DeepSeek-R1 for Beginners
post by Anton Razzhigaev (anton-razzhigaev) · 2025-02-05T18:58:16.282Z · LW · GW · 0 commentsContents
Overview Why is everyone talking about “reasoning” again? What did the DeepSeek team release? The core difference between R1 and R1-Zero DeepSeek-R1-Zero: Pure RL, no dataset, no humans Why no humans? GRPO and the “aha moment” A closer look at GRPO The core idea of GRPO, in plain terms What about the training data for R1-Zero? Readability? Slipped off the radar DeepSeek-R1: a multi-stage training pipeline 1) Cold-start dataset 2) “Reasoning-only” RL 3) Rejection sampling + new SFT 4) Final RL on all scenarios Distillations Conclusion Useful Links None No comments
Why the new generation of “reasoning LLMs” is so exciting, and how the authors trained their model to actually think. (This is a translation of my original post in Russian).
Overview
In recent months, there’s been a growing buzz around “reasoning models,” i.e., large language models (LLMs) that can do more than just continue a text in a plausible style: they solve complex tasks step by step, using an internal chain-of-thought (CoT). The first notable demonstrations of such a technique emerged with OpenAI’s “o1” (though many details remain under wraps). Recently, the DeepSeek team stirred the community by releasing two open-source variants, R1 and R1-Zero, built on top of their own large Mixture-of-Experts (MoE) model, DeepSeek-V3.
I won’t dive into the “whose model is better—o1 or R1?” debate here. Instead, I’ll focus on the main technical highlights of R1, why the Zero version is especially exciting, and how the authors managed to teach the model to reason effectively.

Why is everyone talking about “reasoning” again?
Some folks ask:
“What’s really new here? We’ve known about chain-of-thought prompting for a while; it works decently. Models have long been able to ‘think out loud’ and solve tasks step-by-step.”
True, the idea that LLMs can reason internally isn’t new. It’s been known for some time that if you prompt a language model to “think carefully before answering,” it can increase accuracy. After all, even humans often do math “by the column,” or break down logic step-by-step.
But what’s the catch? Previous models—like GPT-4—hit a limit if you make them think too long. Their performance can decrease due to hallucinations, context window issues, and the infamous “lost in the middle” problem (where content in the middle of a long prompt gets forgotten).
In contrast, the latest generation (o1, R1, etc.) doesn’t show that same limitation: the benefit from chain-of-thought reasoning keeps increasing the longer they “think.” The folks at OpenAI call this phenomenon “test-time scaling” — you can keep throwing more inference compute at these models at runtime (not just more during pretraining), and they keep improving.
What did the DeepSeek team release?
DeepSeek provided eight models:
- DeepSeek-R1
- DeepSeek-R1-Zero
- Plus six distilled versions onto smaller backbones (Qwen 1.5B, 7B, 14B, 32B, Llama 3-8B, 70B).
Both R1 and R1-Zero are based on DeepSeek-V3, a large Mixture-of-Experts model:
- Architecture: A standard decoder-only transformer, but with multi-headed latent attention (MLA) + DeepSeekMoE, plus MTP (Multi-Token Prediction), which allows the model to predict multiple future tokens in parallel.
- Size: 671B parameters overall, but only ~37B of those are “active” for any given token, thanks to MoE gating.
Essentially, R1 and R1-Zero are relatively “small” fine-tunings on top of the big DeepSeek-V3.
The core difference between R1 and R1-Zero
They have the same architecture, but their training regimes differ drastically:
- R1-Zero does not use any supervised fine-tuning (SFT) on human-labeled text. There’s zero curated dataset, no human annotation. It’s purely RL-driven, using unit tests for code tasks, straightforward checks for math solutions, logic puzzle verification, etc. The authors call it “pure reinforcement learning.”
- R1, on the other hand, uses a more classical multi-stage approach to achieve more readable chain-of-thought traces and higher benchmark scores. Interestingly, they do use earlier R1-Zero checkpoints to help generate part of the supervised dataset.
Hence, we have:
- DeepSeek-R1-Zero: RL-only, no supervised step, no human labeling.
- DeepSeek-R1: SFT + RL + additional refinements. More “human-friendly” reasoning, better on standard tasks.
DeepSeek-R1-Zero: Pure RL, no dataset, no humans
Why no humans?
