The Ap Distribution
post by criticalpoints · 2024-08-24T21:45:35.029Z · LW · GW · 8 commentsThis is a link post for https://eregis.github.io/blog/2024/07/23/Ap-distribution.html
Contents
8 comments
E.T. Jaynes introduces this really interesting concept called the distribution in his book Probability Theory. Despite the book enjoying a cult following, the distribution has failed to become widely-known among aspiring probability theorists. After finishing the relevant chapter in the book, I googled the phrase "Ap distribution" in an attempt to learn more, but I didn't get many search results. So here's an attempt to explain it for a wider audience.
The distribution is a way to give a probability about a probability. It concerns a very special set of propositions that serve as basis functions for our belief state about a proposition —somewhat similarly to how the Dirac delta functions can serve as basis elements for measures over the real line. The proposition says that "regardless of whatever additional evidence that I've observed, the probability that I will assign to proposition is ". It's defined by the rule:
This is a fairly strange proposition. But it's useful as it allows us to encode a belief about a belief. Here's why it's a useful conceptual tool:
If we say that there is a probability of some proposition being true, that can represent very different epistemic states. We can be more or less certain that the probability is "really" .
For example, imagine that you know for sure that a coin is fair: that in the long run, the number of heads flipped will equal the number of tails flipped. Let be the proposition "the next time I flip this coin, it will come up heads." Then your best guess for is . And importantly, no matter what sequence of coin flips you observe, you will always guess that there is a 50% chance that the next coin flip lands on heads.
But imagine a different scenario where you haven't seen a coin get flipped yet, but you are told that it's perfectly biased towards either heads or tails. Because of the principle of indifference, we would assign a probability of to the next coin flip landing on heads—but it's a very different from the case when we had a fair coin. Just one single flip of the coin is enough to collapse the probability of to either or for all time.
There is a useful law in probability called the law of total expectation. It says that your expectation for your future expectation should match your current expectation. So given a static coin, the probability that you give for the next coin flip being heads should be the same as the probability that you give for 100th or 1000000th coin flip being heads.
Mathematically, the law of total expectation can be expressed as:
The law of total expectation is sometimes bastardized as saying "you shouldn't expect your beliefs to change." But that's not what it's saying at all! It's saying that you shouldn't expect your expectation—the center of mass of your state of belief—to change. But all higher moments in belief space can and do change as you acquire more evidence.
And this makes sense. Information is the opposite of entropy; if entropy measures our uncertainty, than information is a measure of our certainty: how constrained the possible worlds are. If I have a biased coin, I give a 50% chance that the 100th flip lands on heads. But I know now that right before the 100th flip, I will be in an epistemic state of 100% certainty in the outcome—it's just that current me doesn't know what outcome future me will be 100% certain in.
A way to think about the proposition is as a kind of limit. When we have little evidence, each bit of evidence has a potentially big impact on our overall probability of a given proposition. But each incremental bit of evidence shifts our beliefs less and less. The proposition can be thought of a shorthand for an infinite collection of evidences where the collection leads to an overall probability of given to . This would perhaps explains why the proposition is so strange: we have well-developed intuitions for how "finite" propositions interact, but the characteristic absorbing property of the distribution is more reminiscent of how an infinite object interacts with finite objects.
For any proposition , the probability of can be found by integrating over our probabilities of
where can be said to represent "the probability that, after encountering an infinite amount of evidence, I will give a probability of to the proposition ."
