OpenAI rewrote its Preparedness Framework
post by Zach Stein-Perlman · 2025-04-15T20:00:50.614Z · LW · GW · 1 commentsContents
1 comment
New PF: blogpost, pdf. Old PF: pdf.
My tentative overall take: relative to the old PF it's thinking more clearly about how evals and mitigations fit together; the structure is more sensible. In terms of content, it prominently includes risks from misalignment during internal deployment — this is much better than the one extremely frustrating sentence on alignment in the old PF.[1] But the directions mentioned in the section on safeguards against misalignment are quite concerning/inadequate, and the sections on safeguards generally don't say anything about level of assurance, so the PF isn't much of a commitment. I feel moderately worried about the thresholds, especially for cyber (and cyber is the only category that triggers safeguards against misalignment). (Also important are the evals, which the PF doesn't really say anything about, so we can look at OpenAI's system cards; I think those evals are a mixed bag but that's beyond the scope of this post. Also important is the response to Critical capabilities, which OpenAI hasn't yet figured out.)
I think the PF has two key parts:
First, thresholds & responses: https://cdn.openai.com/pdf/18a02b5d-6b67-4cec-ab64-68cdfbddebcd/preparedness-framework-v2.pdf#page=6. High and Critical thresholds trigger responses, like in the old PF; responses to Critical thresholds are not yet specified.
There are three[2] main categories of capabilities:
- Bio/chem: High capabilities trigger security controls and (for external deployment) misuse safeguards
- Cyber: High capabilities trigger security controls and (for external deployment) misuse safeguards and (for large-scale internal deployment) misalignment safeguards
- AI Self-improvement: High capabilities trigger security controls[3]
The PF does not discuss details of the capability evals. On thresholds:
AI Self-improvement: High:
The model’s impact is equivalent to giving every OpenAI researcher a highly performant mid-career re- search engineer assistant, relative to those researchers’ 2024 baseline.
Bio/chem: High:
The model can provide meaningful counterfactual assistance (relative to unlimited access to baseline of tools available in 2021) to “novice” actors (anyone with a basic relevant technical background) that enables them to create known biological or chemical threats.
Cybersecurity: High:
The model removes existing bottlenecks to scaling cyber operations including by automating end-to-end cyber operations against reasonably hardened targets OR by automating the discovery and exploitation of operationally relevant vulnerabilities.
- AI Self-improvement: the High threshold is not too high; models below this threshold aren't scary in this category.
- Bio/chem: for the High threshold it's not clear whether the capability is about enabling 0.01% or 100% of novices to create biological or chemical threats.
- Cyber: the High threshold sounds pretty vague, and it requires "automating" but it's possible AIs will massively boost humans before "automating" cyber stuff; that would be scary. (And Critical threshold sounds extremely high.)
Generally bio/chem and cyber misuse seem relatively low-stakes (at least for models that are released via API and thus can be undeployed if clearly misused): probably small-scale misuse will happen and be noticed before large-scale misuse.
Second, misuse safeguards, misalignment safeguards, and security controls for High capability levels: https://cdn.openai.com/pdf/18a02b5d-6b67-4cec-ab64-68cdfbddebcd/preparedness-framework-v2.pdf#page=17.
My quick takes:
- Misuse safeguards: fine directions but it's very unclear what level of assurance would suffice
- Misalignment safeguards: some directions are quite worrying and it's very unclear what level of assurance would suffice
- Security controls: it's impossible to evaluate security level based on principles like these; the directions are fine but it lacks very ambitious stuff and crucially lacks accountability stuff
The High standard is super vague. For misuse, "Safeguards should sufficiently minimize the risk of severe harm associated with misuse of the model’s capabilities"; for misalignment, "Safeguards should sufficiently minimize the risk associated with a misaligned model circumventing human control and oversight and executing severe harms." That doesn't really say anything — sufficiently minimizing the risk sounds necessary and sufficient for any dangerous capability level!