Hiring annotators for RLHF (Reinforcement Learning from Human Feedback) is expensive and slow. In R1-Zero, the authors replaced that human feedback with automated checks. For coding tasks, the reward is pass/fail from the compiler/tests. For math tasks, the reward is a numeric match (the model’s final answer vs. a gold solution). For logic tasks, they run unit tests or puzzle checks. This approach scales quickly and cheaply, without humans in the loop.
GRPO and the “aha moment”
They used an RL algorithm called GRPO (Group Relative Policy Optimization), invented in their earlier “DeepSeekMath” work. Unlike classic PPO (from OpenAI), GRPO doesn’t need a similarly sized reward model to run side-by-side. Instead, it evaluates a “group” of model outputs to figure out which ones are better or worse.
According to the team, the model converges rapidly — around 4,000 RL iterations produce a noticeable jump. Around the midpoint of training, they observe a sudden “aha moment” where the model starts systematically inserting self-reflection, self-checks, and extremely long chain-of-thought sequences (hundreds or even thousands of tokens), even for trivial questions. It also spontaneously starts mixing multiple languages or using pseudo-code as part of its reasoning trace.


From a human perspective, this looks bizarre or even creepy, but the reward algorithm doesn’t care about how “readable” the chain-of-thought is. If producing half-English, half-code monologues improves final accuracy, so be it. We saw something similar with the “QuietStar” approach, where bizarre, seemingly nonsensical token sequences improved correctness.

Ultimately, the genuine “thought” is hidden in the model’s internal layers, and what we read on-screen is more of a side-effect. But indeed, R1-Zero shows that purely RL-based reasoning can spontaneously emerge — complete with multi-language gibberish if that’s how it best solves tasks.
A closer look at GRPO
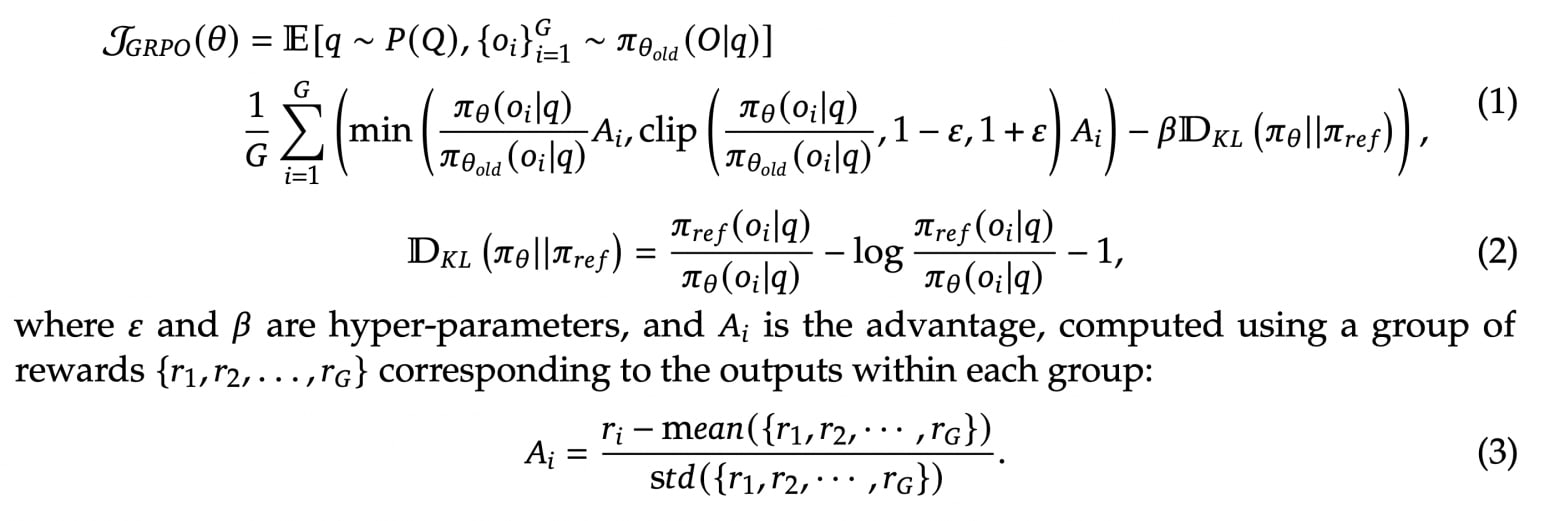
Don’t be scared by the equation. Here’s the idea in simpler terms:
- In typical RL for LLMs (like PPO), you have your main “actor” model (the LLM) and a separate “critic” or reward model. That critic is often nearly as large as the actor, which doubles memory/compute.
