OpenAI's Sora is an agent
post by Caleb Biddulph (caleb-biddulph) · 2024-02-16T07:35:52.171Z · LW · GW · 25 commentsContents
How to play any video game by predicting the next frame Beyond video games None 25 comments
If you haven't already, take a look at Sora, OpenAI's new text-to-video AI. Sora can create scarily-realistic videos of nearly any subject. Unlike previous state-of-the-art AIs, the videos are coherent across time scales as long as one minute, and they can be much more complex.
Looking through OpenAI's research report, this one section caught my attention:

For a moment, I was confused: "what does it mean, Sora can 'control the player in Minecraft with a basic policy?' It's generating footage of a video game, not actually playing it... right?"
It's true that in these particular demo videos, Sora is "controlling the player" in its own internal model, rather than interfacing with Minecraft itself. However, I believe OpenAI is hinting that Sora can open the door to a much broader set of applications than just generating video.
In this post, I'll sketch an outline of how Sora could be used as an agent that plays any video game. With a bit of "visual prompt engineering," I believe this would even be possible with zero modifications to the base model. You could easily improve the model's efficiency and reliability by fine-tuning it and adding extra types of tokens, but I'll refrain from writing about that here.
The capabilities I'm predicting here aren't totally novel - OpenAI itself actually trained an AI to do tasks in Minecraft, very similarly to what I'll describe here.
What interests me is that Sora will likely be able to do many general tasks without much or any specialized training. In much the same way that GPT-3 learned all kinds of unexpected emergent capabilities just by learning to "predict the next token," Sora's ability to accurately "predict the next frame" could let it perform many visual tasks that depend on long-term reasoning.
Sorry if this reads like an "advancing capabilities" kind of post. Based on some of the wording throughout their research report, I believe OpenAI is already well aware of this, and it would be better for people to understand the implications of Sora sooner rather than later.
How to play any video game by predicting the next frame
Recall from the OpenAI report that Sora can take any video clip as input and predict how it will continue. To start it off, let's give it a one-second clip from the real Minecraft video game, showing the player character shuffling around a bit. At the bottom of that video, we'll add a virtual keyboard and mouse to the screen. The keys and buttons will turn black whenever the player presses them, and an arrow will indicate the mouse's current velocity:
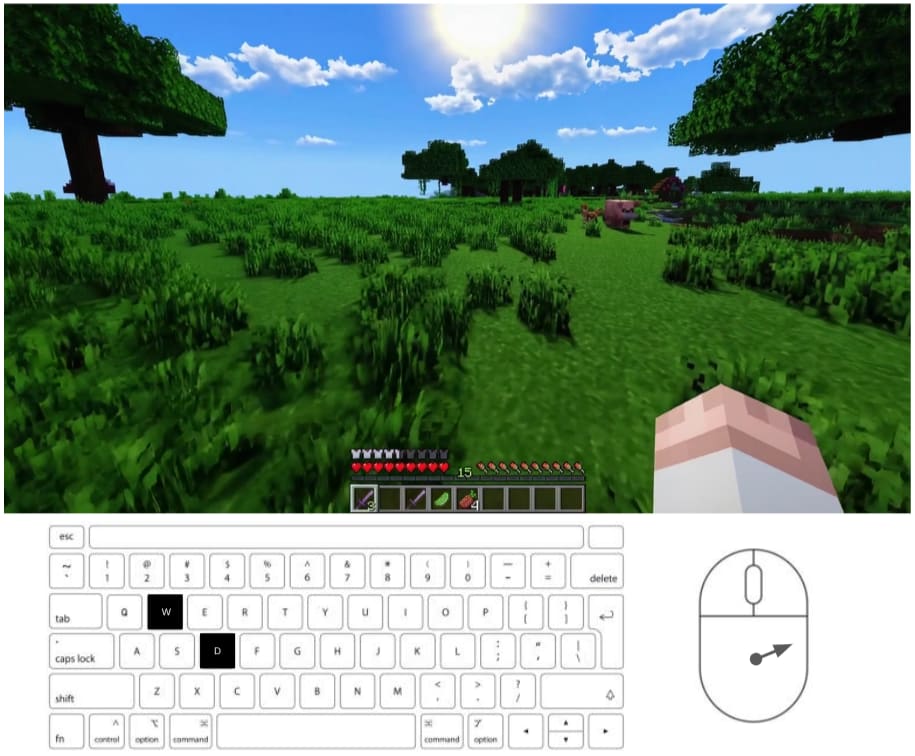
If we ask Sora to continue the video with a short clip, it'll keep making the player character move around. Hopefully, it'll also change the display to reflect the actions the player is making - for instance, the left mouse button should turn black whenever the player interacts with an object. Video game streamers sometimes play with virtual keyboards on their screen, so I don't think it would be a huge logical leap for Sora to be able to accurately highlight the right keys.
