"model scores" is a questionable concept
post by Maxwell Peterson (maxwell-peterson) · 2020-11-06T03:19:45.196Z · LW · GW · 0 commentsContents
Calibrating the probabilities from a model None No comments
A couple of years ago, while I was working on a problem of what to do with the predictions of a random forest model, I noticed that the mean of the predictions on the test set didn't match the mean of the outcomes in the training data. Let me make that more concrete; consider the following problem (isomorphic to a problem I worked on in the past):
A town has two donut shops. The donut shops are in terrible competition, and the townspeople feel very strongly about the shops. It's, like, political. You run the good shop. Every year, 6% of people switch to your competitor. You are a data-driven company, and your kid needed something to do, so they've been sitting in the corner of the shop for years scribbling down information about each visitor and visit. So now you have a bunch of data on all your customers. "Did they come in that Monday 4 weeks ago? How about the Monday after that? How many donuts did they buy each month?" and so on. Representing "They switched to the other shop forever" as 1 and "that didn't happen" as 0, we have a label vector labels of 0's and 1's, grouped into, say, one data record and label per customer-year. We want to predict who might switch soon, so that we can try and prevent the switch.
So we put your kid's notes into some predictive model, train it, and make predictions on some other set of data not used in the training (call this the test set). Each prediction will take as input a data record that looks something like (Maxwell, Male, age 30, visited twice this year), and output a continuous prediction in the range (0, 1) for how likely Maxwell is to leave. You'll also have a label, 1 or 0, for whether Maxwell actually left. After doing these predictions on the test set, you can check how well your model is modeling by comparing the true labels to the predictions in various ways. One thing to check when figuring out how well you did: check that the average number of people predicted to leave your shop in past years is close to the number of people who actually left. If there are 100 people in the test set, and only 6 actually left in any given year, you should be unhappy to see a prediction vector where all the predictions look like [0.1, 0.9, 0.5, 0.8] (imagine this list is much longer with numbers on a similar scale), because the expected number of leavers from those probabilities is (0.1 + 0.9 + 0.2 + 0.8) / 4 = 2 / 4 = 0.5, or 50%. When only 6% actually left! The predictions are too high. This happens.
One way it can happen is when you artificially balance the classes in your training data. Artificial balancing is: your original data had 6% leaving, but you threw away a bunch of people who didn't leave, in order to obtain a training set where 50% of people left and 50% didn't. You can also do artificial balancing in a way that doesn't throw data away, by upsampling the rare 6% class instead of downsampling the common class. (I think balancing is wasteful and rarely or never necessary, but it's kind of a common thing to do.) Whether you up or down sample, the average prediction for whether someone will leave doesn't reflect reality - it's too high - leading to the 50% situation. Inputting balanced data has given the model bad information as to the base rate. Predictive modelers often may not mind this, because in their problems they are only interested in the order being correct. They want a relationshop like "if Kim is more likely than Sam to visit on Monday, I want Kim to be assigned model score higher than the one Sam is assigned" to be true, but beyond that don't care about the base probabilities. (Why you might only care about the ordering: say your strategy to keep a person likely to leave from leaving is to talk to them really nicely for 20 minutes every single time you see them, be it in the shop or on the street. You might decide you don't want to spend half your day being fake-nice to people, and resolve to only intervene in the top-5 most likely to leave. Then all you need from your model is "these are the top 5".)
So. I had a project, working with the output of someone else's classification model, isomorphic to the donut model. The input data had been balanced, and the probabilities had the undesired property of mean(predictions) >> mean(true labels). And I thought... Oh. The means are way off. This means models don't always output probabilities! They output something else. I started calling these output numbers "model scores", because they lacked the means-are-close property that I wanted. And for years, when people talked about the outputs of classification models and called them "probabilities", I would suggest calling them model scores instead, because the outputs weren't promised to satisfy this property. But I think I was off-base. Now I think that classifier outputs are still probabilities - they are just bad probabilities, that have the base rate way off. Being off on the base rate doesn't make something not a probability, though, any more than a biased sample or data issue turns probabilities into some separate type of thing. Bad probabilities are probabilities! You can apply the operations and reasoning of probability theory to them just the same.
I still think it's good to distinguish between 1) probabilities that are only good for relative ordering from 2) probabilities that are good for more than that, but saying that the former aren't probabilities was going too far. This is what I mean by "'model scores' is a questionable concept."
