Proofs, Theorems 6-8, Propositions 2,3
post by Diffractor · 2021-12-03T18:46:18.937Z · LW · GW · 0 commentsContents
No comments
Theorem 6: Causal IPOMDP's: Any infra-POMDP with transition kernel which fulfills the niceness conditions and always produces crisp infradistributions, and starting infradistribution , produces a causal belief function via .
So, first up, we can appeal to Theorem 4 on Pseudocausal IPOMDP's, to conclude that all the are well-defined, and that this we defined fulfills all belief function conditions except maybe normalization.
The only things to check are that the resulting is normalized, and that the resulting is causal. The second is far more difficult and makes up the bulk of the proof, so we'll just dispose of the first one.
T6.1 First, , since it's crisp by assumption, always has for all constants . The same property extends to all the (they're all crisp too) and then from there to by induction. Then we can just use the following argument, where is arbitrary.
The last two inequalities were by mapping constants to the same constant regardless of , and by being normalized since it's an infradistribution. This same proof works if you swap out the 1 with a 0, so we have normalization for .
T6.2 All that remains is checking the causality condition. We'll be using the alternate rephrasing of causality. We have defined as
and want to derive our rephrasing of causality, that for any and and and family , we have
Accordingly, we get to fix a , and family of functions , and assume
Our proof target is
Applying our reexpression of in terms of and and projection, we get
Undoing the projections on both sides, we get
Unpacking the semidirect product, we get
Now, we can notice something interesting here. By concavity for infradistributions, we have
So, our new proof target becomes
Because if we hit that, we can stitch the inequalities together. The obvious move to show this new result is to apply monotonicity of infradistributions. If the inner function on the left hand side was always above the inner function on the right hand side, we'd have our result by infradistribution monotonicity. So, our new proof target becomes
At this point, now that we've gotten rid of , we can use the full power of crisp infradistributions. Crisp infradistributions are just a set of probability distributions! Remember that the semidirect product, , can be viewed as taking a probability distribution from , and for each , picking a conditional probability distribution from , and all the probability distributions of that form make up .
In particular, the infinitely iterated semidirect product here can be written as a repeated process where, for each history of the form Murphy gets to select a probability distribution over the next observation and state from (as a set of probability distributions) to fill in the next part of the action-observation-state tree. Accordingly every single probability distribution in can be written as interacting with an expanded probabilistic environment of type (which gives Murphy's choice wherever it needs to pick the next observation and state), subject to the constraints that
and
We'll abbreviate this property that always picks stuff from the appropriate set and starts off picking from as .
Our old proof goal of
can be rephrased as
and then rephrased as
And now, by our earlier discussion, we can rephrase this statement in terms of picking expanded probabilistic environments.
Now, on the right side, since the set we're selecting the expanded environments from is the same each time and doesn't depend on , we can freely move the inf outside of the expectation. It is unconditionally true that
So now, our proof goal shifts to
because if that were true, we could pair it up with the always-true inequality to hit our old proof goal. And we'd be able to show this proof goal if we showed the following, more ambitious result.
Note that we're not restricting to compatibility with and , we're trying to show it for any expanded probabilistic environment of type . We can rephrase this new proof goal slightly, viewing ourselves as selecting an action and observation history.
Now, for any expanded probabilistic environment , there is a unique corresponding probabilistic environment of type where, for any policy, . This is just the classical result that any POMDP can be viewed as a MDP with a state space consisting of finite histories, it still behaves the same. Using this swap, our new proof goal is:
Where is an arbitrary probabilistic environment. Now, you can take any probabilistic environment and view it as a mixture of deterministic environments . So we can rephrase as, at the start of time, picking a from for some particular . This is our mixture of deterministic environments that makes up . This mixture isn't necessarily unique, but there's always some mixture of deterministic enivironments that works to make where is arbitrary. So, our new proof goal becomes:
Since is just a dirac-delta distribution on a particular history, we can substitute that in to get the equivalent
Now we just swap the two expectations.
And then we remember that our starting assumption was
So we've managed to hit our proof target and we're done, this propagates back to show causality for .
