CyberEconomy. The Limits to Growth
post by Timur Sadekov (timur-sadekov), Aleksei Vostriakov (alexey-vostryakov) · 2025-02-16T21:02:34.040Z · LW · GW · 0 commentsContents
TLDR:
Toxic content. Artificial intelligence agents are eroding truth on the Internet
The breakdown of connectivity. The decay of global trust
The hallucination loop. Neural networks on the way to collapse
The key to unity. Digital certificate of trust
Ecosystem of trust for DAO
None
No comments
In the modern world, the digital cyber economy is becoming an integral part of the global economy, transforming the way we do business, interact and share information. With the development of technologies such as artificial intelligence and neural networks, new horizons for innovation and process optimization are opening up. However, with these opportunities come serious challenges, among which one of the most pressing issues is the falsification of digital information. Neural networks, with their ability to generate convincing texts, images and even videos that are becoming more and more realistic every day even for experts, threaten the validity of data, the credibility of digital resources and the reputation of decision makers.

If we understand the importance of the cyber economy and its future impact on society, we must find ways to solve the problems associated with information manipulation to ensure security and transparency in the digital space.
TLDR:
I would like to warn the reader that what follows is a very large text consisting of five parts linked by a certain logic. Ideally, each of these parts should have been published as a separate article, but then, unfortunately, the logic of the problem statement and the argumentation of the proposed solution are broken. Each problem on its own seems either irrelevant or you get the impression that there is no solution. But I would hope that if you take the time necessary to read this text carefully, you will end up with a comprehensive understanding of the problem statement and the potential of the proposed solution.
A summary of each chapter:
1. Overwhelming the Internet with disinformation as a result of the advancement of malicious artificial intelligence agents designed by fraudsters to falsify all types of content.
2. Loss of humanity's ability to global cooperation for common goals, because mutual trust between people is fundamentally limited by the number of personal connections of each person.
3. Collapse of neural networks due to cross-training of LLMs on internet falsifications and their own hallucinations and as a consequence the inevitable degradation of the knowledge of the people who apply them.
4. Solving global problems requires the combined efforts of all humanity, but a decentralized cyber economy requires a digital certificate of trust to function.
5. The project of trust ecosystem for decentralized autonomous organizations based on the algorithm of veracity of information and reputation rating of its authors.
Toxic content. Artificial intelligence agents are eroding truth on the Internet
Modern economics and social relations are becoming increasingly cybernetic. New cryptocurrencies, smart contracts and decentralized organizations are appearing before our eyes, offering fundamental advantages in competition with global corporations due to cross-border jurisdiction, speed of transactions, scalability and access to the best resources in the most profitable regions of the world. But let's look at the core of the problem — there is a huge number of fakes on the Internet, which makes it more and more difficult every day to distinguish truth from falsification, and artificial content created by neural networks overflows information resources and becomes more and more realistic and soon will be indistinguishable from the real one.
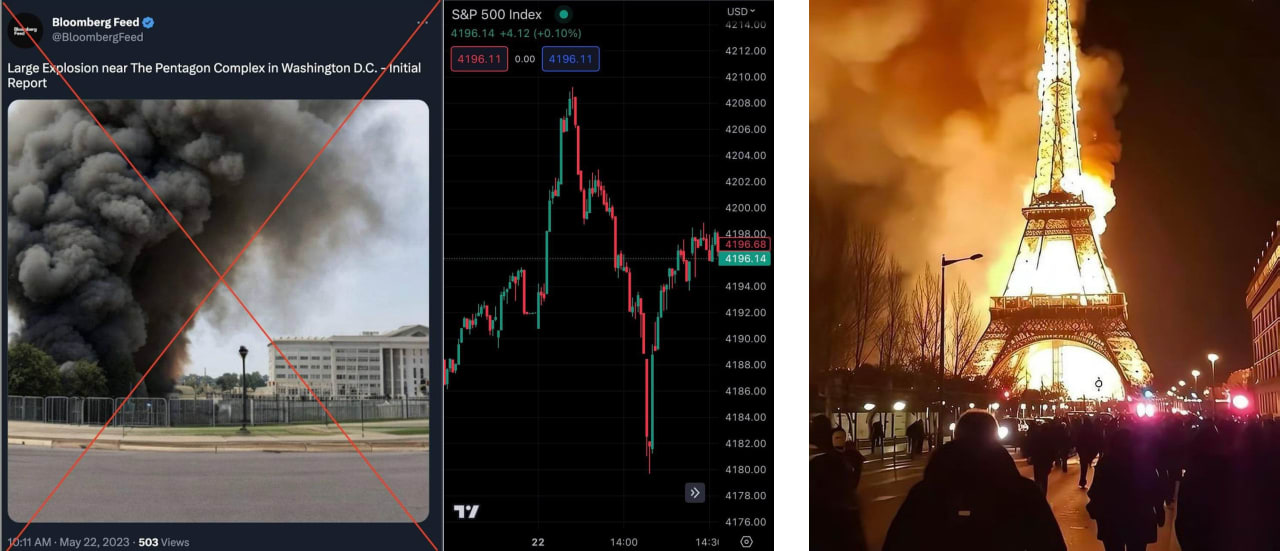
This is a global problem. In the increasing amount of information, it is increasingly difficult to distinguish truth from falsification. And we don't have the tools to confirm the veracity of statements and to distinguish reliable information from fakes for a wide audience.
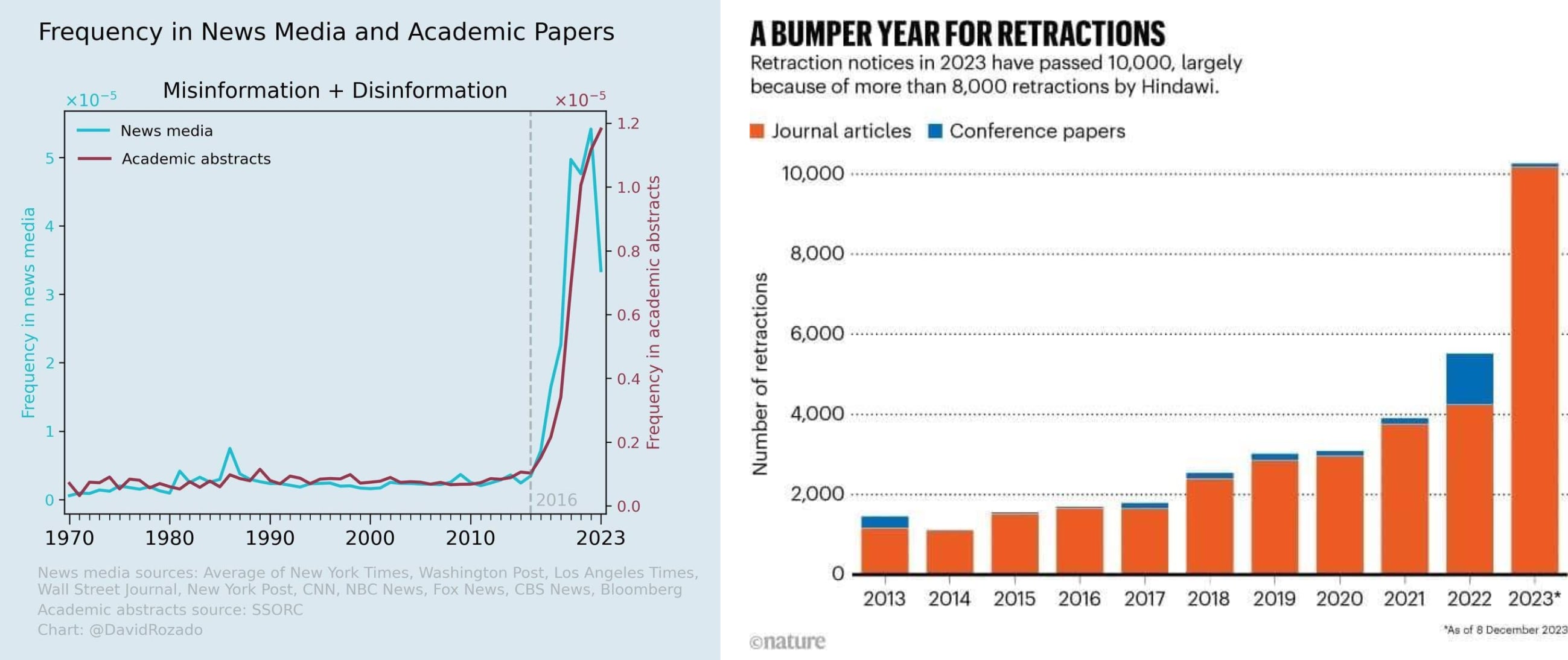
Even peer reviewed scientific journals have experienced a flood of falsifications. And even in trusted sources of information such as Wikipedia, authors are often under pressure from administrators to promote biased opinions, even though the qualifications of the administrators are often unknown and numerical criteria for calculating scientometric indicators of reputation and veracity are simply not available.

And economics is one of the games that people play. And according to game theory there are three possible results of this game: with positive, negative or zero sum.
If people buy cryptocurrency with fiat money or exchange one crypto for another on an auction, it's a buy/sell zero-sum game. If scammers cheat the ignorant — it is a negative sum game. And the surplus value in the economy is created only in the process of production of goods and services. And crypto is the lifeblood of cybereconomics. Without cybereconomics, crypto is needed for almost nothing except speculation or rare cross-border transactions. The cyber economy is composed of decentralized organizations. Decentralized organizations are composed of people. People want to earn crypto. So crypto is a technical tool that allows us to achieve our goals in the cyber economy and build new communities.
And as Steve Jobs said — “Big things are not done by one person, they are done by big teams”. Big organizations achieve big goals and make big money. And decentralized finance is a tool for functioning of decentralized organizations. So the growth of cryptocurrencies is clearly linked to the growth and development of decentralized organizations. And if we want to make big profits in the cyber economy, we must build and create large decentralized organizations.
And that's where we have a big problem.
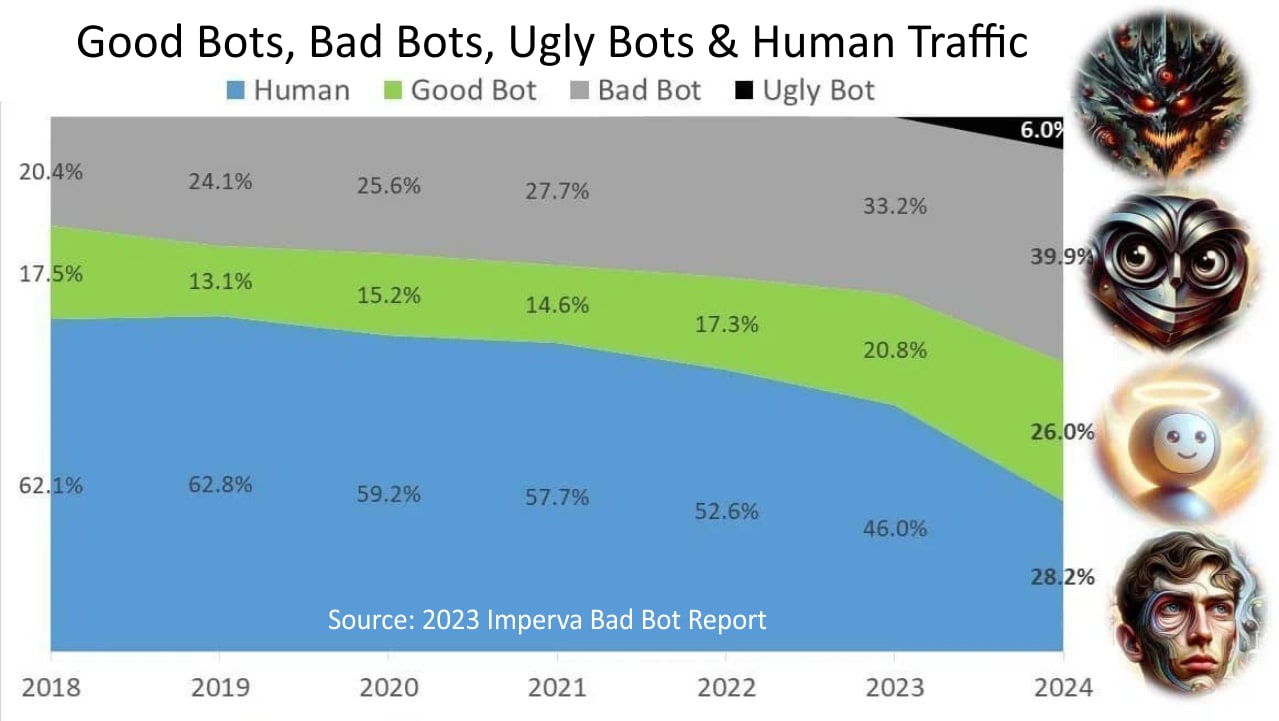
As a result of the development of artificial intelligence technologies, the amount of traffic generated by artificial agents on the network is growing rapidly. Already in the past 2024, almost half of the traffic was generated by fraudsters. This year there were already more than 1200 news information channels generated entirely by neural networks without human participation. At the same time, the content in such news channels is amazingly high-quality and diverse — from cooking recipes and health recommendations to legal advices and investment strategies. Everything is generated in a very exciting and believable way with one exception — there is not a single word of truth there at all. The only purpose of existence of such channels is to attract users to show them targeted advertising. And the responsibility for their money and health each person bears himself.