This is how we can let Sora take "actions." Suppose that right after recording that one-second clip, we stop the game and wait for Sora to predict the next 0.1 seconds of the video. Once we have our results, we just take the average color of each key in the last frame of the predicted video and determine which buttons Sora thinks the player will be pressing. Finally, we continue the game for 0.1 seconds, holding down those buttons, and feed the 1.1 seconds of real Minecraft video into Sora to get its next move.
Now Sora is moving around, doing some things that would be pretty reasonable for a human player to do. To give it some direction, let's add the text prompt "building a house." This will make Sora take actions that it's seen from Minecraft players in its training data who were building houses.
Who knows, Sora might build a pretty good house just by looking a tenth of a second into the future again and again. But remember, "video generation models are world simulators." Sora can predict up to a minute of video at once, ensuring that the entire video is consistent from start to finish. This means that it can accurately simulate the entire process of building a house, as long as it takes under one minute. Effectively, Sora can "visualize" the next steps it's going to take, much like a human would.
You can make Sora generate an entire coherent video of the player building a house, then take the frame just 0.1 seconds into that video and extract its action. You could even generate several videos to see multiple possible house-building strategies that the player might take, multiple best-guesses of environments the player might find themselves in, and choose the most common set of button presses 0.1 seconds into all of those videos.
Of course, the more video frames you generate, the less efficiently your agent will run. There are easy ways you could speed it up, but those are outside the scope of this post.
You don't even need text to get Sora to do what you want. Recall that Sora can interpolate between two fixed clips at the start and the end of the video. You can start Sora off on the first level of Super Mario Bros:
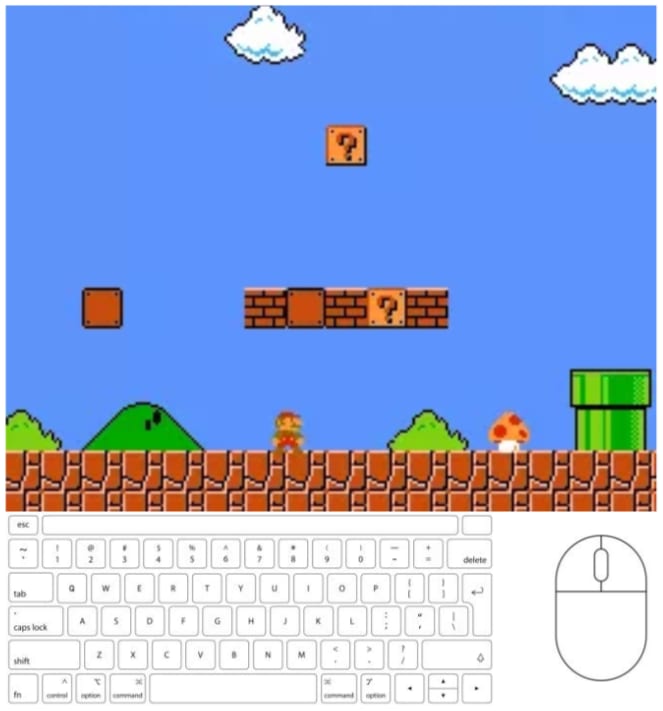
And interpolate to this image one minute later (or 30 seconds later if you want to go for a speedrun):

Beyond video games
Of course, Sora's capabilities as an agent aren't limited to games. OpenAI already demonstrated its ability to predict how an artist will place paint on a canvas:

It's not hard to imagine what might happen if you hooked up Sora to a live video feed of a paintbrush controlled by a robot arm.
