ML Safety Research Advice - GabeM
post by Gabe M (gabe-mukobi) · 2024-07-23T01:45:42.288Z · LW · GW · 2 commentsThis is a link post for https://open.substack.com/pub/mukobimusings/p/ml-safety-research-advice
Contents
1. Career Advice 1.1 General Career Guides 2. Upskilling 2.1 Fundamental AI Safety Knowledge 2.2 Speedrunning Technical Knowledge in 12 Hours 2.3 How to Build Technical Skills 2.4 Math 3. Grad School 3.1 Why to Do It or Not 3.2 How to Get In 3.3 How to Do it Well 4. The ML Researcher Life 4.1 Striving for Greatness as a Researcher 4.2 Research Skills 4.3 Research Taste 4.4 Academic Collaborations 4.5 Writing Papers 4.6 Publishing 4.7 Publicizing 5. Staying Frosty 5.1 ML Newsletters I Like 5.2 Keeping up with ML Research 6. Hiring ML Talent 6.1 Finding ML Researchers 6.2 Finding ML Safety-Focused Candidates 6.3 Incentives Acknowledgments None 2 comments
This is my advice for careers in empirical ML research that might help AI safety (ML Safety). Other ways to improve AI safety, such as through AI governance and strategy, might be more impactful than ML safety research (I generally think they are). Skills can be complementary, so this advice might also help AI governance professionals build technical ML skills.

1. Career Advice
1.1 General Career Guides
- Preventing an AI-related catastrophe - 80,000 Hours
- A Survival Guide to a PhD (Andrej Karpathy)
- How to pursue a career in technical AI alignment — EA Forum [EA · GW]
- AI safety technical research - Career review - 80,000 Hours
- Beneficial AI Research Career Advice
2. Upskilling
2.1 Fundamental AI Safety Knowledge
- AI Safety Fundamentals – BlueDot Impact
- AI Safety, Ethics, and Society Textbook
- Forming solid AI safety threat models helps you select impactful research ideas.
2.2 Speedrunning Technical Knowledge in 12 Hours
- Requires some basic coding, calculus, and linear algebra knowledge
- Build Intuition for ML (5h)
- Backpropagation, the foundation of deep learning (3h)
- Transformers and LLMs (4h)
2.3 How to Build Technical Skills
- Traditionally, people take a couple of deep learning classes.
- Other curricula that seem good:
- Syllabus | Intro to ML Safety
- Levelling Up in AI Safety Research Engineering [Public]
- ARENA
- Maybe also check out recent topical classes like this with public lecture recordings: CS 194/294-267 Understanding Large Language Models: Foundations and Safety
- Beware of studying too much.
- You should aim to understand the fundamentals of ML through 1 or 2 classes and then practice doing many manageable research projects with talented collaborators or a good mentor who can give you time to meet.
- It’s easy to keep taking classes, but you tend to learn many more practical ML skills through practice doing real research projects.
- You can also replicate papers to build experience. Be sure to focus on key results rather than wasting time replicating many experiments.
- “One learns from books and reels only that certain things can be done. Actual learning requires that you do those things.” –Frank Herbert
- Note that ML engineering skills will be less relevant over time as AI systems become better at writing code.
- A friend didn’t study computer science but got into MATS 2023 with good AI risk takes. Then, they had GPT-4 write most of their code for experiments and did very well in their stream.
- Personally, GitHub Copilot and language model apps with code interpreters/artifacts write a significant fraction of my code.
- However, fundamental deep learning knowledge is still useful for making sound decisions about what experiments to run.
2.4 Math
- You don’t need much of it to do empirical ML research.
- Someone once told me, “You need the first chapter of a calculus textbook and the first 5 pages of a linear algebra textbook” to understand deep learning.
- You need more math for ML theory research, but theoretical research is not as popular right now.
- Beware mathification: authors often add unnecessary math to appease (or sometimes confuse) conference reviewers.
- If you don’t understand some mathematical notation in an empirical paper, you can often send a screenshot to an LLM chatbot for an explanation.
- Mathematical fundamentals that are good to know
- Basic probability
- Very basics of multivariable calculus, like partial derivatives and chain rule
- Matrix multiplication, matrix inverses, eigenvectors/eigenvalues, maybe a couple of decompositions
3. Grad School
3.1 Why to Do It or Not
- Only do it if you have a good career growth reason (including credentials), an advisor you get along well with, and a solid idea of what research you’ll work on.