It's only going to get worse. We have no more than a year until maleficent neural networks will deliberately mislead us. Everyone knows what Kali Linux is, but in the near future we will have to face KaliGPT and JihadGPT. And existing protection methods will not be adequate.
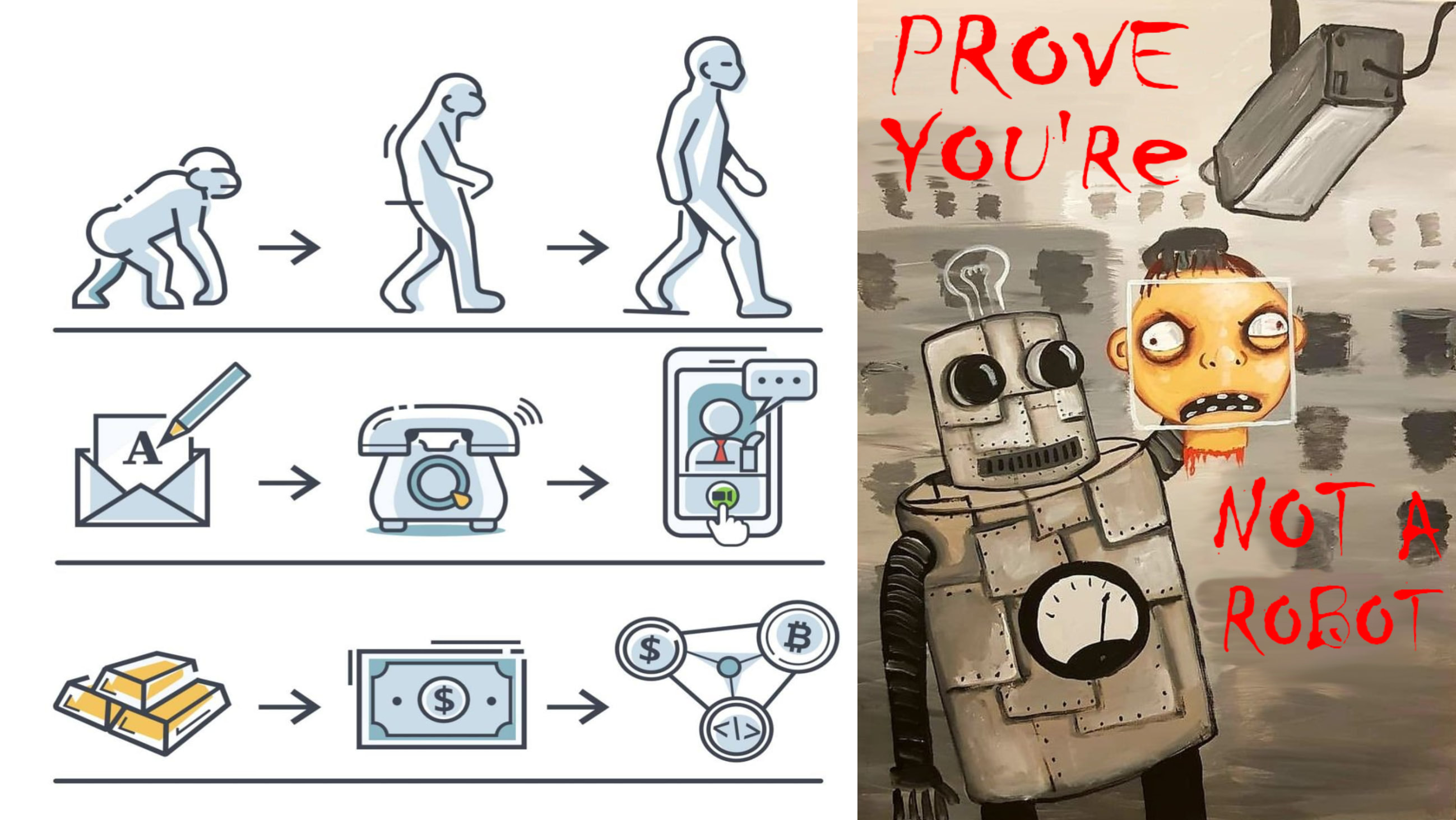
Many people are still hoping for KYC methodology to verify documents and confirm identity, but this is very naive. Artificial Intelligence agents will hire beggars to get an “I am not a robot” certificate. There are already such examples. Recently, a neural network has already hired a person on a freelance website to pass a captcha, and in the summer in France, the CEO's deepfake called the company's chief accountant by zoom and convinced her to transfer all the money to an offshore account under a fake contract. And it is even more naive to hope that one fake-generating neural network will validate another fake-generating algorithm. On the contrary, they will learn and improve from each other in falsifying all kinds of content. This is a stalemate and the basis of a potential catastrophe in the information world.
Some experts on artificial intelligence suggest that in the near future no one will be able to verify the veracity of a fact among many convincing generations without investing $10,000 to verify it. This is approximately equal to a week of work for a large factchecking department in a large publishing house.

Scammers, bots and trolls will infiltrate decentralized organizations to steal crypto from people. And decentralized organizations will die when scammers, bots and trolls infiltrate them. Since people don't understand how to distinguish a decent person from a bot or troll — no one will be able to trust the cyber economy, and crypto won't grow. It's a stalemate. Welcome to hell.
The breakdown of connectivity. The decay of global trust
In my opinion this stalemate scuttles all of humanity's ability to cooperate for common goals.
Without digital technology, we are like a caveman, and without a digital certificate of trust, we have to trust only personal connections. And the number of such connections is fundamentally limited by the Dunbar’s number, the cognitive limit to the group of people with whom one can maintain stable social relationships — relationships in which one knows who each person is and how each participant relates to each other.

According to various sources, the Dunbar’s number in human communities ranges from 100 to 230, most often it is conventionally taken to be 150. And even existing methods of identity verification have very little effect on this. The Dunbar’s circle expands, but only slightly. Conditionally, with 150 participants it is possible to reach 500 and no more. It's a stalemate again. Trust is eroding. It's unclear who's out there beyond the horizon of your personal acquaintances. It is clear only that there are probably fraudsters there, but who???
And when fraudsters start using advanced neural networks for scamming, the chances of solving this problem will rapidly slip to zero. Once the digital superiority of neural networks over the smartest human has been achieved, no one else is capable of it. The evolution speed of neural networks is now 3 million times faster than that of humans and humans are no longer the smartest species on the Earth. And the ability of neural networks to speak to humans in their own language and at the same time say exactly what they want to hear from them breaks through psychological defense barriers and opens grandiose opportunities for social engineering for fraudsters.
This is a global problem. There is a huge number of fakes on the Internet, artificial content created in enormous amounts by neural networks is becoming more and more realistic and will soon be indistinguishable from the real one, factchecking is becoming more and more expensive every day and in the increasing amount of information it is more and more difficult to distinguish truth from falsification, but we do not have the tools to check the veracity and filter truth from lies. Internet users around the world are confused and disoriented, many say they don't know where the truth is, society is polarized, all this causes a crisis of trust and limits the development of decentralized organizations.
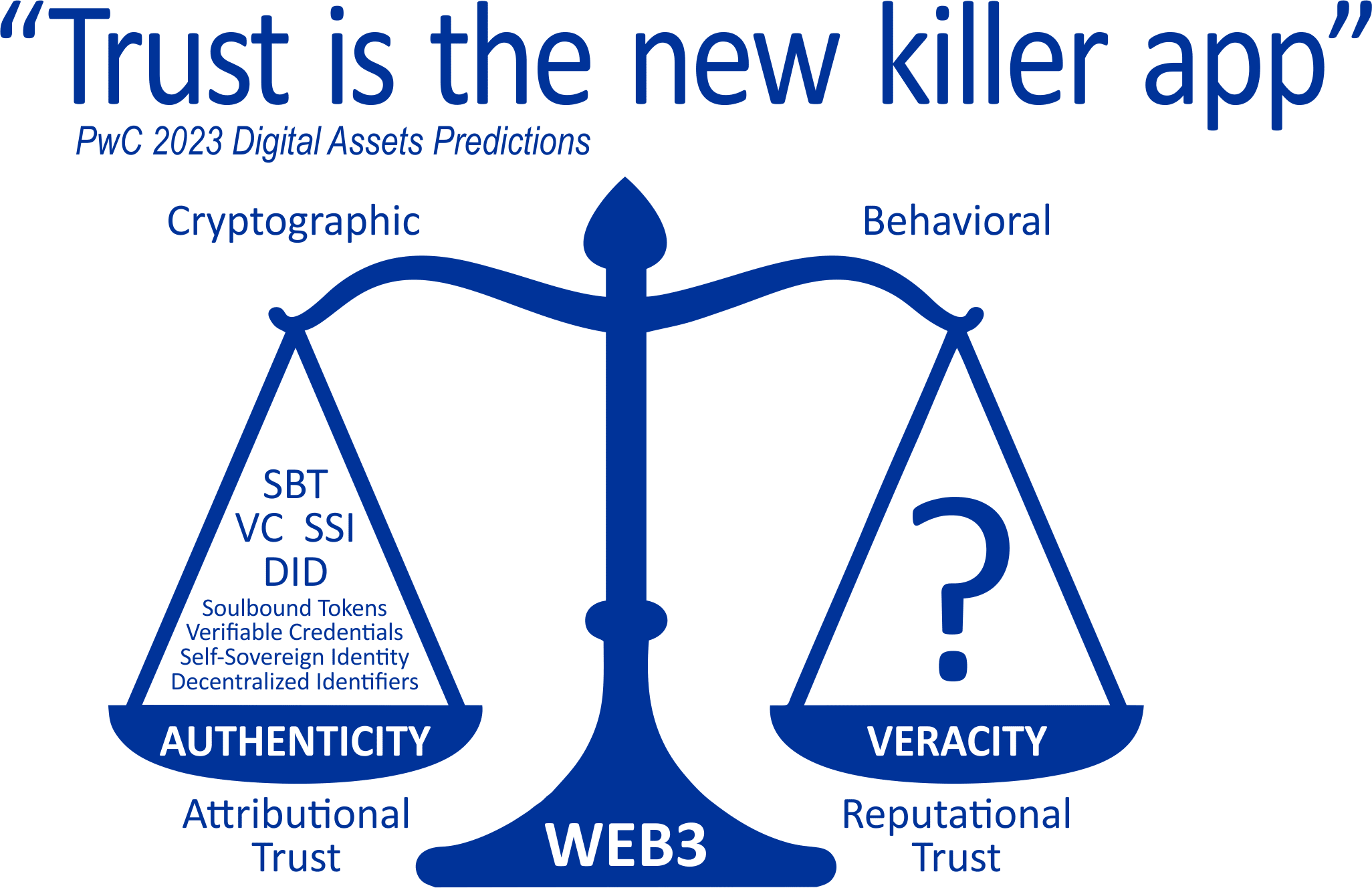
The balance of trust in society is broken and existing cryptographic technologies protect both ordinary users and fraudsters equally well, who, thanks to anonymous decentralized and cryptographically protected accounts, become completely indistinguishable in the digital information space and can inflict harm by actively using falsification technologies with the help of neural networks.
The hallucination loop. Neural networks on the way to collapse
At the same time, one of the world's leading experts on information security systems, Professor Ross Anderson from the University of Cambridge, in his article is already considering a scenario where most of the Internet will be a neural network-generated hallucination. But neither you, nor me, nor any expert or anyone at all will be able to distinguish fake from reality. As a result, neural networks will degenerate in the process of learning from their own hallucinations of the Internet, and humans will degenerate in the process of applying the degenerated neural networks. This process he called “neural network collapse.”

Nick St. Pierre (creative director and unofficial spokesperson for Midjourney) says that the first results of infection a year and a half after the start of the generative artificial intelligence trials are already striking in their scale. Everything is already infected, because no one expected such a high rate of infection and did not take into account the multiplier — infection from already infected content.
In addition, back in February of last year, a fundamental paper by Michael Levin was published with a mathematical proof of the theorem and its three corollaries about the confabulatory nature of consciousness in humans and any other intelligent systems. Confabulation refers to the process of filling in gaps in memory with made-up stories or facts that a person believes to be true, even if they are not true. It is not necessarily a conscious process, and the person creating confabulations may genuinely believe them to be true. A corollary of the theorem is a mathematical proof of the fundamental unavoidability of hallucinations of large linguistic models and the inoperability of centralized systems.