Maybe the concept of "AI taking artists' jobs" isn't as shocking as it once was, but Sora could be repurposed for many other visual tasks:
- Operating autonomous vehicles and drones in highly complex situations.
- Fluidly controlling a digital "avatar" while conversing with a user, reacting to their movements and facial expressions.
- Perhaps most notably, operating any computer with a screen. As far as I can tell, Sora's text understanding isn't great yet, but as they say, "two more papers down the line..." Your fully-remote office job might be at risk not too long from now.
And this is all without any fine-tuning or specialized changes to the architecture. If I can think of these ideas in a few hours, just imagine how many uses for this technology will exist a year from now. All I can say is, prepare for things to get weird.
25 comments
Comments sorted by top scores.
comment by tailcalled · 2024-02-16T08:16:35.830Z · LW(p) · GW(p)
Agent-complete would surely have to mean that it can do just about any task that requires agency, rather than that it can just-barely be applied to do the very easiest tasks that require agency. I strongly doubt that SORA is agent-complete in the strong sense.
Replies from: caleb-biddulph↑ comment by Caleb Biddulph (caleb-biddulph) · 2024-02-16T09:01:37.708Z · LW(p) · GW(p)
That sounds more like "AGI-complete" to me. By "agent-complete" I meant that Sora can probably act as an intelligent agent in many non-trivial settings, which is pretty surprising for a video generator!
Replies from: tailcalled↑ comment by tailcalled · 2024-02-16T09:30:42.454Z · LW(p) · GW(p)
many
If you don't handle all of some domain but instead just handle "many" settings within the domain, you're not complete with respect to the domain.
"Complete" implies "general".
Replies from: caleb-biddulph↑ comment by Caleb Biddulph (caleb-biddulph) · 2024-02-16T16:30:12.351Z · LW(p) · GW(p)
Reading the Wikipedia article for "Complete (complexity)," I might have misinterpreted what "complete" technically means.
What I was trying to say is "given Sora, you can 'easily' turn it into an agent" in the same way that "given a SAT solver, you can 'easily' turn it into a solver for another NP-complete problem."
I changed the title from "OpenAI's Sora is agent-complete" to "OpenAI's Sora is an agent," which I think is less misleading. The most technically-correct title might be "OpenAI's Sora can be transformed into an agent without additional training."
comment by gwern · 2024-02-16T20:24:41.488Z · LW(p) · GW(p)
Here's a simpler way to turn a generative model into a policy which doesn't rely on actions being encoded into the state (which won't be true in most settings and can't be true in some - there are no 'actions' for a human moving around) or reversing the image generator to the prompt etc: assume your agent harness at least has a list of actions A. (In the case of Minecraft, I guess it'd be the full keyboard + mouse?) Treat Sora as a Decision Transformer, and prompt it with the goal like "A very skilled player creating a diamond, in the grass biome.", initialized at the current actual agent state. Sample the next displayed state. Now, loop over each action A and add it to the prompt: "The player moves A" and sample the next displayed state. Take whichever action A yielded a sample closest to the original action-free prompt (closest embedding, pixel distance, similar likelihood etc). This figures out what action is being taken by the internal imitated agent by blackbox generation. If unclear (eg. due to perceptual aliasing so the right action & wrong action both lead to immediately the same displayed state), sample deeper and unroll until the consequences do become clear.
This is not an efficient approach at all, but it is a minimal proof of concept about how to extract the implicit agency it has learned from the imitation-learning modeling of humans & other agents. (I say 'other agents' to be clear that agency can be learned from anywhere; like, it seems obvious that they are using game engines, and if you are using a game engine, you will probably want it populated by AI agents inside the game for scalability compared to using only human players.)
comment by Martín Soto (martinsq) · 2024-02-16T19:12:15.980Z · LW(p) · GW(p)
Guy who reinvents predictive processing through Minecraft
comment by Chris_Leong · 2024-02-16T08:49:22.925Z · LW(p) · GW(p)
It seems like there should be a connection here with Karl Friston's active inference. After all, both you and his theory involve taking a predictive engine and using it to produce actions.
comment by Hailey Collet (hailey-collet) · 2024-02-19T15:50:21.484Z · LW(p) · GW(p)
The thing about the simulation capability that worries me most isn't plugging it in as-is, but probing the model, finding where the simulator pieces are and extracting them. This is obviously complicated, but for example something as simple as a linear probe identifying which entire layers are most involved and initializing a new model for training with those layers integrated, a model which doesn't have to output video (obviously your data/task/loss metric would have to ensure it gets used/updated/not overwritten, but choosing things where it would be useful should be enough)... I'm neither qualified to elaborate further nor inclined to do so, but the broad concern here is more efficient application of the simulation capability / integrating it into more diverse models.
