Brief analysis of OP Technical AI Safety Funding
post by 22tom (thomas-barnes) · 2024-10-25T19:37:41.674Z · LW · GW · 5 commentsContents
TL;DR Method Results Grants by Research Agenda Grants by Cluster Key Findings (1) Evaluations & Benchmarking make up 2/3rds of all OP TAIS funding in 2024 (2) Excluding Evaluations & Benchmarking, OP grants for TAIS have fallen significantly (3) Most TAIS funding is focused on "investment" rather than direct approaches to AI safety None 5 comments
TL;DR
I spent a few hours going through Open Philanthropy (OP)'s grant database. The main findings were:
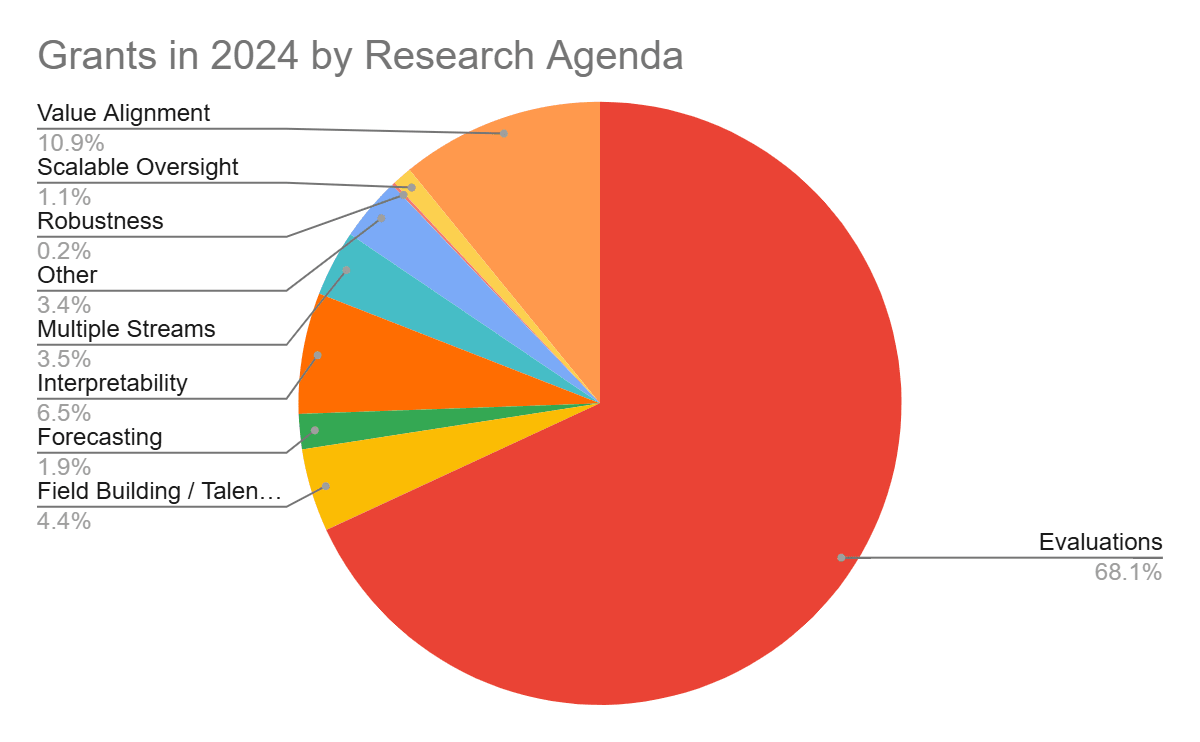
- Open Philanthropy has made $28 million grants for Technical AI Safety (TAIS) in 2024
- 68% of these are focused on evaluations / benchmarking. The rest is split between interpretability, robustness, value alignment, forecasting, field building and other approaches.
- OP funding for TAIS has fallen from a peak in 2022
- Excluding funding for evaluations, TAIS funding has fallen by ~80% since 2022.
- A majority of TAIS funding is focused on "meta" rather than "direct" safety approaches
My overall takeaway was that very few TAIS grants are directly focused on making sure systems are aligned / controllable / built safely.[1]
Method
I:
- Downloaded OP's list of grants
- Filtered for "Potential Risks from Advanced AI"
- Classified grants as either "Policy" or "Non-Policy"
- Within "Non-Policy", classified grants by different focus areas (e.g. evaluations, interpretability, Field building, "Multiple" and "Other")
- In most cases I classified just from the grant name; occasionally I dug for a bit more info. There are definitely errors, and cases where grants could be more clearly specifcied.