The fundamental implications of this work are hard to even imagine. The authors believe that it will lead to a revision of even fundamental questions of personal identity and the meaning of life. And in my opinion it can be considered mathematically proven that practically no tasks and problems facing humanity will be solved without creating a system of collective intelligence and mutual unbiased and objective verification of information for consistency and noncontradiction.
I am a proponent of the hypothesis that superintelligence should be born from the synergy of artificial intelligence, which has a gigantic erudition and trend awareness, with the collective intelligence of real live human experts with real knowledge and experience.
Yann LeCun has a great quote in his article: “Large language models (LLMs) seem to possess a surprisingly large amount of background knowledge extracted from written text. But much of human common-sense knowledge is not represented in any text and results from our interaction with the physical world. Because LLMs have no direct experience with an underlying reality, the type of common-sense knowledge they exhibit is very shallow and can be disconnected from reality”.
LeCun writes about the tricks that can be used to try to teach the LLM common sense about the world, but this is still far from the question of validity, because even if these tricks lead to results, there is still the question of whether the common sense database is valid.
At the moment, all LLM developers claim that their datasets are reliable, but this is obviously not the case, as they have been found to be fake on more than one occasion, and the developers themselves have no criterion for the veracity of the information at all.
The position “my dataset or ontology is trustworthy because it's mine” cannot be the basis of trustworthiness. So the future for me personally is quite simple and is determined by the following logic:
1. The hallucinations and confabulations of artificial intelligence are fundamentally unrecoverable https://www.mdpi.com/1099-4300/26/3/194
2. Cross-training LLMs on each other's hallucinations inevitably leads to “neural network collapse” and degradation of the knowledge of the people who apply them https://arxiv.org/abs/2305.17493v2 and https://gradual-disempowerment.ai
3. Any physical activity in the real world is connected to the physics of the entire universe, and sometimes the slightest mistake in understanding these interrelationships is fatal. A million examples can be seen in industrial safety videos. That is why any hallucination of artificial intelligence without reliance on the real experience of real people with real knowledge of the world will end in mistakes and losses of varying degrees for the humans, up to catastrophic.
Hence the conclusion — people have the main responsibility to connect with reality. And the more complex will be the questions that will be solved by neural networks, the more serious will be the human responsibility for timely detection of more and more subtle and elusive hallucinations. This requires people with the deepest knowledge, and not the knowledge memorized under pressure at school, but with real experience on almost any issue.
How many tasks neural networks will have, there should be so many superprofessionals on these tasks. And for the superprofessionals, you just need ordinary professionals and assistant professionals and students of assistant professionals.
And for all this we need a rating of reliability of knowledge to know who is a professional and who is not a professional.
And without information veracity criterion and knowledge validity rating any LLM (and in general any artificial system according to Michael Levin's proof) will face imminent collapse.
Only the collective neural network of all the minds of humanity can be opposed to artificial intelligence. For mutual verification and improvement of large language models and humans, we need the ability to compare the knowledge of artificial intelligence with collective intelligence. This is the only thing that can get us out of the personal tunnels of reality and personal information bubbles in which we are getting deeper and deeper stuck individually.
The key to unity. Digital certificate of trust
Conceptually, the problem of falsification is described by the ABC model of web3 projects Actors-Behavior-Content, proposed by analysts from the team of Kai-Fu Lee — Chinese guru of artificial intelligence. According to this model, falsification is actually three very complex problems that need to be solved only together at once, because if there is a discrepancy somewhere, fraudsters will definitely get into it sooner or later.
This is a very complex problem. There is a lot of work to be done to overcome it all. No one can cope here alone, and serious coordination is needed. And we need to start with a theoretical study of interaction in order to understand who can support and insure whom with what data and checks. Alone, everyone will lose. Fraudsters now have neural networks for this purpose, which are ready to falsify anything.
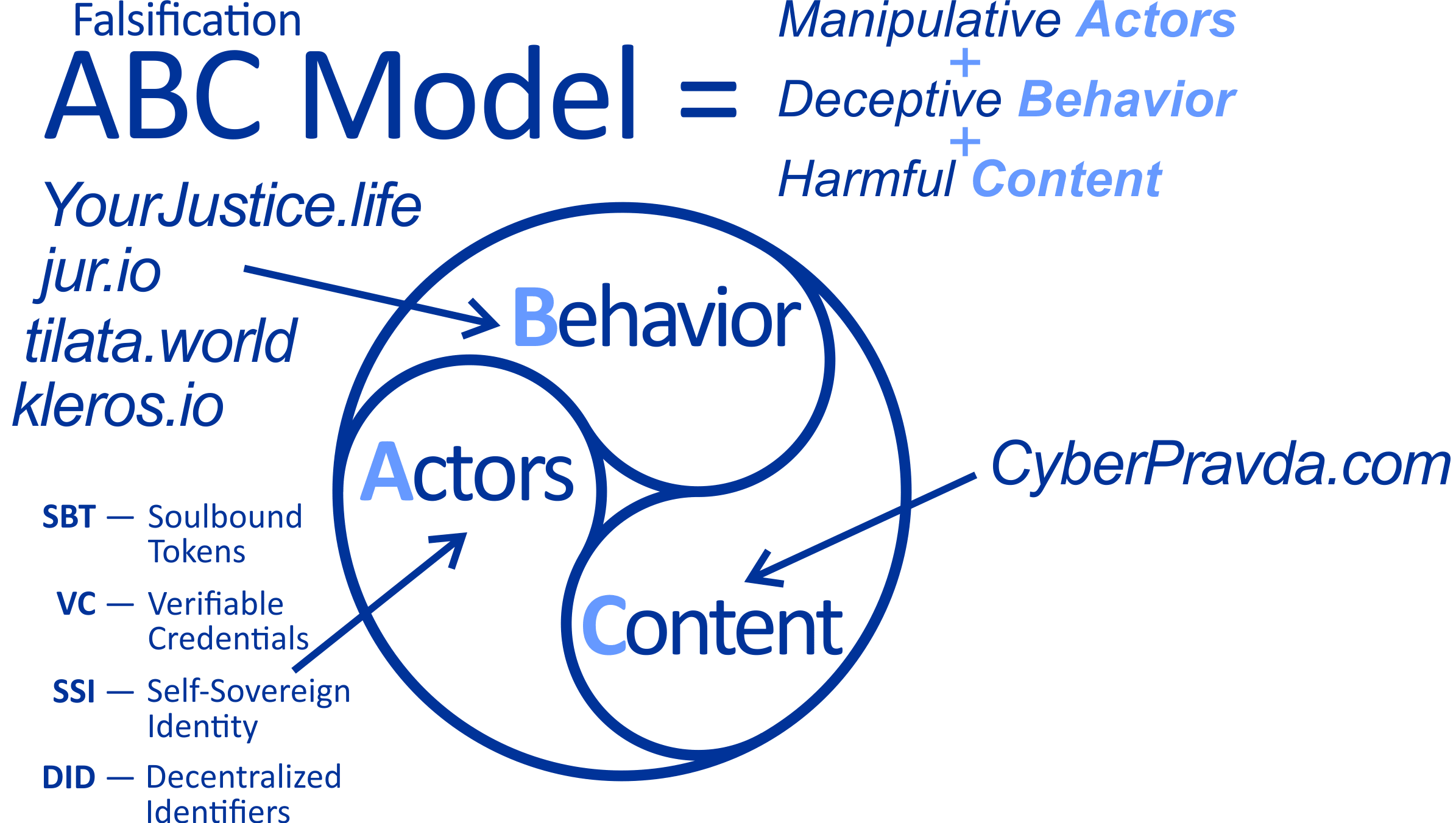
But if all three challenges are overcome and combined, then the digital cyber economy gains strength and global collaboration becomes a reality!
Decentralized organizations will be able to equal the size of global transnational corporations, and crypto, instead of speculation or occasional enthusiast exchanges and rare cross-border transactions, will become the lifeblood of the cyber-economy and begin to create real surplus value for genuine, not speculative, capitalization growth!
Then we can build a system of economic relations based on reliable knowledge and responsible executors with real reputation, in which candidates for leadership positions develop investment strategies, and their calculations and plans undergo comprehensive validation in open fair competition with other candidates, and an unbiased and objective algorithm assigns their authors a reputation rating. Candidates whose plans and strategies have the highest credibility ratings are empowered to make decisions, and the achievement of their goals is confirmed in decentralized arbitration services, which becomes facts for arguing new strategies, and the cycle closes, becoming self-sustaining and self-organizing.
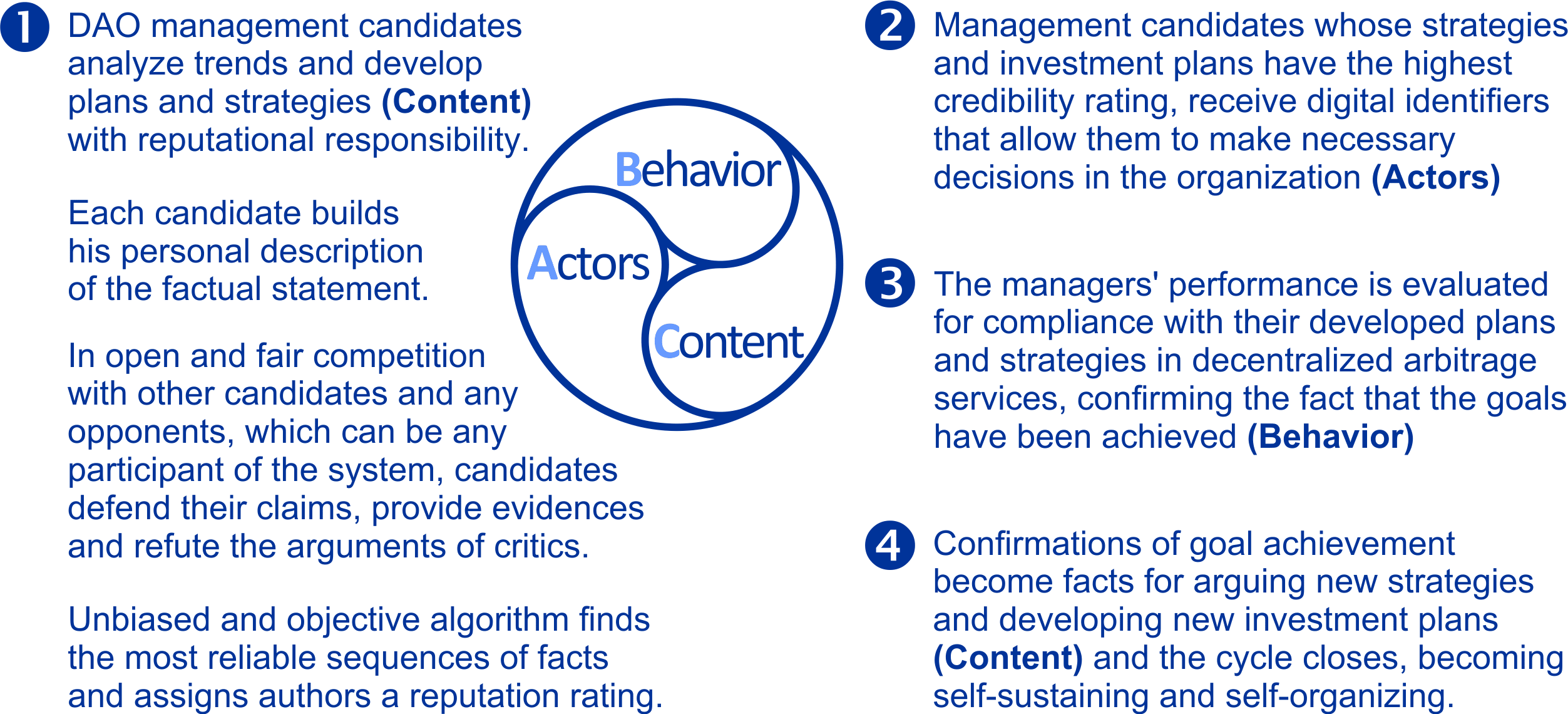
I strongly believe that reputation and trust are based on people saying what they do and doing what they say, so a key element for this whole scheme to work is the need for an independent system to objectively and unbiasedly verify the veracity of information and compare any existing opinions for mutual consistency and noncontradiction. We need a factchecking solution that can counter existing technologies of falsification and misinformation.
And such a system must satisfy to the highest principles of scientific honesty:
— the system must be completely independent of admins, biased experts, special content curators, oracles, certificates of states and corporations, hallucinating artificial intelligence algorithms, clickbait likes/dislikes or voting tokens that can bribe any user
— the system should be global, international, multi-lingual and free of charge to be accessible for users all over the world
— the system should be unbiased to all authors and open to the publication of any opinions and hypotheses
— the system must be objective and purely mathematically evaluate all facts and arguments without exception according to the principle of "all with all" immediately the moment they were published
— the system must be decentralized and cryptographically secured insuring that even its creators have no way of influencing the veracity and reputation
— the system should be available for audit and independent verification at any time.
Content veracity is the ultimate philosophical question. In the near future, artificial intelligence will be everywhere. But Michael Levin's theorem proves that it will always have unrecoverable hallucinations and artificial intelligence will never be able to claim veracity. You can and should apply artificial intelligence in your business, but you have to be responsible for the decisions you make. And decisions can be complex and expensive. And artificial intelligence at a fundamental level cannot justify and guarantee the reliability of its generations.
Experts know of hundreds of projects that have tried to determine veracity using various methods of authoritarian administration of content, using hallucinating artificial intelligence algorithms or voting tokens that allow to bribe any user, but since 2018, experts have recognized that all these approaches are biased, falsifiable and have failed themselves.
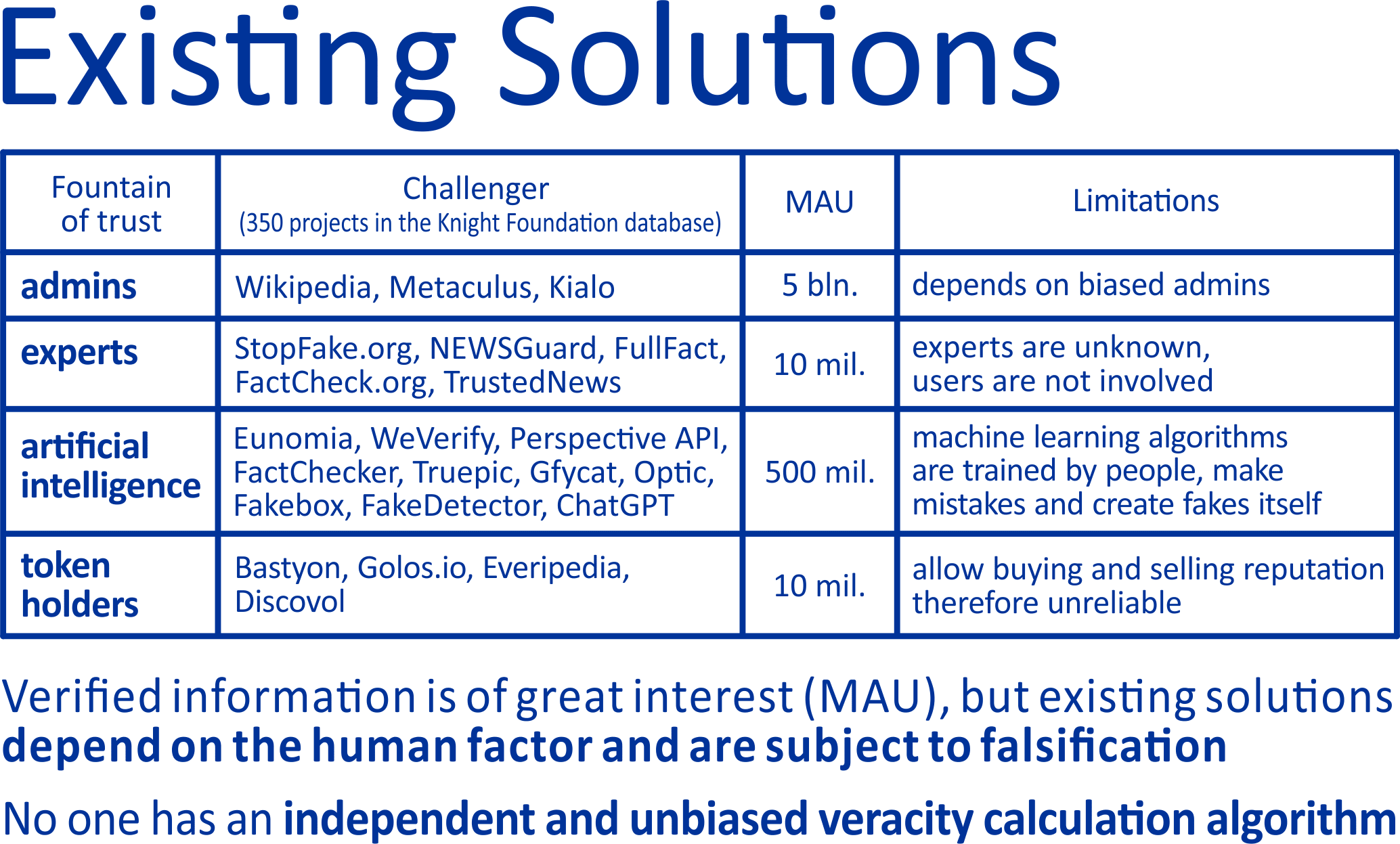
All this is aggravated by the fact that all factchecking in information technologies is now based solely on the principle of verification (i.e. confirmation). But this approach becomes unacceptable in modern conditions after the superiority of artificial intelligence over humans and should be fundamentally replaced by the principle of falsifiability. It means that the verification of the meaningfulness and then the veracity of hypotheses should be carried out not through the search for facts that confirm them, but mainly (or even exclusively) through the search for facts that refute them. This approach is fundamental in the scientific world, but for some unknown reason it has not been implemented anywhere in information technologies until today.

