Forecasting ML Benchmarks in 2023
post by jsteinhardt · 2022-07-18T02:50:16.683Z · LW · GW · 20 commentsContents
MATH Background Key Considerations Analyzing Key Consideratoins Why did Minerva do well? How much low-hanging fruit is there? What kinds of errors is Minerva making? Do they seem easy or hard to fix? How much additional data could be generated for training? Could other methods improve mathematical reasoning? Historical Rate of Progress on MATH Historical Rate of Progress on Other Datasets How much will people work on improving MATH performance? Bottom-Line Forecast MMLU Forecast Background Key Considerations Analyzing Key Considerations Historical Rate of Progress on MMLU Historical Rate of Progress on Other Datasets Combining Chinchilla and Minerva Other Low-Hanging Fruit How much will people work on improving MMLU performance? Bottom-Line Forecast Looking Ahead None 22 comments
Thanks to Collin Burns, Ruiqi Zhong, Cassidy Laidlaw, Jean-Stanislas Denain, and Erik Jones, who generated most of the considerations discussed in this post.
Previously, I evaluated the accuracy of forecasts about performance on the MATH and MMLU (Massive Multitask) datasets. I argued that most people, including myself, significantly underestimated the rate of progress, and encouraged ML researchers to make forecasts for the next year in order to become more calibrated.
In that spirit, I’ll offer my own forecasts for state-of-the-art performance on MATH and MMLU. Following the corresponding Metaculus questions, I’ll forecast accuracy as of June 30, 2023. My forecasts are based on a one-hour exercise I performed with my research group, where we brainstormed considerations, looked up relevant information, formed initial forecasts, discussed, and then made updated forecasts. It was fairly easy to devote one group meeting to this, and I’d encourage other research groups to do the same.
Below, I’ll describe my reasoning for the MATH and MMLU forecasts in turn. I’ll review relevant background info, describe the key considerations we brainstormed followed, analyze those considerations, and then give my bottom-line forecast.
MATH
Background
Metaculus does a good job of describing the MATH dataset and corresponding forecasting question:
The MATH dataset is a dataset of challenging high school mathematics problems constructed by Hendrycks et al. (2021). Hypermind forecasters were commissioned to predict state-of-the-art performance on June 30, 2022, '23, '24, and '25. The 2022 result of 50.3% was significantly outside forecasters' prediction intervals, so we're seeing what the updated forecasts are for 2023, '24, and '25.
What will be state-of-the-art performance on the MATH dataset in the following years?
These questions should resolve identically to the Hypermind forecasts:
"These questions resolve as the highest performance achieved on MATH by June 30 in the following years by an eligible model.
Eligible models may use scratch space before outputting an answer (if desired) and may be trained in any way that does not use the test set (few-shot, fine tuned, etc.). The model need not be publicly released, as long as the resulting performance itself is reported in a published paper (on arxiv or a major ML conference) or through an official communication channel of an industry lab (e.g. claimed in a research blog post on the OpenAI blog, or a press release). In case of ambiguity, the question will resolve according to Jacob Steinhardt’s expert judgement."
It’s perhaps a bit sketchy for me to be both making and resolving the forecast, but I expect in most cases the answer will be unambiguous.
Key Considerations
Below I list key considerations generated during our brainstorming:
- Why did Minerva do well on MATH? Is it easy to scale up those methods? Is there other low-hanging fruit?
- What kinds of errors is Minerva making? Do they seem easy or hard to fix?
- Minerva was trained on arXiv and other sources of technical writing. How much additional such data could be generated?
- Are there other methods that could lead to improvement on mathematical reasoning?
- Possibilities: self-supervised learning, verifiers, data retrieval
- Base rates: What has been the historical rate of progress on MATH?
- Base rates: How does progress typically occur on machine learning datasets (especially NLP datasets)? If there is a sudden large improvement, does that typically continue, or level off?
- How much will people work on improving MATH performance?
Analyzing Key Consideratoins
Why did Minerva do well? How much low-hanging fruit is there?
Minerva incorporated several changes that improved performance relative to previous attempts:
- Chain-of-thought prompting: this started in earnest with PALM, which Minerva is based on. There are straightforward ways to continue improving on it, e.g. chain-of-thought is currently few-shot and one could fine-tune to improve further, or one could use follow-up prompts to try to fix errors in the first prompt’s reasoning. It seems to be an active area of interest in ML so it’s likely there will be further progress here.
- Based on Figure 10 of the PaLM paper, chain-of-thought currently gives a 40% boost on GSM-8k (perhaps an easy data set), and gains ranging from around 5%-25% on other tasks.
