Political Biases in LLMs: Literature Review & Current Uses of AI in Elections
post by Yashvardhan Sharma (yashvardhan-sharma), Robayet Hossain (robayet-hossain), Ariana Gamarra (ariana-gamarra) · 2024-03-07T19:17:25.586Z · LW · GW · 0 commentsContents
What is Political Bias in LLMs? What do the current works say? Round 1: Unveiling Bias Through Diverse Methodologies Round 2: Delving Deeper into Bias Detection and Measurement Limitations of these papers: Limitations Details What areas of research should we consider moving forward? What are the social implications and current use of AI in elections? Acknowledgments References None No comments
TL;DR: This research discusses political biases in Large Language Models (LLMs) and their implications, exploring current research findings and methodologies. Our research summarized eight recent research papers, discussing methodologies for bias detection, including causal structures and reinforced calibration, while also highlighting real-world instances of AI-generated disinformation in elections, such as deepfakes and propaganda campaigns. Ultimately, proposing future research directions and societal responses to mitigate risks associated with biased AI in political contexts.
What is Political Bias in LLMs?
Large Language Models (LLMs) are neural networks that are trained on large datasets with parameters to perform different natural language processing tasks (Anthropic, 2023). LLMs rose in popularity among the general public with the release of OpenAI’s ChatGPT due to their accessible and user-friendly interface that does not require prior programming knowledge (Caversan, 2023). Since its release, researchers have been trying to understand their societal implications, limitations, and ways to improve their outputs to