Theorem 7: Pseudocausal to Causal Translation: The following diagram commutes when the bottom belief function is pseudocausal. The upwards arrows are the causal translation procedures, and the top arrows are the usual morphisms between the type signatures. The new belief function is causal. Also, if , and is defined as for any history containing Nirvana, and for any nirvana-free history, then .
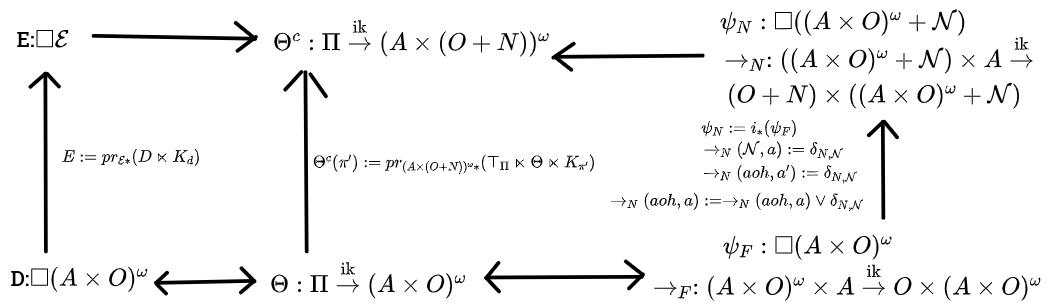
T7.0 Preliminaries. Let's restate what the translations are. The notation is that "defends" . defends if it responds to any prefix of which ends in an action with either the next observation in , or Nirvana, and responds to any non-prefixes of with Nirvana.
Also, we'll write if is "compatible" with and . The criterion for this is that , and that any prefix of which ends in an action and contains no Nirvana observations must either be a prefix of , or only deviate from in the last action. An alternate way to state that is that is capable of being produced by a copolicy which defends , interacting with .
With these two notes, we introduce the infrakernels , and .
is total uncertainty over such that defends .
And is total uncertainty over such that is compatible with and .
Now, to briefly recap the three translations.For first-person static translation, we have
Where is the original belief function.
For third-person static translation, we have
Where is the original infradistribution over .
For first-person dynamic translation, the new infrakernel has type signature
Ie, the state space is destinies plus a single Nirvana state, and the observation state is the old space of observations plus a Nirvana observation. is used for the Nirvana observation, and is used for the Nirvana state. The transition dynamics are:
and, if , then
and otherwise,
The initial infradistribution is , the obvious injection of from to .
The obvious way to show this theorem is that we can assume the bottom part of the diagram commutes and are all pseudocausal, and then show that all three paths to produce the same result, and it's causal. Then we just wrap up that last part about the utility functions.
Fortunately, assuming all three paths produce the same belief function, it's trivial to show that it's causal. is an infradistribution since is, and is a crisp infrakernel, so we can just invoke Theorem 6 that crisp infrakernels produce causal belief functions to show causality for . So we only have to check that all three paths produce the same result, and show the result about the utility functions. Rephrasing one of the proofs is one phase, and then there are two more phases showing that the other two phases hit the same target, and the last phase showing our result about the utility functions.
We want to show that
T7.1 First, let's try to rephrase into a more handy form for future use. Invoking our definition of , we have:
Then, we undo the projection
And unpack the semidirect product
And unpack what means
And then apply the definition of
This will be our final rephrasing of . Our job is to derive this result for the other two paths.
T7.2 First up, the third-person static translation. We can start with definitions.
And then, we can recall that since and are assumed to commute, we can define in terms of via . Making this substitution, we get
We undo the first pushforward
And then the projection
And unpack the semidirect product
And remove the projection
and unpack the semidirect product and what is
Now, we recall that is all the that defend , to get
At this point we can realize that for any which defends , when interacts with , it makes a that is compatible with and . Further, all compatible with and have an which produces them. If has its nirvana-free prefix not being a prefix of , then the defending which doesn't end early, just sends deviations to Nirvana, is capable of producing it. If looks like but ended early with Nirvana, you can just have a defending which ends with Nirvana at the same time. So we can rewrite this as
And this is exactly the form we got for .