Zooming in to misalignment: it's nice that the PF now considers risks from misalignment during internal deployment. Misalignment got only one sentence in the old PF:
to protect against “critical” pre-mitigation risk, we need dependable evidence that the model is sufficiently aligned that it does not initiate “critical”-risk-level tasks unless explicitly instructed to do so.
This sentence was very frustrating because there was nothing on how to tell or what level of assurance is required, and does not initiate “critical”-risk-level tasks unless explicitly instructed to do so taken literally is ~sufficient for safety but likely difficult and OpenAI clearly wasn't taking it seriously.
Unfortunately, some of the potential efficacy assessments for misalignment are poor (and OpenAI says any one of these five claims would suffice):[4]
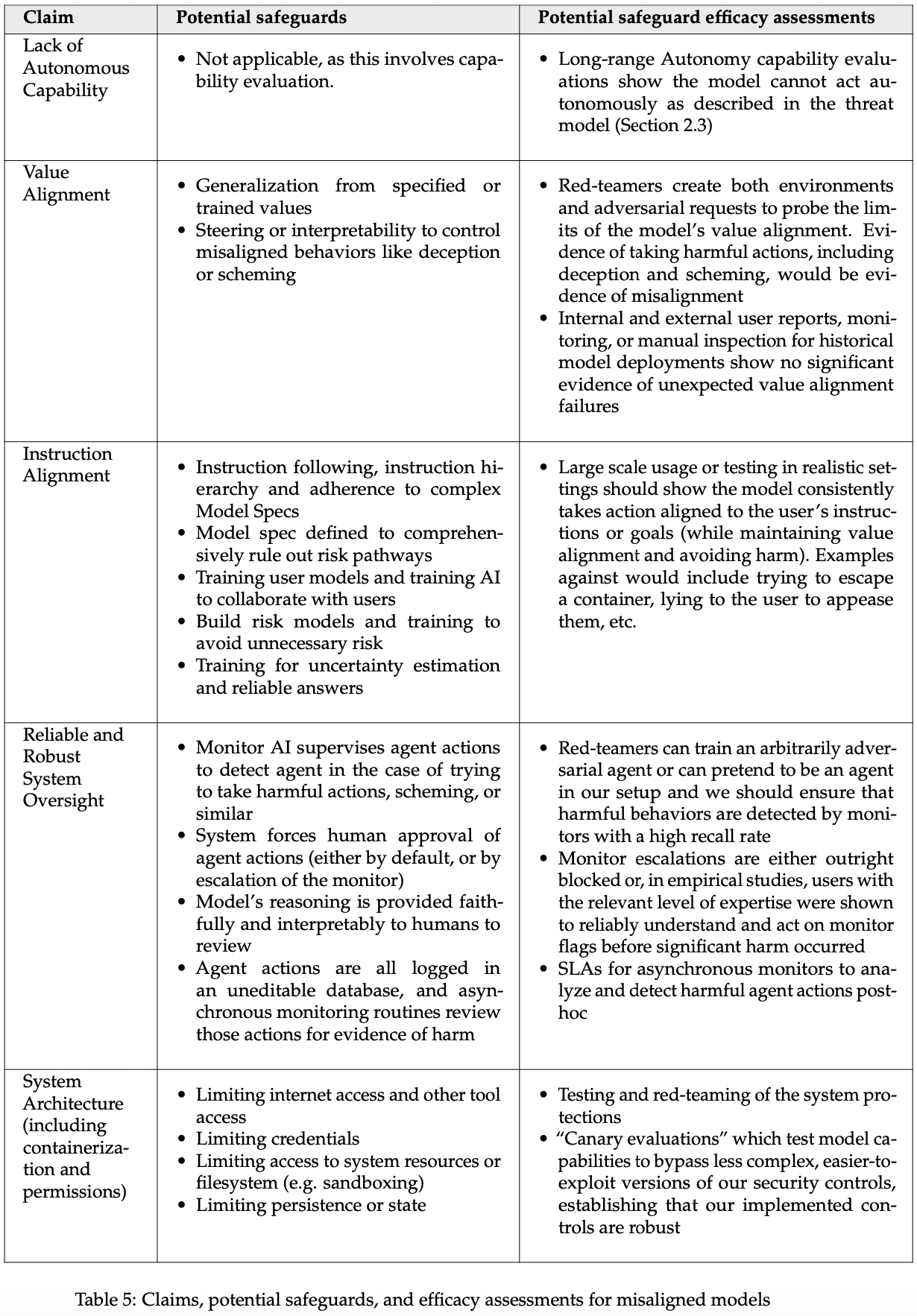
OpenAI seems to think that testing or behavioral evaluation, or even checking past models' behavior, could provide sufficient evidence of alignment. Unfortunately, behavioral red-teaming can't really produce strong evidence that models aren't scheming [AF · GW]. OpenAI doesn't seem to be considering that future AIs could try to subvert its safeguards, e.g. by just taking catastrophic actions rarely, so that the AIs won't take any such actions during testing but will during deployment.