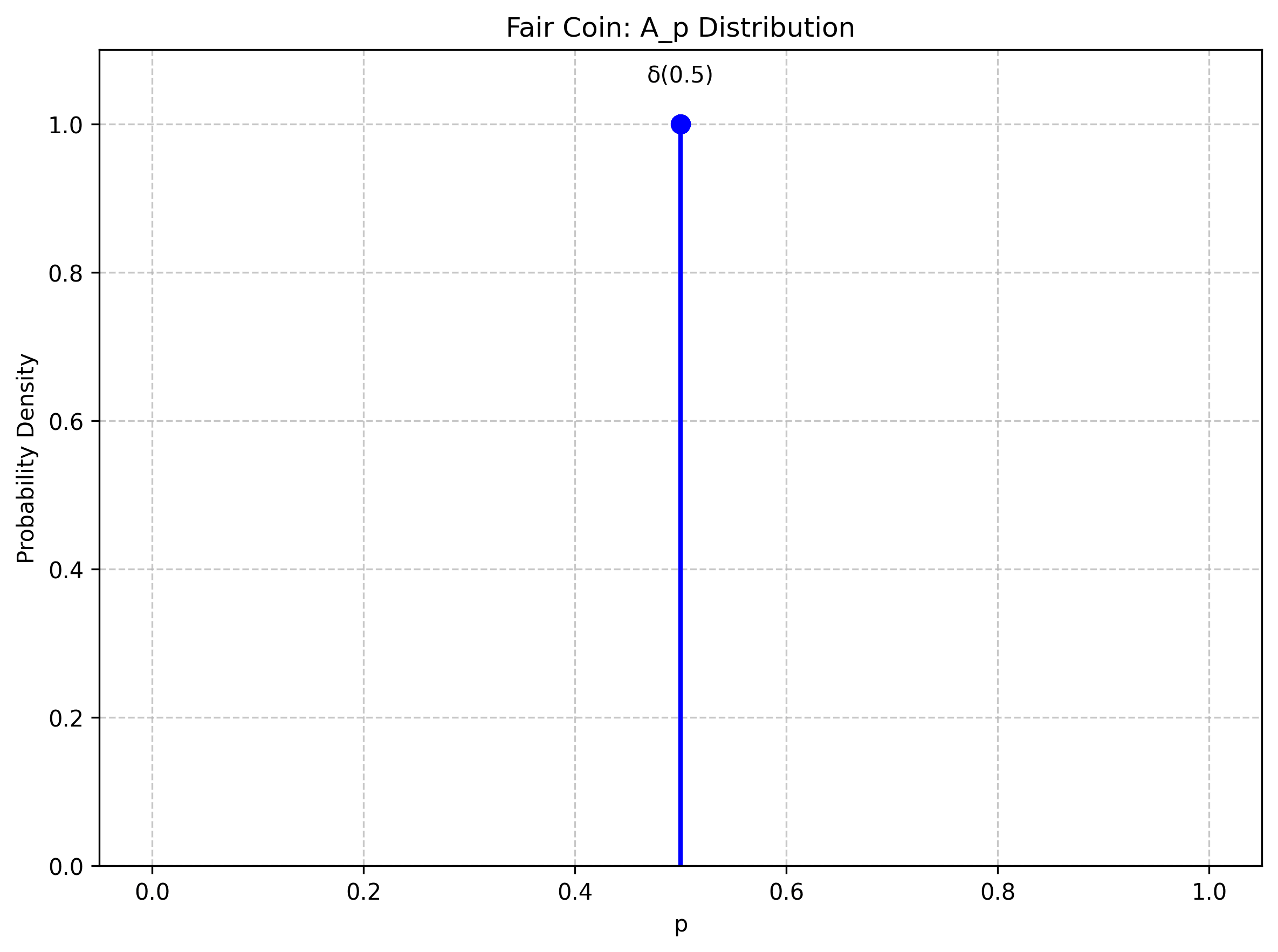
For the fair coin, our belief in space would be represented by a delta function at .
For the biased coin (where we don't know the bias), our belief would be represented by two deltas of weight 1/2 at and .