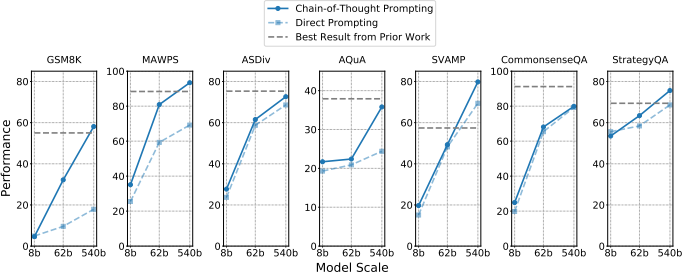
- Based on Figure 10 of the PaLM paper, chain-of-thought currently gives a 40% boost on GSM-8k (perhaps an easy data set), and gains ranging from around 5%-25% on other tasks.
- Training on more math data: Minerva uses continued pre-training on math and other technical data. Right now this data is 5% as large as the original pretraining corpus. If there is more available data, it could be a straightforward way to get further improvements (see below for estimates of available data).
- Large models: the largest version of Minerva is very large (540B parameters) and does 7% better than the 62B parameter model. It seems like it would be relatively expensive to continue improving performance solely by scaling up (but see below on undertraining).
- Minerva's web scraping avoids filtering out math and LaTeX, while previous scrapers often did.
- Using majority vote to aggregate over multiple generated solutions improves performance significantly: by almost 17% for both the 62B and 540B parameter models. “Intuitively, the reason majority voting improves performance is that while there are many ways to answer a question incorrectly, there are typically very few ways to answer correctly.”
- One could imagine a better aggregation method as majority vote is fairly simple. How much better could we hope to do? The Minerva paper estimates that the right answer (with correct reasoning) occurs among the top 256 samples at least 68% of the time for the 62B parameter model, which is 40% above the top-1 baseline and 25% above the majority vote method. So it seems very plausible to improve this further.
Other log-hanging fruit:
- Minerva is based on PALM, which was significantly undertrained according to the Chinchilla paper. So at the same compute budget, a better-trained model would have higher performance. How much does this matter? Based on Figure 3 of the PaLM paper, it looks like Chinchilla is about as good as a PaLM-style model that is 4x bigger.
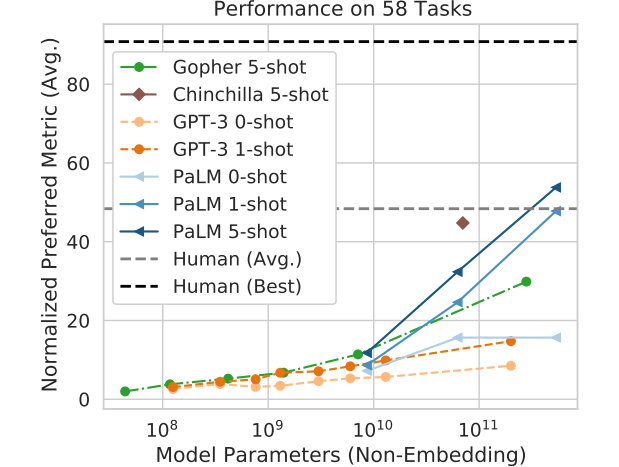
I’d guess that corresponds to about a 4% improvement in the case of the MATH dataset (since making the model 8.7x bigger was a 7% improvement). - Minerva itself is also undertrained: Table 2 of the Minerva paper states that it only used 26B tokens during fine-tuning, which is less than one epoch (the fine-tuning dataset had 38.5B tokens). I wouldn't be surprised if training further also gave a ~5% improvement, although the actual amount could be significantly larger or smaller.
Overall summary: the lowest-hanging fruit towards further improvement would be (in order):
- Improving over majority vote (up to 25% improvement, easy to imagine an 8% improvement),
- fine-tuning on more data (unknown improvement, intuitively around 5%),
- a better-trained version of PaLM (expensive so not clear it will happen, but probably a 4% improvement),
- improving chain-of-thought prompting (easy to imagine a 3-5% improvement, possible to imagine a 10% improvement),
- training a larger model (not obvious it will happen, but probably a couple percent improvement if so),
- perhaps small gains from improving web scraping as well as tokenization.
Aggregating these, it feels easy to imagine a >14% improvement, fairly plausible to get >21%, and >28% doesn’t seem out of the question. Concretely, conditional on Google or some other large organization deciding to try to further improve MATH performance, my prediction of how much they would improve it in the next year would be:
- 25th percentile: 14%
- 50th percentile: 21%
- 80th percentile: 28%
(This prediction is specifically using the "how much low-hanging fruit" frame. I'll also consider other perspectives, like trend lines, and average with these other perspectives when making a final forecast.)
What kinds of errors is Minerva making? Do they seem easy or hard to fix?
As noted above, the 62B parameter model has best-of-256 performance (filtered for correct reasoning) of at least 68%. My guess is that the true best-of-256 performance is in the low-to-mid 70s for 62B. Since Minerva-540B is 7% better than Minerva-62B, the model is at least capable of generating the correct answer around 80% of the time.
We can also look at errors by type of error. For instance, we estimated that calculation errors accounted for around 30% of the remaining errors (or around 15% absolute performance). These are probably fairly easy to fix.
