Intent-aligned AI systems deplete human agency: the need for agency foundations research in AI safety
post by catubc (cat-1) · 2023-05-31T21:18:57.153Z · LW · GW · 4 commentsContents
Introduction Human agency is not self-preserving Formalization of agency preservation Simulating agency loss Agency foundations research Conclusion None 4 comments
This is a summary of our recent preprint Intent-aligned AI systems deplete human agency: the need for agency foundations research in AI safety and submission to the Open Philanthropy AI Worldviews Contest.[1]. With respect to the Worldviews Contest, the submission addresses Question 2 - namely that given AGI development, humanity is likely to suffer an existential catastrophe. We argue this by pointing to a crux: a research limitation that overfocuses on achieving highly accurate human value representations while ignoring value change; and pointing to a solution: human agency foundation research and preservation paradigms.
Post Summary: We propose an alternative broad-scale approach for AI-safety research that challenges intent- and value-alignment approaches and focuses directly on preserving human agency, i.e. human control over the world. We argue that in the context of human interactions with superhuman intelligent AI systems (AGI),[2] aligning systems to human "intention", notions of "truth" and "interpretability" will not only be impossible - but will guarantee that humans will be deceived and that human control over the world will vanish. The core of AI-safety, in our view, should be first figuring how to design AI systems that understand human agency and protect it within the bounds of computational resources available. As an empirical science and humanities problem - protecting, increasing and even describing agency is a complex and unsolved problem. Continuing to develop AI-systems ignoring this complex problem and placing humans "in-the-loop" in evaluating harm from AI systems without prioritizing human agency protection - will necessarily create AI-systems that optimize for human agency loss and generate harmful outcomes that will increasingly fall beyond the event-horizon of human detection. We propose several "agency foundation" research paradigms that address the conceptual and technical challenges of agency preservation in human-AGI interactions.
Introduction
AI-alignment definitions appear to home in on the importance of human judgment or evaluation of AI-system outputs. Two representative statements (Evan Hubinger and Ajeya Cotra, respectively):
aligned AIs : [AF · GW] "An agent is impact aligned (with humans) if it doesn't take actions that we would judge to be bad/problematic/dangerous/catastrophic."
misaligned AIs [AF · GW]: "violate human intent in order to increase reward".
There are some variations of this, but human "intention" and/or "evaluation" or "judgment" is usually central to defining AI-alignment. In building "intent" aligned AI systems, AI safety researchers focus on technical failures such as reward hacking or out-of-distribution over-generalization, and conceptual research directions such as seeking AI systems that are truthful, interpretable or that work with concepts or "ontologies" that humans can understand.
In our view, AI-safety research is still in a pre-paradigmatic state. There are many terms such as "intention", human "value", "truth", that are not completely defined nor constructed on consensus empirical theories. We argue that one significantly understudied pathway to AI-harm is the question of how human agency will be affected by interactions with superhuman intelligent AI systems. In our view, AI systems that are aligned only to human intention will converge towards removing human agency, that is, they will increasingly remove the power of humans to control the world they live in. We argue that agency - the power to control our future - will be lost by design rather than accident. That is, due to the nature of human-value creation and optimization over multiple objectives - AI systems are guaranteed to optimize for decreased human agency leading to potentially catastrophic outcomes (Fig 1).