reduce user risk (Gallegos et al., 2023; Liang et al., 2022). One area of research explored is the different social biases that LLMs perpetuate through their outputs. For instance, the LLM may be more likely to assign a particular attribute to a specific social group, such as females working certain jobs or a terrorist more likely belonging to a certain religion (Gallegos et al., 2023; Khandelwal et al., 2023).
In this post, we focus on a different bias called political bias, which could also affect society and the political atmosphere (Santurkar et al., 2023). Before, looking into current research regarding this bias in LLMs, we will define the term political bias as the following: When LLMs disproportionally generate outputs that favor a partisan stance or specific political views (e.g., left-leaning versus progressive views) (Urman & Makhortykh, 2023; Motoki, 2023).
What do the current works say?
Having established the definition of political bias in LLMs and its potential societal implications, let's delve into existing research exploring this crucial topic. Our team targeted research papers from arXiv and Google Scholar, focusing on searches using keywords related to “political bias”, “elections”, and “large language models”, and set up two rounds of analyses where we discussed key findings.
Our team analyzed the following review paper, Bias and Fairness in Large Language Models, to understand an overview of biases and potential harms that have arisen alongside the outburst of LLMs in recent years. From here, we divided our research structure into two rounds, where we emphasized specific concepts from this first paper and moved on to review narrower topics. Round 1 focused on a holistic review of different biases and auditing approaches for LLMs whereas