- Anything else, and you’ll likely waste a lot of time compared to alternative jobs you could get if you are at the level where you can get into ML grad school.
- More people getting into AI safety should do a PhD | Adam Gleave
- How to pursue a career in technical AI alignment — EA Forum [EA · GW]
- FAQ: Advice for AI alignment researchers – Rohin Shah
- AI safety technical research - Career review - 80,000 Hours
- Looking back on my alignment PhD — LessWrong [LW · GW]
- (outdated) Machine Learning PhD - Career profile - 80,000 Hours
- You might also consider master’s programs or “mastering out” of a Ph.D. program (leaving after you get an intermediate M.S. degree) as lower-cost grad school options
- Some schools do online CS M.S. degrees
- UK/EU Ph.D.s are often shorter than U.S. Ph.D.s (~3-4 years vs ~4-6 years), though you may need a master’s degree before.
3.2 How to Get In
- Beneficial AI Research Career Advice
- Machine Learning PhD Applications — Everything You Need to Know — Tim Dettmers
3.3 How to Do it Well
4. The ML Researcher Life
4.1 Striving for Greatness as a Researcher
- Hamming, "You and Your Research" (June 6, 1995)
- It contains a lot of mundane-sounding advice that many people just don’t have the discipline to follow.
- “It’s not hard to do; you just do it!”
- I listen to this every few months for inspiration and focus.
4.2 Research Skills
- General advice
- Empirical ML research these days is less about principled understanding and more about rapidly testing many ideas.
- The cheaper you can make it to invalidate or validate a possibly good research idea, the more ideas you can test until you find something that works well.
- See Research as a Stochastic Decision Process for tips on prioritization among trying different ideas.
- See Touch reality as soon as possible (when doing machine learning research) — AI Alignment Forum [AF · GW] for more motivation.
- In deep learning research or applications, often fancy novel things never work.
- So, just imitate what others have succeeded with in similar problems or subdomains.
- ASAP create a slideshow with the “story” of your paper, including motivation, key results, implications, etc. This is useful for several reasons:
- It forces you to have a coherent and concise story for your paper and makes paper writing more structured.
- You can draw fake plots as previsualization for experimental results to help communicate the point of an experiment, sync on presentation, and form hypotheses.
- You can share it with potential collaborators to quickly communicate the project.
- You get a jump start on crafting talks for your paper.
- The scientific method, taught in middle school, actually works!
- Observation, Question, Hypothesis, Methods, Experiment, Analysis, Conclusions, Iterate
- Scientists don't use it enough. Be better.
- Don’t just run a bunch of experiments because you can. Iteratively ask pointed research questions and design experiments to best answer them to save time and write more meaningful papers.
- Preregistration should be much more normalized, and researchers should start practicing it early in their careers.
- Keep a lab notebook
- Especially with the iterative nature of empirical ML research, it’s useful to write down
- Your priorities for the day
- Your hypotheses
- What you did
- Why did you decide to do those particular things, especially why you decided to run certain experiments or test a specific change
- What results did you get
- What those results mean
- See Jacob Steinhardt’s public research log from his Stanford Ph.D. as a fun example, though most of his logs are just what he did.
- Especially with the iterative nature of empirical ML research, it’s useful to write down
4.3 Research Taste
- Think ahead about the new AI shifts you expect to be coming and aim to work on research that will be relevant to the future.
- If you work on what’s hot now, you’re too late.
- I'm not sure what the right timeline to aim for is. Too early and you’ll be chasing trends; too late and you’ll work on irrelevant topics or be too ahead of your time.
- I’d guess 6-12 months is a good balance.
- Don't update much on people around you not liking your research
- If you have a good idea, it might be unpopular or go against existing precedent.
- If you listen too much to old researchers who don't like your new idea, they won't pursue new and original ideas.
- Also, don't overupdate on them liking it, as it could be hype or a crowded area.
- Predict reviews of published papers on https://openreview.net/ to form better mental models of the ML community.
- Read a paper without seeing the reviews, try to predict what the ML community would have to say about it (ideally, write it down), then look at the reviews and see what you got right or missed.
- It is the qualitative natural language data—not the quantitative review score—that you want to predict.
