How to train your transformer
post by p.b. · 2022-04-07T09:34:52.465Z · LW · GW · 0 commentsContents
No comments
In this blogpost I describe a transformer project, how I proceeded, the results, the pitfalls and more. At the end of the post I will repeat all salient points in a TL;DR, so if you are short of time, just skip ahead.
I originally published this on a company blog. The blog has been down for the last couple of months and seems unlikely to be up again any time soon. I republish it here, to give context and additional detail for my research agenda [LW · GW] into transformer capabilities.
The transformer is currently the hottest Deep Learning model. Introduced in 2017, it was initially conceived to give Google translate a huge quality boost, but quickly turned out to be useful for many more application besides machine translation.
The two main workhorses of Deep Learning used to be convolutional neural networks for image processing and any data that has a vaguely similar format and LSTMs for sequence processing or any data that can, sensibly or not, be interpreted as a sequence.
The story of the last four years has been one of transformers or transformer-inspired architectures (look for the key words “attention based”), slowly out competing ConvNets and LSTMs in one domain after another. I already mentioned machine translation, but any kind of language modelling achieved a huge boost in quality by switching to the transformer architecture.
NLP, “natural language processing”, finally had its “image net moment”, when the transformer-based BERT-model turned out to just be better at everything NLP than anything else. Automatic text generation of any form and kind (satire, poetry, python-code, dungeons and dragons, …) was made possible by GPT-2 and recently GPT-3.
In one of the most exciting scientific breakthroughs of recent history, Google subsidiary Deepmind solved the protein folding problem (for certain definitions of “solved”). One key difference between the protein folding programs Alphafold2 (solved protein folding) and Alphafold1 (was pretty good) … you guessed it: a transformer-inspired building block.
Other advances achieved with transformers include CLIP, an open-ended image recognizer and DALL-E, a model that can create images from a short textual description.
Interestingly, the transformer model is not naturally a sequence model or an image model. Instead, the attention mechanism that lies at its core is an operation over sets without any intrinsic order, quite unlike words in text or pixels in an image. Therefore, it is conceivable that if the necessary data and compute is available, transformers can also often outperform tree-based methods on tabular data, where those have reigned supreme in most Kaggle competitions. The unifying vision for machine learning is a transformer replacing convolutional nets, LSTMs and XGBoost.
So, it is only natural that you want to train a transformer yourself. But how to go about it? In this blogpost I will describe a transformer project in all the gory detail.
Deep Learning is a very empirical endeavor. If it works, it works. Each technique and its opposite can be rationalized after it was shown to work. Many papers are basically a list of tricks that were necessary to get to publishable results. Competence for a Deep Learning practitioner, therefore, is to large degree the depth of their bag of tricks. In the following I will try to add a few tricks to your bag.
My project is concerned with the prediction of human moves in chess games. For chess, databases with millions of tournament games are freely available. Because each game has on average 80 positions, these games result in hundreds of millions of training samples in a highly complex domain.
And if that’s not enough, there are almost a billion online chess games available for dozens of billions of training samples. It is not easy to beat chess, when it comes to big data Deep Learning for the small budget.
Speaking of which, if data is not prohibitive for a small Deep Learning project, compute often is. We circumvent this problem by running most of our experiments on free google Colab notebooks.
Colab is free, but not unlimited. After a while you will trigger usage limits that freeze your GPU-budget for a number of days. It is also not terribly convenient. Free Colab notebooks never run longer than 12 hours and usually only half that. You have to make sure to write out your models and all data of interest regularly. RAM is also limited and Colab disconnects if you don’t keep it in the front of your screen.
But its free GPU time, roughly 20 times faster than my laptop, and the training data can be read in directly from Google drive, so disconnects don’t necessitate uploading training data for hours on end.
For my implementation I started out with pre-existing Keras code. However, even on Colab I realized that it was not possible to train transformers with more than four or five layers. That’s no good. We want to scale!
So, I added dynamic linear combinations of layers in line with the ideas from Wang et al., 2018. This allowed me to scale to more than 30 layers. The idea is simply to learn weights for a weighted sum of earlier layer outputs as the input for each new layer. This means that the gradient can skip from the last layer directly to the first and only later in training concentrate on the input from the directly preceding layer.
