Use and misuse of models: case study
post by Stuart_Armstrong · 2017-04-27T14:36:15.140Z · LW · GW · Legacy · 4 commentsContents
The problem: what really determined the result Trees and forests None 4 comments
Some time ago, I discovered a post comparing basic income and basic job ideas. This sought to analyse the costs of paying everyone a guaranteed income versus providing them with a basic job with that income. The author spelt out his assumptions and put together a two models with a few components (including some whose values were drawn from various probability distributions). Then he ran a Monte Carlo simulation to get a distribution of costs for either policy.
Normally I should be very much in favour of this approach. It spells out the assumptions, it uses models, it decomposes the problem, it has stochastic uncertainty... Everything seems ideal. To top it off, the author concluded with a challenge aiming at improving reasoning around this subject:
How to Disagree: Write Some Code
This is a common theme in my writing. If you are reading my blog you are likely to be a coder. So shut the fuck up and write some fucking code. (Of course, once the code is written, please post it in the comments or on github.)I've laid out my reasoning in clear, straightforward, and executable form. Here it is again. My conclusions are simply the logical result of my assumptions plus basic math - if I'm wrong, either Python is computing the wrong answer, I got really unlucky in all 32,768 simulation runs, or you one of my assumptions is wrong.
My assumption being wrong is the most likely possibility. Luckily, this is a problem that is solvable via code.
And yet... I found something very unsatisfying. And it took me some time to figure out why. It's not that these models are helpful, or that they're misleading. It's that they're both simultaneously.
To explain, consider the result of the Monte Carlo simulations. Here are the outputs (I added the red lines; we'll get to them soon):
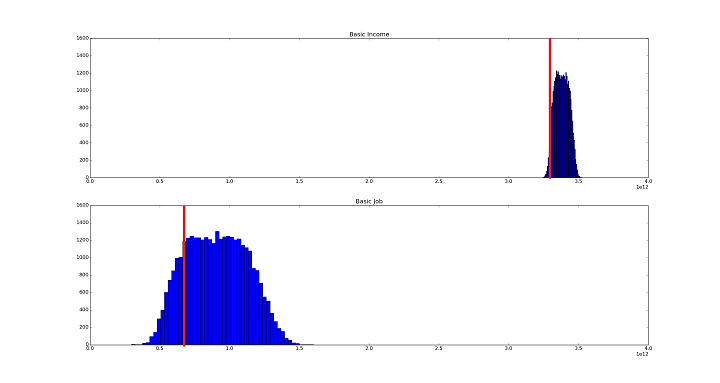
The author concluded from these outputs that a basic job was much more efficient - less costly - than a basic income (roughly 1 trillion cost versus 3.4 trillion US dollars). He changed a few assumptions to test whether the result held up:
For example, maybe I'm overestimating the work disincentive for Basic Income and grossly underestimating the administrative overhead of the Basic Job. Lets assume both of these are true. Then what?
The author then found similar results, with some slight shifting of the probability masses.
The problem: what really determined the result
So what's wrong with this approach? It turns out that most of the variables in the models have little explanatory power. For the top red line, I just multiplied the US population by the basic income. The curve is slightly above it, because it includes such things as administrative costs. The basic job situation was slightly more complicated, as it includes a disabled population that gets the basic income without working, and a estimate for the added value that the jobs would provide. So the bottom red line is (disabled population)x(basic income) + (unemployed population)x(basic income) - (unemployed population)x(median added value of jobs). The distribution is wider than for basic income, as the added value of the jobs is a stochastic variable.
But, anyway, the contribution of the other variables were very minor. So the reduced cost of basic jobs versus basic income is essentially a consequence of the trivial fact that it's more expensive to pay everyone an income, than to only pay some people and then put them to work at something of non-zero value.
Trees and forests
So were the complicated extra variables and Monte Carlo runs for nothing? Not completely - they showed that the extra variables were indeed of little importance, and unlikely to change the results much. But nevertheless, the whole approach has one big, glaring flaw: it does not account for the extra value for individuals of having a basic income versus a basic job.
And the challenge - "write some fucking code" - obscures this. The forest of extra variables and the thousands of runs hides the fact that there is a fundamental assumption missing. And pointing this out is enough to change the result, without even needing to write code. Note this doesn't mean the result is wrong: some might even argue that people are better off with a job than with the income (builds pride in one's work, etc...). But that needs to be addressed.
So Chris Stucchio's careful work does show one result - most reasonable assumptions do not change the fact that basic income is more expensive than basic job. And to disagree with that, you do indeed need to write some fucking code. But the stronger result - that basic job is better than basic income - is not established by this post. A model can be well designed, thorough, filled with good uncertainties, and still miss the mark. You don't always have to enter into the weeds of the model's assumptions in order to criticise it.
4 comments
Comments sorted by top scores.
comment by simon · 2017-04-29T12:03:50.824Z · LW(p) · GW(p)
Another issue: as far as I can tell, he does not account for people switching from regular jobs to the basic job and the corresponding loss of productivity from not working regular jobs.
I also noticed, when trying to figure out whether he accounted for that or not:
Here, "non_worker" actually refers to workers outside the basic job
But then he defines the number of basic workers in such a way that a decreasing number of non-workers also leads to a decreasing number of people on the basic job.
Edit: and probably much more importantly, he counts the basic income as a cost as given, but not as a benefit as received. It's a monetary transfer, and thus destroys wealth only to the extent that it changes incentives (wealth efffect -> less incentive to work for the poor, higher marginal taxes -> less incentive to work for the rich). A correct calculation needs to assess the effect of these incentives and not count the transfer as if it were destruction of wealth.
Further edit: of course, that point is part of "it does not account for the extra value for individuals of having a basic income", now also paying attention to the people in the labour force receiving a basic income, and also looking at it from a wealth standpoint v. utility standpoint. I suppose in the end it should be a utility standpoint that should be used, but one needs to take into account effects on wealth in assessing the utility as well.
comment by MrMind · 2017-04-28T07:24:50.896Z · LW(p) · GW(p)
I would compendiate the article like thus, tell me if it's a fair representation of your point of view:
"The most likely possibilities: my assumptions or my presuppositions are wrong. The first is a problem that is solvable via code. The second just invalidate the model."
Replies from: Stuart_Armstrong↑ comment by Stuart_Armstrong · 2017-05-01T04:50:18.148Z · LW(p) · GW(p)
Almost that. The model still has some validity about the variables that it does look at. But basically, yeah.