Replies from: N1X↑ comment by N1X · 2024-02-22T22:27:55.547Z · LW(p) · GW(p)
Why "selection" could be a capacity which would generalize: albeit to a (highly-lossy) first approximation, most of the most successful models have been based on increasingly-general types of gamification of tasks. The more general models have more general tasks. Video can capture sufficient information to describe almost any action which humans do or would wish to take along with numerous phenomena which are impossible to directly experience in low-dimensional physical space, so if you can simulate a video, you can operate or orchestrate reality.
Why selection couldn't generalize: I can watch someone skiing but that doesn't mean that I can ski. I can watch a speedrun of a video game and, even though the key presses are clearly visible, fail to replicate it. I could also hack together a fake speedrun. I suspect that Sora will be more useful for more-convincingly-faking speedrun content than for actually beating human players or becoming the TAS tool to end all TAS tools (aside from novel glitch discovery). This is primarily because there's not a strong reason to believe that the model can trained to achieve extremely high-fidelity or high-precision tasks.
comment by Alex Mallen (alex-mallen) · 2024-02-17T19:13:09.635Z · LW(p) · GW(p)
I think the relevant notion of "being an agent" is whether we have reason to believe it generalizes like a consequentialist (e.g. its internal cognition considers possible actions and picks among them based on expected consequences and relies minimally on the imitative prior). This is upstream of the most important failure modes as described by Roger Grosse here.
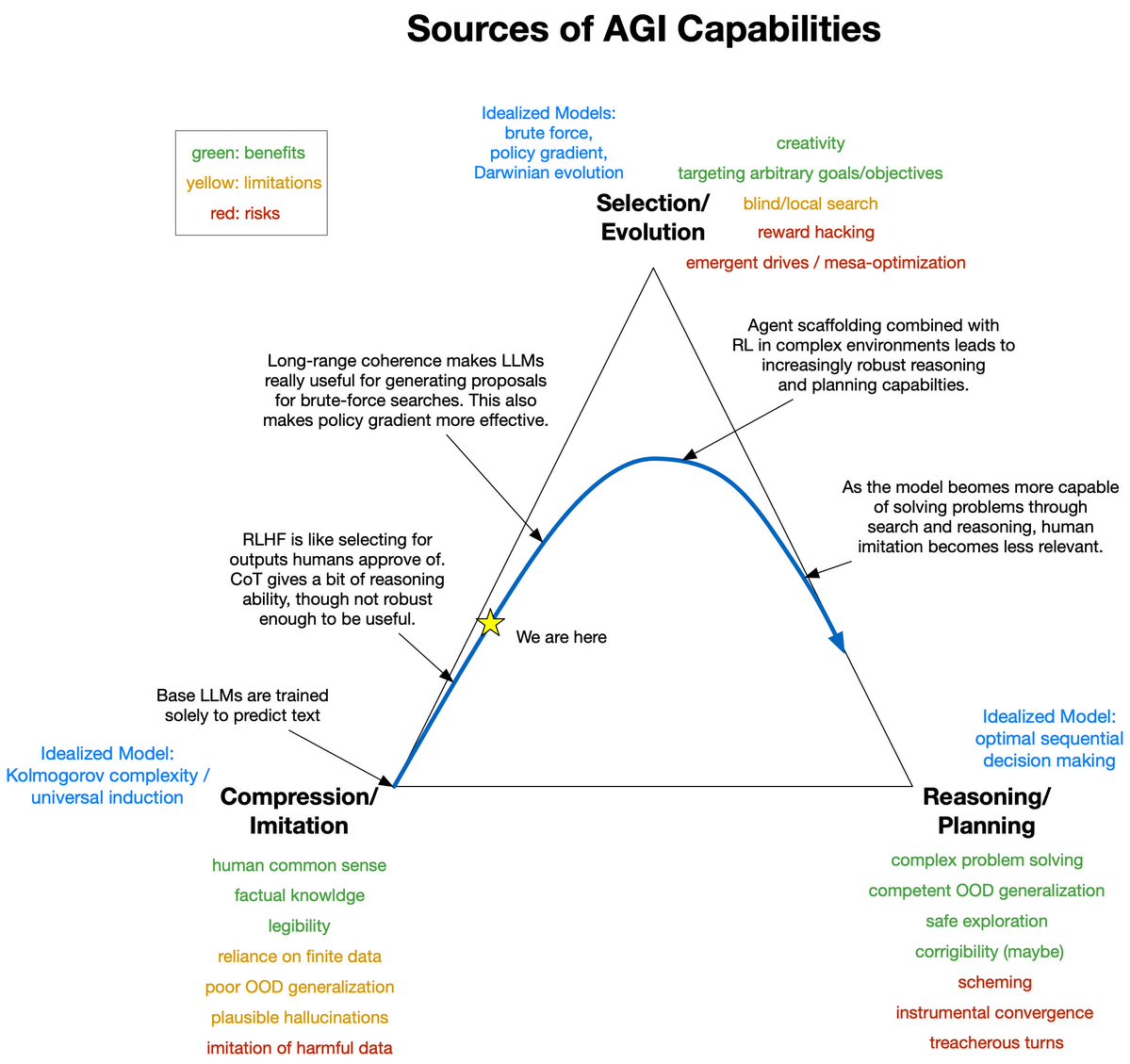
I think Sora is still in the bottom left like LLMs, as it has only been trained to predict. Without further argument or evidence I would expect that it probably for the most part hasn't learned to simulate consequentialist cognition, similar to how LLMs haven't demonstrated this ability yet (e.g. fail to win a chess game in an easy but OOD situation).
comment by Chris_Leong · 2024-02-16T09:02:08.153Z · LW(p) · GW(p)
It's worth noting that there are media reports that OpenAI is developing agents that will use your phone or computer. I suppose it's not surprising that this would be their next step given how far a video generation model takes you towards this, although I do wonder how they expect these agents to operate with any reliability given the propensity of ChatGPT to hallucinate.