The currently hotter method of scaling depth is called Rezero. I also implemented Rezero for the transformer and a fully connected model, but although it allows almost unlimited depth scaling, Rezero did not beat my linear combination transformer.
The data is provided to the model by a generator. This is necessary if you go beyond small models, because you cannot keep all your training data in memory. For chess games this memory saving becomes especially worthwhile, because chess games are quite compressed compared to the 70 to 90 vectors with dimension 128 that I use to encode a single position.
Data should be cleaned first. Shuffled second. Split into training, validation and test set third. Don’t skip any of these steps or you will never be sure how good your model actually currently is. I know, because I skipped all these steps (it was just a little toy project, wasn’t it) and I had to go back and do them all and throw away all my earlier results.
Shuffling the data does not necessarily mean that you have shuffled the single data points. In my project the games were shuffled, but the data points are positions and these are strongly correlated for the same game. Something similar is often true if you sample sequences. Correlated data points in a batch bias the gradient and might degrade the training. Therefore, in these cases it makes sense to try in memory shuffling of the data points that are computed by the generator. Don’t output each batch once you have computed it. Instead keep 10 or more batches in memory, shuffle these data points, and output one tenth of the prepared data points as a batch.
Deep Learning models often scale very smoothly with data, compute and model size. Some of your early experiments should involve computing or at least estimating the scaling laws of you model. That means, you should track how your performance scales with compute, model size and data.
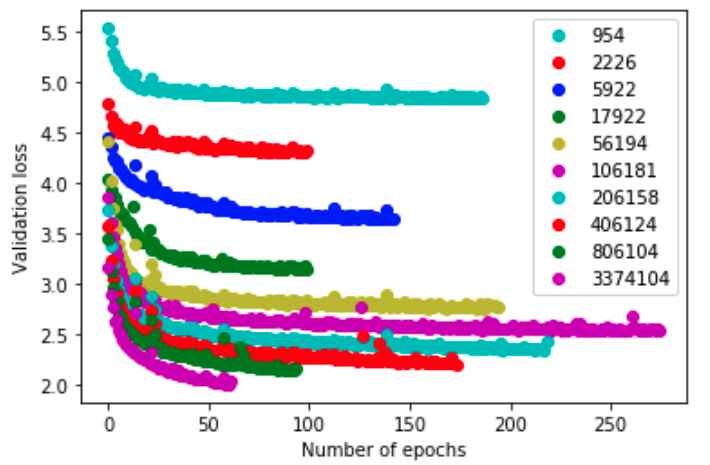
Scaling laws are useful in two separate ways. On the one hand they allow us to ferret out information bottlenecks in our architectures. Simply put: If the architecture scales nicely, there is probably no information bottleneck. Otherwise, the bottleneck would hobble the performance more and more. This does not mean that the architecture is optimal or anything, but you are doing something right.
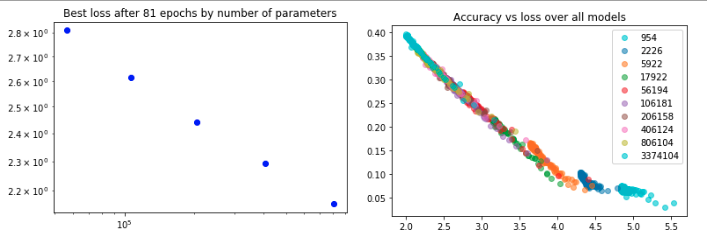
And of course, scaling laws allow you to get the most out of the compute, memory and data available. At least in theory. In practice scaling laws depend on hyperparameters such as batch size and learning rate, as well as all kinds of architecture choices that will probably vary throughout the project. But at the very least you get a sense of where things are going and what kind of performance might be realistic to shoot for.
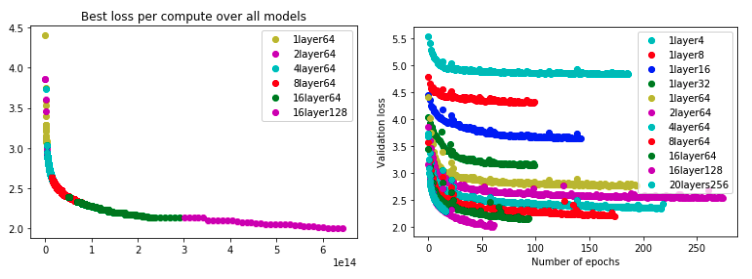
Now, the result of your scaling law investigation might be, that you are first and foremost memory constrained. You just cannot fit the ideally sized model with the necessary batch size onto your GPU. In that case, it is helpful to know that you can trade compute for memory via gradient accumulation. With gradient accumulation you do not update the weights after each batch. Instead, you accumulate the gradient over several batches, until you have reached enough samples for the desired (larger) batch size.
