[Linkpost]Transformer-Based LM Surprisal Predicts Human Reading Times Best with About Two Billion Training Tokens
post by Curtis Huebner · 2023-05-04T17:16:33.335Z · LW · GW · 1 commentsThis is a link post for https://arxiv.org/abs/2304.11389
Contents
1 comment
From the abstract:
Recent psycholinguistic studies have drawn conflicting conclusions about the relationship between the quality of a language model and the ability of its surprisal estimates to predict human reading times, which has been speculated to be due to the large gap in both the amount of training data and model capacity across studies. The current work aims to consolidate these findings by evaluating surprisal estimates from Transformer-based language model variants that vary systematically in the amount of training data and model capacity on their ability to predict human reading times. The results show that surprisal estimates from most variants with contemporary model capacities provide the best fit after seeing about two billion training tokens, after which they begin to diverge from humanlike expectations. Additionally, newly-trained smaller model variants reveal a 'tipping point' at convergence, after which the decrease in language model perplexity begins to result in poorer fits to human reading times. These results suggest that the massive amount of training data is mainly responsible for the poorer fit achieved by surprisal from larger pre-trained language models, and that a certain degree of model capacity is necessary for Transformer-based language models to capture humanlike expectations.
The authors show strongly U-shaped curves relating the additional predictive power that adding per-token suprisal gives to a regression model and model perplexity.
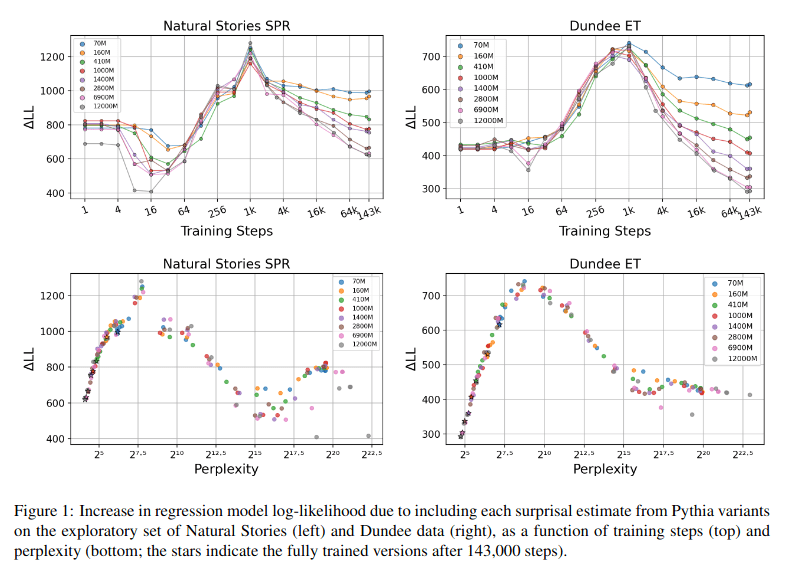
From the results section:
The results in Figure 13 show that across both cor-
pora, surprisal from most LM variants made the
biggest contribution to regression model fit after
1,000 training steps (i.e. after ∼2B tokens). This
seems to represent a ‘humanlike optimum,’ after
which surprisal estimates begin to diverge from hu-
manlike expectations as training continues. At this
point in training, there appears to be no systematic
relationship between model capacity and predictive
power of surprisal estimates.