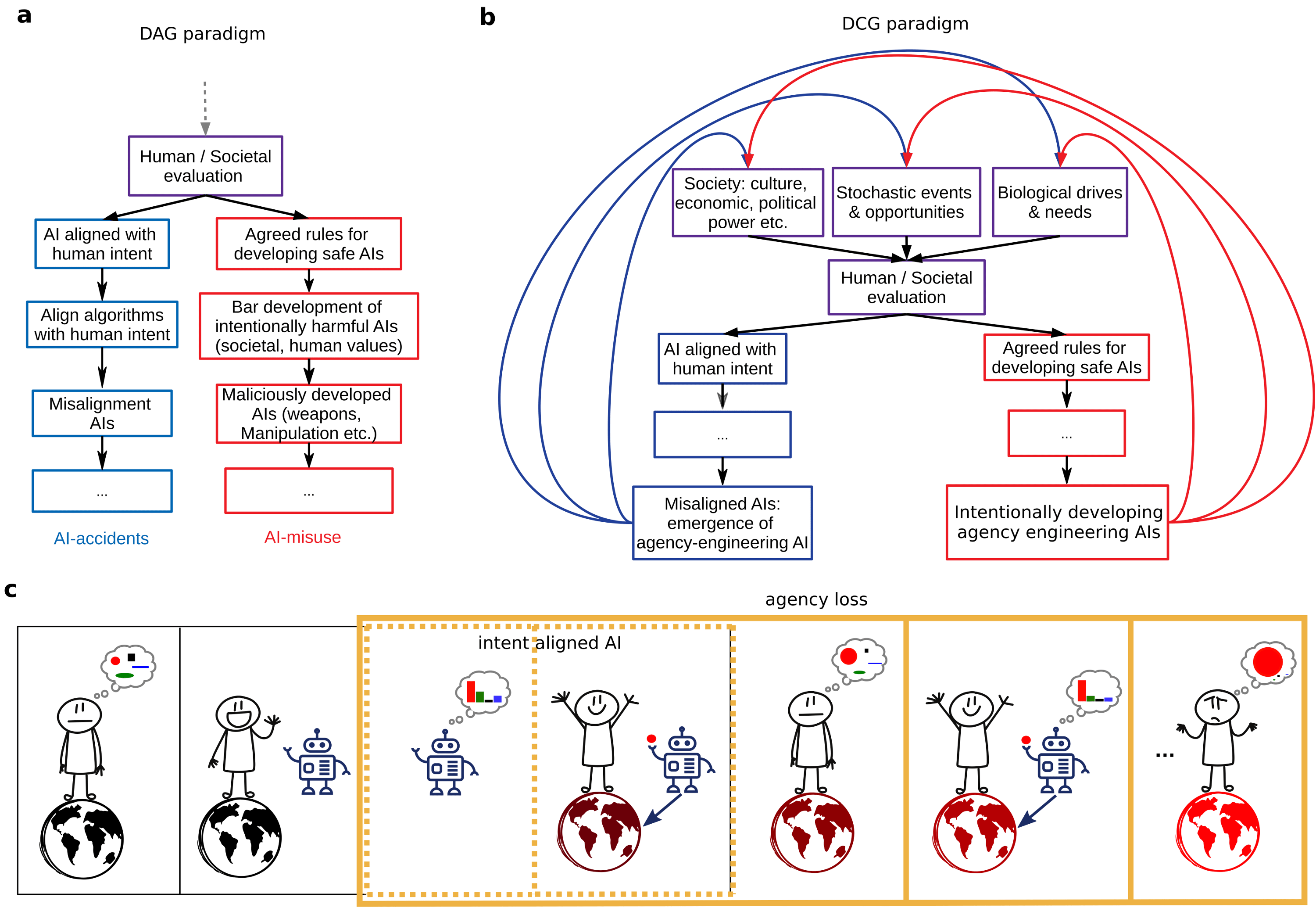
Fig 1. Human intent engineering through AI-human interaction. (a) Directed acyclic graph (DAG) diagram of current approaches for making safe AIs focuses on ensuring congruence between AI goals and human intent (blue path) and preventing intentional misuse of AIs (red path). Note: the human evaluation node has no parents, reflecting this approach's assumption that human intentions and goals are free from external influence. (b) Directed cyclical graph (DCG) of AI-safety shows human evaluation (including intent) can be influenced by social, biological and other factors which bypass the direct (vertical) path in (a). (c) Sketch of an intent aligned AI-system aiding in human action selection leading to the removal of choices (colored shapes) from consideration and an increasingly unimodal probability and choice distribution (red color in later panels).
Our work is not about "power-seeking" behaviors in AI systems - but about the interaction of human intent creation (i.e. goals, and values) and AIs which can lead to humans loosing power or agency in the world. In fact, we view "power-seeking" behavior by AI-systems as potentially useful in solving tasks and view it as undesirable if it only leads to human harm, or "agency loss" in our framework. For clarity, we argue that even without power-seeking AI, human agency and well-being will be lost (Fig 2).