In the other direction, the remaining MATH questions are harder than the ones that Minerva solves currently. I couldn’t find results grouped by difficulty, but Figure 4 of the Minerva paper shows lower accuracy for harder subtopics such as Intermediate Algebra.
How much additional data could be generated for training?
We estimated that using all of arXiv would only generate about 10B words of mathematical content, compared to the 20B tokens used in Minerva. At a conversation rate of 2 tokens/word, this suggests that Minerva is already using up most relevant content on arXiv. I’d similarly guess that Minerva makes use of most math-focused web pages currently on the internet (it looks for everything with MathJax). I’d guess it’s possible to find more (e.g. math textbooks) as well as to synthetically generate mathematical exposition, and probably also to clean the existing data better. But overall I’d guess there aren’t huge remaining gains here.
Could other methods improve mathematical reasoning?
For math specifically, it’s possible to use calculators and verifiers, which aren’t used by Minerva but could further improve performance. Table 9 of the PaLM paper shows that giving PaLM a calculator led to a 4% increase in performance on GSM8K (much smaller than the gains from chain-of-thought prompting).

In the same table, we see that GPT-3 gets a 20% gain using a task-specific verifier. Given that the MATH problems are fairly diverse compared to GSM8K, I doubt it will be easy to write an effective verifier for that domain, and it’s unclear whether researchers will seriously try in the next year. The calculator seems more straightforward and I’d give a ~50% chance that someone tries it (conditional on there being at least one industry lab paper that focuses on math in the next year).
Historical Rate of Progress on MATH
- As of 03/05/2021: 6.9%.
- As of 06/30/2022: 50.3%.
This is a roughly 2.9% accuracy gain per month (but almost certainly will be slower in future). Taking this extrapolation literally would give 85.1% for 06/30/2023.
Historical Rate of Progress on Other Datasets
The Dynabench paper plots historical progress on a number of ML datasets, normalized by baseline and ceiling performance (see Figure 1, reproduced below).
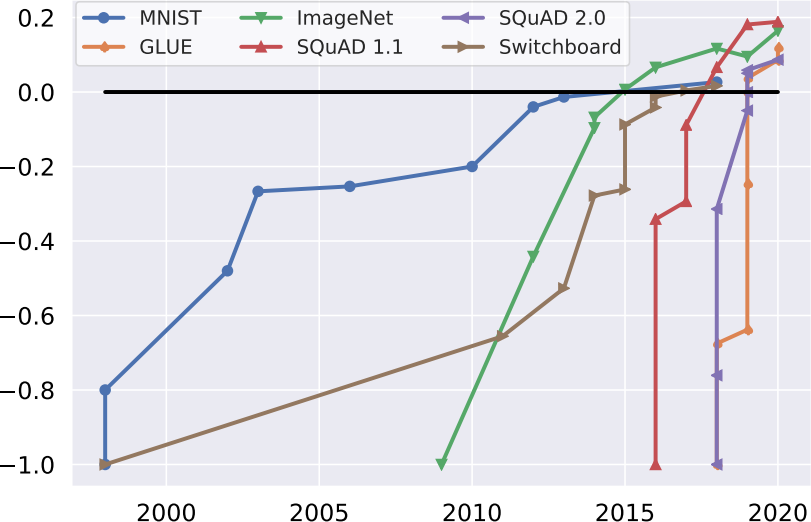
We seem to often see immediate huge gains, while the next ones are somewhat slower.
Here’s another benchmark for reference. It got 67% -> 86% within 1-2 months, then took 4 months to break 90%.
Overall, it seems clear we should expect some sort of slow-down. In some cases, the slow-down was huge. I think progress should not slow down that much in this case since there’s still lots of low-hanging fruit. Maybe progress is 60% as fast as before? So that would give us 71% on 06/30/2023.
How much will people work on improving MATH performance?
Two sources of progress:
- General increased scaling of language models
- Specific efforts to improve math / quantitative reasoning
How many language papers have been released historically?
- GPT-2: 02/2019 (OpenAI)
- GPT-3: 03/2020 (OpenAI)
- UnifiedQA: 05/2020 (AI2)
- Gopher: 12/2021 (DeepMind)
- Chinchilla: 03/2022 (DeepMind)
- PaLM: 04/2022 (Google)
(This only counts language models that achieved broad state-of-the-art performance. E.g. I'm ignoring OPT, BLOOM, GPT-J, etc.)
By this count, there have been 6 papers since the beginning of 2019. So base rate of around 1.7 / year. If we use a Poisson process, predicts that we will see 0 new papers with probability 18%, 1 with probability 31%, 2 with probability 26%, and >2 with probability 25%.
What about math-specific work? Harder to measure what “counts” (lots of math papers but how many are large-scale / pushing state-of-the-art?). Intuitively I’d expect more like 1.1 such papers per year. So around 33% chance of zero, 37% chance of 1, 20% chance of 2, 10% chance of >2.