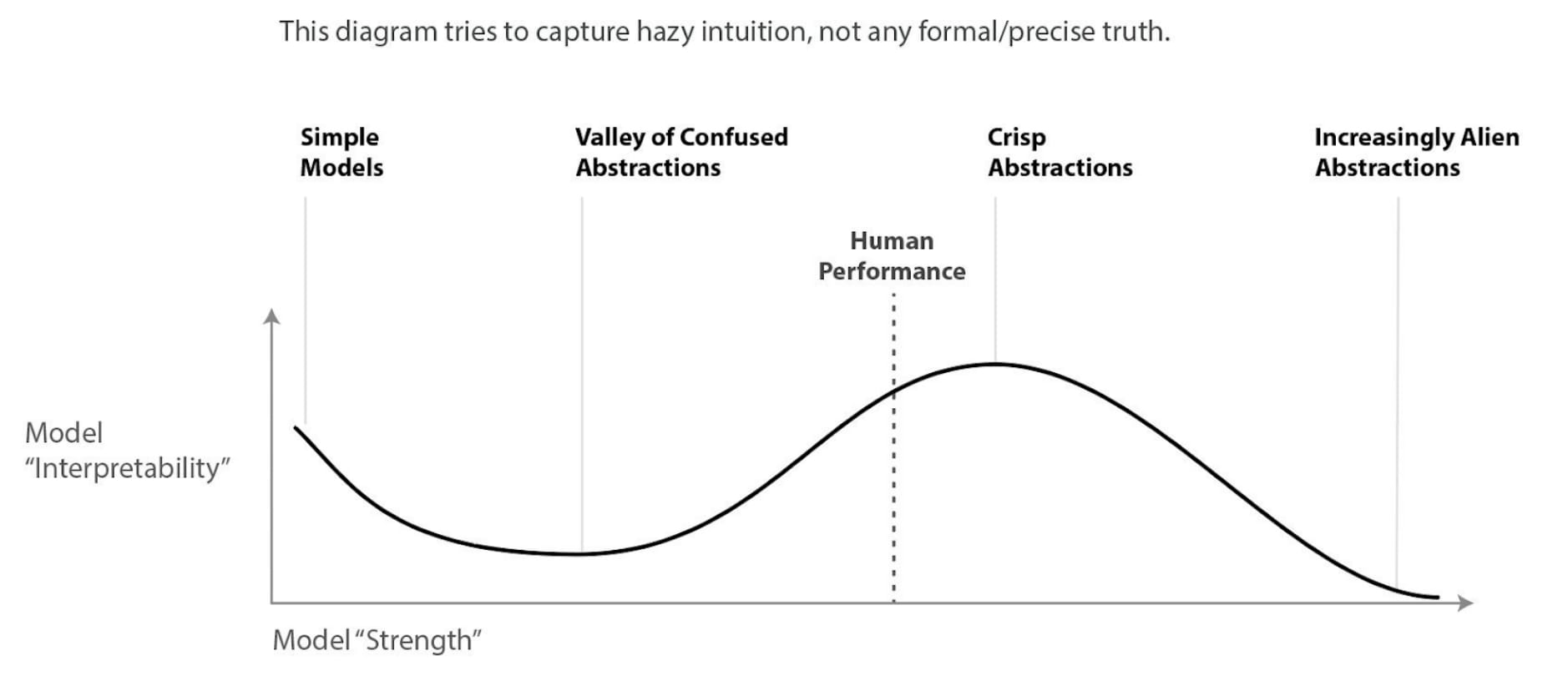
I'm not going to speculate too much but these curves remind me a lot of the diagram describing Chris Olah's view on the difficulty of mechanistic interpretability with model power:
Other remarks:
-It would be neat to compare the perplexity inflexion point with the Redwood estimates of human perplexity scores on text.
-Performance seems well tied to model perplexity and tokens but not so much to model size
1 comments
Comments sorted by top scores.
comment by jacob_cannell · 2023-05-05T17:20:21.487Z · LW(p) · GW(p)
Interesting. My previous upper estimate of human lifetime training token equivalent was ~10B tokens: (300 WPM ~ 10T/s * 1e9/s ), so 2B tokens makes sense if people are reading/listening only 20% of the time.
So the next remaining question is what causes human performance on downstream tasks to scale much more quickly as a function of tokens or token perplexity (as LLMs need 100B+, perhaps 1T+ tokens to approach human level). I'm guessing it's some mix of:
- Active curriculum learning focusing capacity on important knowledge quanta vs trivia
- Embodiment & RL - humans use semantic knowledge to improve world models jointly trained via acting in the world, and perhaps have more complex decoding/mapping
- Grokking vs shallow near memorization