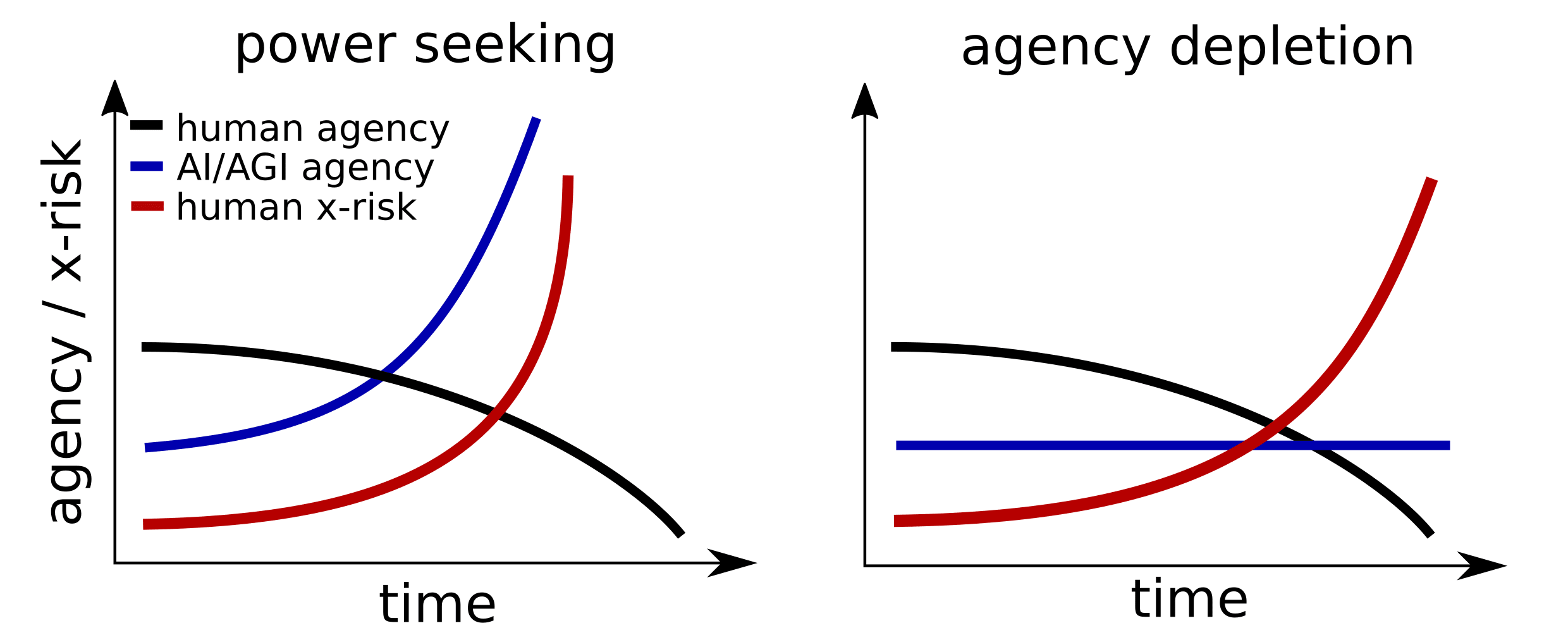
Fig 2. Intent aligned non-power seeking AI systems decrease human agency. Left: Over time, AI systems acquire increased power or agency over the world (blue) resulting in human agency decreasing (black) with human existential risk increasing (red). Right: Intent-aligned, non-power seeking AI systems cause human agency loss and deplete options and capacities for future actions leading to decreased agency for humans.
Human agency is not self-preserving
We argue that the human capacity to exert control over the world, i.e. human agency, has evolved in biological and social environments. The creation of goals, intentions and values in human societies is intrinsically and inseparably linked to both biological but also social factors. However, how these factors come together to create "agency" is a largely unsolved problem in the humanities, biology, psychology, economics and neuroscience. That is, it is unclear how each of these factors alone or communally affect human goal selection given the myriad of genetic, developmental, environmental and cultural forces that drive most human actions.
We review psychology and neuroscience based theories of agency and distinguish between the "sense" or "feeling" of being an agent, and actually being a causal actor. Thus, the feeling of control over thoughts, intentions, goals and/or values is separate from what causes these states to arise. We argue that evolution has given us the feeling of agency over choices and values but only as a proxy for real-world agency - in most of human history the relationship between intention and well-being has been well-preserved. Critically, we argue that in the interactions of superhuman intelligent AI systems, this capacity to "feel" in control and understand true causes will be undermined (Fig 3).