comment by Tao Lin (tao-lin) · 2024-02-18T17:53:26.651Z · LW(p) · GW(p)
I think the "fraction of Training compute" going towards agency vs nkn agency will be lower in video models than llms, and llms will likely continue to be bigger, so video models will stay behind llms in overall agency
comment by Cole Wyeth (Amyr) · 2024-02-16T17:33:53.625Z · LW(p) · GW(p)
One could hook up a language model to decide what to visualize, Sora to generate visualizations, and a vision model to extract outcomes.
This seems like around 40% of what intelligence is - the only thing I don't really see is how reward should be "plugged in," but there may be naive ways to set goals.
comment by Nikola Jurkovic (nikolaisalreadytaken) · 2024-02-17T00:16:45.830Z · LW(p) · GW(p)
EDIT: as Ryan helpfully points out in the replies, the patent I refer to is actually about OpenAI's earlier work, and thus shouldn't be much of an update for anything. Note that OpenAI has applied for a patent which, to my understanding, is about using a video generation model as a backbone for an agent that can interact with a computer. They describe theirtraining pipeline as something roughly like:
Start with unlabeled video data ("receiving labeled digital video data;")Train an ML model to label the video data ("training a first machine learning model including an inverse dynamics model (IDM) using the labeled digital video data")Then, train a new model to generate video ("further training the first machine learning model or a second machine learning model using the pseudo-labeled digital video data to generate at least one additional pseudo-label for the unlabeled digital video.")Then, train the video generation model to predict actions (keyboard/mouse clicks) a user is taking from video of a PC ("2. The method of claim 1, wherein the IDM or machine learning model is trained to generate one or more predicted actions to be performed via a user interface without human intervention. [...] 4. The method of claim 2, wherein the one or more predicted actions generated include at least one of a key press, a button press, a touchscreen input, a joystick movement, a mouse click, a scroll wheel movement, or a mouse movement.')