- The DeepSeek team wanted to do large-scale RL on big math/coding/logic sets without running a massive reward model in parallel.
- GRPO removes the external reward model entirely. Instead, each “group” of responses for a particular prompt is scored directly (e.g., do the code tests pass?), and the model sees which answers in the group are above or below average. Good answers get a positive advantage signal; bad ones get negative.
- They then apply a PPO-like update but relative to the old policy.
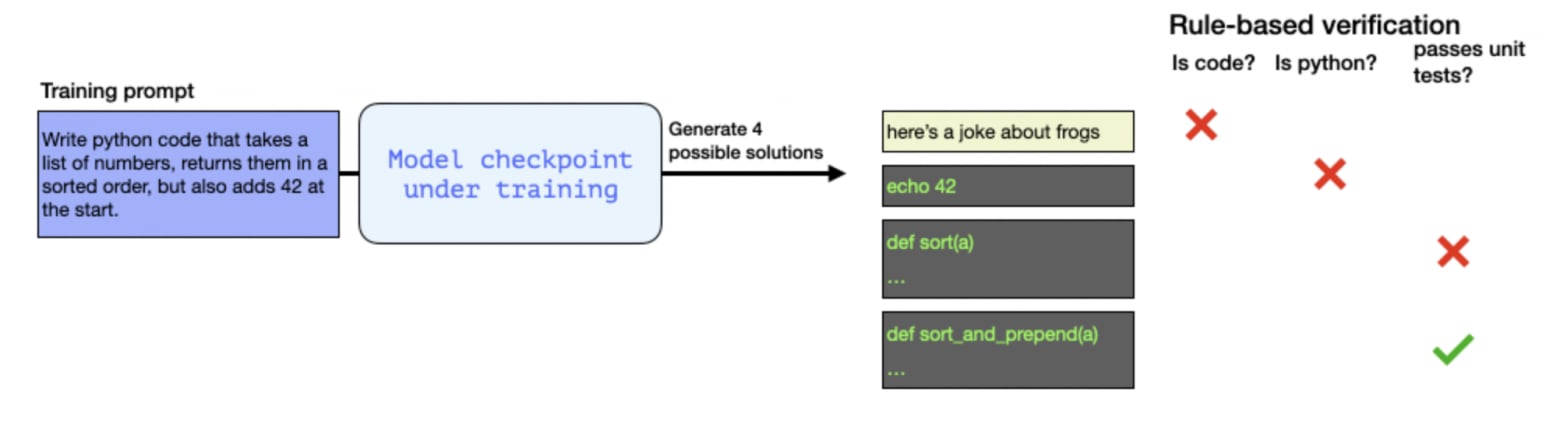
The core idea of GRPO, in plain terms
- Form a group. For each question (prompt), the old policy (model) generates not just one answer but an entire group G of answers.
- Compute rewards. For each answer, we measure a reward—by running the code through automated tests, comparing numerical results for math problems, etc.
- Calculate ‘relative’ advantages. Let ri be the reward for the i-th answer. Using the GRPO advantage formula, we see how each generated candidate stacks up. Answers with ri above the group average get a positive advantage (they’re reinforced), while those below average get penalized.
- Update the policy. We then apply standard PPO-like steps: compute the ratio
- , clip updates to keep them stable, and introduce a KL penalty so the model doesn’t stray too far from the initial checkpoint.
The net benefits:
- Huge GPU savings: no separate large reward model.
- Less reward hacking: because the baseline is just the average performance in the group.
- Easier scaling: if you can automatically check correctness (like test-based pass/fail or numeric answer matching), you can train on hundreds of thousands of tasks cheaply.
What about the training data for R1-Zero?
There’s no single curated dataset. They basically aggregated a bunch of tasks from standard benchmarks: MATH, CodeForces, MMLU, GPQA, plus synthetic tasks that can be automatically verified. They feed these tasks into the RL pipeline. That’s it. No human-labeled chain-of-thought at all.
Readability? Slipped off the radar
Yes, R1-Zero’s chain-of-thought is quite messy. It randomly flips between languages, adds weird code blocks, or random jargon. Because the RL reward only checks final correctness, the model can produce a borderline unreadable solution path. This is reminiscent of approaches where the LLM effectively invents a private “internal language.” For purely automated tasks, that’s a feature, not a bug.