This is blogpost about training a transformer and I specifically started the project to learn a bit more about the architecture. But of course, you should use a complicated model just because it is so fancy. Right from the start, I also tried to train a fully connected rezero network as a simple baseline to compare against. These networks train much faster but ultimately converged to much lower accuracy, which provided a sensible sanity check.
If you want to do a Deep Learning project, start by reading the relevant literature carefully. In this short blog post, I try to provide you with some more tricks for your bag of Deep Learning tricks. Papers about similar projects as yours, will provide you with tricks that already worked in a similar situation. In the case of my chess move prediction, I got at least one non-obvious trick from the best current paper on the topic: Give not just the position, but also the last few moves as input. This significantly boosted the accuracy of my model.
It is also a generalizable piece of advice. In chess, previous moves should not matter for the next moves, beyond the fact that they led to the current position. But in practice, probably because we predict human moves, they do matter. Sometimes seemingly redundant information can help the network to be just that 1% or 2% more accurate.
Speaking of which, my final network reaches an accuracy of slightly above 51%. This was a surprisingly high accuracy, intuitively I would have expected humans to be too variable in the moves they choose for such a high accuracy to be possible.
However, I also found a move prediction project out of Stanford, https://maiachess.com, that reaches roughly 53% for internet games in a narrow rating range.
Maia chess is not directly comparable to my chess transformer project, because they have a lot more training data, the level of play is much lower in their games and they exclude opening and part of the endgame for move prediction. But it is at least an indication that my model doesn’t lag hopelessly behind.
The chess transformer was also a fascinating project because it is possible to directly play against each model. The early models showed a great willingness to keep the material balance even if it required ignoring the rules, which is quite surprising.
Playing against later models was the complete opposite of playing against normal engines. If you play a normal chess engine, it often feels like playing against an idiot that is nonetheless very difficult to beat. Chess transformer on the other hand plays extremely sensible moves and still manages to lose all the time, which is certainly a lot more satisfying.
A few more observations:
Accuracy was surprisingly stable across different rating ranges. I had assumed that better players might be more predictable. But there is also the opposite possibility that the network fails to predict moves that are motivated by tactical points, as it doesn’t look ahead, and stronger players might make more moves based on those concrete tactical details. This suggests that the lower level of play in the Maia training data is not necessarily a handicap when it comes to the ultimately possible prediction accuracy.
Lowering the learning rate when the model starts stagnating gives an additional strong boost. But starting with a lower learning rate seems to hurt final performance. These are common observations, and they might motivate a future foray into cyclical learning rates, super convergence and the like.
Elo inference unfortunately didn’t work. I had hoped that I could use the model to do maximum likelihood estimates of the Elo ratings of players of a given game, but the model seems to utilize the rating information too badly.
Although I am quite happy with the model I managed to train, there are further avenues for improvement.
Currently, I provide the game position in the same way, independent of who’s move it is. One way to improve performance might be to mirror the position for black, so that the board is always seen from the perspective of the player who is going to make a move.
As mentioned, the Elo rating of both players that is provided to the model is not utilized particularly well. The accuracy is only boosted by a small part of a percent. The Maia results, where a different model is trained for each 100-point rating range with a big drop-off in accuracy outside that range, indicate that there is more potential to use rating information for accuracy gains.
TL;DR:
- Read the relevant literature and take note of all tricks
- Use Colab for free GPU time. [Now, maybe rather use free Kaggle notebooks]
- Rezero or Dynamic Linear Combinations for scaling depth.
- Shuffle data and create train, validation, test sets from the beginning.
- Shuffle in memory if samples are otherwise correlated.
- Train a simple fully connected network as baseline and sanity check.
- Establish scaling laws to find bottlenecks and aim at the ideal model size.
- Use gradient accumulation to fit larger models on a small GPU.
- Lower the learning rate when the model stagnates, but don't start too low. [Better yet, use a cyclic learning rate schedule.]
0 comments
Comments sorted by top scores.