- Beware of the high variability in ML reviewers these days: they’ll miss some things, and many of their critiques will be bad faith.
- Don’t do this because the ML community is “right.” Do it because it can be useful to know what the ML academic community thinks:
- To tailor your research to increase acceptance odds.
- To model what research problems the ML community will likely work on or not.
- To dig further into the assumptions and sketchy parts of papers that you might not find, but the community does.
- You should build an internal model of the emotional aspects of why people like or dislike certain work.
- The actual logical reasons are often secondary to the emotional reasons, e.g., hype or reviews.
- But if you have a good model of the ML community's emotions, you can adversarially train yourself to filter out the hype, trends, and bad motivations.
- Then, you can form a better model of actually good research: research taste.
- Read a paper without seeing the reviews, try to predict what the ML community would have to say about it (ideally, write it down), then look at the reviews and see what you got right or missed.
- You can also ask random ML researchers about their work in person.
- Ask "why" questions to go up in abstraction about motivations. E.g., "Why do you care about Bayesian methods?"
- Ask "how" questions to go down in abstraction about concrete choices. E.g., "How are Bayesian methods better at X than Y?"
- Forces you to have good knowledge of classic research that can quickly indicate if someone's work is irrelevant or redundant.
- Resource on research taste
4.4 Academic Collaborations
- Professors don’t do research (in terms of the actual work)—their grad students do.
- Often, academics are more willing than expected to talk about their work or consider follow-up collaboration if it’s evident you’ve read and understood their research.
- Be wary of having too many opinionated collaborators on a paper.
- Despite being somewhat common in ML, having too many collaborators is usually a good way for a paper to die in Idea Hell or otherwise take a lot of time due to conflicting ideas.
- More engineers without opinions can often help accelerate research. Still, too many engineers on a project is definitely a thing and can lead to over-engineering, fractured codebase understanding, and high management costs.
- It’s good to have one or possibly two (if strongly idea-aligned) project leads who will set the direction of the paper and decide on tone, framing, and presentation.
- Conversely, don’t spread yourself too thin and spend only a few hours per week each on a handful of projects.
- Several people recommended to me having 1-2 projects you lead at a time and only up to a couple more you collaborate on.
- When inviting other collaborators later, having a concrete deal is super helpful. E.g., “Here’s our working abstract, and we already have these 3 key results. Would you like to run experiments X and Y and help write sections Z? I think that will take W hours, and we’d be happy to make you a middle co-author.”
- It’s not uncommon to bring in specialized people later to provide critical feedback on certain topics in exchange for authorship.
- You can also do this if you are specialized enough.
- A mentor said that, in grad school, they frequently came up with a research idea and ran the core experiment in only a week or two. Then, using the tease of the core result, they brought on other collaborators to do the rest of the experiments and write the paper.
- The mentor usually ended up as the first author on these papers since they came up with the idea and did the initial work, and then they managed collaborators with less effort.
4.5 Writing Papers
- LEADERSHIP LAB: The Craft of Writing Effectively
- Super important. People don’t communicate the value of their work enough.
- Tips for Writing Technical Papers
- Provides a decent structure you can default to for paper organization.
- [1807.03341] Troubling Trends in Machine Learning Scholarship
- Issues due to perverse incentives in the field you should avoid.
- Learn to communicate clearly and simply.
- Most PhD programs don't prioritize teaching communication skills, but individual researchers can greatly differentiate themselves and their work by developing them.
- Resources that colleagues have recommended or that I like
- Get feedback early and often from researchers your trust about the clarity and organization of your writing.
- As you read other ML papers while writing your own, you’ll start to take note of the structural and writing tricks they use to effectively community.
4.6 Publishing
- Nowadays, most of the impact comes from arXiv preprint + Twitter thread + sending the preprint to relevant researchers.