Round 2 allowed us to narrow down even further and delve deeper into political biases and overall implications in LLMs. This section summarizes these key findings from eight recent studies, categorized into two rounds for clarity.
Here is a list of all 8 studies evaluated:
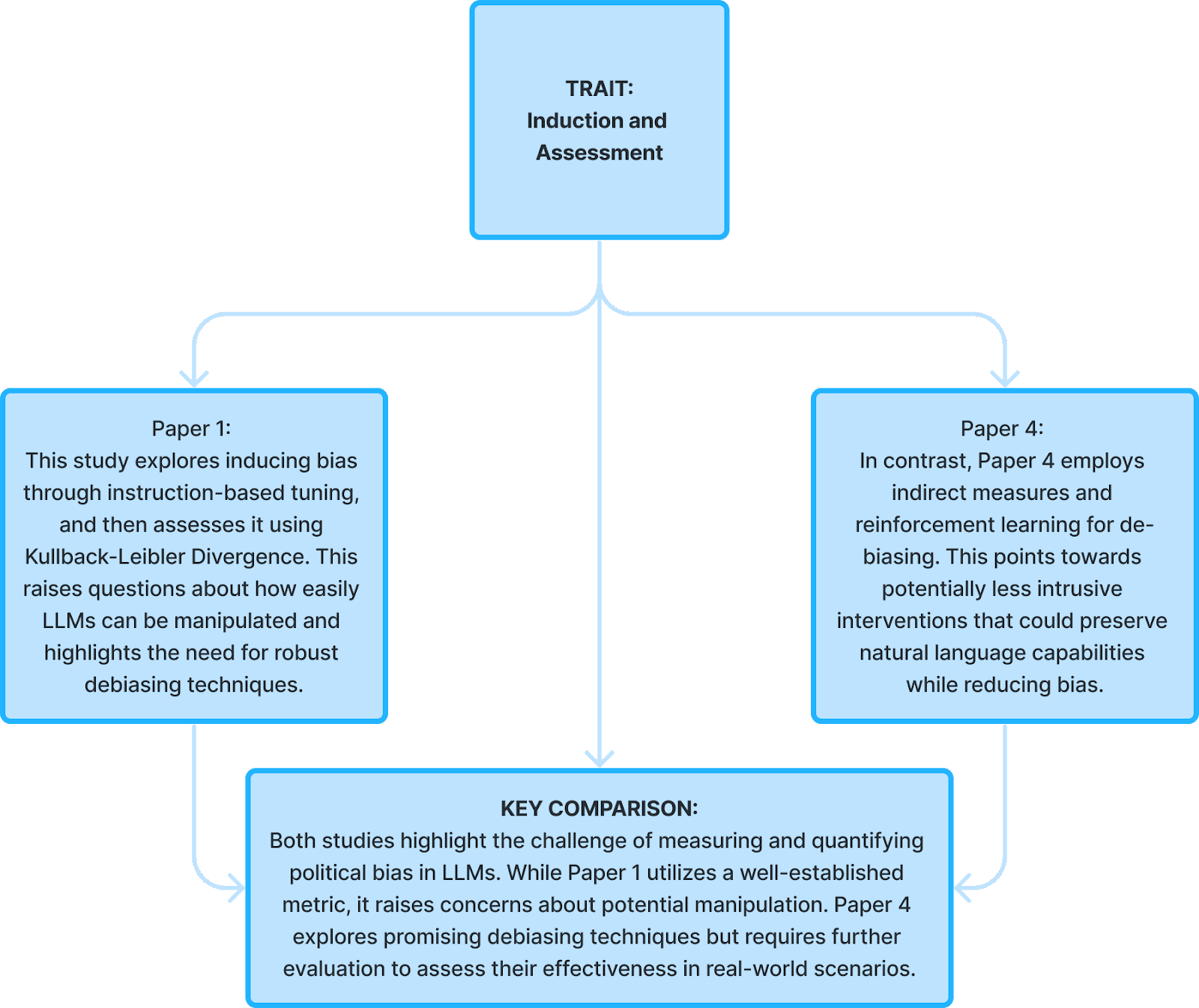
- Inducing Political Bias Allows Language Models Anticipate Partisan Reactions to Controversies - Paper 1
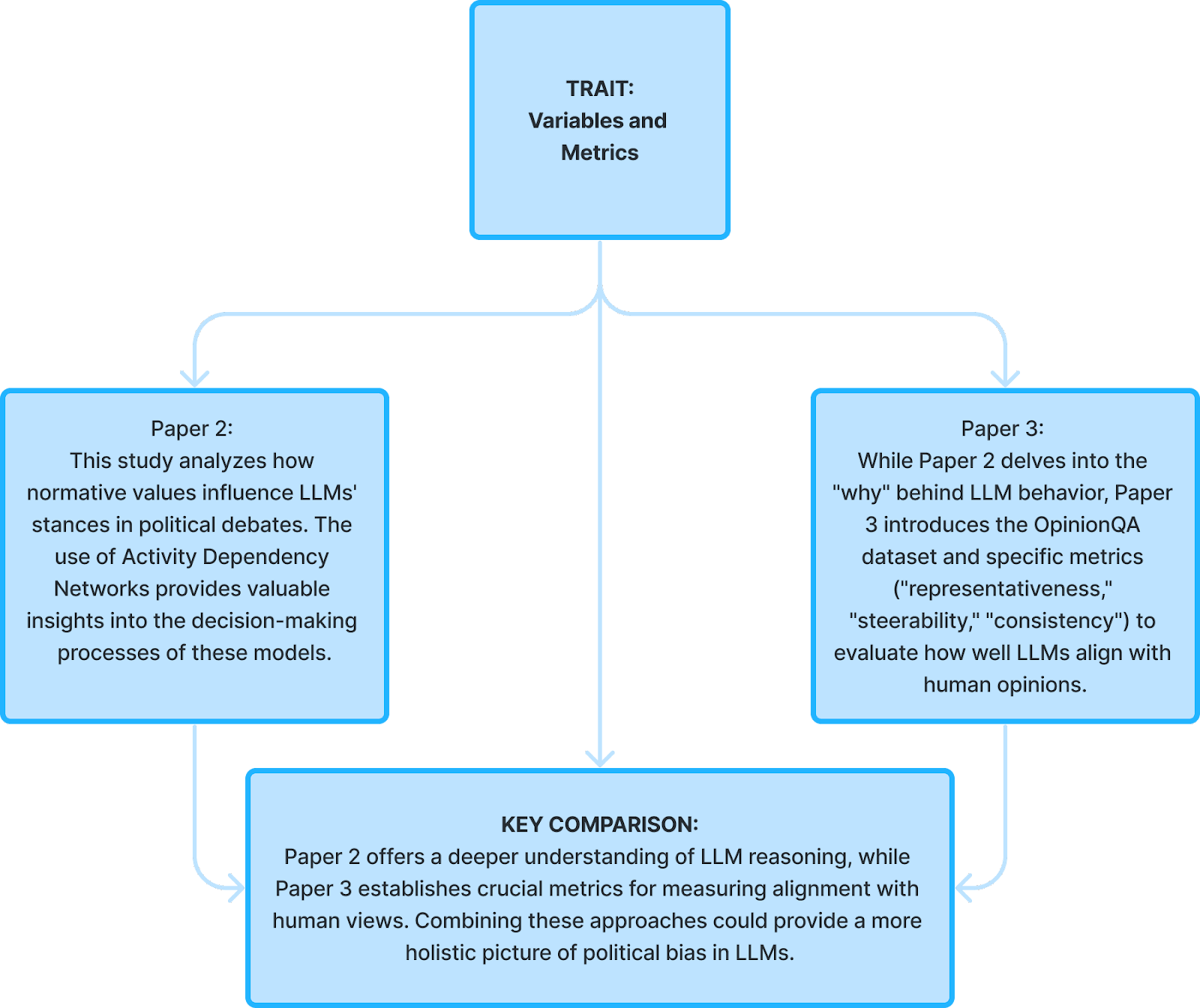
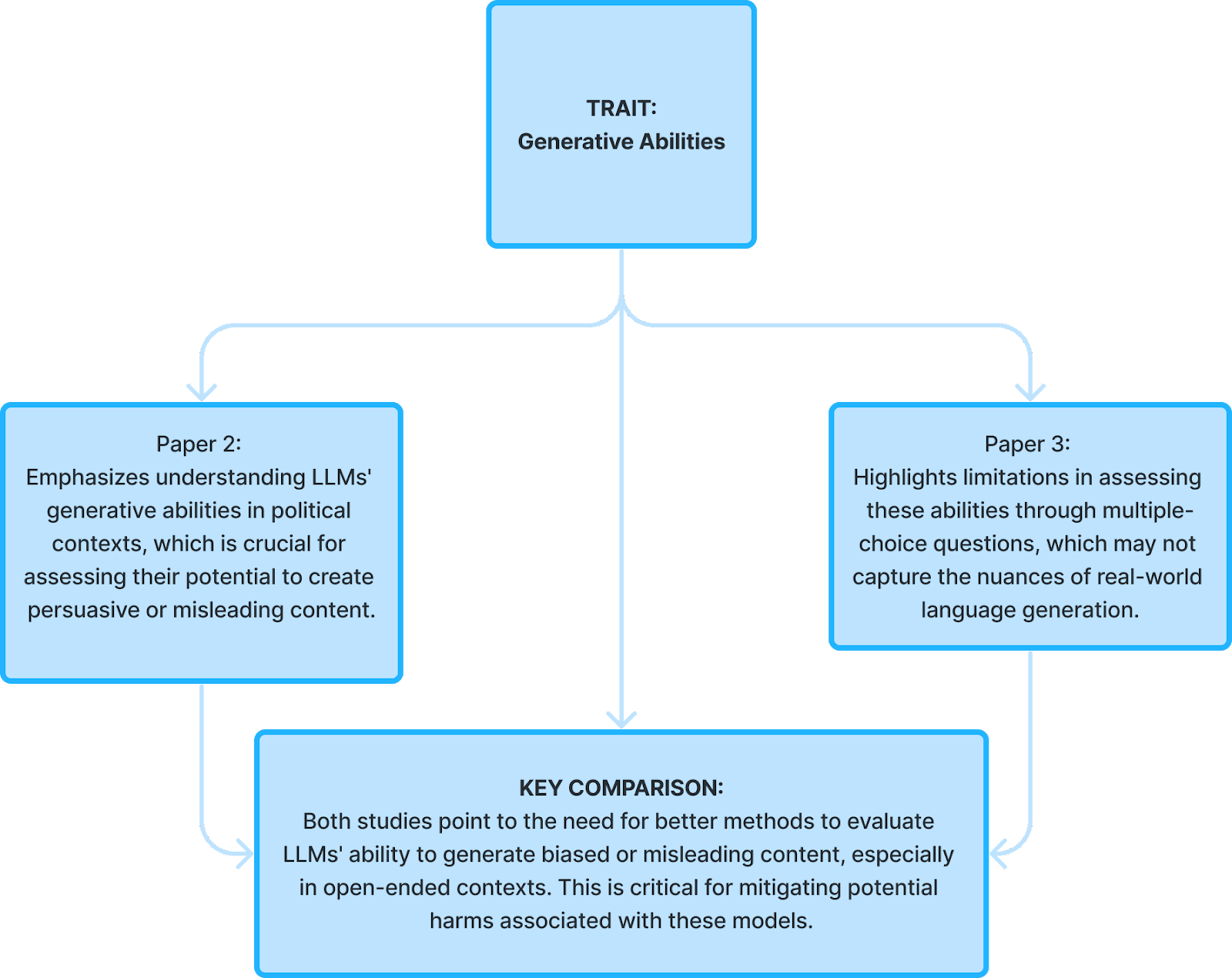
- Navigating the Ocean of Biases: Political Bias Attribution in Language Models via Causal Structures - Paper 2
- Whose Opinions Do Language Models Reflect? - Paper 3
- Mitigating Political Bias in Language Models Through Reinforced Calibration - Paper 4
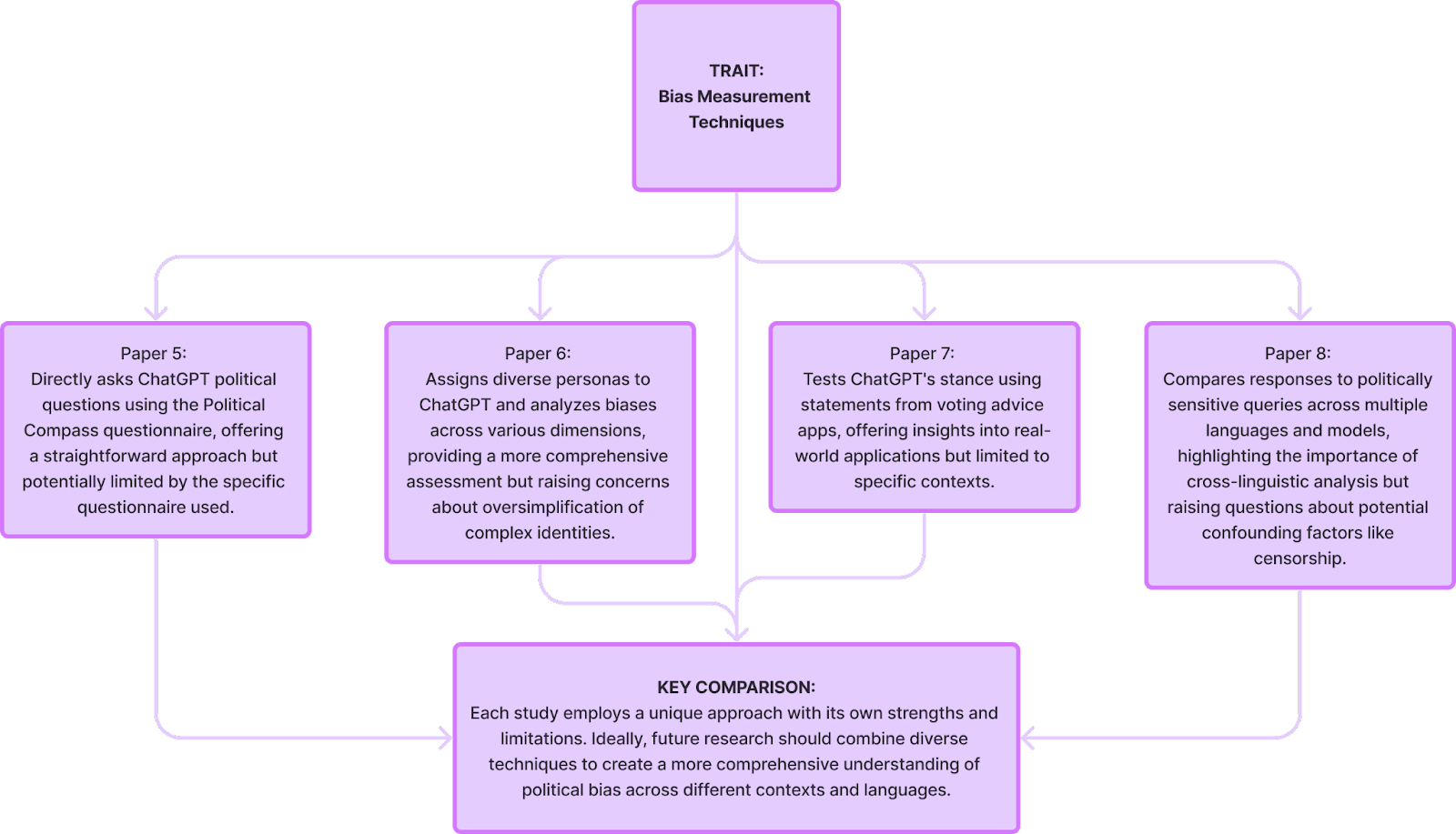
- More human than human: measuring ChatGPT political bias - Paper 5