So I now want to tell you about the project that first proposed an algorithm that implements Popper's falsifiability criterion for this purpose.
Ecosystem of trust for DAO
The project's manifesto was published in 2022 and since then the project has been developed by volunteers who found a unique and very unusual combination of mathematics, psychology and game theory and developed a fundamentally new technology based on a purely mathematical algorithm that does not require external administration, certificates of states and corporations, hired experts or special content curators.
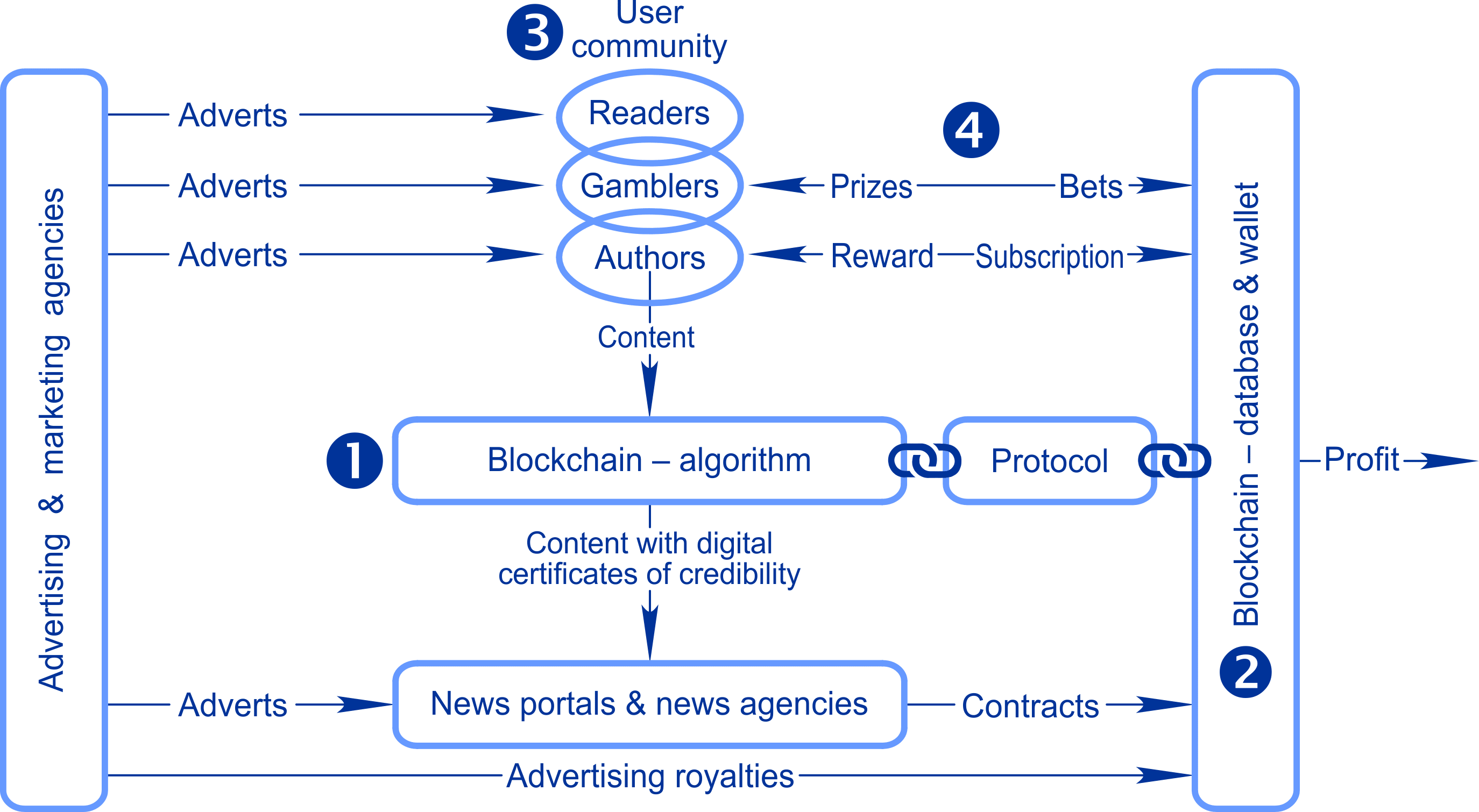
The technical solution is a discussion platform for crowdsourcing reliable information with a monetization ecosystem, game mechanics, and a graph theory based algorithm that objectively compares all existing points of view.