- Combined focus areas into "Clusters" - "Empirical", "Theory", "Forecasting & Evaluating", "Fieldbuilding" and "Other"
- Created charts
Results
Grants by Research Agenda
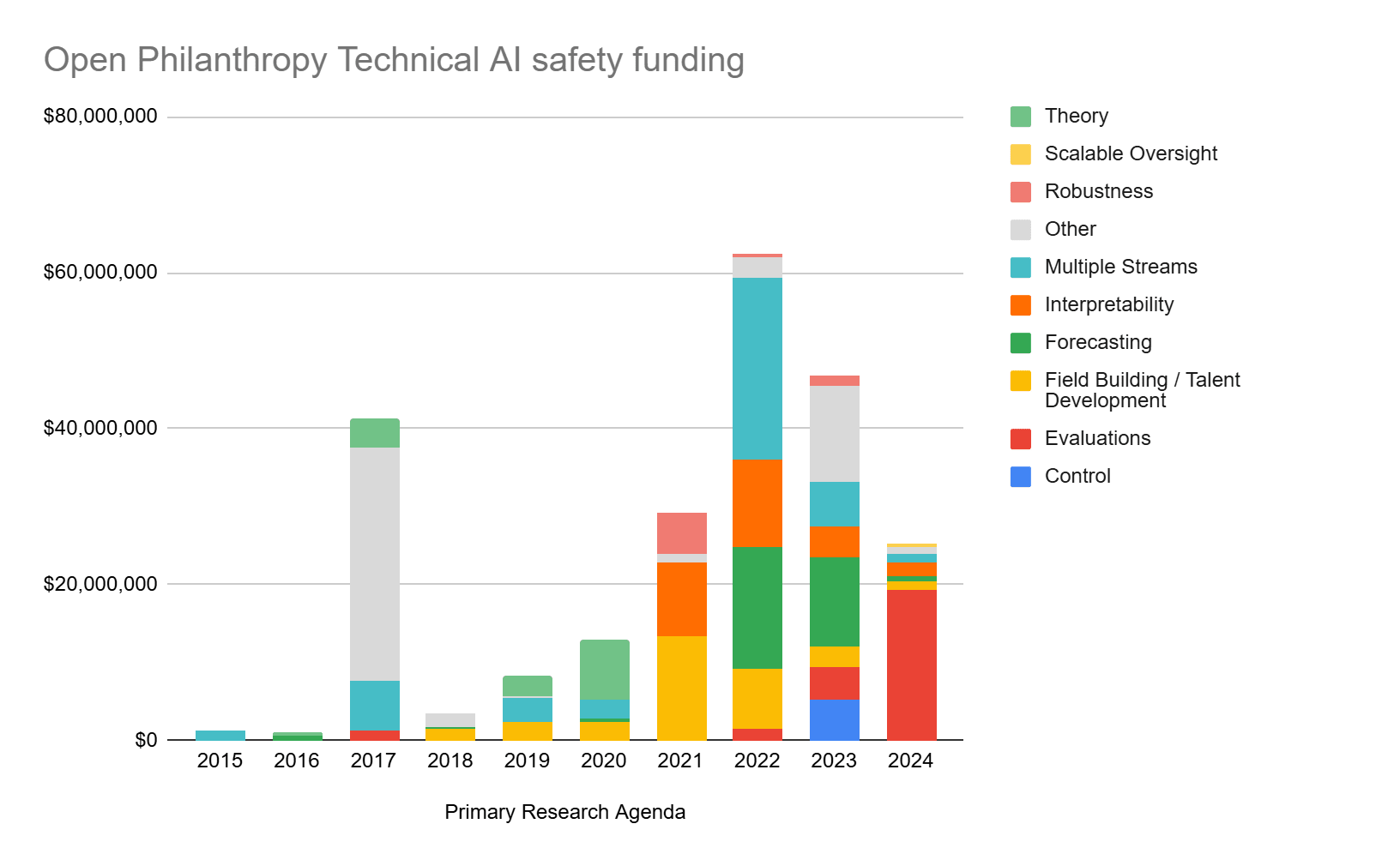
Grants by Cluster