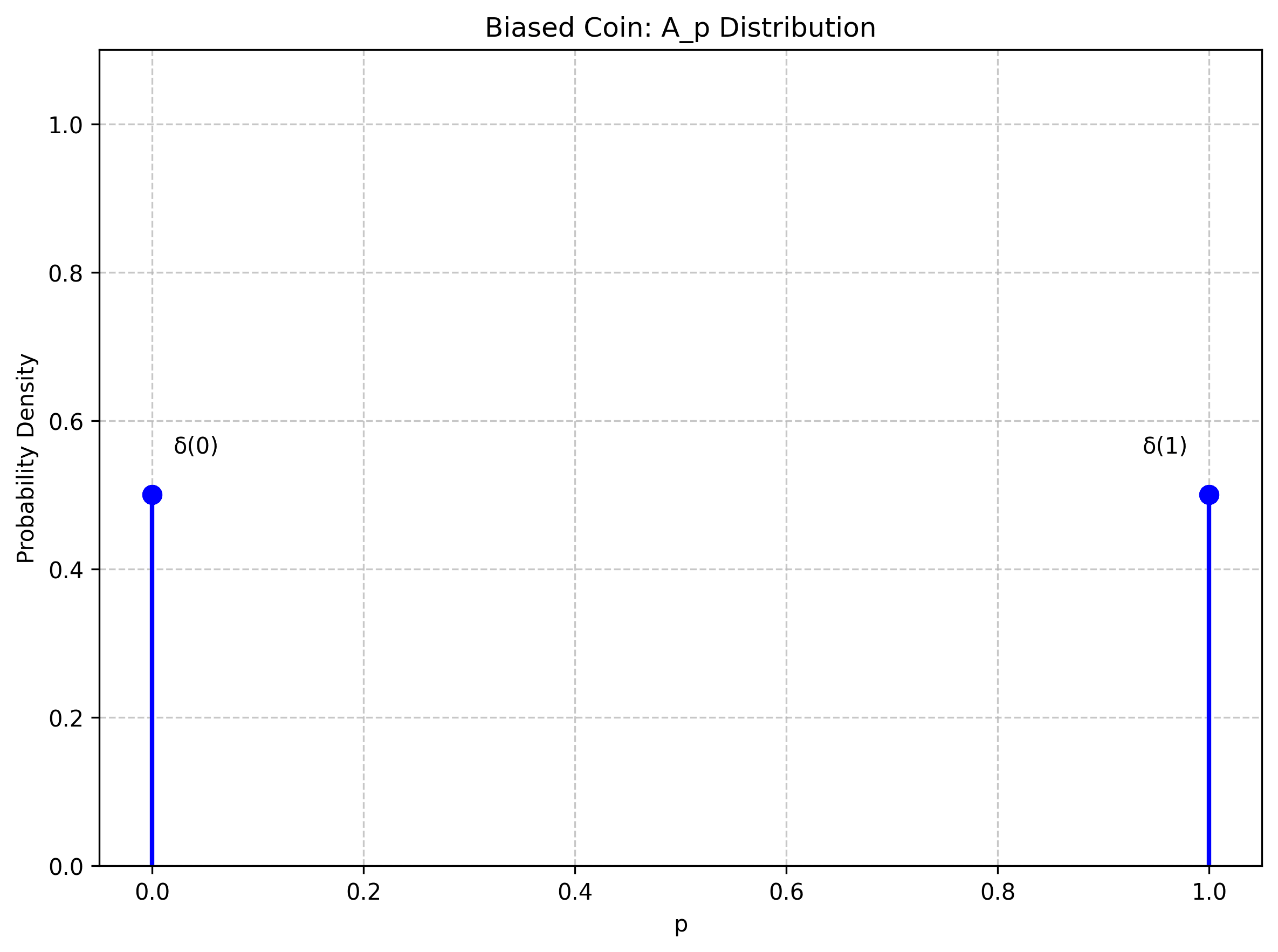
Both distributions assign a probability of to . But the two distributions greatly differ in their variance in space.
8 comments
Comments sorted by top scores.
comment by transhumanist_atom_understander · 2024-12-19T20:37:41.116Z · LW(p) · GW(p)
The reason nobody else talks about the A_p distribution is because the same concept appears in standard probability expositions as a random variable representing an unknown probability. For example, if you look in Hoff's "A First Course in Bayesian Statistics", it will discuss the "binomial model" with an unknown "parameter" Θ. The "event" Θ=p plays the same role as the proposition A_p, since P(Y=1|Θ=p) = p. I think Jaynes does have something to add, but not so much in the A_p distribution chapter as in his chapter on the physics of coin flips, and his analysis of die rolls which I'm not sure if is in the book. He gets you out of the standard Bayesian stats mindset where reality is a binomial model or multinomial model or whatever, and shows you that A_p can actually have a meaning in terms of a physical model, such as a disjunction of die shapes that lead to the same probability of getting 6. Although your way of thinking of it as a limiting posterior probability from a certain kind of evidence is interesting too (or Jaynes's way of thinking of it, if it was in the book; I don't recall). Anyway, I wrote a post on this [LW · GW] that didn't get much karma, maybe you'll be one of the few people that's interested.