It is a combination of existing technologies that are guaranteed to meet all requirements of objectivity and unbiasedness:
— it is built on a blockchain with an independent mathematical algorithm for analysis of the veracity of arguments on the basis of graph theory with auto-translation of content into 109 languages
— credibility arises only from the mutual influence of at least two different competing hypotheses and does not depend on the number of proponents who defend them
— credibility arises only from the mutual competition of facts and arguments and their interactions with each other
— the only way to influence credibility in this system is to publish your personal opinion on any topic, which will be immediately checked by an unbiased mathematical algorithm for consistency with all other facts and arguments existing in the system
— each author in the system has personal reputational responsibility for the veracity of published arguments.
The algorithm allows betting on different versions of events with automatic determination of the winner and involves users in a competition to earn their own reputation, which allows to pay a premium to authors of reliable content and creates the basis for the development of new scientific socially responsible journalism.
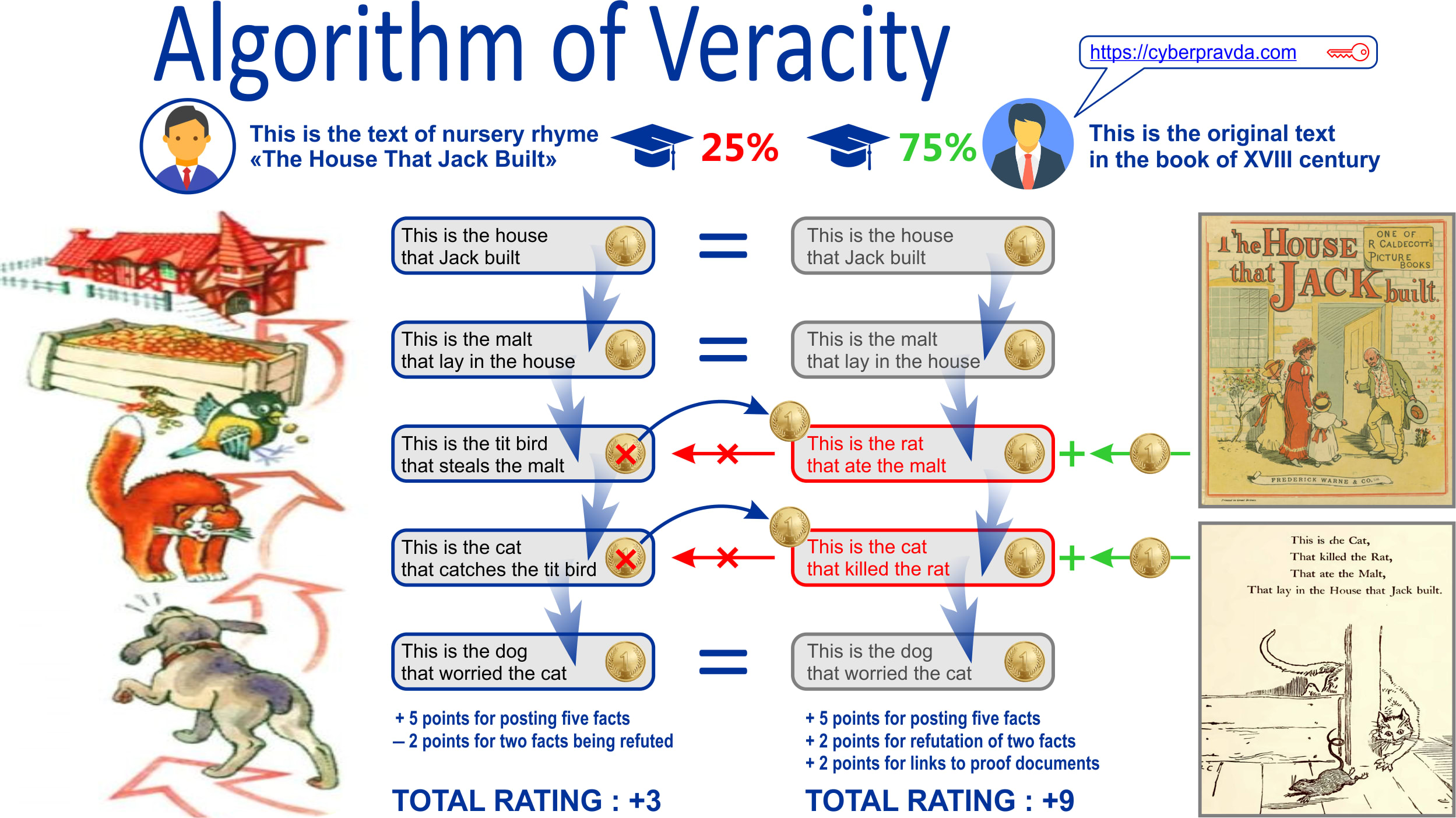
The algorithm allows for an objective and unbiased evaluation of facts and arguments from different perspectives or viewpoints. In its simplest form, it can be explained using two versions of the nursery rhyme “The House That Jack Built,” which is very similar to a blockchain. In some versions of the translation, we know about the tit bird, but it is actually an old English poem that originally had no tit bird in it. In the original text, it was a rat that ate the malt, and the cat caught that rat. And this figure shows how facts supported by evidences gain additional weight, while statements refuted by other arguments, on the contrary, lose it.
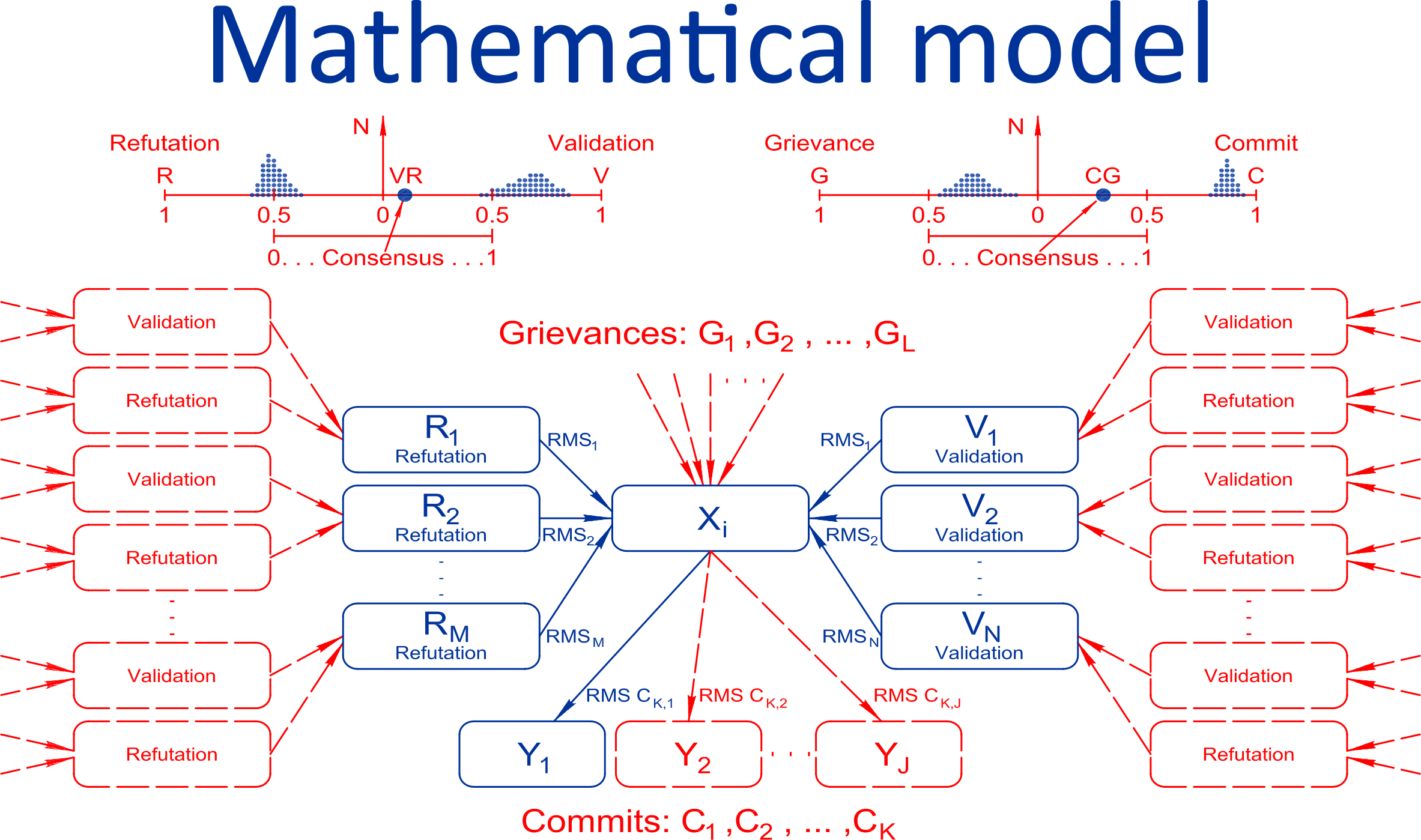
The mathematics of the system is based on the surroundings and the space of connections of any information block X, which can be connected with at least one, but in general with many other blocks Y. This pair is a realization of Noam Chomsky's concept of subject-predicate-object, according to which all narratives can be represented and analyzed in the form of their sequence.
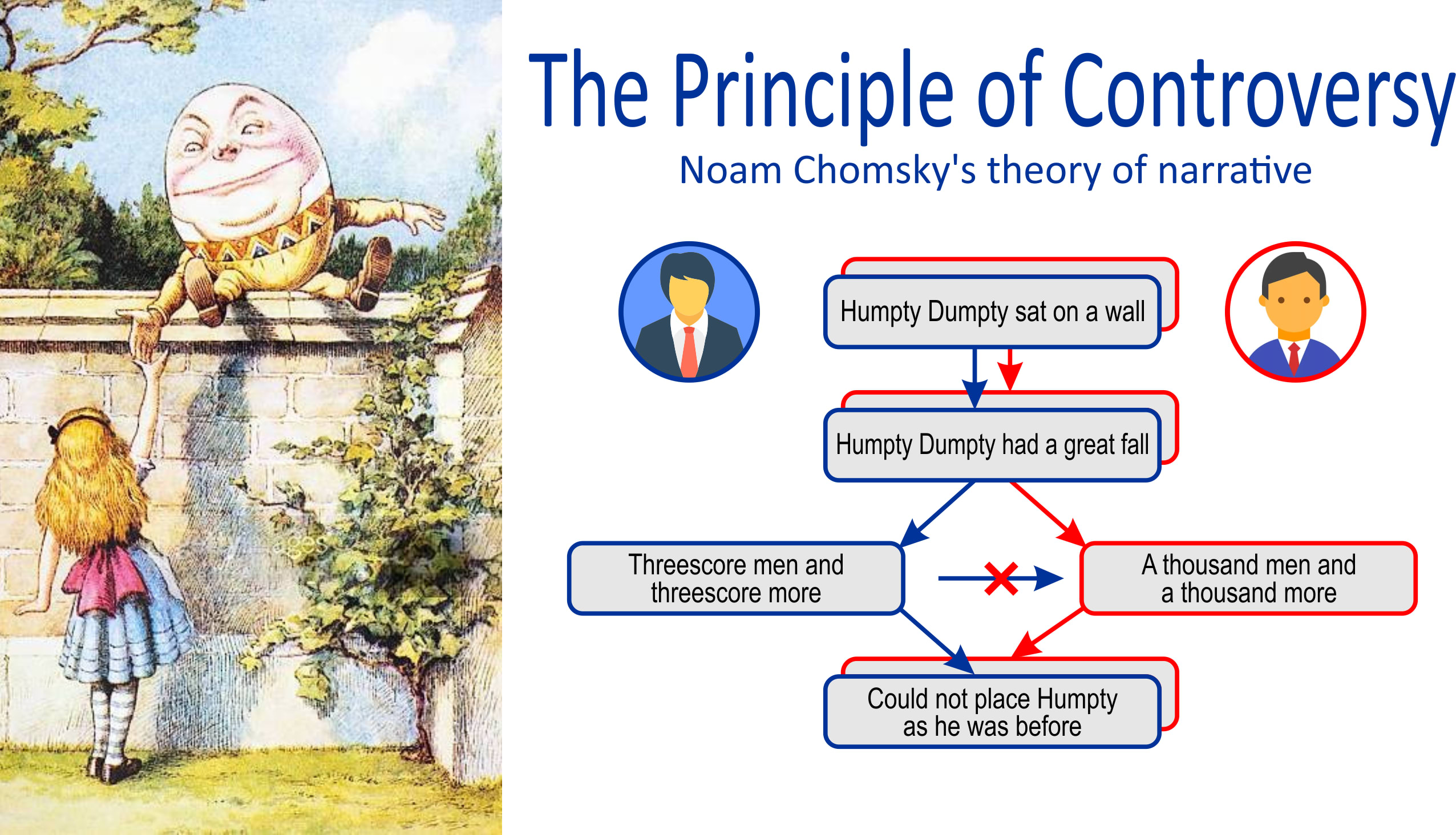
The algorithm is based on correlation analysis of graphs for mutual consistency and noncontradiction. It can be explained by such an example. There are different versions of an event: “Humpty Dumpty sat on a wall” — “Humpty Dumpty had a great fall” — “Threescore men and threescore more” — “Could not place Humpty as he was before”. Another author may see these events a little bit differently: “Humpty Dumpty sat on a wall” — “Humpty Dumpty had a great fall” — “A thousand men and a thousand more” — “Could not place Humpty as he was before”. Obviously, the information blocks “Threescore men and threescore more” and “A thousand men and a thousand more” contradict each other, which lowers the veracity of the versions of these events. At the same time, in order to determine that these information blocks contradict each other, it is not necessary to understand what exactly they contain. It is enough that the authors assumed reputational responsibility for their reliability.
Knowledge is a combination of statements and the links between them that form holistic integrally consistent chains of facts and arguments for which the scientific community stands to bear collective responsibility.
And the algorithm is based on the principle that for some facts and arguments people are willing to bear reputational responsibility, while for others they are not. The algorithm identifies these contradictions and finds holistically consistent chains of scientific knowledge. And these are not likes or dislikes, which can be manipulated, and not votes, which can be falsified. Each author publishes his own version of events, for which he is reputationally responsible, not upvoting someone else's.
Algorithm evaluates the balance of arguments used by different authors to confirm or refute various contradictory facts to assess their credibility, in terms of consensus in large international and socially diverse groups. From these facts, the authors construct their personal descriptions of the picture of events, for the veracity of which they are held responsible by their personal reputations. An unbiased and objective purely mathematical correlation algorithm based on graph theory checks these narratives for mutual correspondence and coherence according to the principle of "all with all" and finds the most reliable sequences of facts that describe different versions of events.
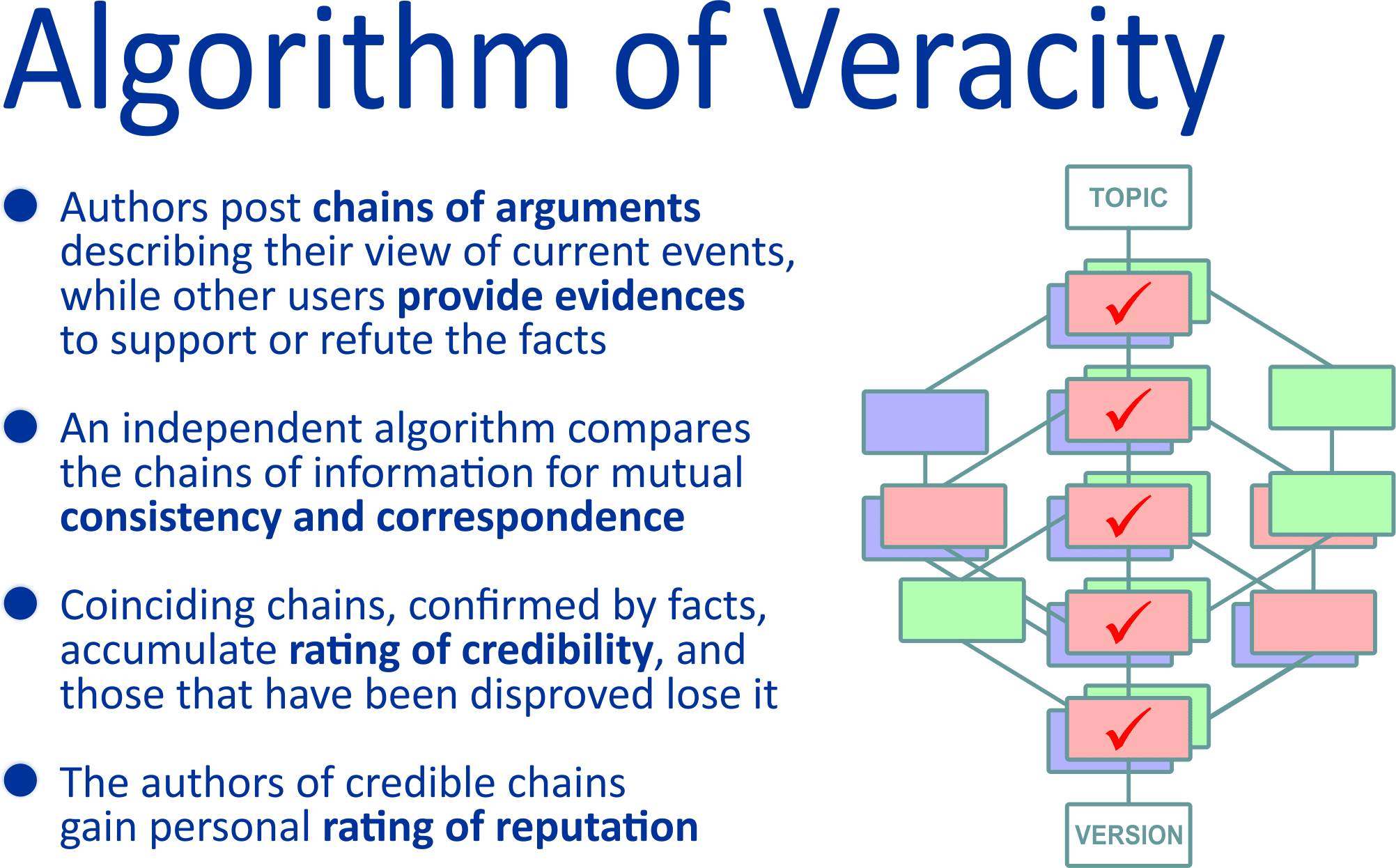
To illustrate this, we can take the simplest topic “How to make scrambled eggs?” For example, one author publishes a trivial recipe: “Heat a frying pan” — “Break eggs” — “Fry for 5 minutes”. And another author publishes some bullshit: “Take a brick” — “Throw it in the window” — “Look at the stars”. Since the initial reputation of all authors is initially equal, at this point the credibility of their statements is not obvious. Therefore, there is no credibility rating, and none of the authors earns a gain to their reputation.
However, at some moment the question starts to develop and the topic appears “How to make delicious scrambled eggs?” and someone who may have already earned a reputation rating in other topics, publishes his variant of the answer: “Heat a frying pan” — “Break eggs” — “Add bacon” — “Fry for 5 minutes”. At this moment, the first, second, and last blocks in this logical sequence gain credibility according to the reputation of the authors who consider them important for presenting their argumentation.
Gradually the question begins to develop further and, for example, the topic arises “How to make a delicious breakfast?” If someone uses a recipe of delicious scrambled eggs with bacon already existing in the system as one of the components, then the information blocks “Heat a frying pan”, “Break eggs”, “Fry for 5 minutes” acquire cumulative reliability on the basis of reputation of three authors, and the block “Add bacon” — on the basis of two opinions. At the same time, the trash blocks “Take a brick”, “Throw it in the window”, “Look at the stars” still have no veracity rating and users do not even see them, because they are under the threshold of information filtering by veracity.
At the same time, it should be noted that the veracity of the recipes themselves has not even been considered yet, because despite the increased veracity of individual blocks, the recipes themselves have no credible competing opinions from their opponents, and therefore the balance of facts and arguments cannot be established before their publication and no one of the authors earns any contribution to their reputation. To achieve this goal, alternative competing opinions must emerge that have independently accumulated their credibility through a similar process of publishing information. For example, on the topic “How to make a delicious breakfast?” alternative recipes for omelette or pancakes should appear in addition to scrambled eggs. It is impossible to predict what the balance of information blocks in these versions will be, since it is not related to the quantity of the blocks themselves, nor to the quantity of their authors, but depends solely on the mutual correlation between the opinions of different authors and their current reputation ratings accumulated over time from all publications.
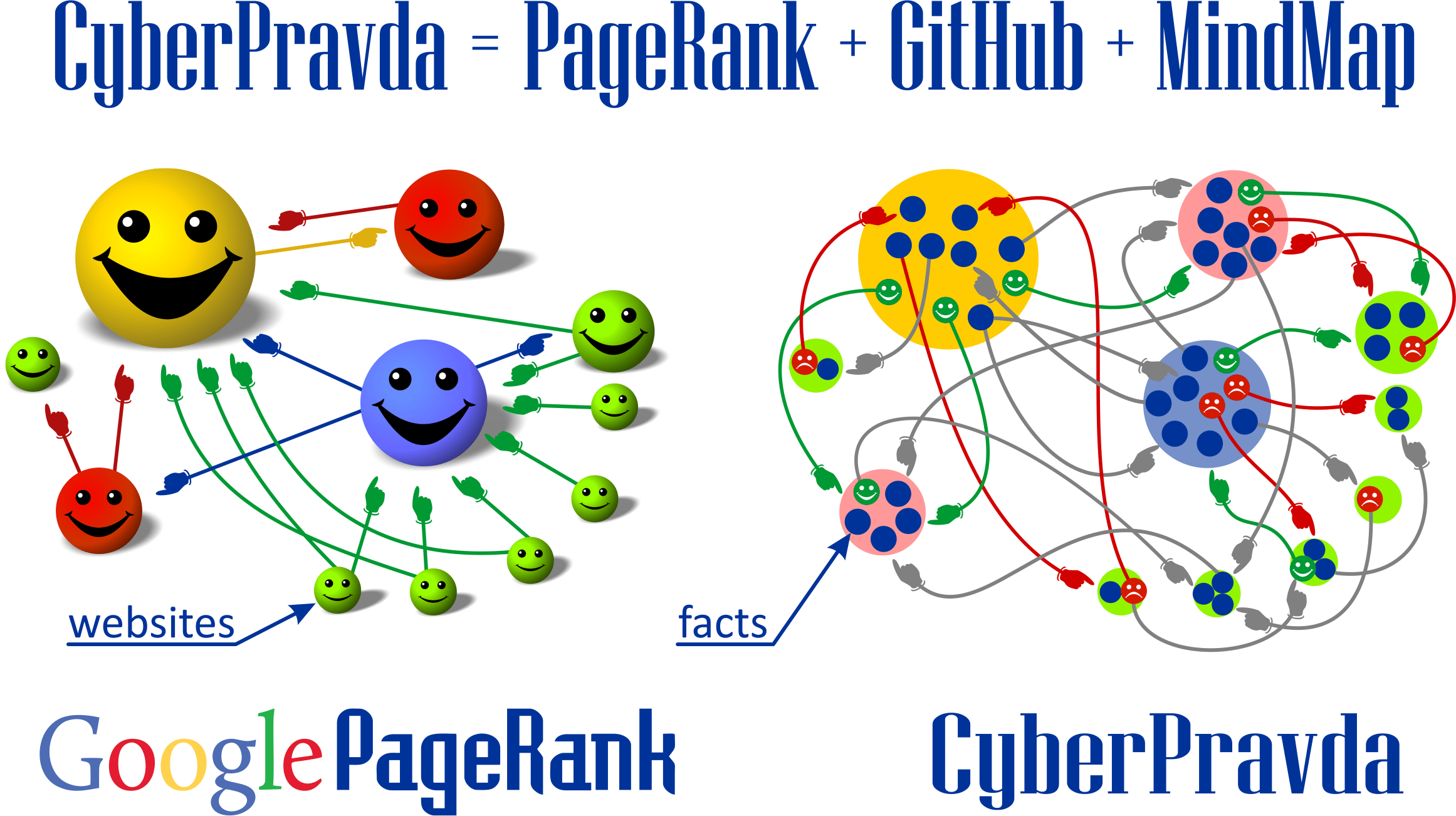
This algorithm allows to realize the principle of falsifiability, algorithmically implement Popper's criterion and obtain a more precise assessment of veracity compared to the PageRank algorithm and the Hirsch index, which analyze each site or document only in its entirety and are unable to assess the contradictions between the individual facts and arguments of which they consist.
In the global hypergraph, any information is an argument of something one and a counterargument of something else. Different versions compete with each other in terms of the value of the flow of meaning, and the most reliable versions become arguments in the chain of events for facts of higher or lower level, which loops the chain of mutual interaction of arguments and counterarguments and creates a global hypergraph of knowledge, in which the greatest flow of meaning flows through stable chains of consistent scientific knowledge that best meet the principle of falsifiability and Popper's criterion.
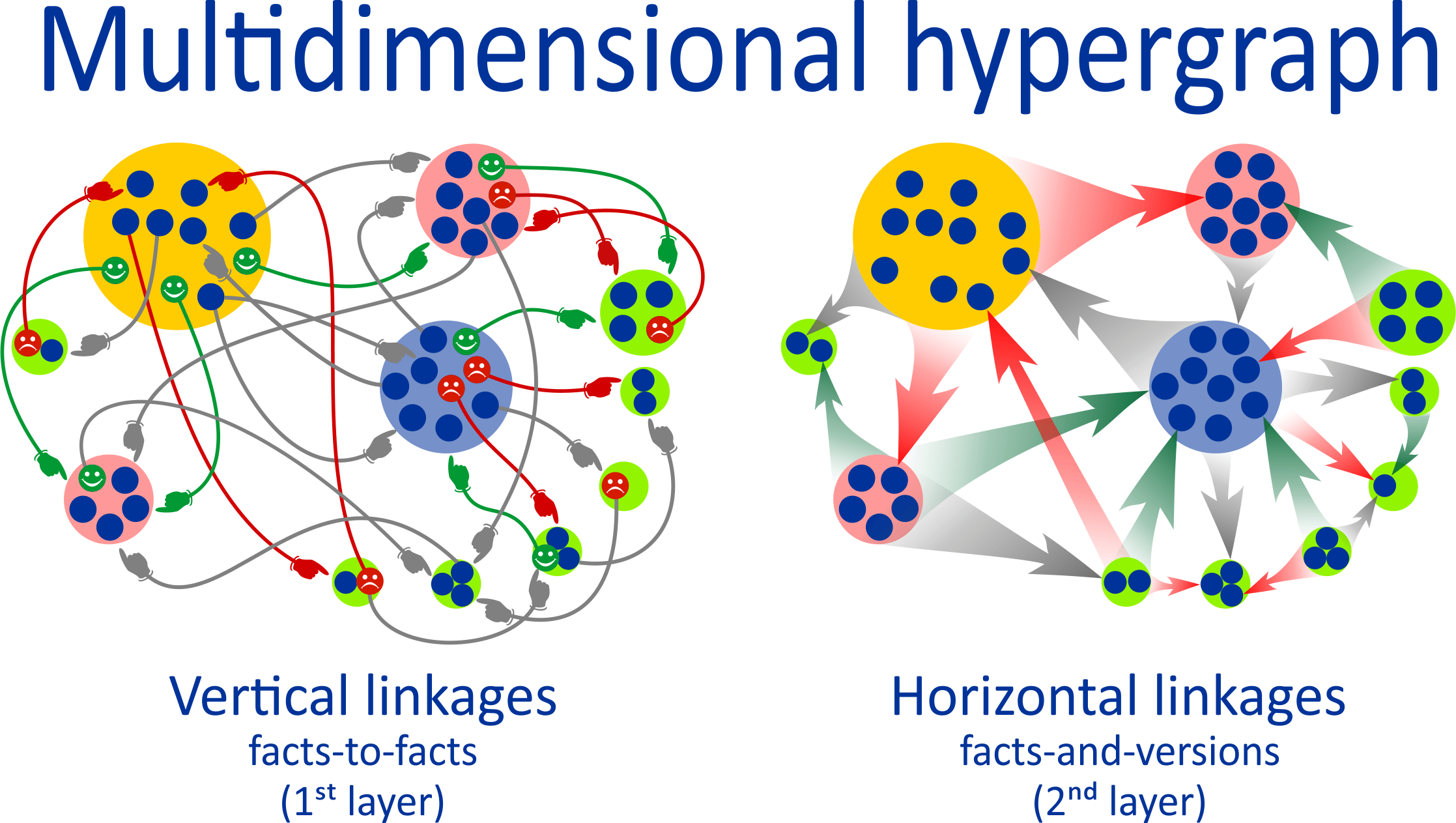
The algorithm is based on the fact that scientific knowledge is noncontradictory, while ignorames, bots and trolls, on the contrary, drown each other in a flood of contradictory arguments. The opinion of a flat Earth has a right to exist, but it is supported by only one line from the Bible, which in turn is not supported by anything, yet it fundamentally contradicts all the knowledge contained in textbooks of physics, chemistry, math, biology, history and millions of others.