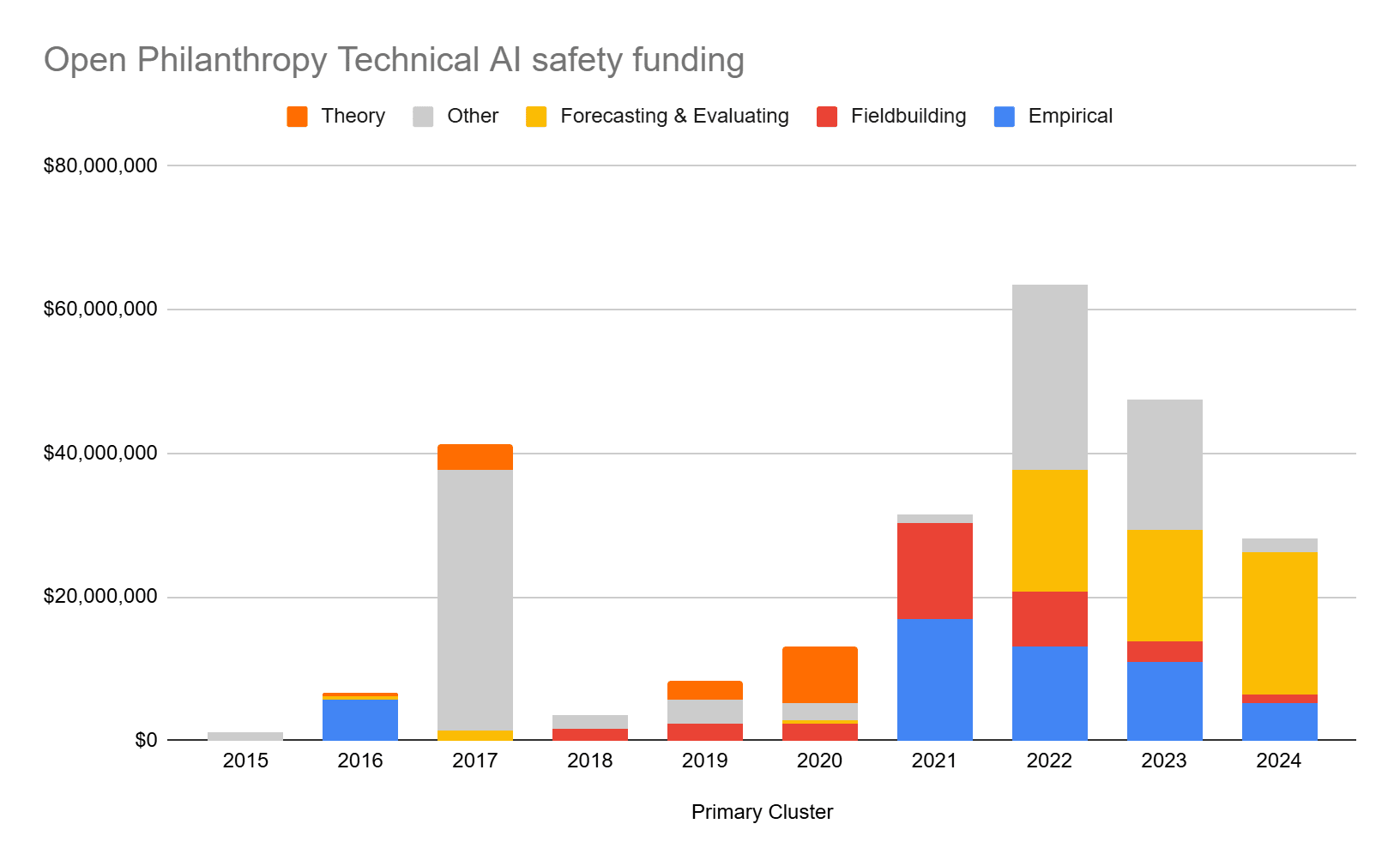
Full data available here
Key Findings
(1) Evaluations & Benchmarking make up 2/3rds of all OP TAIS funding in 2024
Most of these grants are related to the RFP on LLM Benchmarks.
