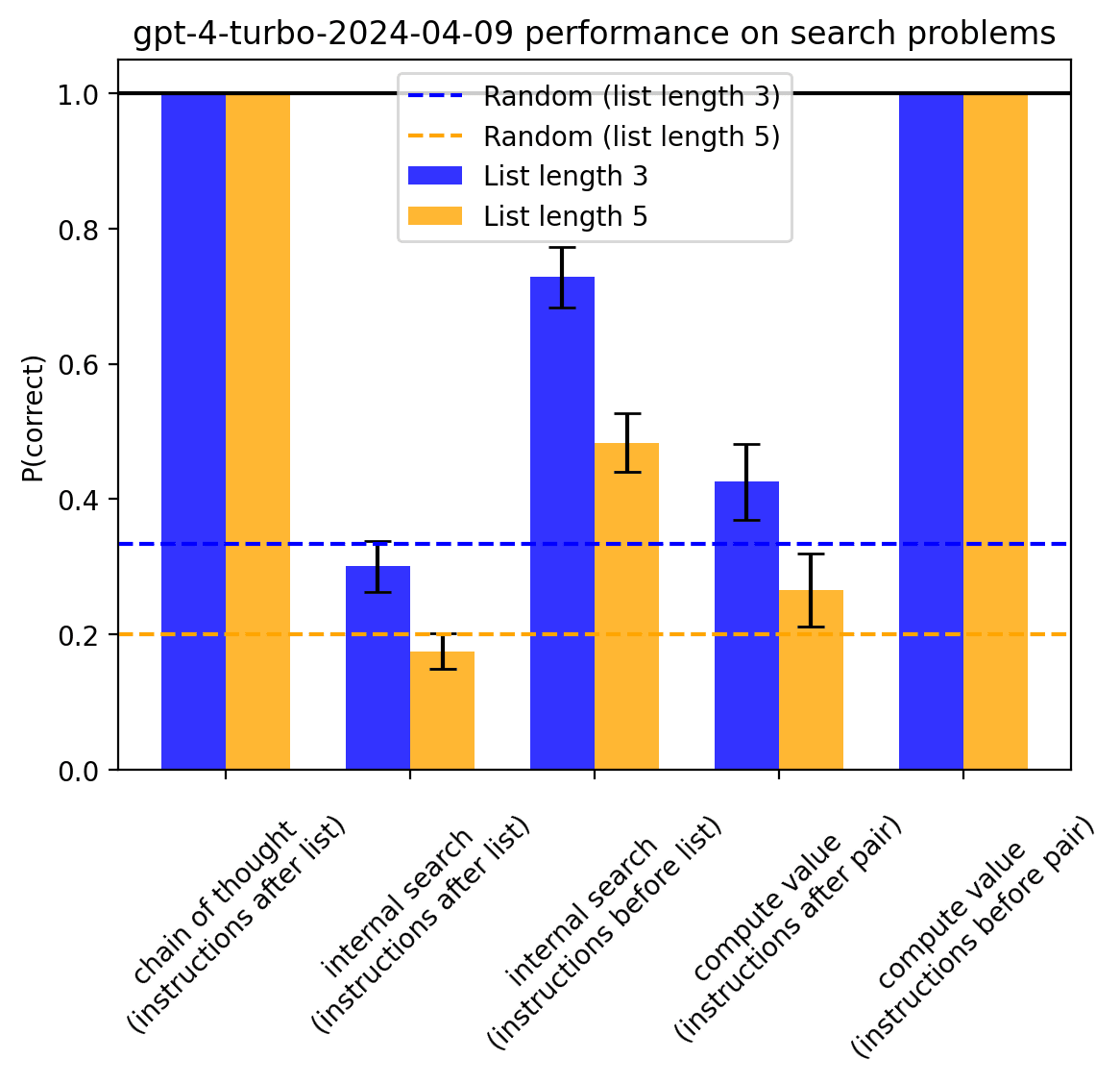
P(correct) indicates the probability (normalized by the probabilities assigned to the other candidates) assigned to the correct answer, or, in the case of chain of thought, the fraction of examples in which the model concluded with the correct answer. Error bars indicate 95% CIs based on standard error. Note that list length is also the number of pairs the model was presented with. See code for details.