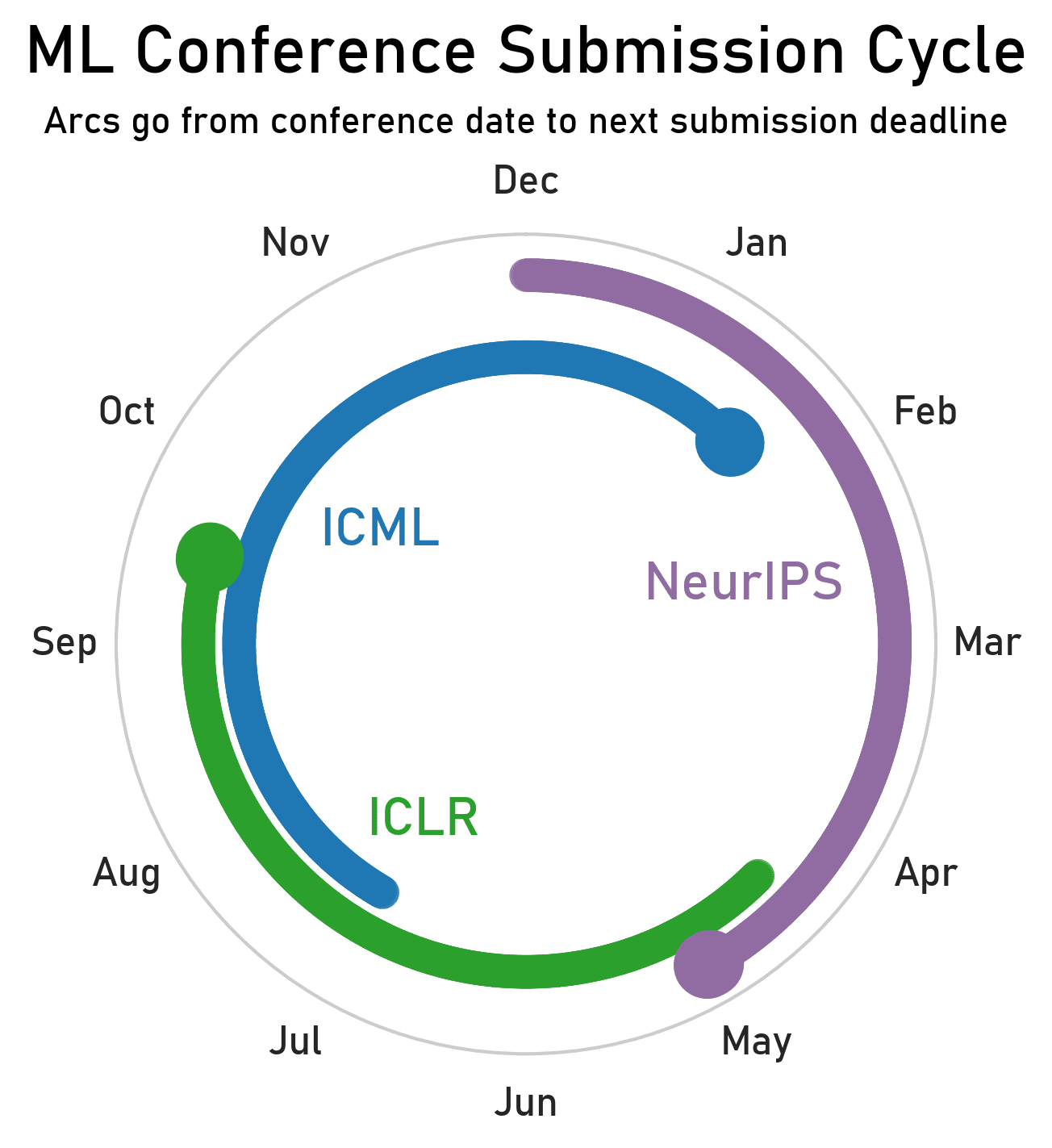
- Know the top ML conference cycle:
- NeurIPS is held in December and due in May.
- ICLR is held in April/May and due in September/October.
- ICML is held in July and due in January/February.
- This holy trinity of conferences is spaced so you can always prepare to submit to the next one.
- It’s probably good to attend 1 or maybe 2 of these conferences per year as long as you want to be better integrated into the ML community.
- ML conferences aren’t for presenting papers.
- They’re big social events for meeting collaborators and finding job opportunities.
- This is partly due to the modern preprint+Twitter ecosystem, where everyone has already read the papers that interest them months before a big conference with those papers occurs.
- Workshops can be good to publish in.
- Usually, they’re due only a couple of months before the real conference event.
- Much chiller review processes than conferences.
- Usually non-archival, so you are allowed to submit the same paper to many to increase your feedback and odds of acceptance.
- Good for getting decent feedback and technically a publication for preliminary work that you can expand into a full conference paper later.