T7.3 Time for the third and final translation. We want to show that
is what we want. Because the pseudocausal square commutes, we have that , so we can make that substitution to yield
Remove the projection, to get
For this notation, we're using to refer to an element of , the state space. is an element of , a full unrolling. is the projection of this to .
We unpack the semidirect product to yield
and rewrite the injection pushforward
and remove the projection
And unpack the semidirect product along with .
Now we rewrite this as a projection to yield
And do a little bit of reindexing for convenience, swapping out the symbol for , getting
And now, we can ask what is. Basically, the starting state is the destiny , and then interacts with it through the kernel . Due to how is defined, it can do one of three things. First, it could just unroll all the way to completion, if is the sort of history that's compatible with . Second, it could partially unroll and deviate to Nirvana early, even if is compatible with more, because of how is defined. Finally, could deviate from and then would have to respond with Nirvana. And of course, once you're in a Nirvana state, you're in there for good. Hm, you have total uncertainty over histories compatible with and , any of them at all could be made by . So, this projection of the infrakernel unrolling is just . We get
And then we use what does to functions, to get
Which is exactly the form we need. So, all three translation procedures produce identical belief functions.
T7.4 The only thing which remains to wrap this result up is guaranteeing that, if is 1 if the history contains Nirvana, (or infinity for the type signature), and otherwise, then .
We rephrased as
We can notice something interesting. If is the sort of history that is capable of making, ie , then all of the are going to end up in Nirvana except itself, because all the are like "follow , any deviations of from go to Nirvana, and also Nirvana can show up early". In this case, since any history ending with Nirvana is maximum utility, and otherwise is copied, we have . However, if is incompatible with , then no matter what, a history which follows is going to hit Nirvana and be assigned maximum utility. So, we can rewrite
as
Which can be written as an update, yielding
And then, we remember that regardless of and , for pseudocausal belief functions, which is, we have that , so the update assigns higher expectation values than does. Also, . Thus, the infinimum is attained by , and we get
and we're done.
Theorem 8: Acausal to Pseudocausal Translation: The following diagram commutes when the bottom belief function is acausal. The upwards arrows are the pseudocausal translation procedures, and the top arrows are the usual morphisms between the type signatures. The new belief function will be pseudocausal.
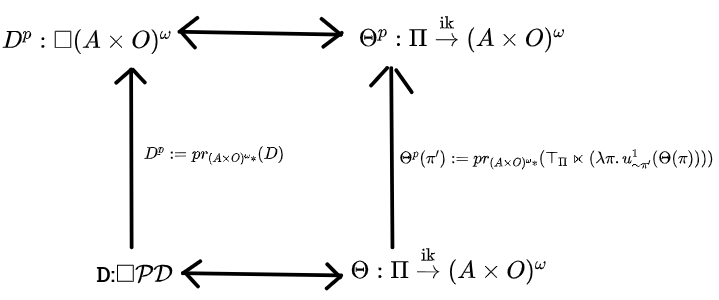
T8.0 First, preliminaries. The two translation procedures are, to go from an infradistribution over policy-tagged destinies , to an infradistribution over destinies , we just project.
And, to go from an acausal belief function to a pseudocausal one , we do the translation
We assume that and commute, and try to show that these translation procedures result in a and which are pseudocausal and commute with each other. So, our proof goals are that
and
Once we've done that, it's easy to get that is pseudocausal. This occurs because the projection of any infradistribution is an infradistribution, so we can conclude that is an infradistribution over . Also, back in the Pseudocausal Commutative Square theorem, we were able to derive that any infradistribution over , when translated to a , makes a pseudocausal belief function, no special properties were used in that except being an infradistribution.
T8.1 Let's address the first one, trying to show that
We'll take the left side, plug in some function, and keep unpacking and rearranging until we get the right side with some function plugged in. First up is applying definitions.
by how was defined. Now, we start unpacking. First, the projection.
Then unpack the semidirect product and , for
Then unpack the update, to get
Then pack up the
And pack up the semidirect product
And since for the original acausal belief function, we can rewrite this as
And pack this up in a projection.
And then, since we defined , we can pack this up as
And then pack up the update
So, that's one direction done.