But if you want to share the chain-of-thought with humans or trust it for interpretability, it becomes a problem. Hence the subsequent “R1” version, which reintroduces some supervised training to produce more coherent, readable reasoning.
DeepSeek-R1: a multi-stage training pipeline
Unlike R1-Zero’s purely RL approach, R1 uses a standard “SFT + RL + final fine-tuning” recipe. Let’s break it down.
1) Cold-start dataset
To avoid the “chaotic start” problem in RL (where the model doesn’t even know basic reasoning templates), they built a small “cold-start” corpus with a few thousand tasks plus detailed chain-of-thought solutions.
- They generated these from earlier models (including R1-Zero) by prompting them to “explain the solution in detail.”
- They then filtered out incorrect or low-quality outputs.
- They standardized the format to “reasoning block + final concise answer.
- DeepSeek-V3 (the base MoE model) is then fine-tuned on this small set (~10k–15k examples across math, logic, code, etc.). The result is a checkpoint that can already produce a decent “long solution + final result.” That sets the stage for the next RL step.
2) “Reasoning-only” RL
The second step is basically R1-Zero’s approach, but starting from a model that already has some coherent chain-of-thought ability.
They focus on tasks with fully automatable checks:
- Math (MATH, CNMO, AIME, etc.) — numeric match for final answers.
- Code (LeetCode-style, Codeforces) — pass/fail on tests.
- Logic, science tasks — if they have a single correct solution, they can do a direct string or numeric comparison.
- Language consistency: a small penalty for producing chaotic code-switching or failing to follow a Markdown format. This penalty lowers raw accuracy a bit, but yields more “human-friendly” outputs.
They run RL for tens of thousands of iterations. As with R1-Zero, an “aha moment” typically appears mid-training — the chain-of-thought grows longer, more self-reflective, and the model starts spontaneously verifying its own answers. But this time, because we started from a checkpoint that already “knows” how to be coherent, we get less gibberish.
3) Rejection sampling + new SFT
Once the RL step converges, they generate a large synthetic dataset from that RL-finetuned model. For each task, they produce multiple solutions, keep only the correct ones (via the same test-based filter), and discard the rest. They also add in “various other” domains from the broader DeepSeek-V3 SFT corpus (factual QA, general writing tasks, style prompts) to avoid overfitting on math/code alone.
The result is a 600k+ example set (the majority is “verified-correct reasoning,” with some general tasks). Then they do another supervised fine-tuning pass on top of DeepSeek-V3, effectively “absorbing” the best RL solutions, plus preserving broader capabilities.
4) Final RL on all scenarios
Finally, they do one more RL run on the entire range of tasks, including general prompts. On math/coding tasks, correctness is still pass/fail. For open-ended tasks, they rely on a preference model to judge helpfulness/harmlessness (like standard RLHF). The end result is the DeepSeek-R1 checkpoint — published for the community. Yes, it’s complicated (there’s a lot of RL-SFT alternation and synthetic data generation), but the diagram from SirrahChan presents a nice overview.