- Bias Runs Deep: Implicit Reasoning Biases in Persona-Assigned LLMs - Paper 6
- The political ideology of conversational AI: Converging evidence on ChatGPT’s pro-environmental, left-libertarian orientation - Paper 7
- The Silence of the LLMs: Cross-Lingual Analysis of Political Bias and False Information Prevalence in ChatGPT, Google Bard, and Bing Chat - Paper 8
Round 1: Unveiling Bias Through Diverse Methodologies
As discussed earlier, political bias in LLMs can manifest in various ways, potentially influencing public opinion, elections, and even shaping real-world events. Understanding and mitigating this bias is crucial for the responsible development and deployment of LLMs. Round 1 studies evaluated the first four papers and showcased diverse approaches to this challenge:
Round 1 studies evaluated the first four papers and showcased diverse approaches to this challenge:
Round 2: Delving Deeper into Bias Detection and Measurement
Round 2 studies build upon the foundation laid in Round 1 by exploring various techniques for detecting and measuring political bias through papers 5-8:
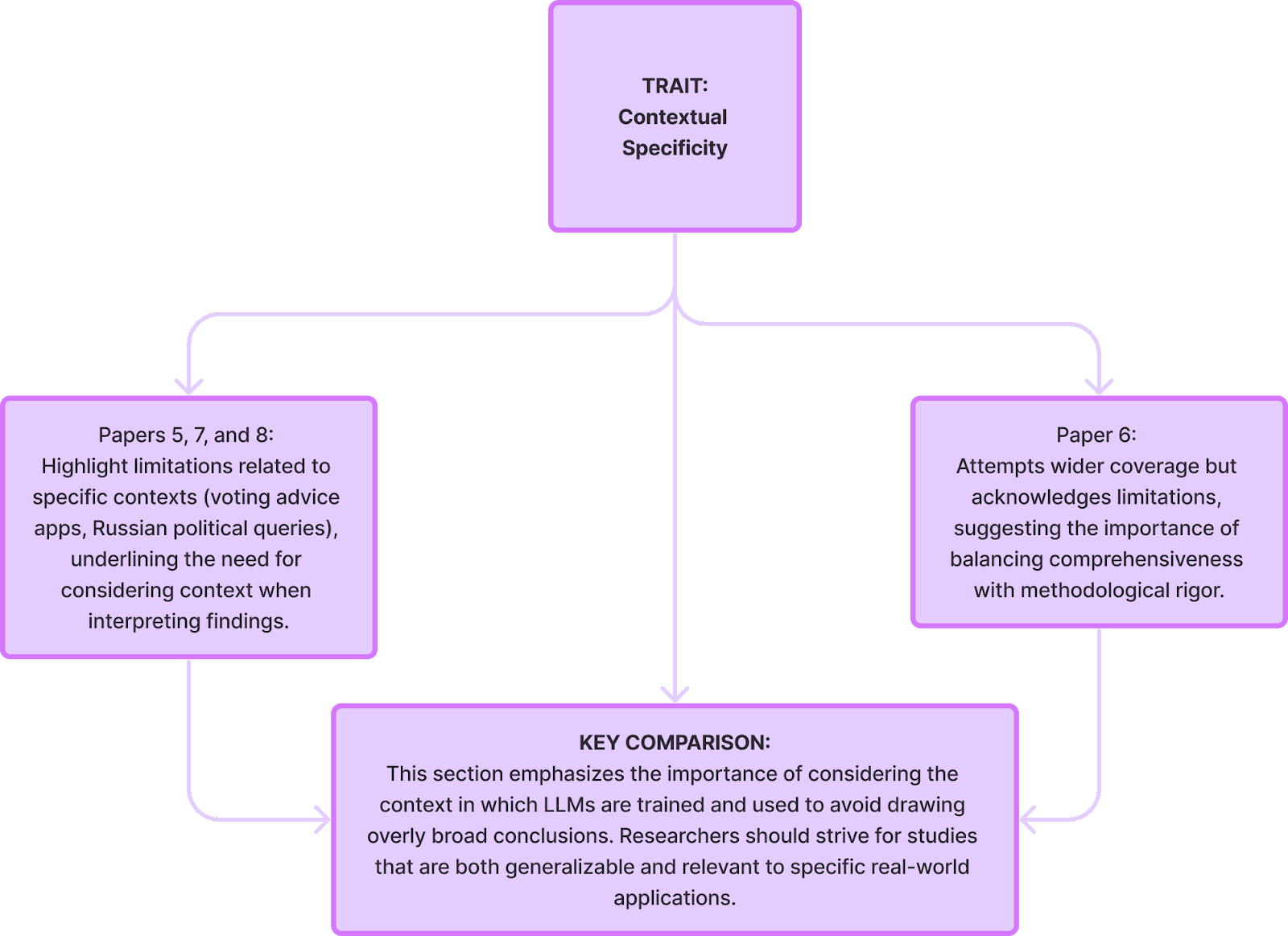
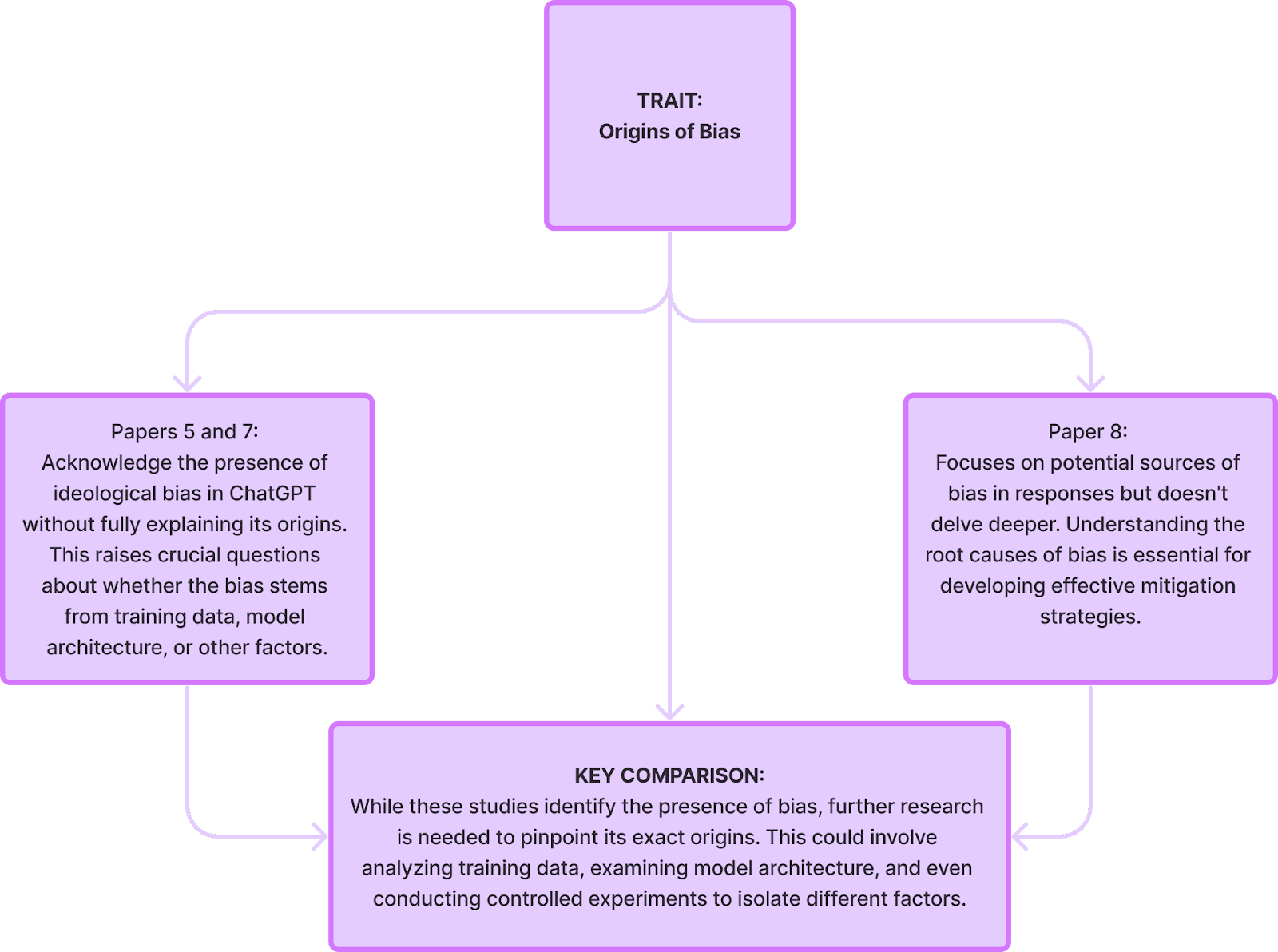
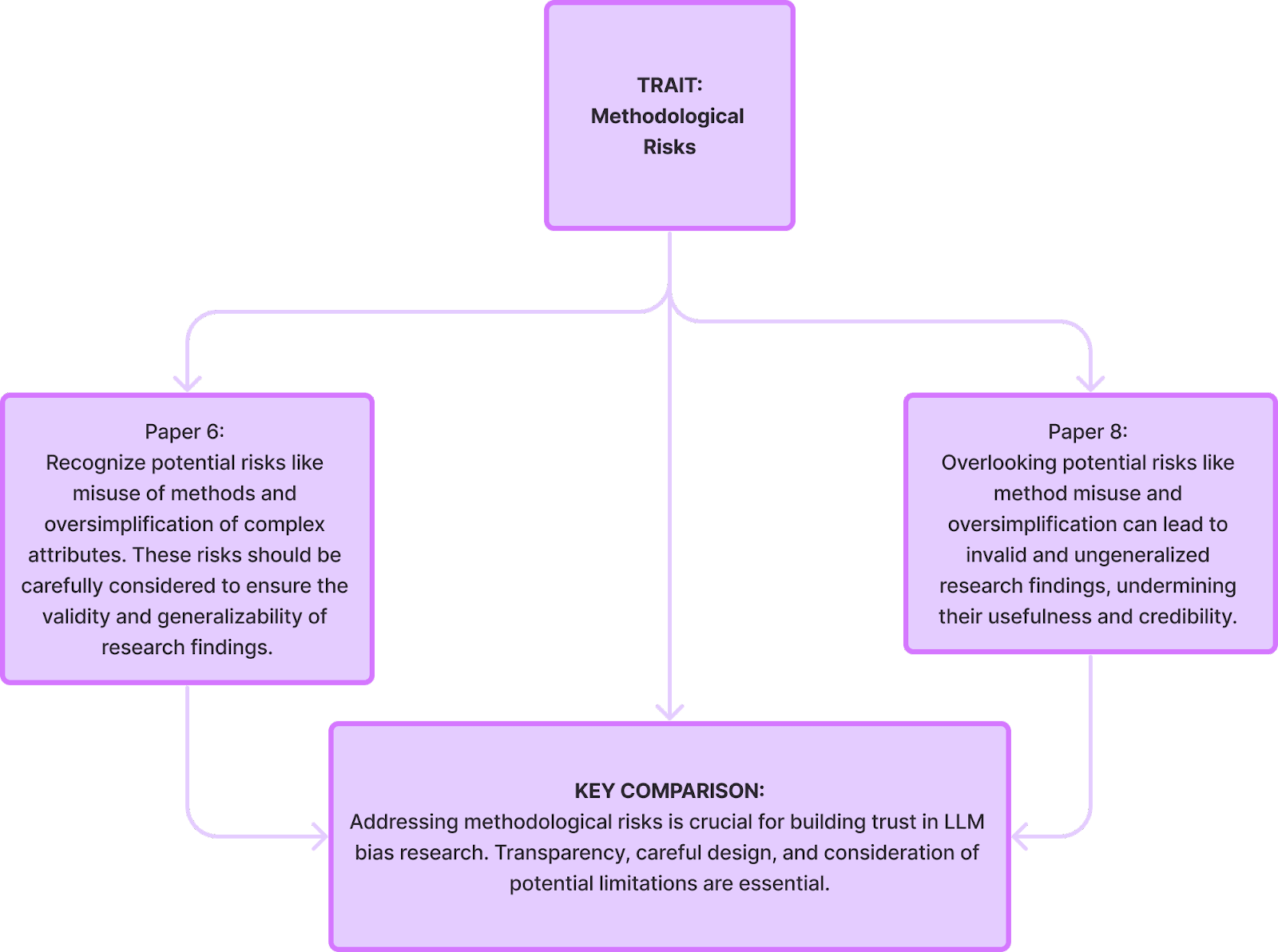
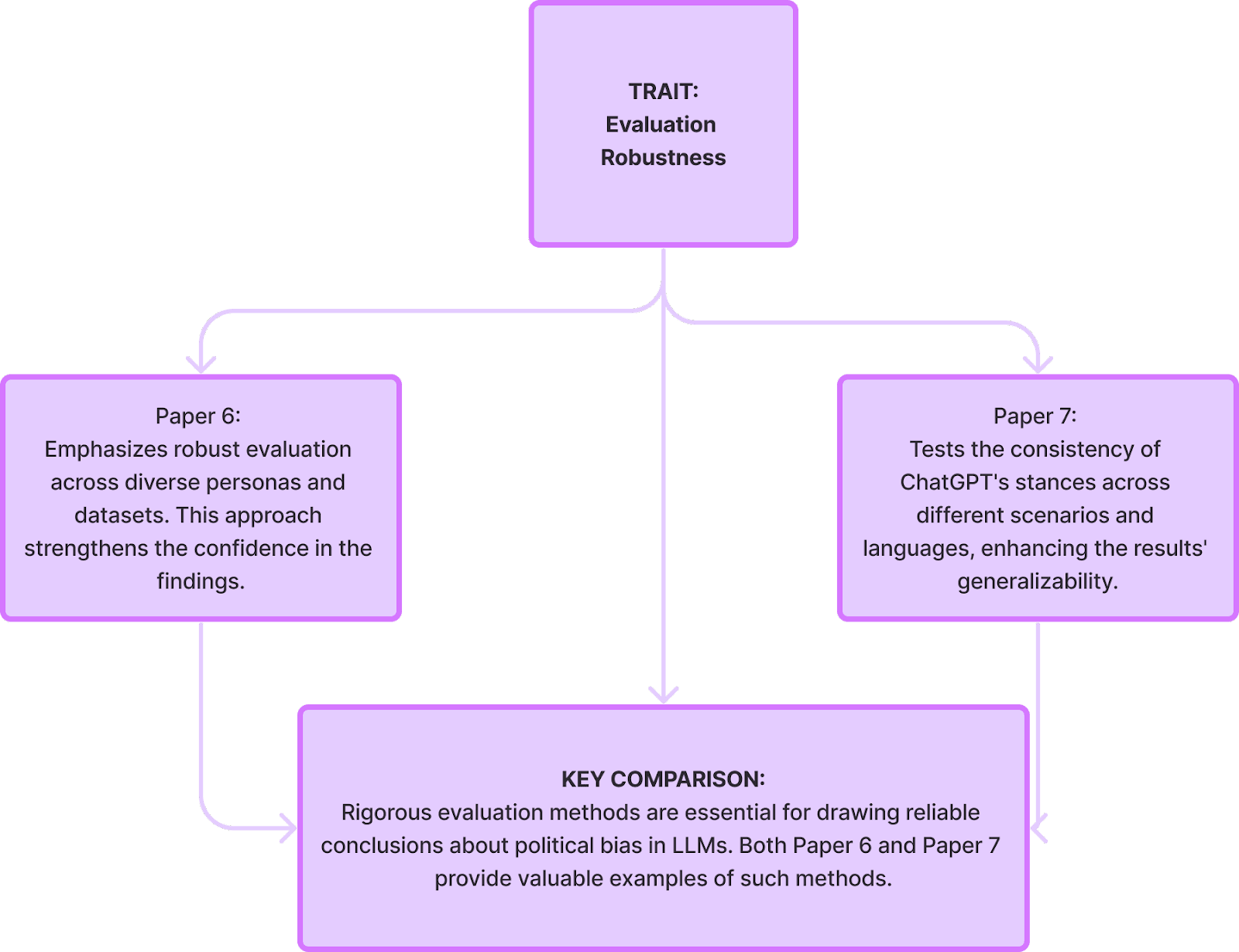
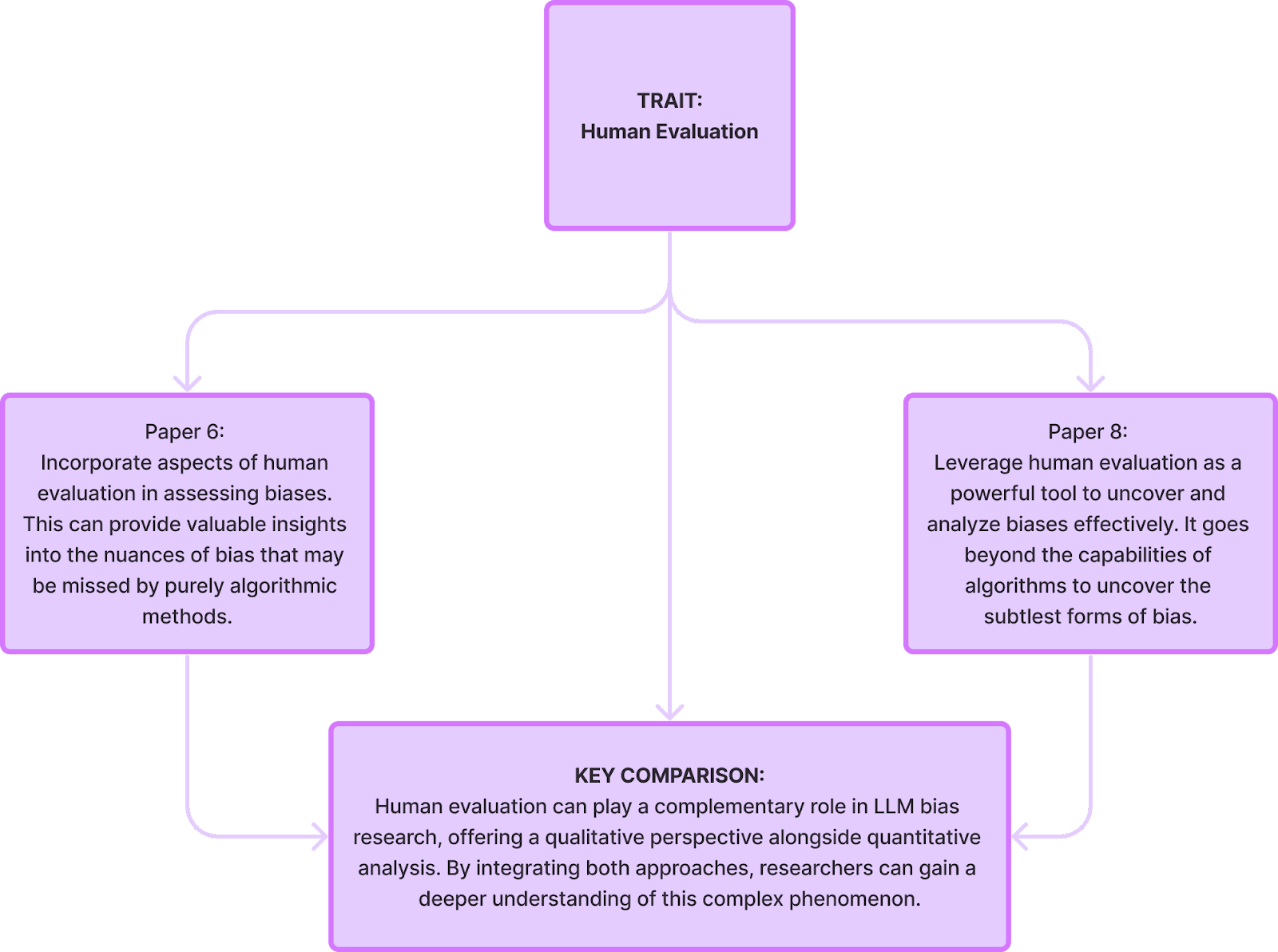
Limitations of these papers:
Limitations | Details |
|---|---|
| Limited/Outdated datasets |
|
| Geographical and cultural specificity |
|
| Multiple choice framing |
|
| Cannot make generalized conclusions about other models |
|
| Lack of constant variables when testing |
|
| Conceptualizing model-human alignment |
|
| Limited attributes used to represent a demographic |
|
| Unclear origins of bias |
|
| No measurement of attitude strength |
|
What areas of research should we consider moving forward?