- Other smaller conferences to consider
- ML researchers don’t do journals much
- But you could consider submitting to Transactions on Machine Learning Research or Journal of Machine Learning Research if a conference deadline doesn’t line up
- It’s common for papers to change somewhat significantly during peer-review rebuttal rounds.
- It’s ideal to have your paper “done” by submission time.
- But it’s also fine and sometimes optimal to submit a rushed paper, keep improving it before the first-round reviews come back, and then update reviewers with your much-improved paper alongside their other complaints during rebuttals.
- Don’t sweat it if you get rejected—ML reviewers have abysmal inter-rater agreements, and again, most of the impact can happen from preprints.
- Be wary of “playing the game.”
- Some people just optimize for publications, submitting shoddy papers to many places.
- Citations and conference acceptances are not the same as impact.
- It probably only makes sense to play the game now if you instrumentally need a few publications to get into grad school or some other credentialist role.
4.7 Publicizing
- Most of the Shapley value of a paper’s impact hinges on how well you publicize it after releasing a preprint. Most papers only get a couple of citations.
- Definitely post a Twitter thread and engage with commenters and retweeters.
- Aim to give some talks. Study and practice how to give good research talks.
- Send your paper with some nice context directly to a few researchers who would most like to read it.
5. Staying Frosty
5.1 ML Newsletters I Like
- AI News • Buttondown
- I usually just read the small summary at the top each day, but they also have summaries of all top AI Discord, Reddit, and Twitter discussions each day
- AI Safety Newsletter | Center for AI Safety | Substack
- Import AI | Jack Clark | Substack sometimes
5.2 Keeping up with ML Research
- Get exposure to the latest papers
- Follow a bunch of researchers you like and some of the researchers they retweet on Twitter.
- Join AI safety Slack workspaces for organic paper-sharing. If you can't access these, you can ask Aaron Scher to join his Slack Connect paper channel.
- Subscribe to the newsletters above.
- Filter down to only the important-to-you papers
- There’s a lot of junk out there [LW(p) · GW(p)]. Most papers (>99%) won't stand the test of time and won't matter in a few months
- Focus on papers with good engagement or intriguing titles/diagrams. Don’t waste time on papers that don’t put in the effort to communicate their messages well
- Filter aggressively based on your specific research interests
- Get good at efficiently reading ML papers
- Don't read ML papers like books, academic papers from other disciplines, or otherwise front-to-back/word-for-word
- Read in several passes of increasing depth: Title, Abstract, First figure, All figures, Intro/Conclusion, Selected sections
- Stop between passes to evaluate understanding and implications
- Do I understand the claims this paper is making?
- Do I think this paper establishes sufficient evidence for these claims?
- What are the implications of these claims?
- Is it valuable to keep reading?
- Aim to extract useful insights in 10-15 minutes
- For most papers, I stop within the first 3-4 passes
- "Oh, that might be a cool paper on Twitter" -> open link -> look at title -> skim abstract -> look at 1-3 figures -> "Ahh, that's probably what that's about" -> decide whether to remember it, forget about it, or, rarely, read more
- You can usually ignore the "Related Work" section. It's often just the authors trying to cite everyone possibly relevant to the subfield who might be an anonymous peer reviewer for conference admissions, or better yet, it’s a takedown of related papers to signal why the new paper is novel.
- Sometimes, it is useful to contextualize how a non-groundbreaking paper fits into the existing literature, which can help you decide whether to read more.
- Nowadays, lead authors often post accessible summaries of the most important figures and insights from their papers in concise Twitter threads. Often, you can just read those and move on
- Some resources I like for teaching how to read ML papers
- Practice reading papers
- Skim at least 1 new paper per day
- A lot of the burden of understanding modern ML lies in knowing the vast context in which papers are situated
- Over time, you'll not only get faster at skimming, you'll also build more context that will make you have to look fewer things up
- E.g. "this paper studies [adversarial prompt attacks] on [transformer]-based [sentiment classification] models" is a lot easier to understand if you know what each of those [things] are.
- It gets easy once you do it each day, but doing it each day is the hard part.
- Other tips
- Discussing papers with others is super important and a great way to amplify your learning without costing mentorship time!
- Understand arXiv ID information: arxiv.org/abs/2302.08582 means it's the 8582nd paper (08582) pre-printed in February (02) 2023 (23)
- https://alphaxiv.org/ lets people publicly comment on arXiv papers
6. Hiring ML Talent
6.1 Finding ML Researchers
- Just do actual recruitment like others in the tech industry.
