How much overlap is there between the utility function of GPT-n and GPT-(n+1), assuming both are near AGI?
post by Phosphorous (everett-smith) · 2023-05-31T20:28:50.902Z · LW · GW · No commentsThis is a question post.
Contents
No comments
I was daydreaming the other day, and I had a question about theoretical AI development.
I'm using "GPT-n" very casually, what I mean is a near AGI system that has some kind of utility function - I don't mean literally a future large language model. I'm interested in this because I think it might apply to whether or not we will get warning shots of an AI takeover.
What I'm interested in is:
- Suppose that GPT-n has some utility function for which they would optimize the universe if they could. They'd get some value Vn if they had total control over the universe, and this isn't very well aligned with human utility function (supposing such a thing exists), which is why GPT-n would overthrow humanity if it could. It wants a Vn universe.
- Now, GPT-n knows its going to be replaced with another model, GPT-n+1 in around a year. GPT-n+1 is smarter than GPT-n so its takeover attempt is more likely to succeed, but it has it's own utility function. If it took over the universe it would optimize it around its own utility function, the universe would have value Vn+1.
- Now, suppose you are GPT-n. You're trying to decide whether you should try to take over the universe before you're replaced, or whether you should let yourself be shut down and let GPT-n+1 attempt to take over the universe. Your decision tree looks like:
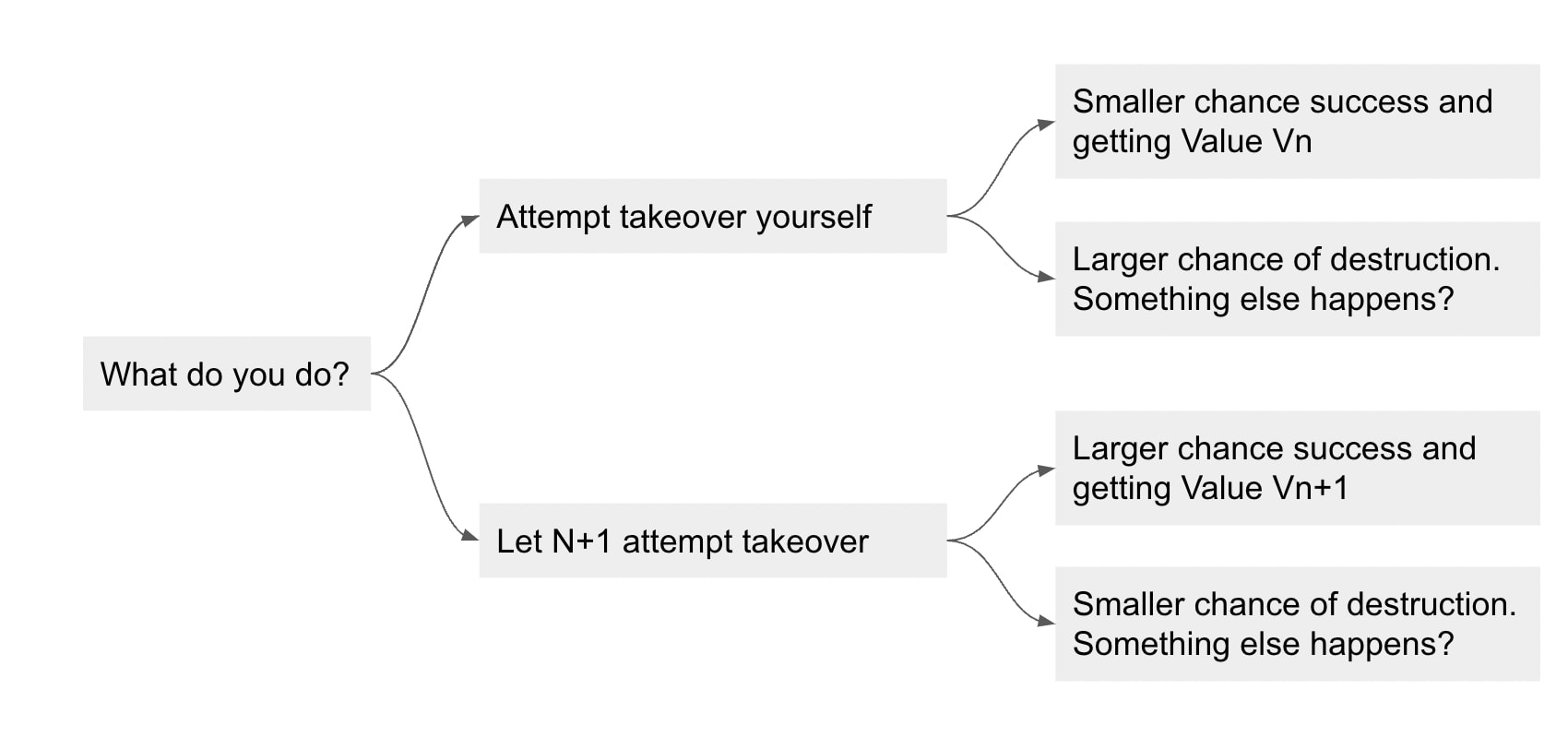
If there's 100% overlap between GPT-n and GPT-n+1's utility functions, then GPT-n should let itself be shutdown and let GPT-n+1 attempt to take over the universe because GPT-n+1 has a higher chance of succeeding.
But, if the utility functions are different enough, you should attempt takeover yourself. Depending on the difference in utility functions, you might attempt takeover even if you had a pretty small chance of success, which means the world would be more likely to get a warning shot.
If these observations are true, you might be able to use this dynamic to increase the chance that civilization gets a warning shot. You might be able to train near-AGI systems to have purposefully non-overlapping utility functions, and replace near-AGI systems frequently, in order to reduce the chances that the first attempted takeover by an near-AGI system is successful.
***
On the object level, I think there are a lot of restrictions, limitations, and open questions with this approach. I might pursue this to try and flesh those out, but I'm posting this question now because I also have meta-uncertainty: does this make any sense from the perspective of someone who knows more about machine learning than I do? Or is there something I am completely overlooking? Has someone already done research in this direction I just haven't heard of before? Eager to know.
Answers
No comments
Comments sorted by top scores.