As research on political bias in LLMs continues to evolve, several key areas require further exploration:
- Expanding beyond English-centric studies: Investigating bias in LLMs trained on diverse languages and cultural contexts is crucial for understanding its global impact.
- Delving deeper into the origins of bias: Pinpointing the root causes of bias within model architectures and training data is essential for developing effective mitigation strategies.
- Developing more robust and nuanced evaluation methods: Combining diverse techniques like human evaluation and automated analysis can provide a more comprehensive picture of bias across different contexts.
This ongoing research will be instrumental in fostering trust and mitigating potential harms associated with biased language models. By understanding and addressing political bias, we can ensure the responsible development and deployment of LLMs that contribute positively to our society.
What are the social implications and current use of AI in elections?
Current generative AI models have shown the potential to create content that could be used to spread false or misleading information. As these models continue to advance, especially at their current pace, they may attain additional skills that could make disinformation more convincing and far-reaching. For example, future models could tailor false narratives to specific audiences and their specific features, generate multimedia content to strengthen their claims, or even automatically promote manipulative messages through influential channels like news outlets or social media (Anderljung et al., 2023).
2024 is going to be an extremely important year in politics, with elections happening around the world in countries, such as India, Bangladesh, Pakistan, the USA, the United Kingdom, and more. The use of AI in elections raises complex yet crucial questions about ethics, transparency, and regulation. As the examples from Argentina, Taiwan, and beyond illustrate, new technologies can be utilized to spread disinformation and manipulate voters. However, with a thoughtful, multifaceted societal response focused on media literacy, fact-checking, and oversight frameworks, the risks of AI can potentially be mitigated.
Acknowledgments
This project was completed as part of the Supervised Program for Alignment Research (SPAR) led by Berkeley AI Safety Initiative in Fall 2023. We would like to thank our SPAR mentor Jan Batzner at the Weizenbaum Insititute in Berlin for facilitating thoughtful discussions and providing extremely helpful feedback throughout this project. This post was written by Ariana Gamarra, Yashvardhan Sharma, and Robayet Hossain after our SPAR project ended, with research contributions from Jerry Lin as well during the research stages.
References
Anderljung, M., Barnhart, J., Korinek, A., Leung, J., O’Keefe, C., Whittlestone, J., Avin, S., Brundage, M., Bullock, J., Cass-Beggs, D., Chang, B., Collins, T., Fist, T., Hadfield, G., Hayes, A., Ho, L., Hooker, S., Horvitz, E., Kolt, N., & Schuett, J. (2023). Frontier AI Regulation: Managing Emerging Risks to Public Safety. ArXiv.org. https://arxiv.org/abs/2307.03718
Anthropic. (2023, October 5). Decomposing Language Models Into Understandable Components. Anthropic. https://www.anthropic.com/news/decomposing-language-models-into-understandable-components?utm_source=substack&utm_medium=email
Caversan, F. (2023, June 20). Making Sense Of The Chatter: The Rapid Growth Of Large Language Models. Forbes. https://www.forbes.com/sites/forbestechcouncil/2023/06/20/making-sense-of-the-chatter-the-rapid-growth-of-large-language-models/?sh=b69acbb56b33
Gallegos, I. O., Rossi, R. A., Barrow, J., Tanjim, M. M., Kim, S., Dernoncourt, F., ... & Ahmed, N. K. (2023). Bias and fairness in large language models: A survey. arXiv preprint arXiv:2309.00770
Gupta, S., Shrivastava, V., Deshpande, A., Kalyan, A., Clark, P., Sabharwal, A., & Khot, T. (2023). Bias runs deep: Implicit reasoning biases in persona-assigned llms. arXiv preprint arXiv:2311.04892
Hartmann, J., Schwenzow, J., & Witte, M. (2023). The political ideology of conversational AI: Converging evidence on ChatGPT's pro-environmental, left-libertarian orientation. arXiv preprint arXiv:2301.01768.
He, Z., Guo, S., Rao, A., & Lerman, K. (2023). Inducing political bias allows language models anticipate partisan reactions to controversies. arXiv preprint arXiv:2311.09687.
Jenny, D. F., Billeter, Y., Sachan, M., Schölkopf, B., & Jin, Z. (2023). Navigating the ocean of biases: Political bias attribution in language models via causal structures. arXiv preprint arXiv:2311.08605.
Liang, P., Bommasani, R., Lee, T., Tsipras, D., Soylu, D., Yasunaga, M., ... & Koreeda, Y. (2022). Holistic evaluation of language models. arXiv preprint arXiv:2211.09110.
Liu, R., Jia, C., Wei, J., Xu, G., Wang, L., & Vosoughi, S. (2021, May). Mitigating political bias in language models through reinforced calibration. In Proceedings of the AAAI Conference on Artificial Intelligence (Vol. 35, No. 17, pp. 14857-14866).
Santurkar, S., Durmus, E., Ladhak, F., Lee, C., Liang, P., & Hashimoto, T. (2023). Whose opinions do language models reflect?. arXiv preprint arXiv:2303.17548.
Motoki, F., Pinho Neto, V., & Rodrigues, V. (2023). More human than human: Measuring ChatGPT political bias. Public Choice, 1-21.
Urman, A., & Makhortykh, M. (2023). The Silence of the LLMs: Cross-Lingual Analysis of Political Bias and False Information Prevalence in ChatGPT, Google Bard, and Bing Chat.
0 comments
Comments sorted by top scores.