An important special case is if there are no developments on either the language models or the math-specific front. Under the above model these have probabilities 18% and 33%, and are probably positively correlated. Additionally, it's possible that language model papers might not bother to evaluate on MATH or might not use all the ideas in the Minerva paper (and thus fail to hit SOTA). Combining these considerations, I’d forecast around a 12% chance that there is no significant progress on MATH on any front.
Bottom-Line Forecast
From the above lines of reasoning, we have a few different angles on the problem:
- Looking at rates of publication of language model papers suggests a 12% chance of no major developments at all (e.g. between 0% and 5% progress).
- Thinking in detail about possible sources of improvements gives something like 25th percentile: 14% gain (to 64%); 50th percentile: 21% gain (to 71%); 80th percentile: 28% gain (to 78%). But these were all conditional on some progress happening, so should adjust down by the 12% chance of no progress at all.
- Extrapolating base rates and adjusting for slowdowns in progress gives a forecast of 71% (with probably a ceiling forecast of 85%).
- Looking at how easy it would be to fix current flaws suggests that 15% should be relatively easy (calculation errors). Up to 30% would "only" require better re-ranking (i.e., a correct solution is in the top 256 ones generated).
- I’ve underestimated progress in the past so should potentially adjust upwards.
If I intuitively combine these, I produce the following forecast:
- 12th percentile: 55%
- 33rd percentile: 63%
- 50th percentile: 71%
- 80th percentile: 80%
- 90th percentile: 89%
The Metaculus community is at 74 median, upper 75% of 83. So I’ll adjust up slightly more. New forecast adjusted towards community prediction:
- 10th percentile: 55%
- 33rd percentile: 66%
- Median: 73%
- 80th percentile: 84%
- 90th percentile: 90%
Rough approximation of this distribution on Metaculus (red is me, green is the community prediction):
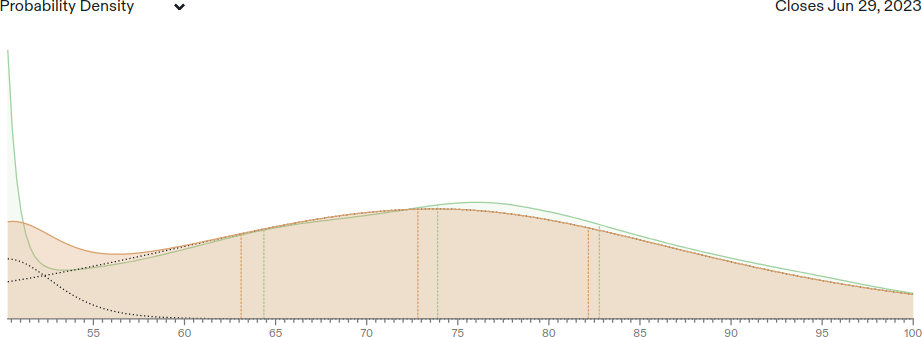
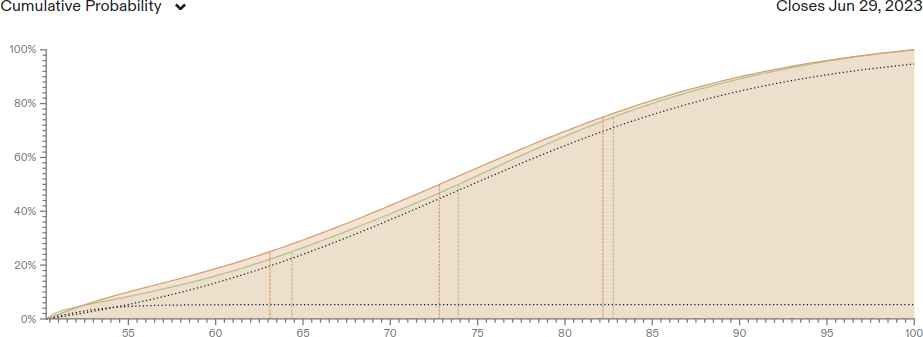
Interestingly, Hypermind forecasts a much smaller median of 64.1%.
MMLU Forecast
Background
Again borrowing from Metaculus:
The Massive Multitask Language Understanding (MMLU) dataset is a dataset of high school, college, and professional multiple choice exams that test expert subject knowledge. It was constructed by Hendrycks et al. (2021). Hypermind forecasters were commissioned to predict state-of-the-art performance on June 30, 2022, '23, '24, and '25. The 2022 result of 67.5% was significantly outside forecasters' prediction intervals, so we're seeing what the updated forecasts are for 2023, '24, and '25.
What will be state-of-the-art accuracy on the Massive Multitask dataset in the following years?
These questions should resolve identically to the Hypermind forecasts:"These questions resolve as the highest performance achieved on MMLU by June 30 in the following years by an eligible model. Eligible models must not have been specifically trained on data from the MMLU dataset. A model need not be publicly released, as long as the resulting performance itself is reported in a published paper (on arxiv or a major ML conference) or through an official communication channel of an industry lab (e.g. claimed in a research blog post on the OpenAI blog, or a press release). If there's uncertainty about whether something counts, we will defer to this leaderboard."