Calibrating the probabilities from a model
If your model's prediction probabilities have undesired properties, and re-training isn't an option... you can fix it! You can go from mean(predictions) = 50% to mean(predictions) = mean(true labels) = 6%. In my problem, I wanted to do this so that we could apply some decision theory stuff to it: Say it costs $10 to mail a person a great offer, that has some chance of keeping them around for the next year (out of appreciation). You expect the average retained person to spend $50 in a year. Consider a customer, Kim. Should you mail her a coupon? It might be worth it if Kim seems on the fence about the donut question - maybe you heard her talking about the other shop wistfully recently, and your prediction on her switching soon is high. Then $10 might be worth it, since you might be able to avoid the $50 loss. On the other hand, if Randall has been coming to your shop for 20 years and has zero interest in the other shop, that $10 probably doesn't make a difference either way, and would be a waste. Here, having well-calibrated probabilities, in the means-are-close sense, is important. If I think my customers are 50% likely to leave on average, I should freak out and mail everyone - I'm looking at a 50% * $50 loss per customer. But this isn't actually the situation, since we know just 6% of people leave each year.
The first thing I thought of, to solve my secret problem that I'm using the donut problem to represent, was a linear scaling: scale each model prediction by , where is the mean of the true labels (the 6%). This makes the mean equal to , but it smushes everything toward 0. We go from the original distribution of probabilities :
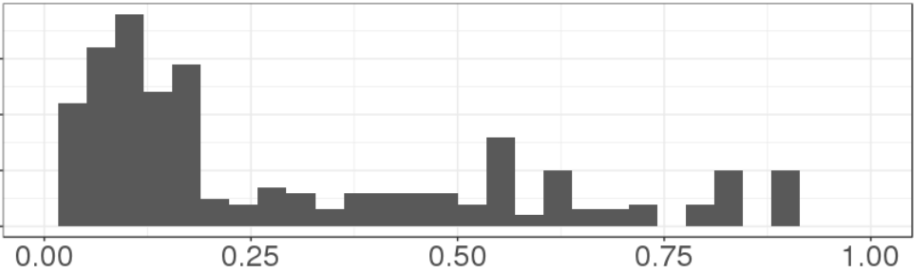
to this scaled distribution:
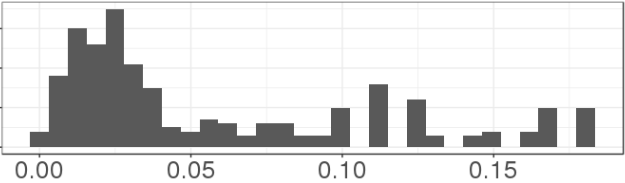
It looks the same, but the range has been compressed - there are no predictions above 0.21 now. If you zoom out to the full range (0, 1), the latter picture looks like this:
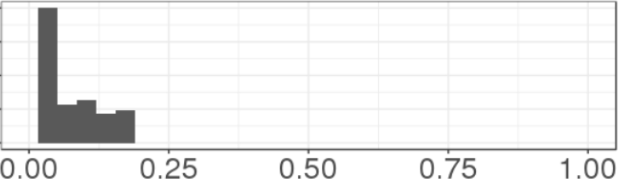
The means are equal now. But what sucks about this is: what if there is someone with a prediction of 0.90? They'll show up here as having a 0.20 probability of leaving. 90% of $50 is $45, so you expect to make net $35 from sending the coupon. But if you use the after-linear-scaling prediction of 20%, 0.2 * $50 - $10 gives an expected gain of $0, so you might not bother. Smushing predictions toward 0 will screw up our coupon calculations.
There are actually many ways to change the distribution of s into some distribution of , where mean() = . In some cases you can use the inner workings of your model directly, like in this explanation of how to change your priors in a trained logistic regression. What I ended up doing in my problem was some sort of ad-hoc exponential scaling, raising the s to whatever power x made mean() = . I don't remember all my reasons for doing this - I remember it at least avoiding the smush-everything-left behavior of the linear scaling - but overall I don't think it was very well-founded.
I think the right thing to do, if you can't retrain the model to do it without balancing, is to write down the qualitative and quantitative conditions you want, as math formulas, and find the scaling function that satisfies them (if it exists). Like, if I want scores above 0.9 to stay above 0.9, and for the mean to equal , then I have two constraints. These two constraints narrow down the large space of scaling functions. A third constraint narrows it down more, and so on, until you either find a unique family of functions that fits your requirements, or find that there is no such function. In the latter case you can relax some of your requirements. My point here is that you have some ideas in your head of the behavior you want: say you know some people really want to leave - you overheard a very bitter conversation about the change to the bavarians, but you don't know who was talking. You've overheard a few bitter conversations like this every year for the past decade. To represent this, you could write down a constraint like "at least 5% of predictions should be assigned 0.9+". Writing down constraints like this in a real problem is probably hard, and I haven't done it before, but I hope to write a post about doing it, in the future.
0 comments
Comments sorted by top scores.