200 COP in MI: Image Model Interpretability
post by Neel Nanda (neel-nanda-1) · 2023-01-08T14:53:14.681Z · LW · GW · 3 commentsContents
Background Motivation Resources Problems None 3 comments
This is the eighth post in a sequence called 200 Concrete Open Problems in Mechanistic Interpretability. Start here [AF · GW], then read in any order. If you want to learn the basics before you think about open problems, check out my post on getting started. Look up jargon in my Mechanistic Interpretability Explainer
Motivating papers: Thread: Circuits, Multimodal Neurons in Artificial Neural Networks
Disclaimer: My area of expertise is language model interpretability, not image models - it would completely not surprise me if this section contains errors, or if there are a lot of great open problems that I’ve missed!
Background
A lot of the early work in mechanistic interpretability was focused on reverse engineering image classification models, especially Inceptionv1 (GoogLeNet). This work was largely (but not entirely!) led by Chris Olah and the OpenAI interpretability team. They got a lot of fascinating results, most notably (in my opinion):
- Finding a technique called Feature Visualization to visualize what neurons are “looking at”, essentially creating a picture that represents what most activates a given neuron

- Intuitively, this technique exploits the fact that each neuron is basically a function that maps an image to a scalar (the neuron activation). Images live in a continuous space (we can vary a pixel by an infinitesimal amount to slightly change the image), so we can do gradient descent on the image to find a max activating image
- Curve Circuits - they reverse engineered a 50,000 ish parameter circuit used to form curve detecting neurons, and understood it well enough that they could hand-code the weights to the neurons, insert in these hand-coded neurons, and (mostly) recover the original performance.
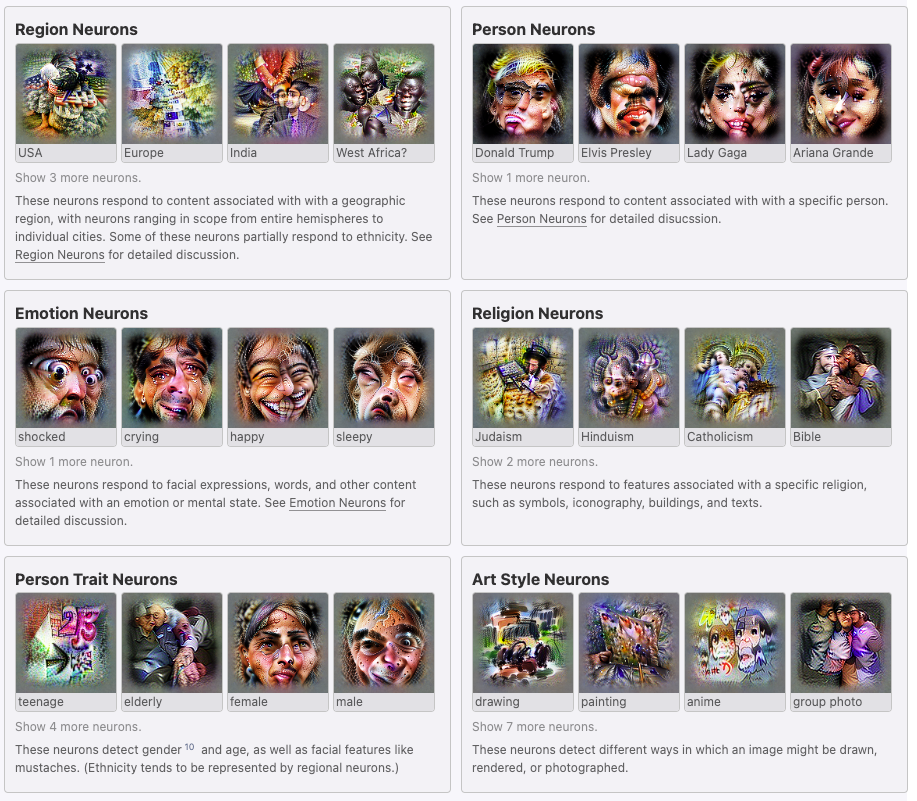
- Multimodal Neurons - they looked at CLIP (a model that takes in an image and a caption and outputs a score for how well they match) and found a bunch of fascinating abstract neurons that seemed to activate on concepts and on things related to that concept - eg a Donald Trump neuron that actives on his picture and on MAGA hats, or neurons corresponding to Halloween, or anime, or Catholicism
Motivation
I think the image interpretability results are awesome, and one of the main things that convinced me that reverse engineering neural networks was even possible! But also, very few people worked on these questions! There was enough work done to give a good base to build off of and to expose a lot of dangling threads, but also a lot of open questions left.