Key Considerations
At a high level, these are fairly similar to those of the MATH dataset. Since more people have worked on MMLU and there’s been steadier progress, we rely more on base rates and less on detailed considerations of how one could improve it further.
- Base rate: What has been the progress on MMLU to date?
- Base rate: How does progress typically occur on machine learning datasets (especially NLP datasets)? If there is a sudden large improvement, does that typically continue, or level off? [Same as previous consideration for MATH]
- The two models Chinchilla and Minerva do well on different subsets of MMLU. What happens if we combine them together?
- How much other low-hanging fruit is there?
- How much will people work on improving MMLU performance?
Analyzing Key Considerations
Historical Rate of Progress on MMLU
Below is a time series of MMLU results, taken from the MMLU leaderboard (note MMLU was published in Jan. 2021). I've bolded few-shot/zero-shot results.
| Model | Date | Average |
|---|---|---|
| Chinchilla (70B, few-shot) | Mar 29, 2022 | 67.5 |
| Gopher (280B, few-shot) | Dec 8, 2021 | 60.0 |
| GPT-3 (175B, fine-tuned) | Jul 22, 2020 | 53.9 |
| UnifiedQA | Oct 7, 2020 | 48.9 |
| GPT-3 (175B, few-shot) | Jul 22, 2020 | 43.9 |
| GPT-3 (6.7B, fine-tuned) | 43.2 | |
| GPT-2 | 32.4 |
If we restrict to few-shot results, we see:
- +7.5 from Dec -> Mar (3 months)
- +11.1 from Oct ‘20 -> Dec ‘21 (14 months)
- +16.1 from July ‘20 -> Dec ‘21 (17 months)
It's not clear which time horizon is best to use here. I came up with an approximate base rate of 1.2 pts / month.
Other notes:
- Source of improvements: better training, more compute, maybe better pretraining data?
- Fine-tuning seems to add 10 points, so a potentially easy source of low-hanging fruit.
Historical Rate of Progress on Other Datasets
We analyzed this already in the previous section on MATH. It seems like there's usually an initial period of rapid progress, followed by a slow-down. However, MMLU has had enough attempts that I’d say it’s past the “huge initial gains” stage. Therefore, I don’t expect as much as a level-off compared to MATH, even though there is less obvious low-hanging fruit---maybe we'll get 75% as fast of progress as before. This would suggest +10.8 points over the next year.
Combining Chinchilla and Minerva
The current SOTA of 67.5 comes from Chinchilla. But Minerva does much better than Chinchilla on the MMLU-STEM subset of MMLU. Here’s a rough calculation of how much taking max(Chinchilla, Minerva) would improve things:
- Chinchilla gets 54.9% on MMLU-STEM
- PaLM gets 58.7%
- Minerva gets 75.0% with majority vote, 63.9% without
- STEM is 19 / 57 of the tasks.
So adding in Minerva would add (75% - 54.9%) * 19/57 = 6.7% points of accuracy.
Will this happen? It's not obvious, since PaLM is owned by Google and Chinchilla is owned by DeepMind. At least one org would need to train a new model. I think there’s a good chance this happens, but not certain (~65% probability).
Other Low-Hanging Fruit
Result of a quick brainstorm:
- External calculators + other STEM-specific improvements (similar to MATH)
- Some of the chain-of-thought improvements could help with other parts of MMLU (beyond STEM) especially if it helps with error correction.
- General knowledge retrieval
In addition, the STEM-specific improvements (e.g. Minerva) will continue to improve MMLU-STEM. Based on the MATH forecast above, on median I expect about half as much improvement over the next year as we saw from the Minerva paper, or around another 3% improvement on MMLU overall (since Minerva gave a 6.7% improvement).
We thought it was possible but unlikely that there are significant advances in general knowledge retrieval in the next year that also get used by MMLU (~20% probability).
How much will people work on improving MMLU performance?
Unlike MATH, there is nothing “special” that makes MMLU stand out from other language modeling benchmarks. So I’d guess most gains will come from general-purpose improvements to language models, plus a bit of STEM-specific improvement if people focus on quantitative reasoning.
Bottom-Line Forecast
In some sense, MMLU performance is already “at” 74.2% because of the Minerva result. Additional low-hanging fruit would push us up another 5 points to 79.2%. Alternately, simply extrapolating historical progress would suggest 10.8 points of improvement, or 85%. Putting these together, I’d be inclined towards a median of 83%.
If we instead say that progress doesn’t slow down at all, we’d get 89%.
As before, I’d give an 18% chance of no new SOTA language model papers, in which case MMLU performance likely stays between 67.5% and 74.2%. This also means we should adjust the previous numbers down a bit.
Overall forecast:
- 18th percentile: 74%
- 25th percentile: 77%
- 50th percentile: 82%
- 75th percentile: 89%
This seems pretty similar to the Metaculus community prediction, so I won’t do any further adjustment.