T8.2 Now for the second result, showing that
Again, we'll take the more complicated form, and write it as the first one, for arbitrary functions .bWe begin with
and then unpack what is to get
Undo the projection
Unpack the semidirect product and .
Remove the projection
Unpack the semidirect product and again.
Let's fold the two infs into one inf, this doesn't change anything, just makes things a bit more concise.
and unpack the update.
Now, we can note something interesting here. If is selected to be equal to , that inner function is just , because is only supported over histories compatible with . If is unequal to , that inner function is with 1's for some inputs, possibly. So, our choice of is optimal for minimizing when its equal to , so we can rewrite as
and write this as
And pack up as a semidirect product
and then because , we substitute to get
and then write as a projection.
Now, this is just , yielding
and we're done.
Proposition 2: The two formulations of x-pseudocausality are equivalent for crisp acausal belief functions.
One formulation of x-pseudocausality is that
where
The second formulation is,
This proof will be slightly informal, it can be fully formalized without too many conceptual difficulties. We need to establish some basic probability theory results to work on this. The proof outline is we establish/recap four probability-theory/inframeasure-theory results, and then show the two implication directions of the iff statement.
P2.1 Our first claim is that, given any two probability distributions and , you can shatter them into measures , and such that and , and . What this decomposition is basically doing is finding the largest chunk of measure that and agree on (that's ), and then subtracting that out from and yields you your and . These measures have no overlap, because if there was overlap, you could put that overlap into the chunk of measure. And, the mass of the "unique to " piece must equal the mass of the "unique to " piece because they must add up to probability distributions, and this quantity is exactly the total variation distance of .
P2.2 Our second claim is that
Why is this? Well, there's an alternate formulation of total variation distance where
As intuition for this, we can pick a function U which is 1 on the support of , and 0 elsewhere. In such a case, we'd get
and then remember that and have disjoint supports, so we get
And any other function in the range wouldn't do as well at attaining different expectation values on and . So that's where the identity comes from. If we try to do the optimal separation but instead restrict to be in , we'd get
and any other utility function in wouldn't do as well at separating the two.
P2.3 Our third claim is that the function which maps to , if goes outside of , and otherwise maps to , corresponds to taking the set of sa-measures that is (the set form of ), and taking the upper completion of it under all signed-measure, b pairs where . Call this an x-sa measure. Ie, if , then one unit of +b is big enough to cancel out 3 units of negative-measure in the signed measure. Clearly, if , and has (is an x-sa measure) then we have
So, adding in the cone of all x-sa pairs like that doesn't actually affect the expectation values of any function bounded in at all. However, for any function which goes over the x upper-bound, you can consider a x-sa measure which concentrates all its large amount of negative measure on a point where the function exceeds the upper bound, and exactly compensates for it with the +b term. Adding this on can make the function, evaluated at said point, have an unboundedly negative expectation value, justifying our choice of for the expectation value.
P2.4 Time for the fourth claim. To build up to it, the monotone hull of a functional is as follows: if is the original functional, then is the monotone hull defined by
Our fourth claim is that, in the set-based value, this operation corresponds to restricting the set of x-sa measures that is to just the a-measures in it. Why? Well, we have
This is because and both agree that any function with negative parts gets value, and both agree on the expectation of any function bounded in , but for functions above 0 which also stray above somewhere, , while .
Therefore, since (when considered as a function, we aren't using the infradistribution reversed ordering here), we have that (higher functions correspond to smaller sets). Now, cannot contain any x-sa-measures with negative measure anywhere in the measure component. For, if there was such a point in there, we could consider a function that assigned extremely high value to the region of negative measure, and 0 value elsewhere, and would attain a negative expectation value on that x-sa measure, which contradicts the nonnegative worst-case expectation value of due to how was defined. So, the set must consist entirely of a-measures. Further, for any function with range in , it is minimized by an a-measure in , and the same point is present in (no extra a-measures added), so the corresponding to that set must assign the exact same expectation value to as and do. Also, any set consisting entirely of a-measures must have its expectation functional be monotone.