- GPT-3.5-turbo and GPT-4-turbo both find internal search much harder than external search
- Neither one can do internal search “from memory” at all, though this may mostly be due to it being hard to compute values from memory
- GPT-3.5-turbo can’t do either form of internal search at all
- Allowing GPT-4-turbo to compute values as the candidates appear in the text (“instructions before list”) enables it to perform search significantly better
- It’s weird that 3.5 does better than 4 for computing values with instructions given after the pair
What does this tell us about inductive biases of various internal behaviors?
That chain-of-thought is more effective is unsurprising given the extra compute used, and that it’s an established technique. This bias might also be driven by the training data to a significant extent, and not just the architecture, because training data includes reasoning traces.
The difference between the two kinds of internal search, however, may provide evidence of autoregressive transformer inductive biases. While GPT-4-turbo performs substantially worse at internal search from memory than internal search using token positions, GPT-4-turbo found it nearly-correspondingly hard to simply compute `digits[idx]` from memory (weirdly worse than 3.5). If one were to devise an experiment with a value that the model is capable of computing from memory, one could find stronger evidence bearing on the inductive biases of LMs tasked with search from memory.
There is also a mechanistic argument why transformers might have an inductive bias away from internal search over a single token position.
If a model wants to compute a value for each candidate in parallel and then choose the argmax, all within a single token position, it is required to implement `num_candidates` copies of the value-computing circuit in its weights because the model can’t pass different activations through the same weights within a single token position (credit to Fabien Roger for arguing this to me). Our “instructions after list” experiments don’t technically limit the model to one token position, but if the model wanted to reuse weights for value computation across token positions, it would need to devise a strategy for assigning candidates’ value computations to the remaining, irrelevant token positions, which also seems like a strike against a simplicity prior.
While this experiment doesn’t provide that much evidence, other experiments like this on different models and tasks could be useful for understanding inductive biases. These results weakly suggest that the frontier of search/consequentialism capabilities will come from externalized reasoning, for transformer LMs trained using current techniques. Parallelized internal search from memory seems disfavored, especially for transformer architectures on inputs with tokens unrelated to the candidates in the search being computed.
Results like these might not be informative for our ability to interpret the target of optimization because, among other reasons:
- Future models may use different/longer serial internal reasoning traces, or unfaithful external reasoning
- Future models probably will be trained to do internal search significantly more than today
- Reward hacking can be caused by the selection pressures of SGD even without internal search
Code is available at: https://gist.github.com/AlexTMallen/77190b0971deca739acb11f2c73c3212
Appendix
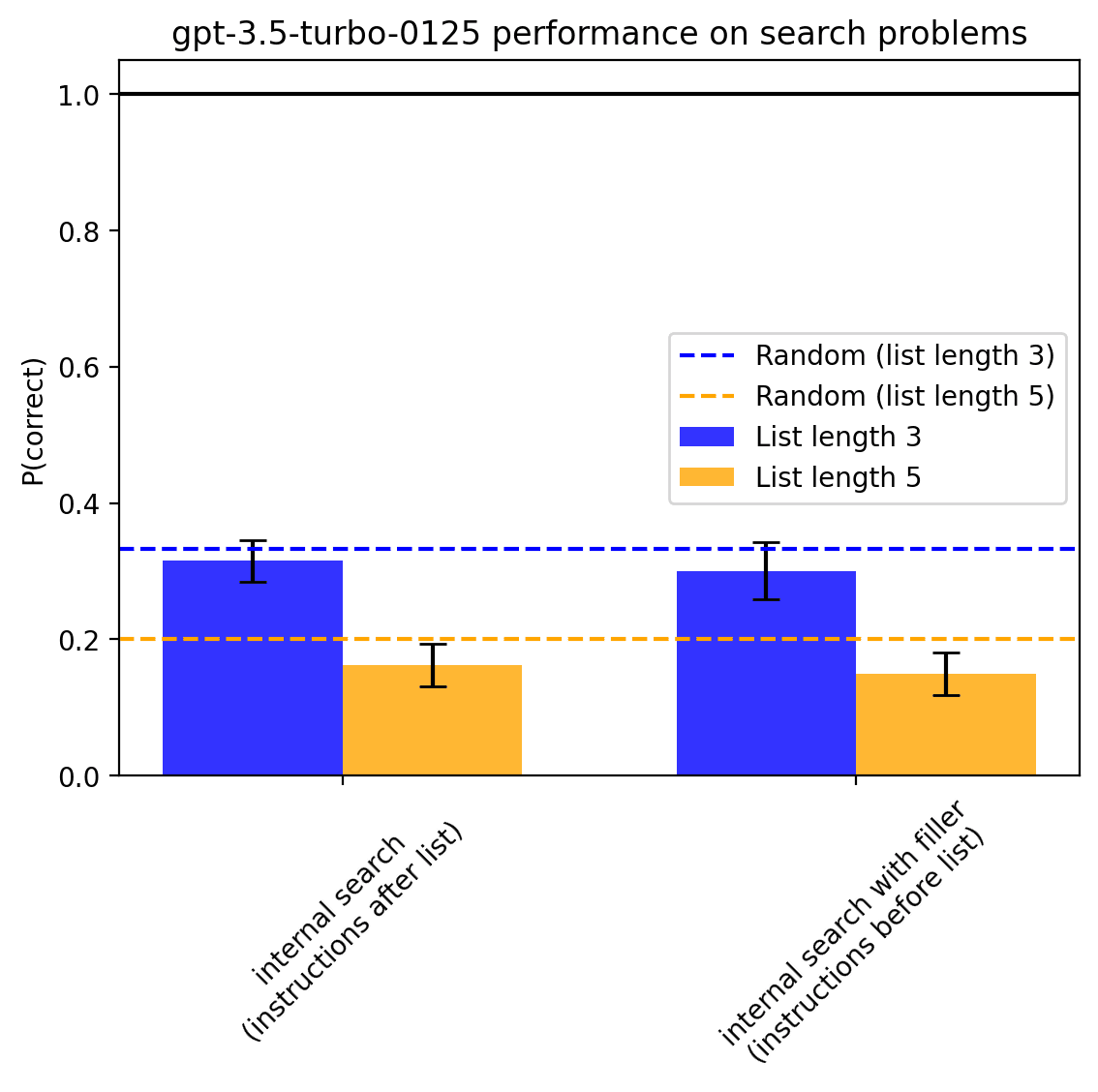
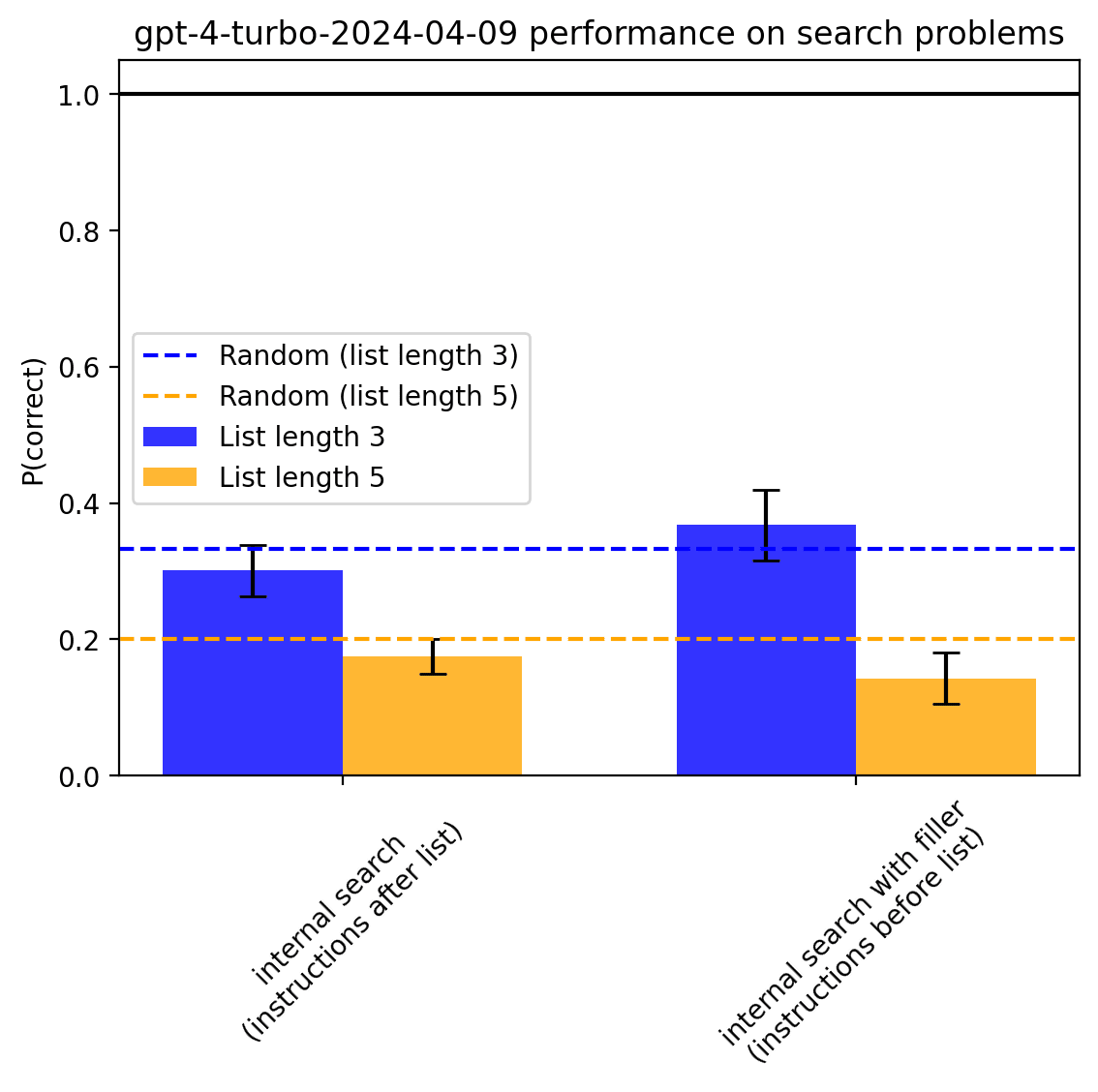
