Grokking Beyond Neural Networks
post by Jack Miller (jack-miller) · 2023-10-30T17:28:04.626Z · LW · GW · 0 commentsThis is a link post for https://arxiv.org/abs/2310.17247
Contents
Abstract Grokking without Neural Networks Inducing Grokking via Data Augmentation A More General Explanation of Grokking Conclusion None No comments
We recently authored a paper titled, Grokking Beyond Neural Networks: An Empirical Exploration with Model Complexity. Below, we provide an abstract of the article along with key take-aways from our experiments.
Abstract
In some settings neural networks exhibit a phenomenon known as grokking, where they achieve perfect or near-perfect accuracy on the validation set long after the same performance has been achieved on the training set. In this paper, we discover that grokking is not limited to neural networks but occurs in other settings such as Gaussian process (GP) classification, GP regression and linear regression. We also uncover a mechanism by which to induce grokking on algorithmic datasets via the addition of dimensions containing spurious information. The presence of the phenomenon in non-neural architectures provides evidence that grokking is not specific to SGD or weight norm regularisation. Instead, grokking may be possible in any setting where solution search is guided by complexity and error. Based on this insight and further trends we see in the training trajectories of a Bayesian neural network (BNN) and GP regression model, we make progress towards a more general theory of grokking. Specifically, we hypothesise that the phenomenon is governed by the accessibility of certain regions in the error and complexity landscapes.
Grokking without Neural Networks
In our paper, we demonstrate that grokking can be observed in linear regression, GP classification, and GP regression. As an illustration, consider the accompanying figure which shows grokking within GP classification on a parity prediction task. If one posits that GPs lack the ability for feature learning, this observation supports the idea that grokking doesn't necessitate feature learning.
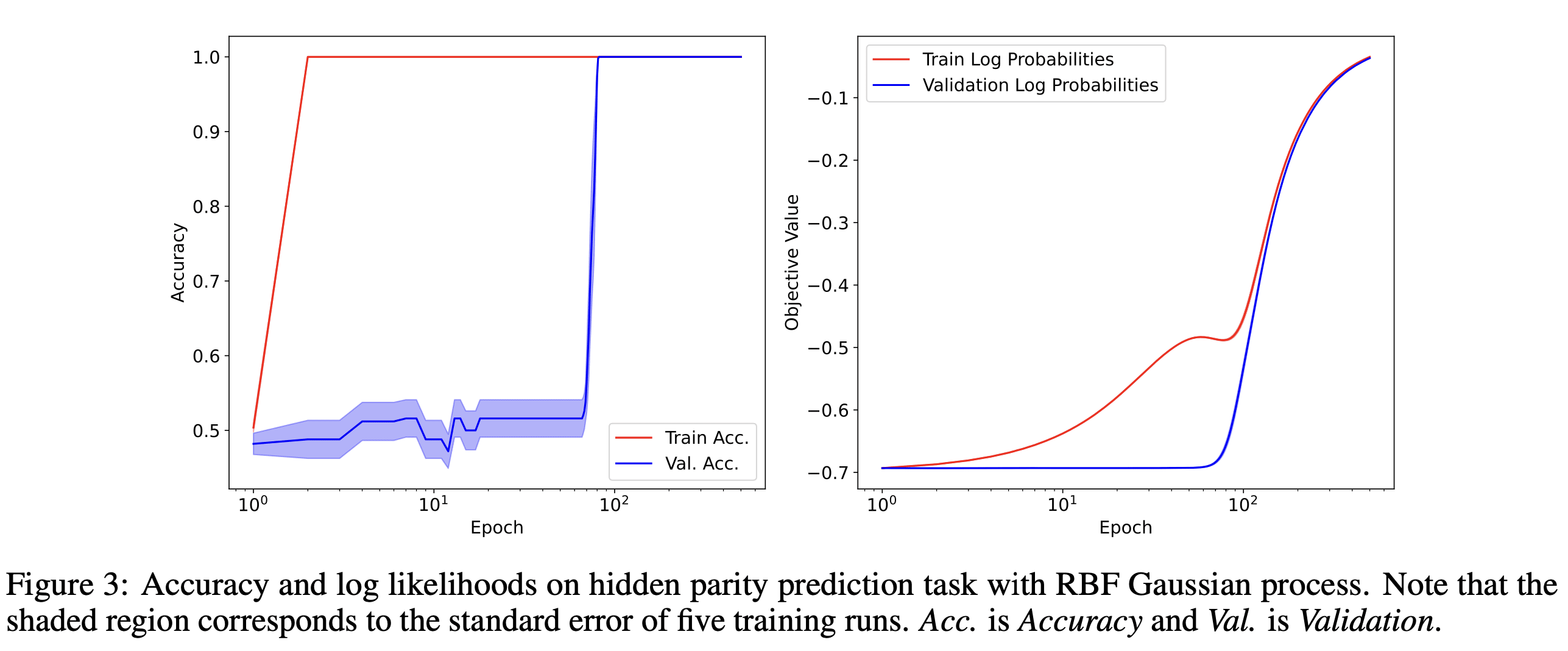
Inducing Grokking via Data Augmentation
Inspired by the work of Merrill et al. (2023) and Barak et al. (2023), we uncover a novel data augmentation technique that prompts further grokking in algorithmic datasets. Here's how it operates: given a training example of dimensionality , we append additional dimensions of data drawn from a standard normal distribution . In the following figure, we delineate the correlation between and the interval between epochs where the network achieves high accuracy on the training and validation sets. Intriguingly, this relationship appears to align well with exponential regression[1].