Replies from: criticalpoints↑ comment by criticalpoints · 2024-12-22T00:03:35.270Z · LW(p) · GW(p)
Thanks for the reference. You and other commentator both seem to be saying the same thing: that the there isn't much use case for the Ap distribution as Bayesian statisticians have other frameworks for thinking about these sorts of problems. It seems important that I acquaint myself with the basic tools of Bayesian statistics to better contextualize Jaynes' contribution.
Replies from: transhumanist_atom_understander↑ comment by transhumanist_atom_understander · 2024-12-22T01:39:18.062Z · LW(p) · GW(p)
Sort of. I think the distribution of Θ is the Ap distribution, since it satisfies that formula; Θ=p is Ap. It's just that Jaynes prefers an exposition modeled on propositional logic, whereas a standard probability textbook begins with the definition of "random variables" like Θ, but this seems to me just a notational difference, since an equation like Θ=p is after all a proposition from the perspective of propositional logic. So I would rather say that Bayesian statisticians are in fact using it, and I was just explaining why you don't find any exposition of it under that name. I don't think there's a real conceptual difference. Jaynes of course would object to the word "random" in "random variable" but it's just a word, in my post I call it an "unknown quantity" and mathematically define it the usual way.
comment by acharman · 2024-12-25T07:18:26.541Z · LW(p) · GW(p)
Both the original post and subsequent comments seem to have some misconceptions regarding the distribution as introduced by Jaynes.
(i) @criticalpoints claims that "way to think about the proposition is as a kind of limit ... The proposition can be thought of a shorthand for an infinite collection of evidences." But as also noted, Jaynes wants to say that "regardless of anything else you may have been told, the probability of is ." But in general, this need not involve any limit, or an infinite amount of evidence. For any proposition A, and probability value p, the proposition is something of a formal maneuver, which merely asserts whatever would be minimally required for a rational agent possessing said information to assign a probability of p to proposition A. For a proposition A, and any suitable finite body evidence E, there is a corresponding distribution.
(ii) This may have been a typo, or a result of Jaynes's very non-standard parenthetical notation used for probabilities, but @criticalpoints claims:
For any proposition , the probability of can be found by integrating over our probabilities of
[emphasis added]. But evaluation of p(A|E) is to be achieved by calculating the expectation of p with respect to an distribution, not just the integral---the integral evaluates to unity, , because the distribution is normalized, while
(iii) @transhumanist_atom_understanderder claims that
The reason nobody else talks about the distribution is because the same concept appears in standard probability expositions as a random variable representing an unknown probability
The point is that Jaynes is actually extending the idea of "probability of a probability" that arises in binomial parameter estimation, or in de Finetti's theorem for exchangeable sequences, as a way to compress the information in a body of evidence E relevant to some other proposition A. While Jaynes admits that the trick might not always work, if it does, rather than store every last detail of the information asserted in some compound evidentiary statement E, a rational agent would instead only need to store a description of a probability distribution which is equivalent to some probability distribution over a parameter , so might be approximated by, say, some beta distribution or mixture over beta distributions. The mean of the distribution reproduces the probability of A, while the shape of this distribution characterizes how labile the probability for A will tend to be upon acquisition of additional evidence. Bayesian updating can then take place at the level of the distribution, rather than over some vastly complicated Boolean algebra of possible explicit conditioning information.
So Jaynes' concept of the distribution goes beyond the usual "probability of a probability" introduced in introductory Bayesian texts (such as Hoff or Lee or Sivia) for binomial models. In my opinion, it is a clever construct that does deserve more attention.