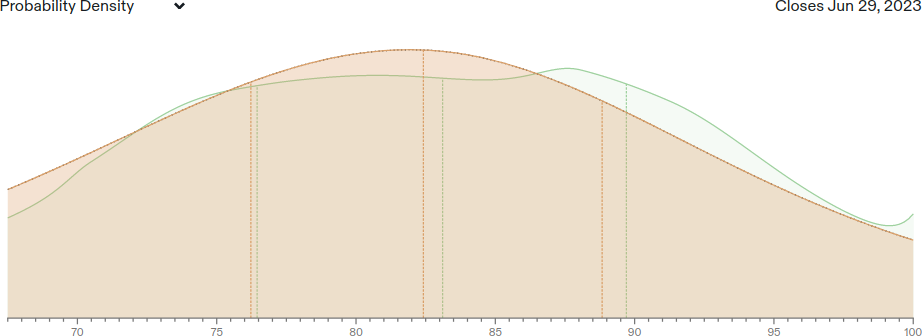
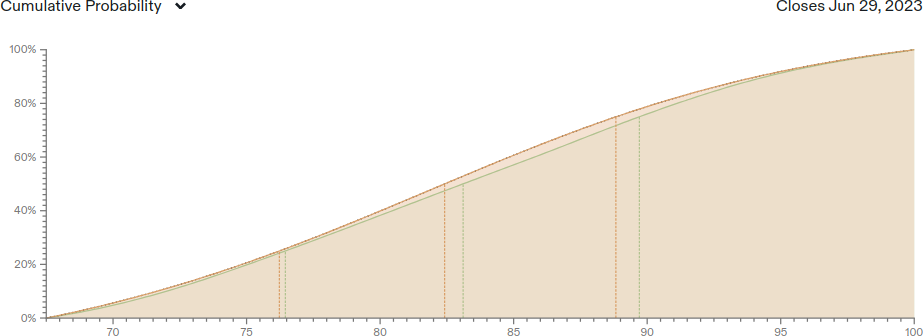
Interestingly, the Hypermind median is only at 72.5% right now. Given the ability to combine Minerva + Chinchilla, this intuitively seems too low to me.
Looking Ahead
My personal forecasts ended up being pretty similar to the Metaculus community forecasts, aside from me expecting slightly slower MATH progress (but only by about a percentage point). So, we can ask what Metaculus expects for 2024 and 2025 as well, as an approximation to what I "would" believe if I thought about it more.
MATH forecast (community prediction in green, top row of each cell):

MMLU forecast (community prediction in green):

So, on median Metaculus expects MATH to be at 83% in 2024 and at 88% in 2025. It expects MMLU to be at 88% in 2024 and at 93% (!) in 2025. The last one is particularly interesting: since MMLU tests domain-specific subject knowledge across many areas, it is predicting that a single model will be able to match domain-specific expert performance across a wide variety of written subject exams.
Do you agree with these forecasts? Disagree? I strongly encourage you to leave your own forecasts on Metaculus: here for MATH, and here for MMLU.
20 comments
Comments sorted by top scores.
comment by Qumeric (valery-cherepanov) · 2022-10-21T03:21:00.399Z · LW(p) · GW(p)
Flan-PaLM reaches 75.2 on MMLU: https://arxiv.org/abs/2210.11416
comment by Tomás B. (Bjartur Tómas) · 2022-07-18T14:57:55.753Z · LW(p) · GW(p)
Large models: the largest version of Minerva is very large (540B parameters) and does 7% better than the 62B parameter model. It seems like it would be relatively expensive to continue improving performance solely by scaling up (but see below on undertraining).
This seems to be a silver lining - the comments on my posts about 10T Chinchilla models [LW · GW] estimate these will not be economically feasible for at least 10 years. One thing I would like more insight into is if all the AI ASIC startups can be safely ignored. Hardware companies usually exaggerate to the point of mendacity, and so far their record has been a string of startups that NVIDIA has completely out-competed. But I would like to know how much probability I should have on some AI ASIC startup releasing something that makes training a 10-100T Chinchilla model feasible in less than 5 years.
Some of my "timelines" intuitions are coming from my perception of the rate of advancement in the last five years, but I am wondering if we've already eaten the easy scaling gains and things might be slightly slower for the next few years.
Replies from: gwern↑ comment by gwern · 2022-07-18T16:28:13.152Z · LW(p) · GW(p)
Hardware has a few dark horses: photonics, spiking neural nets on analogue hardware, and quantum computing are all paradigms that look great in theory and continue to fail in practice... but we know that these are the sorts of things which fail right up until they succeed, so who knows?
You should also consider that with the experience curves of tech & algorithms, and potential for much larger budgets, estimates like $20b (present-day costs) are not that absurd. (Consider that Elon Musk is currently on track to light a >$20b pile of cash on fire because he made an ill-considered impulse purchase online a few months ago. Not to be outdone, MBS continues to set $500b on fire by not building some city in the desert; he also announced $1b/year for longevity research, which should at least do a little bit better in terms of results.)