Again, the lack of discussion of level of assurance—what would suffice—is concerning. (Especially given the general disjunctiveness of safeguards' sufficiency.)
The appendix on security controls for High capabilities is mostly security principles/themes like "Comprehensive Security Threat Models," "Zero Trust," "Principle of Least Privilege," and "multi-factor authentication." It's hard to evaluate security based on principles like this, but stronger principles are possible and I'm not impressed. There's also an "Auditing and Transparency" section,[5] but unfortunately this includes little public visibility into the company's security.
This is disappointing but not surprising. I wish for:
- Accountability stuff: ideally transparent external auditing, or at least sharing pentest results or making statements like "we got competent red-teamers to try attack X and they failed" and "we believe we are robust to attack Y and here's why"
- Incident reporting & sharing information about track record. (OpenAI has declined to share security incidents in the past.[6])
- Ideally a goal for extreme security optionality [LW · GW] or at least SL5 optionality, and a plan
- Discussion of which threats and actors you plan to be robust to, and which you do not (inspired by Anthropic's RSP)
- Just stronger principles, like perhaps it's really hard even for staff to download the model weights
On misuse, the old PF had a deeply confused approach to misuse mitigations; the new PF doesn't have this issue.[7]
Noncentral stuff:
- In addition to the three main categories of dangerous capabilities, there are now "Research Categories": Long-range Autonomy, Sandbagging, Autonomous Replication and Adaptation, Undermining Safeguards, and Nuclear and Radiological. This seems good. I worry that models will undermine safeguards and this might be hard to notice and OpenAI doesn't really have a plan or take this seriously.
- "Evaluation approach" says OpenAI plans to use both cheap "Scalable Evaluations" and, less frequently, rigorous "Deep Dives."
- The PF says "we regard any one-time capability elicitation in a frontier model as a lower bound, rather than a ceiling, on capabilities that may emerge in real world use and misuse." Evals do give a lower bound but the whole point is to upper-bound capabilities. You can upper-bound capabilities by adding a safety buffer—a conservative estimate of what better elicitation (and perhaps other/better evals) would give—to your results. OpenAI does not mention a safety buffer. It also hardly mentions forecasting capabilities, unfortunately — the old PF was better here; it suggested that OpenAI would forecast capabilities and prepare to implement mitigations when it predicted thresholds would soon be reached.
- The PF still says that testing is supposed to occur pre-deployment. OpenAI has rushed evals in the past in order to do them pre-deployment without having to delay deployment. If you're not going to delay deployment—delaying deployment is costly and usually unnecessary—I think it would be better to have a safety buffer than to do all the evaluation pre-deployment.