Replies from: criticalpoints↑ comment by criticalpoints · 2025-01-04T17:49:07.095Z · LW(p) · GW(p)
-
For the first part about " being a formal maneuver"--I don't disagree with the comment as stated nor with what Jaynes did in a technical sense. But I'm trying to imbue the proposition with a "physical interpretation" when I identify it with an infinite collection of evidences. There is a subtlety with my original statement that I didn't expand on, but I've been thinking about ever since I read the post: "infinitude" is probably best understood as a relative term. Maybe the simplest way to think about this is that, as I understand it, if you condition on two distributions at the same time, you get a "do not compute"--not zero, but "do not compute". So the proposition only seems to make sense with respect to some subset of all possible propositions. I interpret this subset as being those of "finite" evidence while the 's (and other propositions) somehow stand outside of this finite evidence class. There is also the matter that, in day-to-day life, it doesn't really seem possible to encounter what to me seems like a "single" piece of evidence that has the dramatic effect of rendering our beliefs "deterministically indeterministic". Can we really learn something that tells us that there is no more to learn?
-
Yes, I suspect that there is a typo there, though I'm a bit too lazy to reference the original text to check. It should be that the probability density over is normalized, and their expectation is the probability of .
-
This idea of compressing all relevant information of relevant to in the object is interesting and indeed, it's perhaps a better articulation of what I find interesting about the distribution than what is conveyed in the main body of the original post. One thread that I want(ed) to tug at a little further is that the distribution seems to lend itself well to the first steps towards something of a dynamical model of probability theory: when you encounter a piece of evidence , its first-order effect is to change your probability of , but its second and n-th order effects are to affect your distribution of what future evidence you expect to encounter and how to "interpret" those pieces of evidence--where by "interpret" I mean in what way encountering that piece of evidence shifts your probability of . This dynamical theory of probability would have folk theorems like "the variance in your A_p distribution must monotonically decrease over time". These are shower thoughts.
-
And it's also interesting perhaps on a more applied/agentic sense in that we often casually talk about "updating" our beliefs, but what does that actually look like in practice? Empirically, we see that we can have evidence in our head that we fail to process (lack of logical omniscience). Maybe something like the distribution could be helpful for understanding this even better.
comment by rotatingpaguro · 2024-08-25T07:32:22.384Z · LW(p) · GW(p)
I don't think this concept is useful.
What you are showing with the coin is a hierarchical model over multiple coin flips, and doesn't need new probability concepts. Let be the flips. All you need in life is the distribution . You can decide to restrict yourself to distributions of the form . In practice, you start out thinking about as a variable atop all the in a graph, and then think in terms of and separately, because that's more intuitive. This is the standard way of doing things. All you do with is the same, there's no point at which you do something different in practice, even if you ascribed additional properties to in words.
A concept like "the probability of me assigning a certain probability" makes sense but I don't think Jaynes actually did anything like that for real. Here on lesswrong I guess @abramdemski [LW · GW] knows about stuff like that.
--PS: I think Jaynes was great in his way of approaching the meaning and intuition of statistics, but the book is bad as a statistics textbook. It's literally the half-complete posthumous publication of a rambling contrarian physicist, and it shows. So I would not trust any specific statistical thing he does. Taking the general vibe and ideas is good, but when you ask about a specific thing "why is nobody doing this?" it's most likely because it's outdated or wrong.
Replies from: criticalpoints↑ comment by criticalpoints · 2024-08-25T21:14:19.653Z · LW(p) · GW(p)
Thanks for the feedback.
What you are showing with the coin is a hierarchical model over multiple coin flips, and doesn't need new probability concepts. Let be the flips. All you need in life is the distribution . You can decide to restrict yourself to distributions of the form ∫10dpcoinP(F,G|pcoin)p(pcoin). In practice, you start out thinking about as a variable atop all the in a graph, and then think in terms of and separately, because that's more intuitive. This is the standard way of doing things. All you do with is the same, there's no point at which you do something different in practice, even if you ascribed additional properties to in words.
This isn't emphasized by Jaynes (though I believe it's mentioned at the very end of the chapter), but the distribution isn't new as a formal idea in probability theory. It's based on De Finetti's representation theorem. The theorem concerns exchangeable sequences of random variables.