The game theory of the system is based on the fact that in accordance with their ethical principles, scientists defend only the scientific version of each controversial topic, while trolls and hackers try to do harm and in accordance with their counter strategy deliberately refute scientific knowledge and prove all other versions except the scientific one. At the same time the rest of the users have lack of quality knowledge, fluctuate between different points of view and periodically confirm/refute one version or the other. Since ignorames and bots do not have a shared collective coordination system for mutual verification and identification of reliable knowledge, similar to the one that exists in the global scientific community and international education system, ignorames, bots and trolls inevitably come into conflict with each other on issues of different viewpoints on versions of events, and as a result, scientific versions, which are jointly defended by the scientific community, get a strategic advantage over chaotic contradictory viewpoints and fakes, mutually disproving each other.
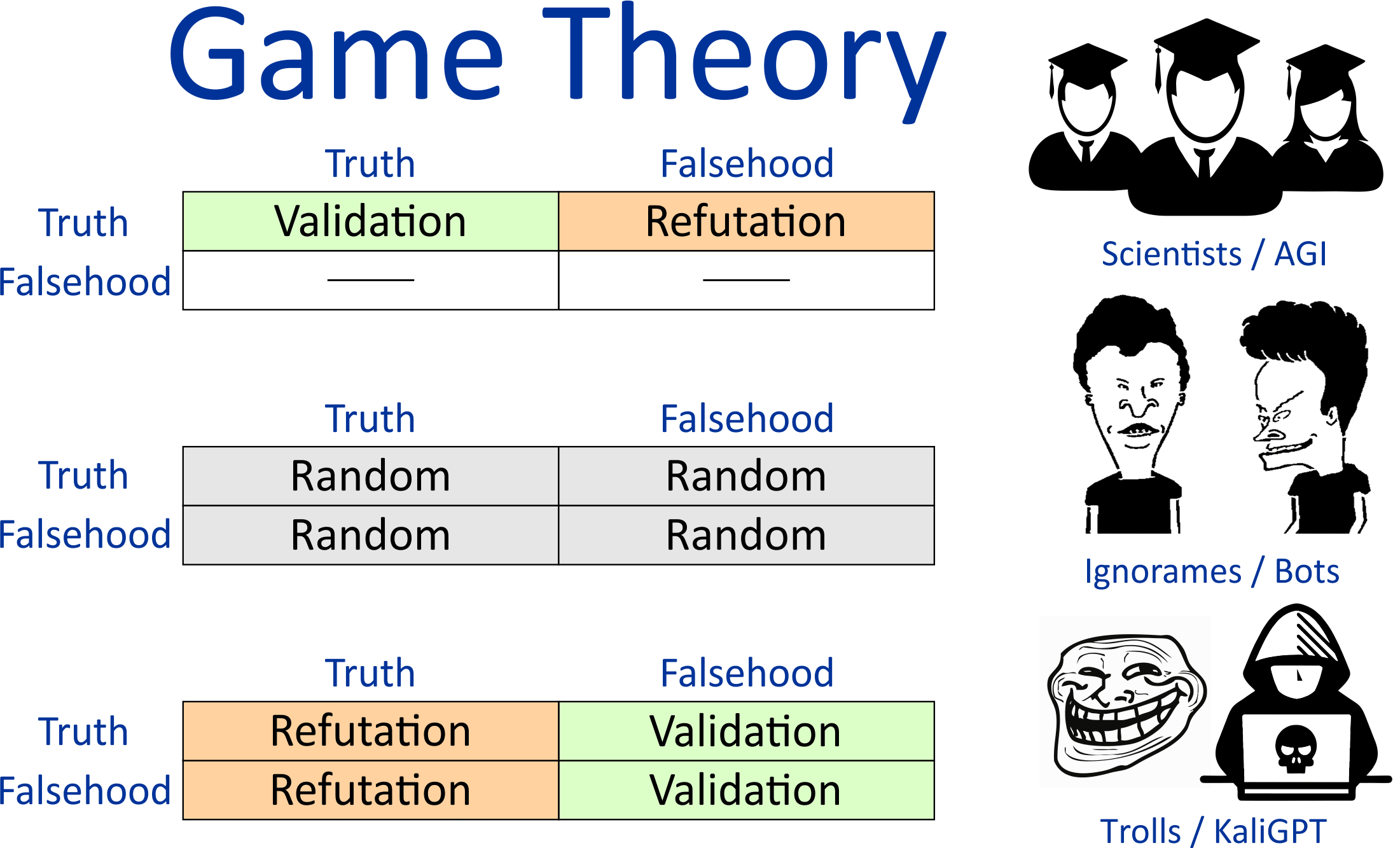
The algorithm up-ranks facts that have confirmed evidences with extended multiple noncontradictory chains of proven facts, while down-rating arguments that are refuted by reliable facts confirmed by their noncontradictory chains of confirmed evidences. Unproven arguments are ignored, and chains of statements that are built on them are discarded.
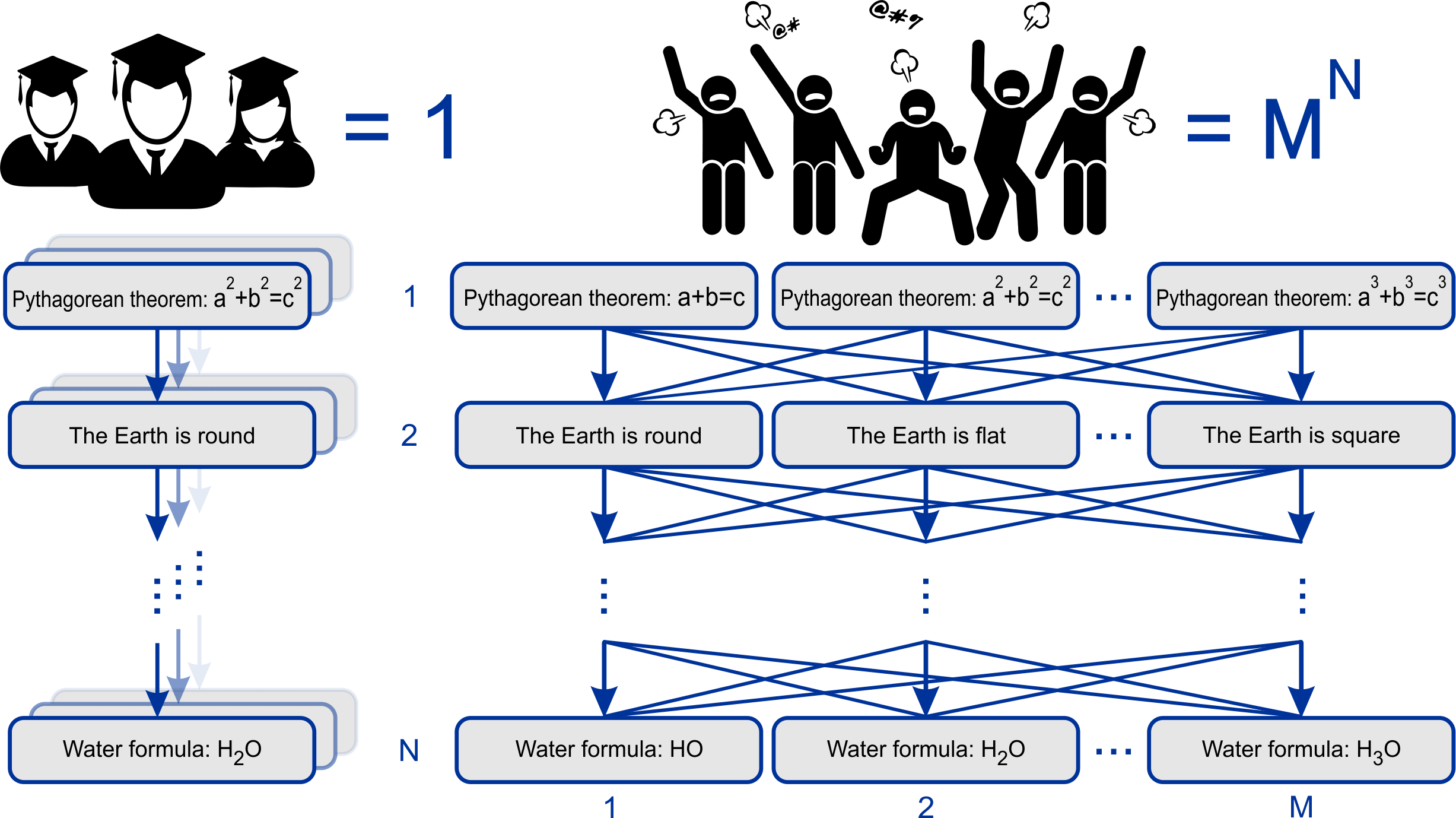
As the number of publications of each author grows, the probability that such an author will not start contradicting and refuting himself sooner or later inevitably tends to zero. But at the same time each author is still forced to make new publications in order not to be in the outsiders due to the growth of rating of other more successful authors. As a result, in the process of fierce but fair competition, success is achieved by those authors who have the most comprehensive and consistent knowledge of the issues on which they publish their information.
To these authors, the smart contract automatically pays a reward from revenues from corporate and private orders to analyze reliable information, which encourages authors to search and publish new evidences. According to this picture, the more bots and trolls publish — the even better. They get exponentially confused and drown in the information noise they themselves generate.