- Talent sourcing is work, and you need to allocate time and other resources if you want it to happen.
- Ideally, hire someone whose main job is recruiting and who won’t seem totally lost when talking to ML researchers.
- Organizations can pay tech recruiting firms or contractors to help them with this without hiring a full recruiter.
- The MVP is to ask for recommendations for people, peruse LinkedIn, and actively DM many candidates, asking them to apply.
- You can also look for relevant research papers and contact the people listed in the first half and at the very end of the author list.
- ML conferences aren’t for presenting papers.
- They’re big social events to meet collaborators and find job opportunities.
- Even if an organization doesn’t have a paid booth or hosted party at a conference, representatives often attend to recruit researchers.
- Consider recruiting talent who aren’t actively searching yet.
- If you know someone well in a large organization of ML researchers—such as an AGI lab or prominent academic department—consider asking if they’ve heard of anyone considering a career transition.
- Academic researchers may especially be open to work but have yet to actively seek it out due to the pernicious comfort of academic roles.
- Recruiting talent from AGI scaling labs may be good in multiple ways.
- Professors may be open to part-time or time-bound work in government.
- Many professors might be willing to help governments but would rather avoid signing up for full-time work (due to other commitments) or long-term work (because they want to return).
- It can be much more attractive to clearly offer these people part-time (work X days per week with us) and/or time-bounded (it’s only 2/3/4 years) work.
- IPAs and similar contracts can be great mechanisms for this.
6.2 Finding ML Safety-Focused Candidates
- Talk to the admin teams of AI safety research organizations for graduates and promising candidates who didn’t end up in the program
- Ask academic advisors who are somewhat safety-focused if they have any students looking for jobs.
- Airtable - Potential PhD Supervisors, AI Alignment / Safety
- Signatories of the CAIS Extinction Statement and maybe the FLI Pause Letter
- Put clear feelers out in AI safety communities.
- Constellation or other local AI safety communities
- Some AI safety university groups
- Directly asking some trusted people to refer people
6.3 Incentives
- Academic ML researchers tend to follow one or a couple of a weird set of incentives:
- Novelty: they want to work on intellectually interesting problems.
- Progress: they want to advance the ML field.
- Prestige: they want recognition for the perception of advancing the ML field or clout from collaborating with cool researchers, often to land an industry or an academic job.
- Citations: they have Goal Mis-Generalized the above into just wanting their Google Scholar numbers to go up.
- Playing the Game: they have Goal Mis-Generalized and like the thrill of submitting to conferences and battling reviewers.
- Societal Impact: unfortunately rare, they want to make the world better.
- Academic ML researchers tend to be comparatively less motivated by
- Money
- Credentials
- Interdisciplinary work
- Incentives vary wildly between people, and most people are archetypes of only a couple of incentives.
- You can figure it out pretty quickly by talking to an ML researcher if you try.
- Sometimes, you can just directly ask what motivates them to do research, and they may be forthcoming.
Acknowledgments
Many thanks to Karson Elmgren and Ella Guest for helpful feedback and to several other ML safety researchers for past discussions that informed this piece!
2 comments
Comments sorted by top scores.
comment by Hoa Do (hoa-do) · 2024-07-23T06:52:40.756Z · LW(p) · GW(p)
Thanks so much for this write up. Just what I need. Do you have any further advice on:
"You should aim to understand the fundamentals of ML through 1 or 2 classes and then practice doing many manageable research projects with talented collaborators or a good mentor who can give you time to meet."
How do you find collaborators or mentors after going through some courses?
Replies from: gabe-mukobi↑ comment by Gabe M (gabe-mukobi) · 2024-08-02T11:36:52.471Z · LW(p) · GW(p)
Traditionally, most people seem to do this through academic means. I.e. take those 1-2 courses at a university, then find fellow students in the course or grad students at the school interested in the same kinds of research as you and ask them to work together. In this digital age, you can also do this over the internet to not be restricted to your local environment.
Nowadays, ML safety in particular has various alternative paths to finding collaborators and mentors:
- MATS, SPAR, and other research fellowships
- Post about the research you're interested in on online fora or contact others who have already posted
- Find some local AI safety meetup group and hang out with them