My personal goal with mech interp is to get good enough at understanding systems that we can eventually understand what’s going on in a human-level frontier model, and use this to help align it. From this perspective, is it worth continuing image circuits work? This is not obvious to me! I think language models (and to a lesser degree transformers) are far more likely to be a core part of how we get transformative AI (though I do expect transformative AI to have significant multimodal components), and most of the mech interp field is now focused on LLMs as a result.
But I also think that just any progress on reverse engineering neural networks is good. And at least some insights transfer. Though there are obviously a lot of differences - Inception has a continuous rather than discrete input space, doesn’t have attention heads or a residual stream, and is doing classification rather than generation. I’m personally most excited about image circuits work driving towards fundamental questions about reverse engineering networks:
- How architecture or model specific is reverse engineering work? If people switch to a new, non-transformer architecture, how much effort will be wasted?
- How much are the circuits in models universal, vs random and specific? Does interpreting one model make interpreting the next much easier?
- What techniques can be built, that might generalise?
- How do multimodal models work? What new challenges and opportunities arise when models are mapping multiple kinds of inputs (eg image and language) to shared latent spaces?
My guess is that all other things being the same, marginal effort should go towards language models. But equally, I want a field with a diverse portfolio of research, and all other things may not be the same - image circuits seem to have a pretty different flavour to transformer circuits. And speculation about which architectures or modalities are most relevant to human level are hard and very suspect. Further, I think that often the best way to do research is by following your curiosity and excitement, and whatever nerd-snipes you, and that being too goal directed can be a mistake. If you feel drawn to image circuits work, or think that AGI is a load of overblown hype and want to work on image circuits for other reasons, then more power to you, and I’m excited to see what you learn!
Resources
- The first section of my mech interp explainer, on key general mech interp concepts
- OpenAI Microscope, a gorgeous website that shows a feature visualization for every neuron in a range of vision models, plus max activating dataset examples. It’s very fun to browse!
- The Weight Explorer, a (somewhat janky) tool that lets you explore inception and visualize the weights between each neuron and the neurons in the layer before after.
- The Lucid library - a library from the old OpenAI interpretability team for doing feature visualization
- The ReadMe links to several useful notebooks for various image circuits papers
- Lucent a PyTorch port (Lucid is in tensorflow v1 - don’t bother learning that!)
- Captum is a PyTorch interpretability library which is mostly aimed at non-mechanistic interpretability but may still be useful - here’s a notebook using it for feature visualization of neurons
- The Circuits Thread on Distill, contains a lot of interesting short articles about reverse engineering circuits in image classification models
- The article visualizing weights has a lot of advice and code for standard techniques
- Building Blocks of Interpretability, Feature Visualization and Activation Atlas are also highly worth checking out
- In general, these articles are all incredibly high production quality, and generally very pleasant to read.
- Chris Olah’s request for proposals for mechanistic interpretability work [AF · GW], which lays out a lot of open questions and motivation far better than I can!
- My TransformerLens library - the vanilla library is very optimised for GPT-2 style language models, but if existing image model infrastructure is insufficient, I expect that many of the core principles and the HookPoint infrastructure could be extended to image models (with some work), and give good research infrastructure. Especially vision transformers!
- Reach out if you’re interested in this!
Problems
This spreadsheet lists each problem in the sequence. You can write down your contact details if you're working on any of them and want collaborators, see any existing work or reach out to other people on there! (thanks to Jay Bailey for making it)
- Different image model architectures - how much can we reverse engineer different image model architectures from inception? How well do the techniques transfer?
- B-C* 7.1 - ResNets - essentially convnets with a residual stream. I recommend starting by taking an open source ResNet and seeing what happens when you apply feature visualization to it.