Now you have a model which can predict what actions to take given a recording of a computer monitor!
They even specifically mention the keyboard overlay setup you describe:
11. The method of claim 1, wherein the labeled digital video data comprises timestep data paired with user interface action data.
If you haven't seen the patent (to my knowledge, basically no-one on LessWrong has?) then you get lots of Bayes points!
I might be reading too much into the patent, but it seems to me that Sora is exactly the first half of the training setup described in that patent. So I would assume they'll soon start working on the second half, which is the actual agent (if they haven't already).
I think Sora is probably (the precursor of) a foundation model for an agent with a world model. I actually noticed this patent a few hours before Sora was announced, and I had the rough thought of "Oh wow, if OpenAI releases a video model, I'd probably think that agents were coming soon". And a few hours later Sora comes out.
Interestingly, the patent contains information about hardware for running agents. I'm not sure how patents work and how much this actually implies OpenAI wants to build hardware, but sure is interesting that this is in there:
Replies from: ryan_greenblatt, ryan_greenblatt, ryan_greenblatt
13. A system comprising:
at least one memory storing instructions;
at least one processor configured to execute the instructions to perform operations for training a machine learning model to perform automated actions,
↑ comment by ryan_greenblatt · 2024-02-17T00:31:26.792Z · LW(p) · GW(p)
AFAICT, the is very similar to the exact process used for OpenAI's earlier minecraft video pretraining work.
Edit: yep, this patent is about this video pretraining work.
Replies from: nikolaisalreadytaken↑ comment by Nikola Jurkovic (nikolaisalreadytaken) · 2024-02-17T00:44:24.436Z · LW(p) · GW(p)
Thanks a lot for the correction! Edited my comment.
↑ comment by ryan_greenblatt · 2024-02-17T00:37:55.128Z · LW(p) · GW(p)
Interestingly, the patent contains information about hardware for running agents. I'm not sure how patents work and how much this actually implies OpenAI wants to build hardware, but sure is interesting that this is in there:
I think the hardware description in the patent is just bullshit patent-ese. Like they patent people maybe want to see things that look like other patents and patents don't really understand or handle software well I think. I think the hardware description is just a totally normal description of a setup for running a DNN.
↑ comment by ryan_greenblatt · 2024-02-17T00:35:39.184Z · LW(p) · GW(p)
video generation model
I've read the patent a bit and I don't think it's about video generation, just about adding additional labels to unlabeled video.
Then, train a new model to generate video ("further training the first machine learning model or a second machine learning model using the pseudo-labeled digital video data to generate at least one additional pseudo-label for the unlabeled digital video.")
This is just generating pseudo-labels for existing unlabeled video data. See the video pretraining work that this patent references.
comment by Ericf · 2024-02-16T23:52:30.606Z · LW(p) · GW(p)
If you have to give it a task, is it really an agent? Is there some other word for "system that comes up with its own tasks to do"?
Replies from: gilch↑ comment by gilch · 2024-02-17T19:23:53.428Z · LW(p) · GW(p)
Did you come up with your hunger drive on your own? Sex drive? Pain aversion? Humans count as agents, and we have these built in. Isn't it enough that the agent can come up with subgoals to accomplish the given task?
Replies from: Ericf↑ comment by Ericf · 2024-02-20T00:23:43.504Z · LW(p) · GW(p)
The described "next image" bot doesn't have goals like that, though. Can you take the pre-trained bot and give it a drive to "make houses" and have it do that? When all the local wood is used up, will it know to move elsewhere, or plant trees?
Replies from: gilch↑ comment by gilch · 2024-02-20T19:20:25.932Z · LW(p) · GW(p)
Yes, maybe? That kind of thing is presumably in the training data and the generator is designed to have longer term coherence. Maybe it's not long enough for plans that take too long to execute, so I'm not sure if Sora per se can do this without trying it (and we don't have access), but it seems like the kind of thing a system like this might be able to do.
comment by MiguelDev (whitehatStoic) · 2024-02-16T08:29:36.340Z · LW(p) · GW(p)
repurposed for many other visual tasks:
MKBHD's video commenting that the stock video industry being be hurt by Sora is pretty compelling, especially as he was even pointing out that he could have been fooled by some of them if he was just randomly browsing social media.