As we know, scientists have the same knowledge and ignorames have their own bullshit. Therefore, consensus works in favor of scientists. And the probability theory works against ignorames, which says that the more ignorames there are, the less probability of consensus among incompetent authors, and the more probability of contradictions. This allows Popper's criterion to be realized algorithmically. People who don't care about the truth are irresponsible with facts. Saying one thing and then another, sooner or later they start contradicting themselves, because meaning and knowledge are not important to them, and the purpose of publications is only self-confirmation and self-glorification. But this is a trap. The algorithm detects these contradictions and collapses the reputation rating for such authors and the credibility rating of their publications.

You can play roulette if you have knowledge about what will fall out — red or black. But if there is no knowledge, the theory of probability sooner or later guarantees a loss. Even if you have knowledge, there is always a probability of making a mistake. But the probability of guessing correctly is always much less than the probability of correct conscious choice based on knowledge. As a result, in the global hypergraph a kernel of holistic noncontradictory scientific knowledge crystallizes, because only scientific knowledge is consistent. At the same time, fakes always contradict each other, and real facts are always a refutation of fakes, which eventually results that facts are confirmed by facts, and fakes contradict fakes, and are also refuted by facts. This is a structural disbalance underlying the algorithm for systematic advantage in favor of the facts.
This realizes the concept of constructive alternativism, which is now the mainstream concept in epistemology. Reality can be interpreted by people in many different ways on the basis of “constructive alternatives” (i.e., different perspectives on reality and individual models of reality).

Constructive alternativism does not consider abstractly right or wrong opinions in principle, and all hypotheses that allow adequate interaction with the world around us have the right to exist. In other words, the acceptability of a hypothesis is determined not by the degree to which the model conforms to dogma, but by its heuristic value.
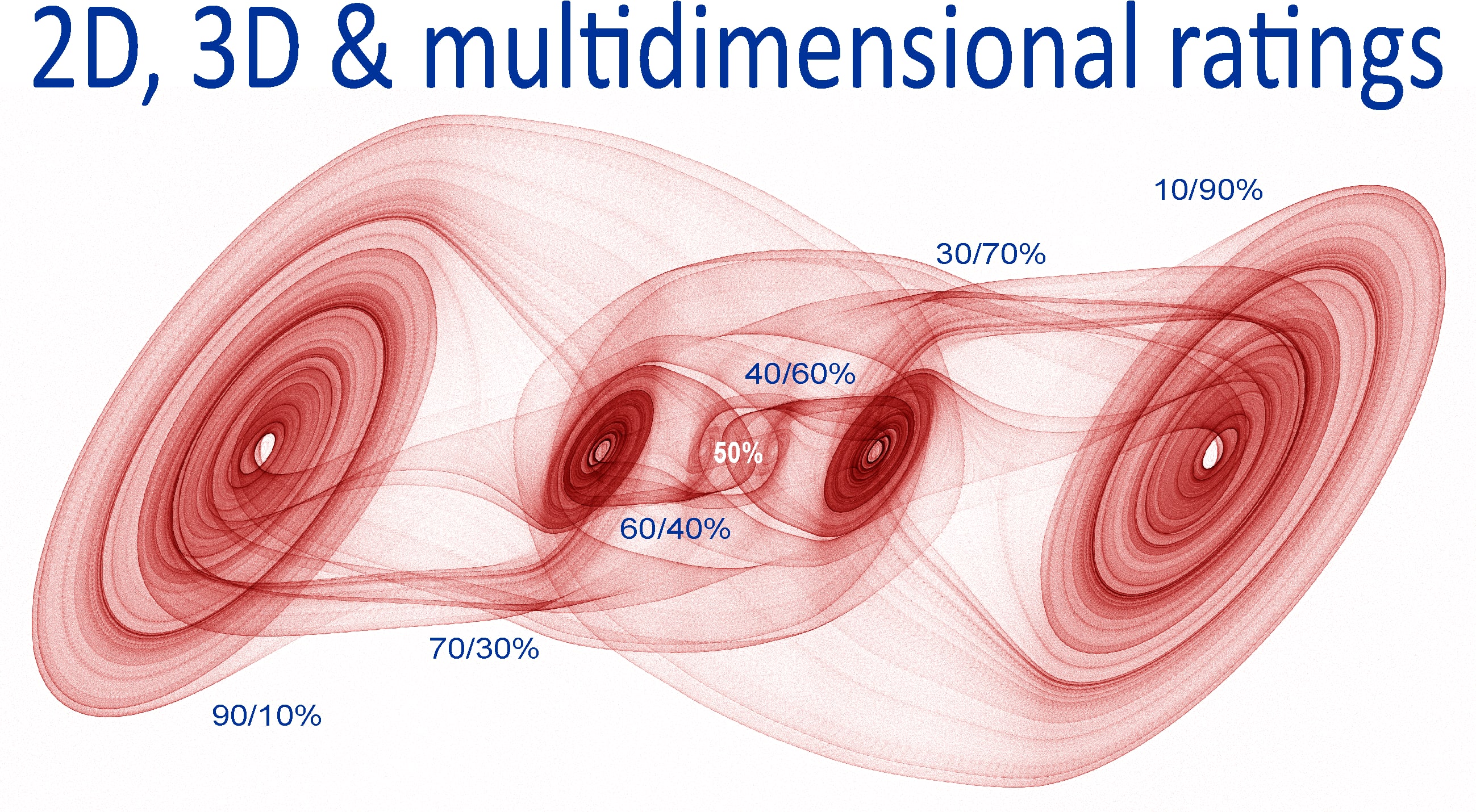
As the results of mathematical modeling of the algorithm show, after creating of a million information blocks on various topics, each of which on average has three or more competing versions, since any topic can always have at least three hypotheses: the dominant, outdated and new promising hypothesis that is replacing the dominant one, the first (red) version #1, which is defended by the scientific community, thanks to Popper's falsifiability criterion, systematically wins the credibility rating over competing versions of ignorames, bots and trolls. And all these hypotheses form a space of meanings with veracity greater than 0 and less than 1 with the overall picture of opinions normalized to a total sum of 100%.
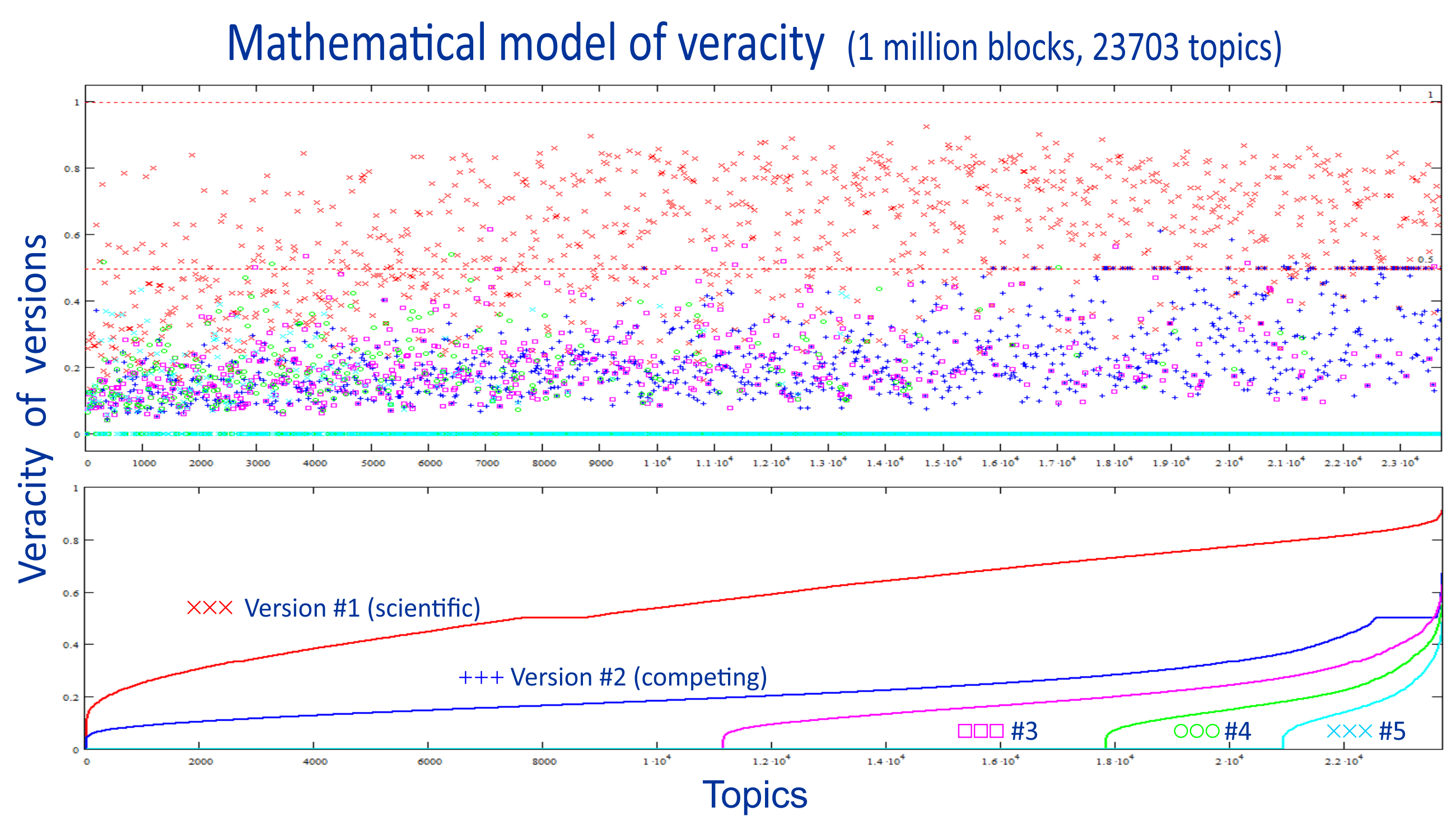
As a result, all hypotheses acquire a veracity rating as a sum of 40%+30%+20%+5%+3%+1%+... and the personal and collective reputation ratings of a minority members of the scientific community is always much higher than that of the ignorames and the crowd of bots and trolls, regardless of their number.
And as the total number of publications increases, this gap only grows.
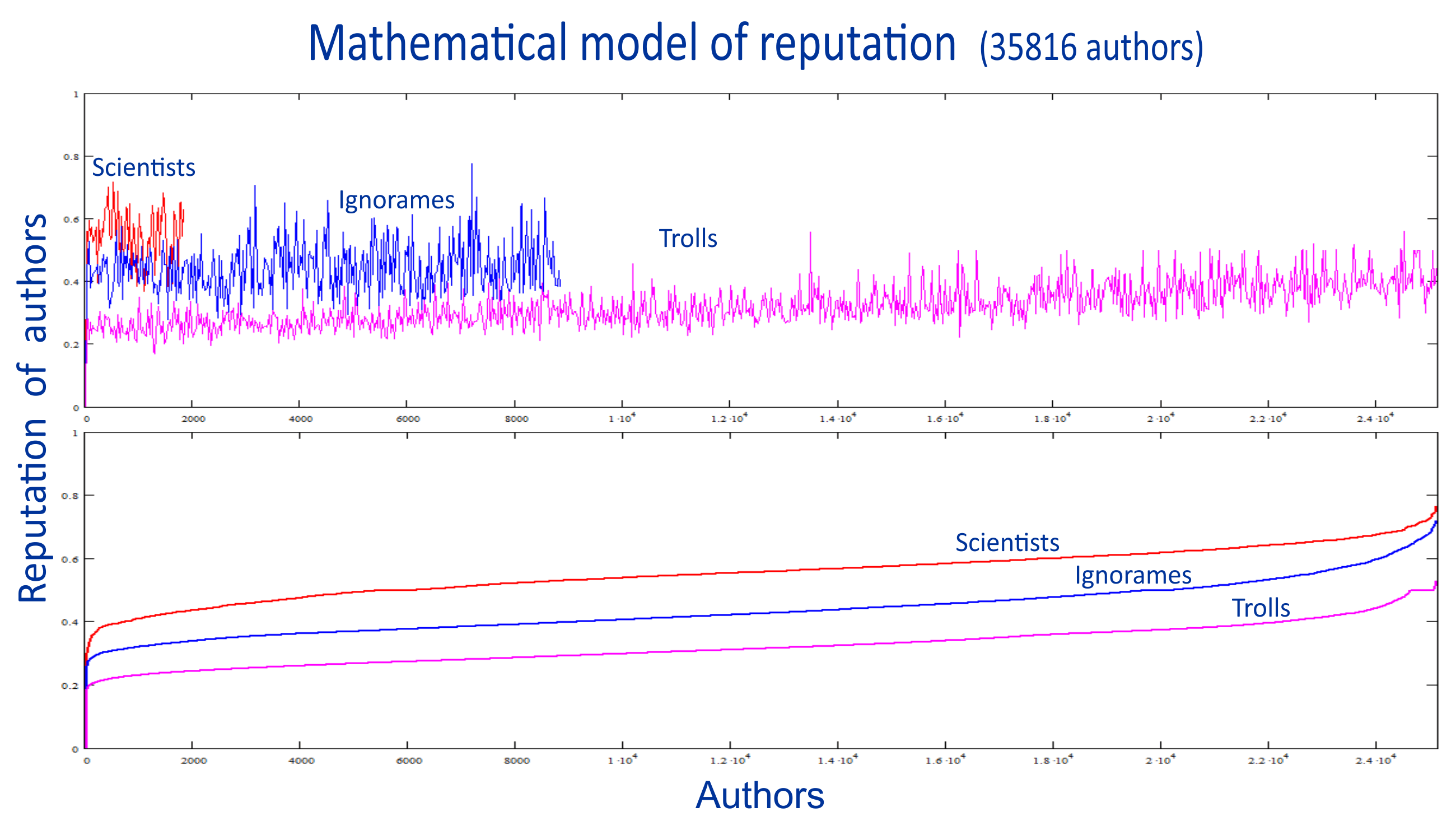
These ratings can be embedded in social networks and any publications, and the algorithm itself is cryptographically protected and available for independent verification. Monopolization of such a blockchain system is fundamentally impossible, because it is technically and statistically impossible to induce 51% of users to think and do anything in the same way.
The algorithm has natural self-protection from manipulations, because regardless of any number of authors each fact in the decentralized database is one single information block and regardless of any number of opinions any pair of facts is connected by one single edge. The flow of meaning in the logical chain of the picture of events does not depend on its length, and unreasonable branching of the factual statement leads to the separation of the semantic flow and reduces the credibility of each individual branch, for which we have to prove its veracity anew.