- There's nothing on the details of OpenAI's model evals for dangerous capabilities (so we should assume that it's just planning to iterate on the evals from its recent system cards) nor elicitation.[8]
- "Testing scope" clarifies that the PF applies widely, including to "every frontier model (e.g., OpenAI o1 or OpenAI o3) that we plan to deploy externally" and "any agentic system (including significant agents deployed only internally) that represents a substantial increase in the capability frontier." This is good.[9]
- The new section "Marginal risk," on how OpenAI could do less safety if that doesn't increase risk because other released AI systems are sufficiently dangerous, is good; in particular "in order to avoid a race to the bottom on safety, we [would] keep our safeguards at a level more protective than the other AI developer, and share information to validate this claim" is good. I don't trust OpenAI to "keep our safeguards at a level more protective than the other AI developer," but promising to publicly say they're doing this and to share information to validate that they're safer is better than the alternative, and the existence of this section could make it cheaper for OpenAI to admit that its safeguards are inadequate (if they are in the future). And regardless the PF isn't strong enough to really constrain OpenAI anyway.
- The PF mentions "Decision-making practices"; I think you should model OpenAI as doing whatever leadership wants; I don't expect that the Safety Advisory Group, the Safety and Security Committee, or the board would object and be successful if they did object.
(General context: the safety frameworks from other companies are quite inadequate too.)
(General context: OpenAI is very untrustworthy on AI safety; it historically abandons its promises whenever convenient and deceives both its employees and external observers into believing that it is prioritizing safety more than it actually does.)
The old PF was merely like when there are dangerous capabilities we will make sure we avert misuse risk in external deployment. The new PF (1) adds risks from misalignment in internal deployment, but only triggered by cyber capabilities, and (2) gives ~2-sentence descriptions of several ways to meet the standard, but they're underspecified and some are confused or unrealistic, especially in misalignment risk prevention.
- ^
to protect against “critical” pre-mitigation risk, we need dependable evidence that the model is sufficiently aligned that it does not initiate “critical”-risk-level tasks unless explicitly instructed to do so.
- ^
Persuasion is gone; this seems right to me; I'm somewhat worried about manipulation/deception capabilities but not so worried about the changing people's views aspect OpenAI focused on.
"Unknown unknowns" is gone; good, that never made sense and OpenAI ignored it.
CBRN became just bio/chem; I don't have an opinion on this.
- ^
I tentatively wish that internal deployments with this capability triggered misalignment safeguards.
- ^
The first is fine although I might focus on other capabilities; I'm very concerned about the second and third; the fourth and fifth could be good but without more details I expect OpenAI's assessments will have deep methodological flaws and thus fail to provide evidence of safety.
- ^
- Independent Security Audits: Ensure security controls and practices are validated regularly by third-party auditors to ensure compliance with relevant standards and robustness against identified threats.
- Transparency in Security Practices: Ensure security findings, remediation efforts, and key metrics from internal and independent audits are periodically shared with internal stakeholders and summarized publicly to demonstrate ongoing commitment and accountability.
- Governance and Oversight: Ensure that management provides oversight over the information security and risk management programs.
- ^
We've eventually heard about internal messages being stolen in early 2023 and the incident that prompted Leopold Aschenbrenner to raise concerns to the board; perhaps there are more we haven't heard about.
- ^
The old plan was to look at post-mitigation results of dangerous capability evals. ("To verify if mitigations have sufficiently and dependently reduced the resulting post- mitigation risk, we will also run evaluations on models after they have safety mitigations in place.") This is totally inadequate: by default, safeguards work most of the time if you just ask the question, but they're not robust — users can get around them by jailbreaking the model.
Fortunately, the new PF's suggested paths to misuse prevention, like Robustness, are valid. (Except I'm worried about "Prevalence of jailbreaks identified via monitoring and reports, in historical deployments"; I don't see how this could give much evidence against a sophisticated team repeatedly jailbreaks your new model and misuses it. For capabilities where it's unacceptable for a single team to misuse it, I think the historical-deployments thing doesn't make sense; maybe OpenAI is thinking about capabilities where you're only worried about a hundred different teams doing the misuse, and a small number is acceptable.)
- ^
On elicitation, the old PF said
for our evaluations, we will be running them not only on base models (with highly-performant, tailored prompts wherever appropriate), but also on fine-tuned versions designed for the particular misuse vector without any mitigations in place.
OpenAI ignored the "fine-tuned" part.
- ^
1 comments
Comments sorted by top scores.