Replies from: Bjartur Tómas, not-relevant, Bjartur Tómas↑ comment by Tomás B. (Bjartur Tómas) · 2022-07-18T18:21:06.514Z · LW(p) · GW(p)
Replies from: gwern↑ comment by gwern · 2022-07-18T19:10:54.875Z · LW(p) · GW(p)
Replies from: carlos-ramon-guevara↑ comment by CRG (carlos-ramon-guevara) · 2022-07-18T21:17:41.801Z · LW(p) · GW(p)
Yeah, it's not really clear how to apply that specific kind of data pruning (straightforward for an image classifier) to the case of causally modelling text tokens in full context windows or any other dense task like that.
↑ comment by Not Relevant (not-relevant) · 2022-07-19T12:26:27.640Z · LW(p) · GW(p)
The big open question to me is, how much information is actually out there? I’ve heard a lot of speculation that text is probably information-densest, followed by photos, followed by videos. I haven’t heard anything about video games; I could see the argument being made that games are denser than text (since games frequently require navigating a dynamically adversarial environment). But I also don’t know that I’d expect the ~millions of existing games are actually that independent of each other. (Being man made, they’re a much less natural distribution than images, and they’ve all been generated for short-term human intelligence to solve).
We also run into the data redundancy question: all the video on the internet contains one set of information, and all the text another set, but these sets have huge overlap. (This is why multimodal models with pretrained language backends are so weirdly data-efficient.) How much “extra” novelty exists in all the auxiliary sources of info?
Replies from: gwern↑ comment by gwern · 2022-07-20T01:18:47.388Z · LW(p) · GW(p)
Replies from: not-relevant, gwern↑ comment by Not Relevant (not-relevant) · 2022-07-20T16:45:28.219Z · LW(p) · GW(p)
My attempt at putting numbers on the total data out there, for those curious:
* 64,000 Weibo posts per minute x ~500k minutes per year x 10 years = ~3T tokens. I’d guess there are at least 10 social media sites this size, but this is super-sensitive data sharded across competing actors, so unless it’s a CCP-led consortium I think upperbounding this at 10T tokens seems reasonable.
* Let’s say that all of social media is about a tenth of the text contributed to the internet. Then Google’s scrape is ~300T, assuming the internet of the last decade is substantially larger than that of the preceding decades.
* 500 hours of video uploaded to YouTube every minute x ~500k minutes per year x 10 years x 3600 seconds per hour x (my guess of) 10 tokens per second = ~90T tokens on YouTube.
* O(100 million) books published ever x100,000 tokens per book = 10T tokens, roughly.
Let’s assume Chinchilla scaling laws still provide the correct total quantity of data needed. Chinchilla scaling laws suggest ~200T tokens for a 10T-param model, so this does indeed seem like it’s in-range for Google (due either to their scrape or to YouTube) and maybe a CCP-led consortium.
(There is also obviously the possibility of collecting new data, or of building lots of simulators.)
(Unclear whether anyone else similarly scraped the internet, or whether enough of it is still intact for scrapers to go in afterward.)
Replies from: gwern↑ comment by gwern · 2022-07-20T17:03:03.479Z · LW(p) · GW(p)
Replies from: not-relevant↑ comment by Not Relevant (not-relevant) · 2022-07-20T17:32:43.260Z · LW(p) · GW(p)
180m books now
That's still just 20T tokens.
academic papers/theses are a few mill a year too
10M papers per year x 10,000 tokens per paper x 30 years = 3T tokens.
You raise the possibility that data quality might be important and that maybe "papers/theses" are higher quality than Chinchilla scaling laws identified on The Pile; I don't really have a good intuition here.
I spent a little while trying to find upload numbers for the other video platforms, to no avail. Per Wikipedia, Twitch is the 3rd largest worldwide video platform (though this doesn't count apps, esp. TikTok/Instagram). Twitch has an average of 100,000 streams going on at any given times x 3e8 tokens per video-year (x maybe 5 years) = 100T tokens, similar to YouTube. So this does convince me that there are probably a few more entities with this much video data.
Replies from: gwern↑ comment by gwern · 2022-07-20T18:20:57.576Z · LW(p) · GW(p)
Replies from: not-relevant, not-relevant↑ comment by Not Relevant (not-relevant) · 2022-07-20T18:40:01.712Z · LW(p) · GW(p)
I agree that if you put enough of these together, there are probably ~10 actors that can scrape together >200T tokens. This is important for coordination; it means the number of organizations that can play at this level will be heavily bottlenecked, potentially for years (until a bunch more data can be generated, which won't be free). It seems to me that these ~10 actors are large highly-legible entities that are already well-known to the US or Chinese governments. This could be a meaningful lever for mitigating the race-dynamic fear that "even if we don't do it, someone else will", reducing everything to a 2 party US-China negotiation.