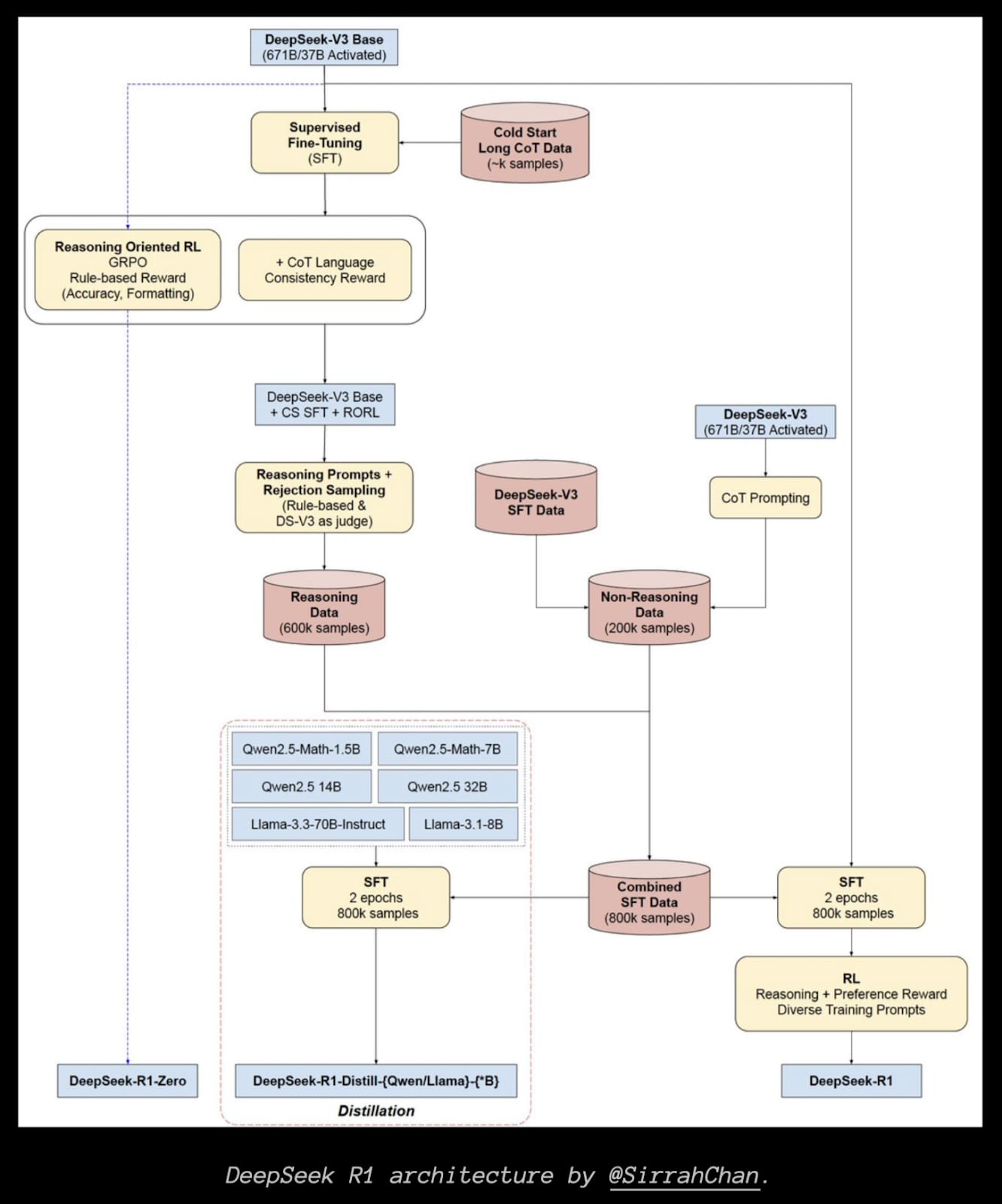
Distillations
Big thanks to the authors for not being stingy: they also trained and released six “R1-distilled” models on smaller backbones (Qwen 1.5B, 7B, 14B, 32B, Llama 3-8B, 70B). The procedure is straightforward:
- They take the big R1 model and generate tons of chain-of-thought solutions.
- They fine-tune smaller models on that data.
They note that distillation works better here than direct RL on a small model, because smaller LLMs often struggle to spontaneously discover advanced chain-of-thought or “aha” reflection by themselves. It’s another reminder that certain reasoning behaviors may be emergent properties of large-scale models.
Conclusion
DeepSeek has unveiled two new “reasoning” models:
- R1-Zero — a fully RL-trained approach with no human annotation.
- R1 — a multi-stage blend of SFT and RL, producing more readable CoT and higher benchmarks.
They’re part of a broader wave of “reasoning LLMs.” The main difference from OpenAI’s o1/o3 is that R1(-Zero) are open-source, with a tech report that’s quite detailed about architecture, training algorithms (GRPO), and how they generate synthetic chain-of-thought data.
The big leap is that the Zero variant removes humans from the loop altogether, letting the model effectively develop its own chain-of-thought, sometimes in a strange mixed language or pseudo-code. That might be a direct path to cheap and fast RL-based reasoning improvements without the bottleneck of human feedback.
I’ll be keeping an eye on how this evolves, and if you’re also curious, feel free to follow my Telegram channel AbstractDL for more updates (though it’s mostly in Russian). Thanks for reading!
Useful Links
- DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning (Original Paper)
- Jay Alammar’s Explanation of DeepSeek-R1
- Tutorial for Reproducing DeepSeek-R1-Mini
- HuggingFace Checkpoints
- DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Thanks for reading!
0 comments
Comments sorted by top scores.