Is GPT-N bounded by human capabilities? No.
post by Cleo Nardo (strawberry calm) · 2022-10-17T23:26:43.981Z · LW · GW · 8 commentsContents
8 comments
I recently talked with someone about large language models and the risks they pose. They suggested that LLMs would be bounded by human intelligence/knowledge because LLMs learn from the internet text that humans have written.
Now, this was a very casual conversation (small-talk at a housewarming party), and they changed their mind a few minutes later. But perhaps this is an assumption people often make about LLMs.
Anyway, I'll briefly explain why LLMs are not bounded by human capacities.
I think the picture they had in their head was something like this:
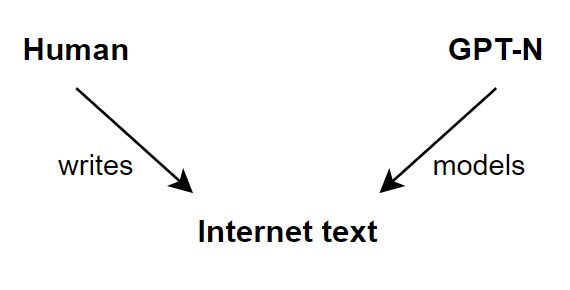
Let's say that all the internet text has been written by humans and we train GPT-N to model the text. There are many ways that GPT-N might do this, but at the very least, GPT-N can just model the humans writing the internet text. This strategy is overkill — like swatting a fly with a sledgehammer — but it suggests that GPT-N has no incentive for more-than-human intelligence or more-than-human knowledge.
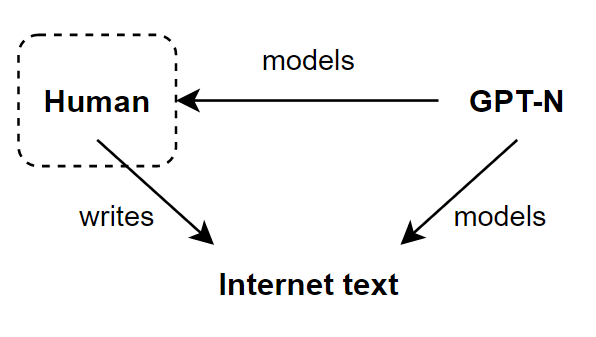
- Concretely, GPT-N doesn't need to "know" things that humans don't know.
For example, humans currently don't know the genome of the next pandemic virus, and therefore the genome of the next pandemic virus won't appear in the internet text, and therefore GPT-N doesn't need to "know" the genome of the next pandemic virus. - Similarly, GPT-N doesn't need any skills that humans don't possess.
For example, humans currently can't prove really tricky theorems in mathematics, and therefore proofs of really tricky theorems won't appear in the internet text, and therefore GPT-N won't need to prove really tricky theorems.
Here's the problem. If GPT-N wants to perfectly model the internet text, it must model the entire causal process which generates it. But this causal process doesn't just include the human, but rather includes the entire universe that the human interacts with.
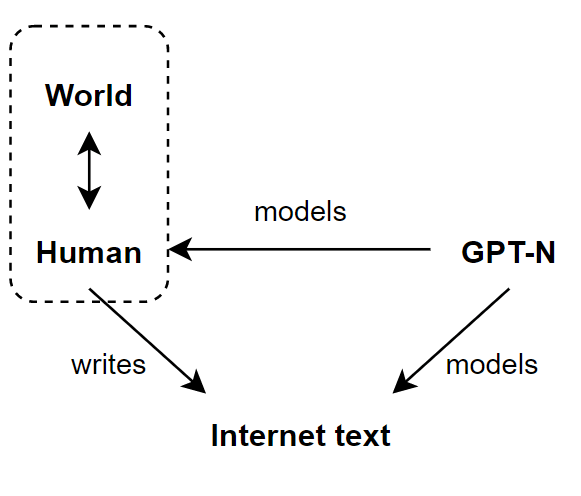
For example, suppose the internet text includes many chess games between Stockfish engines. If GPT-N wants to minimise cross-entropy loss on internet text, then GPT-N would need to learn chess at the level of Stockfish. It doesn't matter that it was a human who physically typed the games onto the internet. A model which could play superhuman chess would achieve lower cross-entropy loss on the current internet text.
(What exactly do I mean by "learn chess"? Either of the following two definitions will work:
- There is a circuit in the weights that instantiates a chess engine.