Replies from: sharmake-farah↑ comment by Noosphere89 (sharmake-farah) · 2022-07-20T20:43:05.207Z · LW(p) · GW(p)
The big problem is the cold war mentality is back, and both sides will compete a lot more rather than cooperate. Combine this with a bit of an arms race by China and the US, and the chances for cooperation on existential risk are remote.
Replies from: not-relevant↑ comment by Not Relevant (not-relevant) · 2022-07-20T20:51:47.925Z · LW(p) · GW(p)
This is a separate discussion, but it is important to point out that the literal Cold War had the opposing powers cooperate on existential risk reduction. Granted that before that, two cities were burned to ash and we played apocalypse chicken in Cuba.
↑ comment by Not Relevant (not-relevant) · 2022-07-20T20:27:24.961Z · LW(p) · GW(p)
Two more points:
- The specific upper bound does matter if we’re worried about superintelligence. If easy-to-get data instead capped out at 10 quadrillion tokens, it’d be easy to blow past 10T-param models; if we conveniently threshold around human-level params, we might be more likely to be dealing with “fast parallel Von Neumanns” than a basilisk, at least initially.
- Just to register a prediction: I would be very surprised if photos have anywhere near as much information content as text/video, given their relative lack of long-term causal structure.
↑ comment by Noosphere89 (sharmake-farah) · 2022-07-20T20:41:17.509Z · LW(p) · GW(p)
In short, while concerted effort could plausibly give us human intelligence, it is likely not to go superhuman and FOOM.
Replies from: not-relevant↑ comment by Not Relevant (not-relevant) · 2022-07-20T20:53:51.190Z · LW(p) · GW(p)
I wouldn’t go that far; using these systems to do recursive self-improvement via different learning paradigms (e.g. by designing simulators) could still get FOOM; it just seems less likely to me to happen by accident in the ordinary coarse of SSL training.
↑ comment by Tomás B. (Bjartur Tómas) · 2022-07-18T16:45:37.995Z · LW(p) · GW(p)
comment by Hailey Collet (hailey-collet) · 2023-03-28T22:12:11.751Z · LW(p) · GW(p)
93% in 2025 FEELS high, but ... Meta was already low for 2023, median 83% but GPT-4 scores 86.4%. If you plot 100%-MMLU sota training compute FLOPS (e.g. RoBERTa with 1.32*10^21 flops scores 27.9% so 72.1% gap, GPT-3.5 @ 3.14*10^23=30% gap, GPT4 @ ~1.742*10^25=13.6% gap), it should take roughly 41x the training compute of GPT-4 to achieve 93.1% ... so it totally checks.
(My estimate for GPT4 compute is based on the 1 trillion parameter leak, approximate number of V100 GPUs they have - they didn't have A100 let alone H100 in hand during GPT4 training interval - possible range of training intervals scaling laws and the training time=8TP/nx law, etc., and ran some squiggles ... it should be taken with a grain of salt, but the final number doesn't change in very meaningful ways for any reasonable assumptions so, e.g., it might take 20x or 80x but it's not going to 500x the training compute to get to 93%)
comment by [deleted] · 2022-07-18T23:49:52.475Z · LW(p) · GW(p)
Will we ever get out of the GLUT era of ML? They say jobs like physicians and lawyers can get replaced by ML. Seems like that's because of the GLUT nature of those jobs, rather than about ML itself.
I guess a better question is at what point is the model no longer considered GLUT. Is intelligence ultimately a form of GLUT? Let's say you figured out the gravitational constant. Well, good for you. The process of deduction is basically looking for patterns in a look up table right? You do a bunch of experiments that tries to cover all edge cases, then you draw some generality out of your process. Without the generalization, you'd have to always go back to the look up table, but now you have a nice little equation that you can just plug in the values. No more GLUT, woohoo! Is this intelligence?
The generalization (coming up with algorithms, proofs, equations, etc) is just part of a process that allows you to use it in a simplified form as part of knowledge building process. The knowledge we build has become the intermediate look up table replacing the older, less efficient way of obtaining the same information. You can use the fact force = mass * acceleration or some constant equivalent of that equation without actually knowing the equation yourself, you are just less efficient at using it than in its simplest form. The person who generalized these knowledge aren't special or anything. It's just that they happened to be the ones doing it instead of someone else. Other people might be doing something else. The work is so rewarding, that's why we encourage people to pursue this line of work, you don't even need much monetary or other related type of incentives for people who are capable of this type of work to want to work on this. Monetary incentives tend to favor the needs of the population, and most people don't really have any immediate need for this type of work done. They are usually enjoying the far derivatives of these knowledge that they can benefit from.
So to build an AI, if you hard code the math symbols and their operations, is that any different than the type of model representation they would learn unsupervised in an open environment? They don't even have to operate on a world model, they can strictly be confined to the math space. Seems like that's what MATH learners are doing. These machines probably will never derive equations like F=m*a but they will have some internal representations of it in their models if they were to do well on MATH data set or the likes.
If we build a neural net that itself has built a computer/neural net, would that be a 3 layer deep recursion?