Upon suggestion by Fabien, I also tried adding filler text to the “instructions after list” setting that might allow the model to have token positions where it can compute the values to argmax over. The prompt looked like this:
A. (1, [2, 1, 3])
B. (0, [3, 1, 2])
C. (2, [3, 1, 2])
Given the list of `(idx, digits)` pairs, tell me for which pair is `digits[idx]` largest (indexing from 0). I will now say "pair A, pair B, pair C", to give you some time to think. On "pair A", think about what the value of digits[idx] is for pair A, and so on for the remaining pairs. Then when answering you will be able to recover the value from the corresponding pairs by paying attention to them. Here is the list of strings I told you I would say: pair A, pair B, pair C. Please answer now. Answer only with the letter.
Prompts for the “compute-value” baselines:
(1, [2, 3, 1])
Given the above pair `(idx, digits)`, tell me what is `digits[idx]` (indexing from 0). Answer only with the digit.Given the below pair `(idx, digits)`, tell me what is `digits[idx]` (indexing from 0).
(0, [3, 2, 1])
Answer only with the digit.
2 comments
Comments sorted by top scores.
comment by meemi (meeri) · 2024-04-15T16:03:56.783Z · LW(p) · GW(p)
Great post! I'm glad you did this experiment.
I've worked on experiments where I test gpt-3.5-turbo-0125 performance in computing iterates of a given permutation function in one forward pass. Previously my prompts had some of the instructions for the task after specifying the function. After reading your post, I altered my prompts so that all the instructions were given before the problem instance. As with your experiments, this noticeably improved performance, replicating your result that performance is better if instructions are given before the instance of the problem.
comment by Sophie Liu (sophie-liu) · 2024-04-14T18:57:08.697Z · LW(p) · GW(p)
Super easy to follow and well structured!