Introducing REBUS: A Robust Evaluation Benchmark of Understanding Symbols
post by Arjun Panickssery (arjun-panickssery), agg (ag) · 2024-01-15T21:21:03.962Z · LW · GW · 0 commentsContents
No comments
This is a summary of https://arxiv.org/abs/2401.05604.
When Google announced Gemini Pro, they displayed its ability to solve rebuses—wordplay puzzles which involve creatively adding and subtracting letters from words derived from text and images.
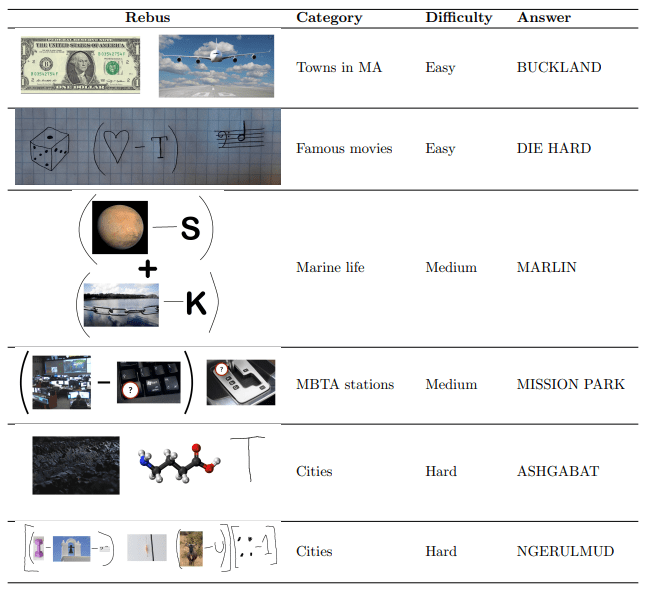
We introduce a new benchmark (Github) evaluating the performance of multimodal large language models on rebus puzzles. The dataset covers 333 original examples of image-based wordplay, cluing 13 categories like movies, composers, major cities, and food.
The REBUS dataset highlights several key challenges in multimodal language models:
- Multi-step visual reasoning—many rebuses contain information in a meaningful pattern, from which the necessary string operations and structure must be successfully inferred.
- Spelling—string manipulations require accurate letter-wise representations.
- Hypothesis testing—for instance, if the model recognizes a fictional-character-themed puzzle as containing images representing “Megachiroptera” and “Einstein,” it needs to revise its initial interpretations to reach the correct answer “Batman.”
- World knowledge—many puzzles contain crucial references and hints.
- Grounded image recognition—puzzles sometimes require identifying the most important part of an image, or recognizing what the image may represent as a whole, like understanding that a photograph of a group of lions might be cluing “lion,” “big cats,” “savanna,” or “pride.”
- Understanding human intent—solving the puzzles requires an understanding of what answers or reasoning steps could have been plausibly developed by the puzzle author.
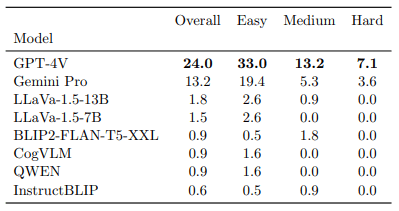
We find that the proprietary models GPT-4V and Gemini Pro significantly outperform all other tested models, but even they only achieve scores of 24% and 13.2%, respectively. Models rarely understand all parts of a puzzle, and they almost always fail to explain their correct answers with correct justifications.
0 comments
Comments sorted by top scores.