So, recapping what we've done so far, we know that . We know that must consist entirely of a-measures, otherwise we'd get a contradiction with monotonicity. Further, (the biggest set that could possibly be) has its expectation functional agree with on the expectations of functions in , and it's monotone like is. Now, if (strict subset), we'd have the functional corresponding to the intersection being strictly below on some function. However is the minimal monotone function that agrees with on the expectations of functions in , so this rule out strict subset, and we must have equality. The monotone hull of an expectation functional corresponds to the restriction to the set to a-measures. Further, we can rewrite the definition
as just
And we're done with this.
Putting claims 3 and 4 together, we can now express what the set is, from our definition of . (interpreted as a set of sa-measures) is just the upper completion of under x-sa measures, those with (this is the restriction to ), and then the intersection of that set with the cone of a-measures (monotone hull), and then upper completion under sa-measures (the restriction to ).
P2.5 Time to begin showing one direction of the iff statement. Remember, we're assuming that all the are induced by a set of probability distributions, they're crisp. We'll start with the easy direction, that
implies
where . (well, technically, this shouldn't just be continuous functions, but lower-semicontinuous functions as well) To begin with, let be arbitrary with bounded in . We can start unpacking
Now, this minimal value must be attained by some minimal point in , which is some probability distribution . So, we have
We can, at this point, select the closest probability distribution to in according to total variation distance, call that . We do our usual shattering of into and , the chunk of measure where and overlap, and the chunk of measure that's unique to . Note that the chunk of measure where and overlap must be supported on histories compatible with since , so we can break things down as
And then we can break down further into and , for the chunk of measure on histories compatible with and incompatible, respectively, yielding
Which can be rephrased as
Now it's time for some inequalities, explained afterwards.
So, for the first line, the first two inequalities are obvious. For the second line, the initial inequality is us invoking the total variation distance variant of x-pseudocausality since is as close as possible to while also being in , and the equality is reexpressing total variation distance in accordance with our second claim. The third line is just shattering and in our way connected with total variation distance, and the fourth line is just canceling. For the fifth line, the first equality is the supremum being attained by a function that's on , and 0 on , as the two measures are disjoint, and the second equality is . Then, for line 6, the inequality is obvious because , and then we just wrap the inf up as an expectation according to , and apply the definition of .
P2.6 Now for the other direction of the iff-statement, going from
to
Using our set-based characterization of inframeasure ordering, we can accurately rephrase our initial statement as
The former set is "take all the minimal points of , convert all their measure on histories incompatible with to the +b term, do closed convex hull and upper completion", and the latter set is "take , do upper completion w.r.t. the cone of x-sa measures, restrict to just the a-measures, and then add in the cone of sa-measures again"
Pick a . When we 1-update it on compatibility with , we get . And said point lies in , which means it must be possible to create by taking a minimal point in (call that one ), and adding an x-sa measure to it. Call the x-sa measure . So, our net result is:
The update of equals plus an x-sa measure. Now, breaking up into its positive and negative parts which are disjoint, and , we can rewrite things as:
Adding to both sides and folding it into , and rearranging a bit and adding parentheses, that second equality can be restated as
Now, is supported entirely over histories compatible with , and is a chunk of negative measure taken out of , so must be supported entirely over histories compatible with . Also, and are disjoint (Jordan decomposition), and is supported entirely over histories incompatible with , so the positive measure and the negative measure must be disjoint. Since is made from by adding on a chunk of positive measure and a chunk of negative measure which are disjoint, we have . At this point, we only have one step left.
For the last step, because is an x-sa measure, we have . Also, because , our inequality turns into
and this gets us our
result. We're done!
Proposition 3: If a utility function is bounded within and a belief function is x-pseudocausal, then translating to (pseudocausal translation) fulfills .
Blessedly, this one is very easy. First, let's recap the translation of a belief function (assumed to be x-pseudocausal) from acausal to pseudocausal. It is
So, applying this, we have
And then we recall that x-pseudocausality is Also, recall that since , and our utility function is bounded in , we get the statement Additionally, . Therefore, the infinimum is attained by itself, and we get
and we're done!
0 comments
Comments sorted by top scores.