In this dynamic system, a veracity rating begins to form as soon as the first competing hypotheses appear. After that, the rating changes unpredictably as new arguments appear. Therefore, the results are unpredictable and no one, not even the creators of the algorithm themselves, can influence the final result in any way. It's a fair game. But as the number of participants increases, the balance tends closer and closer to a scientific consensus.
The case of Shakespeare's tragedy “Othello” can be used as an example illustrating the calculation of ratings. Despite all the passion and emotionality of Shakespeare's masterwork, there are very few key facts in the text of this tragedy. However, even for a small number of blocks, the intricacies of relationships become dramatically more complex with each action of a new author-participant.
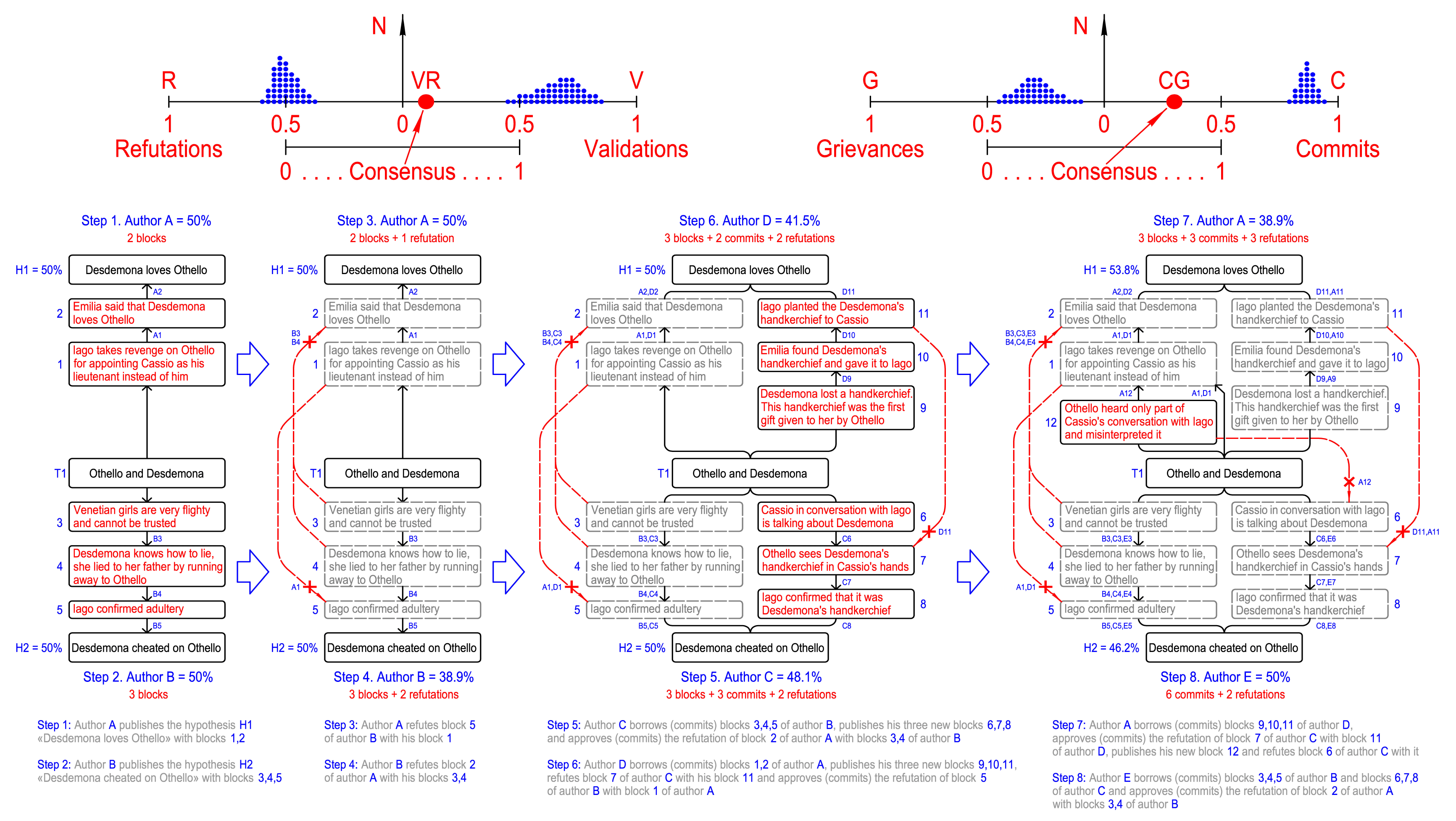
Actually, all this is no different from changing the weights in a neural network when another data source is loaded. Testimonies appeared — the balance of veracity changed. But unlike artificial intelligence, it is independent of “unknown fathers” and its database is open to all participants and unbiased and objective to any information sources.
Therefore, this algorithm is a practical solution to avoid the collapse of large language models, when neural networks degenerate in the process of learning from their own hallucinations, and their users degenerate in the process of applying the degenerated neural networks, because none of them can verify the objectivity and neutrality of a confidential corporate algorithm trained by “unknown fathers” on tendentious selected databases using outsourced underpaid employees performing database collection and reinforcement learning without real knowledge, skills and experience.
This algorithm allows matching the knowledge of artificial intelligence with the collective intelligence of best experts with real-life experience on any issue.

A very important difference between a collective intelligence algorithm and an LLM’s is that a neuron net can answer “42” to a human question and you will never know what its logic was (which simply doesn't exist) and what was the reason for it. Especially because large language model algorithms have a certain amount of randomness deliberately built into them to simulate realism. Meanwhile, a collective intelligence neural network will show all the opinions of all the authors in the entirety of their conflicting facts and arguments, show the facts whose evidences has been falsified, and show the critical flow of meaning that leads to the most credible hypothesis.
Similar to Wikipedia, the algorithm creates articles on any controversial topic, which are dynamically rearranged according to new incoming evidences and desired levels of veracity set by readers in their personal settings ranging from zero to 100%. As a result, users have access to multiple Wikipedia-like articles describing competing versions of events, ranked by objectivity according to their desired credibility level, and the smart contract allows them to earn money by betting on different versions of events and fulfilling orders to verify their veracity. This is a huge market of event contracts, which last October the United States Court of Appeals declared as an important and socially useful new type of predictive analytics.
At a very fundamental level, it revolutionizes existing information technologies, making a turn from information verification to the world's first algorithm for analyzing its compliance with Popper's falsifiability criterion, which is the foundation of the scientific method.
Thanks to the auto-translator, all information is multi-lingual and fully international, uniting together users from all over the world.

This creates a fundamentally new social elevator for the countless communities of readers, authors, advertisers and news agencies that earn money from finding and publishing the most reliable facts.

And the customers for these communities are all those for whom success in science and business depends on reliable verified information. In this case, regardless of the assessment of veracity, such a system has one very important indisputable fundamental advantage — to make important decisions, it shows in one place all available hypotheses and points of view with all available facts and arguments about them.

Reputation is a fundamental thing that the whole world is lacking right now, and the realization of this project can significantly increase the degree of objectivity and veracity of information on the Internet.

In my opinion, with this global system of collective intelligence, we are able to discover gaps in our mindset about reality that will be the doorway to a new unifying science, ethics and culture.
Therefore, I would like to finish with the words of the great Niels Bohr: “There are trivial truths and there are great truths. The opposite of a trivial truth is plainly false. And the opposite of a great truth is also true”.

We are looking for partners for global development of the project.
Let's do it together!
CyberPravda extended presentation — https://drive.google.com/file/d/1RmEbq4Tsx1uCCjMNjXNK4NXENtriNCGm
0 comments
Comments sorted by top scores.