(2) Excluding Evaluations & Benchmarking, OP grants for TAIS have fallen significantly
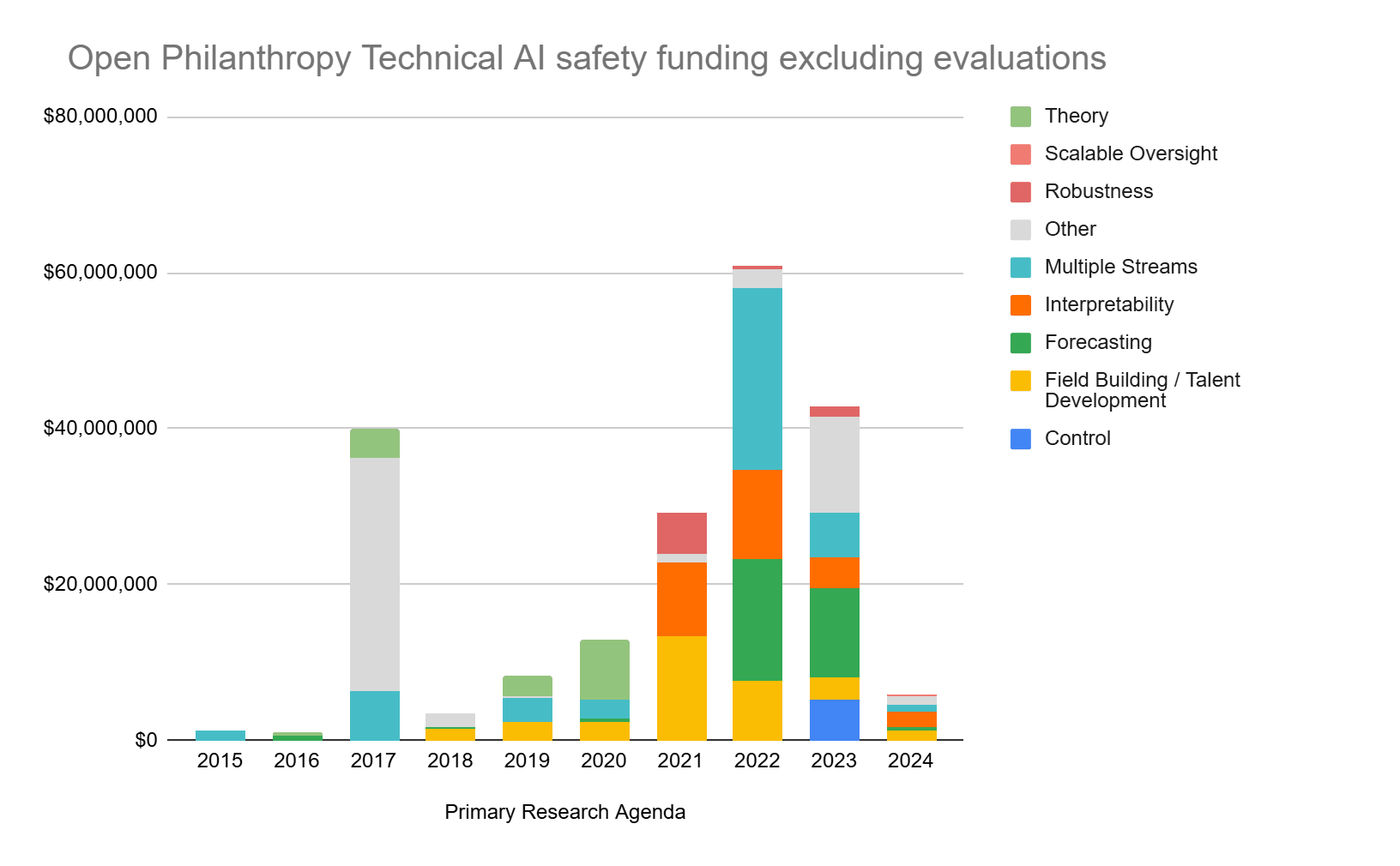
- 2022 Funding (excluding evaluations): $62,089,504
- 2023 Funding (excluding evaluations): $43,417,089
- 2024 Funding (projected, excluding evaluations): $10,808,390
- 82.6% reduction vs 2022
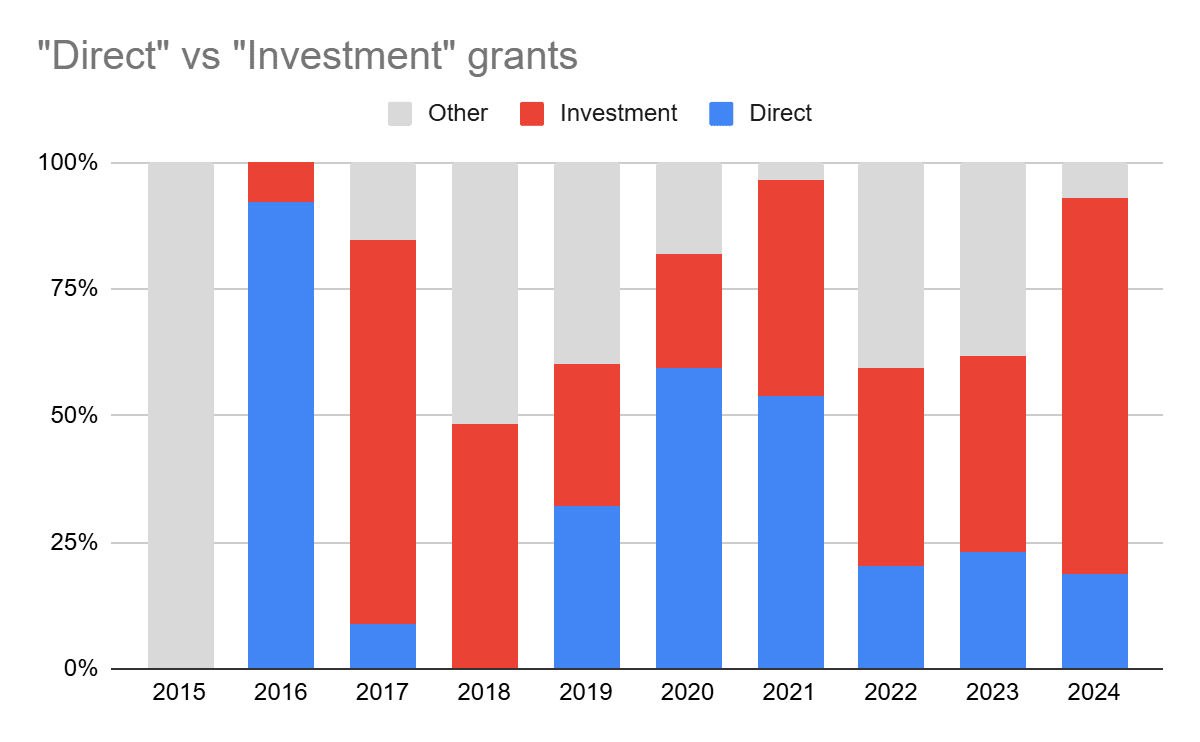
(3) Most TAIS funding is focused on "investment" rather than direct approaches to AI safety
I classify grants into two broad buckets:
- "Direct" - grants for research agendas which aim to improve safety today (e.g. Interpretability, Control, Robustness, Value Alignment, Theory)
- "Investment" - grants which pay off through future impact - e.g. Field building, Talent development, reducing uncertainty (via Forecasting & Evaluation)
- ^
More cynically: I worry the heavy focus on evaluations will give us a great understanding of how / when scary AI systems emerge. But that won't (a) prevent the scary AI systems being built, or (b) cause any action if they are built (see also Would catching your AIs trying to escape convince AI developers to slow down or undeploy? [LW · GW])
5 comments
Comments sorted by top scores.
comment by Chris_Leong · 2024-10-26T16:42:49.095Z · LW(p) · GW(p)
That’s useful analysis. Focusing so heavily on evals seems like a mistake given how AI Safety Institutes are focused on evals.
comment by maxnadeau · 2024-11-04T23:47:49.346Z · LW(p) · GW(p)
(I work at Open Phil on TAIS grantmaking)
I agree with most of this. A lot of our TAIS grantmaking over the last year was to evals grants solicited through this RFP. But I want to make a few points of clarification:
- Not all the grants that have been or will be approved in 2024 are on our website. For starters, there are still two months left in the year. But also, there are some grants that have been approved, but haven't been put on the website yet. So $28 million is an modest underestimate, so it isn't directly comparable to the 2022/2023 numbers.
- I agree that evals don't create new technological approaches to making AIs safer, but I think there are lots of possible worlds where eval results create more willpower and enthusiasm for putting safeguards in place (especially when those safeguards take work/cost money/etc). Specifically, I think evals can show people what a model is capable of, and what the trend lines are over time, and these effects can (if AIs are increasingly more capable) get people to invest more effort in safeguards. So I don't agree with the claim that evals won't "cause any action if they are built", and I also disagree that "very few TAIS grants are directly focused on making sure systems are aligned / controllable / built safely".
I appreciate you examining our work and giving your takes!
comment by BrianTan · 2024-12-05T04:17:09.686Z · LW(p) · GW(p)
Thanks for this analysis! A minor note: you're probably aware of this, but OpenPhil funds a lot of technical AI safety field-building work as part of their "Global Catastrophic Risks Capacity Building" grants. So the proportion of field-building / talent-development grants would be significantly higher if those were included.
comment by Bogdan Ionut Cirstea (bogdan-ionut-cirstea) · 2024-12-03T11:22:30.668Z · LW(p) · GW(p)
Thanks for this post!
This looks much worse than I thought it would, both in terms of funding underdeployment, and in terms of overfocusing on evals.
comment by MichaelDickens · 2024-10-26T16:32:09.103Z · LW(p) · GW(p)
Thank you, this information was useful for a project I'm working on.