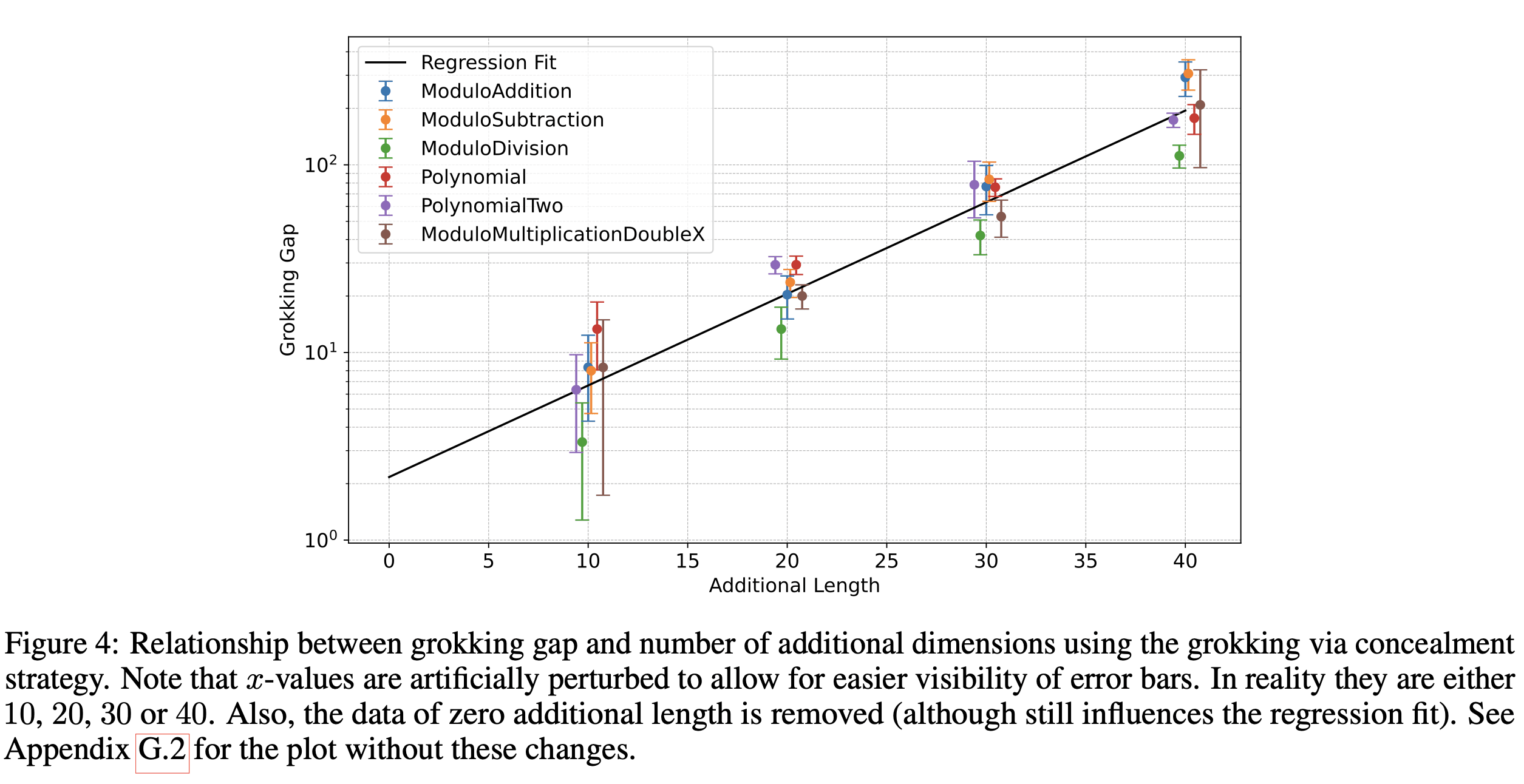
A More General Explanation of Grokking
In our literature review, we didn't come across any existing theory of grokking that catered to the broader scenarios we investigated. This isn't surprising given that grokking has predominantly been observed in neural networks, causing researchers to focus only on this model type. This propelled us to contemplate a more overarching explanation. Our resulting theory posits:
If the low error, high complexity (LEHC) weight space is readily accessible from typical initialisation but the low error, low complexity (LELC) weight space is not, models will quickly find a low error solution which does not generalise. Given a path between LEHC and LELC regions which has non-increasing loss, solutions in regions of LEHC will slowly be guided toward regions of LELC due to regularisation. This causes an eventual decrease in validation error, which we see as grokking.
This claim is further supported by trajectory analyses we complete on a BNN and GP regression model[2]. While we do not provide a mathematical proof of the claim, it does seem to be a natural explanation of the phenomenon with decent empirical backing. Further, it seems to be congruent with other theories of the phenomenon[3].
Conclusion
Prior to our research on grokking, our understanding was that the phenomenon was confined to neural networks, largely attributable to the internal competition of circuits within these networks. While we continue to endorse this latter view, we now perceive circuit competition as a specific instance within our broader explanation of grokking. Future research will determine the robustness of our theory and uncover whether grokking might be evident in an even more diverse set of scenarios.
- ^
See Section 2.2 in the paper for more details concerning the analysis and regression.
- ^
See Section 2.3 in the paper for more details regarding these trajectories.
- ^
See Appendix E in the paper for a discussion of the connection between our theory of grokking and previous explanations.
0 comments
Comments sorted by top scores.