- B-C* 7.2 - Vision Transformers - can you smush together transformer circuits and image circuits techniques? Which ones transfer and which ones break?
- A good simple implementation of a Vision Transformer, if you’re able to read PyTorch, reading this is likely helpful for understanding them!
- I would start by visualizing attention patterns of layer 1 or 2 heads, doing feature vis on the neurons, and doing direct logit attribution on the final layer neurons
- C 7.3 - ConvNeXt - a modern image model architecture, merging ResNet ideas with vision transformer ideas
- Building on the original circuits thread
- Building on the hand-coded curve detectors work:
- B-C* 7.4 - How well can you hand-code curve detectors? Eg, including colour? How much of the original performance can you recover?
- C* 7.5 - Can you hand-code any other circuits? I’d start with some other early vision neurons
- D* 7.6 - What happens if you apply Redwood’s Causal Scrubbing Algorithm to their claimed curve circuits algorithm? Note that I expect this to take significant conceptual effort to extend their to images, since it’s much harder to create precisely controlled inputs.
- B* 7.7 - Looking for equivariance in late layers of vision models, symmetries in a network where there are analogous families of neurons. This will likely look like hunting around in Microscope
- For example, curve detecting neurons come in families for different angles of curves - this means that if we understand one of them, we automatically understand the other 7! Early layers have simple geometric symmetries like colour, rotation and reflection, but late layers are interesting because it’ll likely be more conceptual?
- Left-facing and right-facing dog detectors are another example of equivariance
- C* 7.8 - Digging into examples of polysemantic neurons and trying to understand better what’s going on there.
- A-B 7.9 - Just looking for a wide array of circuits in the model using the weight explorer to look through neurons and how they connect up. What interesting patterns and motifs can you find?
- Building on the hand-coded curve detectors work:
- Multimodal models - Building on the interpretability of CLIP paper
- Reverse-engineering neurons
- B* 7.10 - Look at the weights connecting neurons in adjacent layers. How sparse are they? Are there any clear pattern where one neuron is constructed from previous neurons?
- B-C* 7.11 - Can you rigorously reverse engineer any circuits?
- The Curve Circuits paper is a great model of what different techniques look like here
- B-C* 7.12 - Can you apply transformer circuits techniques to understand the attention heads in the image part?
- B 7.13 - Can you refine the technique for generating max activating text strings used in that paper?
- Could it be applied to language models?
- Reverse-engineering neurons
- C 7.14 - Train a checkpointed run of inception. Do the curve detectors form as a phase change?
- B* 7.15 - Does activation patching work on inception?
- Exploring diffusion models, the architecture behind modern generation models like DALL-E 2 (but not DALL-E 1) or Stable Diffusion
- B-C* 7.16 - Apply feature visualization to the neurons and see whether any seem clearly interpretable.
- B* 7.17 - Are there style transfer neurons? (Ie neurons that activate when given text like “in the style of Thomas Kinkade” - Stable Diffusion is really good at this!)
- B 7.18 - Are different circuits activating when different amounts of noise are input?
- B-C* 7.16 - Apply feature visualization to the neurons and see whether any seem clearly interpretable.
3 comments
Comments sorted by top scores.
comment by Berkan Ottlik (berkan-ottlik) · 2023-01-09T17:51:50.328Z · LW(p) · GW(p)
Different image model architectures
I've done a little bit of work on ViT interpretability. It's kind of messy right now but maybe a starting point for someone else to jump off of + I might add to it in the future: https://berkan.xyz/projects/ (see vision transformer interpretability).
Replies from: arthur-conmy↑ comment by Arthur Conmy (arthur-conmy) · 2023-06-07T12:34:29.187Z · LW(p) · GW(p)
Oh huh - those eyes, webs and scales in Slide 43 of your work are really impressive, especially given the difficulty extending these methods to transformers. Is there any write-up of this work?
comment by redhatbluehat · 2023-03-16T14:25:40.405Z · LW(p) · GW(p)
Thank you for the post! Either to Neel, or to anyone else in the comments: what datasets have you found most useful for testing tiny image transformers?
The vit-pytorch repo uses the cats vs dogs repo from Kaggle but I'm wondering if this is too complex for the very simple image transformers.