A sequence of random variables is exchangeable if the joint distribution of any finite subsequence is invariant under permutations. A sequence of coin flips is the canonical example. Note that exchangeability does not imply independence! If I have a perfectly biased coin where I don't know the bias, then all the random variables are perfectly dependent on each other (they all must obtain the same value).
De Finetti's representation theorem says that any exchangeable sequence of random variables can be represented as an integral over identical and independent distributions (i.e binomial distributions). Or in other words, the extent to which random variables in the sequence are dependent on each other is solely due to their mutual relationship to the latent variable (the hidden bias of the coin).
You are correct that all relevant information is contained in the joint distribution . And while I have no deep familiarity with Bayesian hierarchical modeling, I believe your claim that the decomposition is standard in Bayesian modeling.
But I think the point is that the distribution is a useful conceptual tool when considering distributions governed by a time-invariant generating process. A lot of real-world processes don't fit that description, but many do fit that description.
A concept like "the probability of me assigning a certain probability" makes sense but I don't think Jaynes actually did anything like that for real. Here on lesswrong I guess @abramdemski knows about stuff like that.
Yes, this is correct. The part about "the probability of assigning a probability" and the part about interpreting the proposition as a shorthand for an infinite collection evidences are my own interpretations of what the distribution "really" means. Specifically, the part about the "probability that you will assign the probability in the infinite future" is loosely inspired by the idea of Cauchy surfaces from e.g general relativity (or any physical theory that has a causal structure built in). In general relativity, the idea is that if you have boundary conditions specified on a Cauchy surface, then you can time-evolve to solve for the distribution of matter and energy for all time. In something like quantum field theory, a principled choice for the Cauchy surface would be the infinite past (this conceptual idea shows up when understanding the vacuum in QFT). But I think in probability theory, it's more useful conceptually to take your Cauchy surface of probabilities to be what you expect them to be in the "infinite future". This is how I make sense of the distribution.
And now that you mention it, this blog post was totally inspired by reading the first couple chapters of "Logical Inductors" (though the inspiration wasn't conscious on my part).
--PS: I think Jaynes was great in his way of approaching the meaning and intuition of statistics, but the book is bad as a statistics textbook. It's literally the half-complete posthumous publication of a rambling contrarian physicist, and it shows. So I would not trust any specific statistical thing he does. Taking the general vibe and ideas is good, but when you ask about a specific thing "why is nobody doing this?" it's most likely because it's outdated or wrong.
Not a statistician, so I will defer to your expertise that the book is bad as a statistics book (never thought of it as a statistics book to be honest). I think the strongest parts of this book are when he derives statistical mechanics from the maximum entropy principle and when he generalizes the principle of indifference to consider more general group invariances/symmetries. As far as I'm aware, my opinion on which of Jaynes' ideas are his best ideas matches the consensus.
I suspect the reason why I like the distribution is that I come from a physics background, so his reformulation of standard ideas in Bayesian modeling makes some amount of sense to me even if comes across as weird and crankish to statisticians.
Replies from: rotatingpaguro↑ comment by rotatingpaguro · 2024-08-26T08:13:03.923Z · LW(p) · GW(p)
I still don't understand your "infinite limit" idea. If in your post I drop the following paragraph:
A way to think about the proposition is as a kind of limit. When we have little evidence, each bit of evidence has a potentially big impact on our overall probability of a given proposition. But each incremental bit of evidence shifts our beliefs less and less. The proposition can be thought of a shorthand for an infinite collection of evidences where the collection leads to an overall probability of given to . This would perhaps explains why the proposition is so strange: we have well-developed intuitions for how "finite" propositions interact, but the characteristic absorbing property of the distribution is more reminiscent of how an infinite object interacts with finite objects.
the rest is standard hierarchical modeling. So even if your words here are suggestive, I don't understand how to actually connect the idea to calculations/concrete things, even at a vague indicative level. So I guess I'm not actually understanding it.
For example, you could show me a conceptual example where you do something with this which is not standard probabilistic modeling. Or maybe it's all standard but you get to a solution faster. Or anything where applying the idea produces something different, then I would see how it works.
(Note: I don't know if you noticed, but De Finetti applies to proper infinite sequences only, not finite ones, people forget this. It is not relevant to the discussion though)