- You could make a very short & quick chess engine if you had GPT-N as an oracle. Specifically, you could repeatedly feed GPT-N the prompt "The following is complete a game between two Stockfish engines: 1.e4 c5 2.c3 d5 3.exd5 Qxd5 4.d4 Nf6 5.Nf3 " and play the move that GPT-N predicts follows.
The first definition is looking inside the weights, and the second definition treats the weights as a black-box.)
Note: I am not claiming that GPT-N can actually learns superhuman chess — maybe the architecture isn't capable of instantiating a good chess engine. But I am claiming that "GPT-N can't learn superhuman chess" is not implied by "humans wrote all the text on the internet". It is probably better to imagine that the text on the internet was written by the entire universe, and humans are just the bits of the universe that touch the keyboard.
8 comments
Comments sorted by top scores.
comment by Zac Hatfield-Dodds (zac-hatfield-dodds) · 2022-10-18T16:02:27.030Z · LW(p) · GW(p)
There's also the trivial point that human experts tend to specialise, so an AI system which can perform at the level of any human expert in their field will necessarily be far more capable than any particular human even without synergies between such areas of expertise or any generalisation.
comment by the gears to ascension (lahwran) · 2022-10-18T00:15:23.525Z · LW(p) · GW(p)
but currently, you don't get human level chess play even training on a good dataset of chess moves unless you also do something like add a reinforcement learner: Modeling Strong and Human-Like Gameplay with KL-Regularized Search
so while I agree with your assertion of possibility, it still seems to me that extracting signal from noise is the hard part, and additional data is needed for any agent to decide which behaviors online it'd like to imitate. if that feedback data is, eg, RLHF, then while the overall agent can be stronger than human - potentially much stronger - its ability to improve will be limited to the intelligence of the RLHF feedback process.
comment by Robert Miles (robert-miles) · 2023-05-08T12:17:25.597Z · LW(p) · GW(p)
Other tokens that require modelling more than a human:
- The results sections of scientific papers - requires modelling whatever the experiment was about. If humans could do this they wouldn't have needed to run the experiment
- Records of stock price movements - in principle getting zero loss on this requires insanely high levels of capability
comment by harfe · 2022-10-18T00:05:08.095Z · LW(p) · GW(p)
Summary of your argument: The training data can contain outputs of processes that have superhuman abilities (eg chess engines), therefore LLMs can exceed human performance.
More speculatively, there might be another source of (slight?) superhuman abilities: GPT-N could generalize/extrapolate from human abilities to superhuman abilities, if it was plausible that at some point in the future these superhuman abilities would be shown on the internet. For example, it is conceivable that GPT-N prompted with "Here is a proof of the Riemann hypothesis that has been verified extensively:" would actually a valid proof, even if a proof of the Riemann hypothesis was beyond the ability of humans in the training data.
But perhaps this is an assumption people often make about LLMs.
I think people often claim something along the lines of "GPT-8 cannot exceed human capacity" (which is technically false) to argue that a (naively) upscaled version of GPT-3 cannot reach AGI. I think we should expect that there are at least some limits to the intelligence we can obtain from GPT-8, if they just train it to predict text (and not do any amplification steps, or RL).
comment by GoteNoSente (aron-gohr) · 2023-03-17T04:38:42.771Z · LW(p) · GW(p)
It seems to me that there are a couple of other reasons why LLMs might develop capabilities that go beyond the training set:
1. It could be that individual humans make random errors due to the "temperature" of their own thought processes, or systematic errors because they are only aware of part of the information that is relevant to what they are writing about. In both cases, it could be that in each instance, the most likely human completion to a text is objectively the "best" one, but that no human can consistently find the most likely continuation to a text, whereas the LLM can.
2. Humans may think for a very long time when writing a text. An LLM has to learn to predict the next token from the context provided with a relatively small fixed amount of computation (relatively meaning relative to the time spent by humans when writing the original).
3. The LLM might have different inductive biases than humans, and will therefore might fail to learn to imitate parts of human behaviour that are due to human inductive biases and not otherwise related to reality.
I think there is some evidence of these effects happening in practice. For instance, the Maiabot family of chess bots are neural networks. Each of the Maiabot networks is trained on a database of human game at a fixed rating. However, to the best of my knowledge, at least the weaker Maiabots play much stronger than the level of games they were trained on (probably mostly due to effect (1)).
comment by DragonGod · 2022-12-19T23:27:01.525Z · LW(p) · GW(p)
I prefer @Janus simulators thesis [LW · GW]:
Replies from: janusthe upper bound of what can be learned from a dataset is not the most capable trajectory, but the conditional structure of the universe implicated by their sum (though it may not be trivial to extract that knowledge).