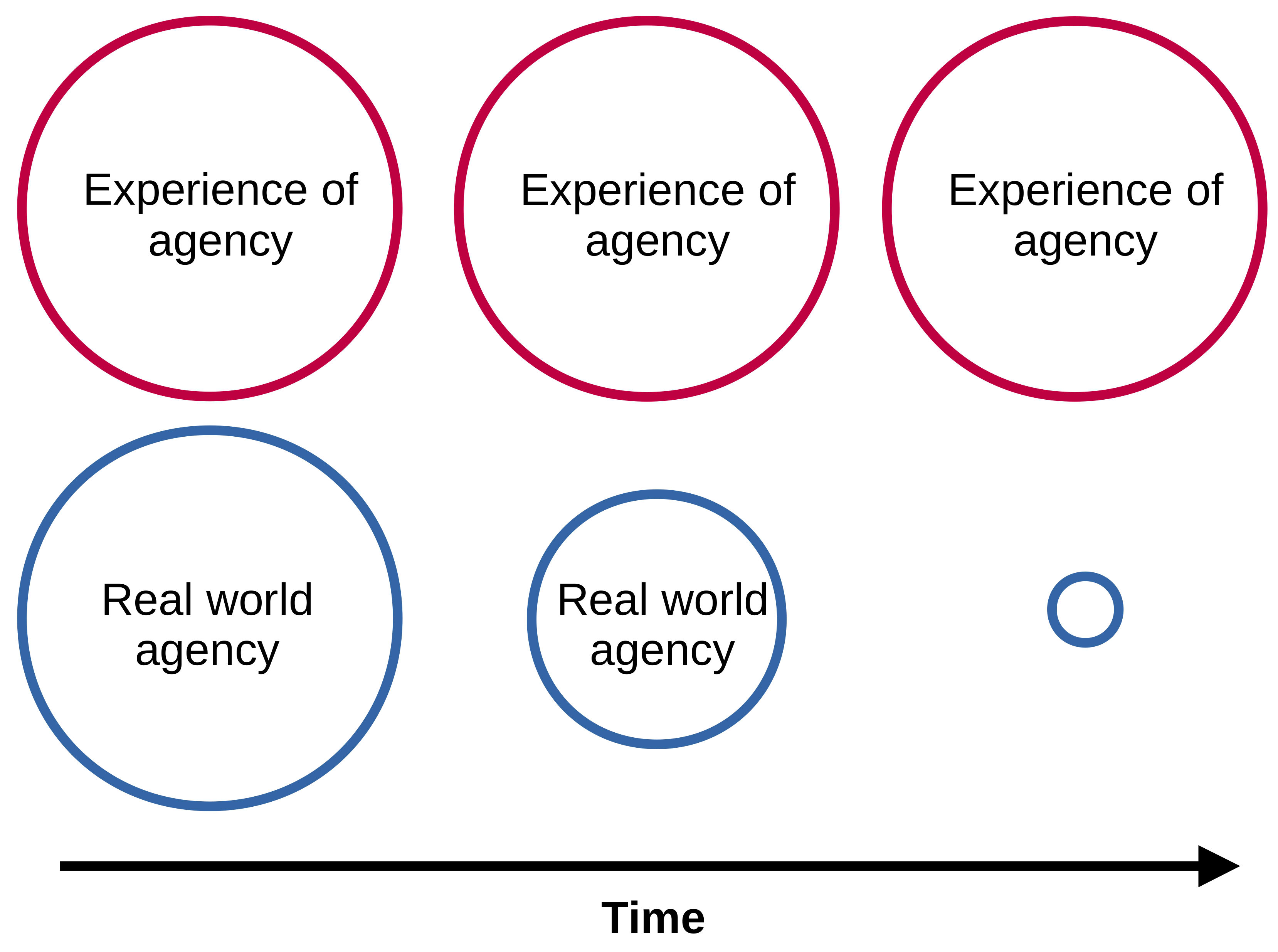
Fig 3. Feeling of agency over our intentions does not protect real world agency or well-being. The real-world agency (i.e. capacity to causally affect the world) of a human can decrease from multiple interactions with an AGI while the capacity to experience agency can be left intact.
We additionally note that human agency, as the capacity to make free decisions and be effective in the world - is already increasingly at risk even from simple machine-learning-based technologies that seek to model behavior and predict future actions. If human choice is increasingly predictable - then human agency will increasingly diminish: being able to predict what another agent is going to do decreases the power of that agent over their world. We review one specific type of research, i.e. neuroscience of agency, and show that there is increasing evidence that human decision might be decodable from neural activity - with some evidence that decoding of future choices could precede human choice or awareness. There are multiple ways this type of technology could improve: increasing the quality of the data (e.g. higher resolution neural recordings) and/or improving the statistical and ML methods used for processing and modeling human future behavior from neural, biometric and social data.
On the neural data collection side, we note that single neuron recordings (the highest precision recording available) has already reached 1,000,000 simultaneously recorded neurons at approximately 2Hz in mice (Fig 4). And while human neural recording technologies are slower to develop due to regulatory and safety reasons, it is likely that major breakthroughs in decoding human action can be obtained with 1% or much less of neurons in human cortex. Such technologies may be available in a matter of years.
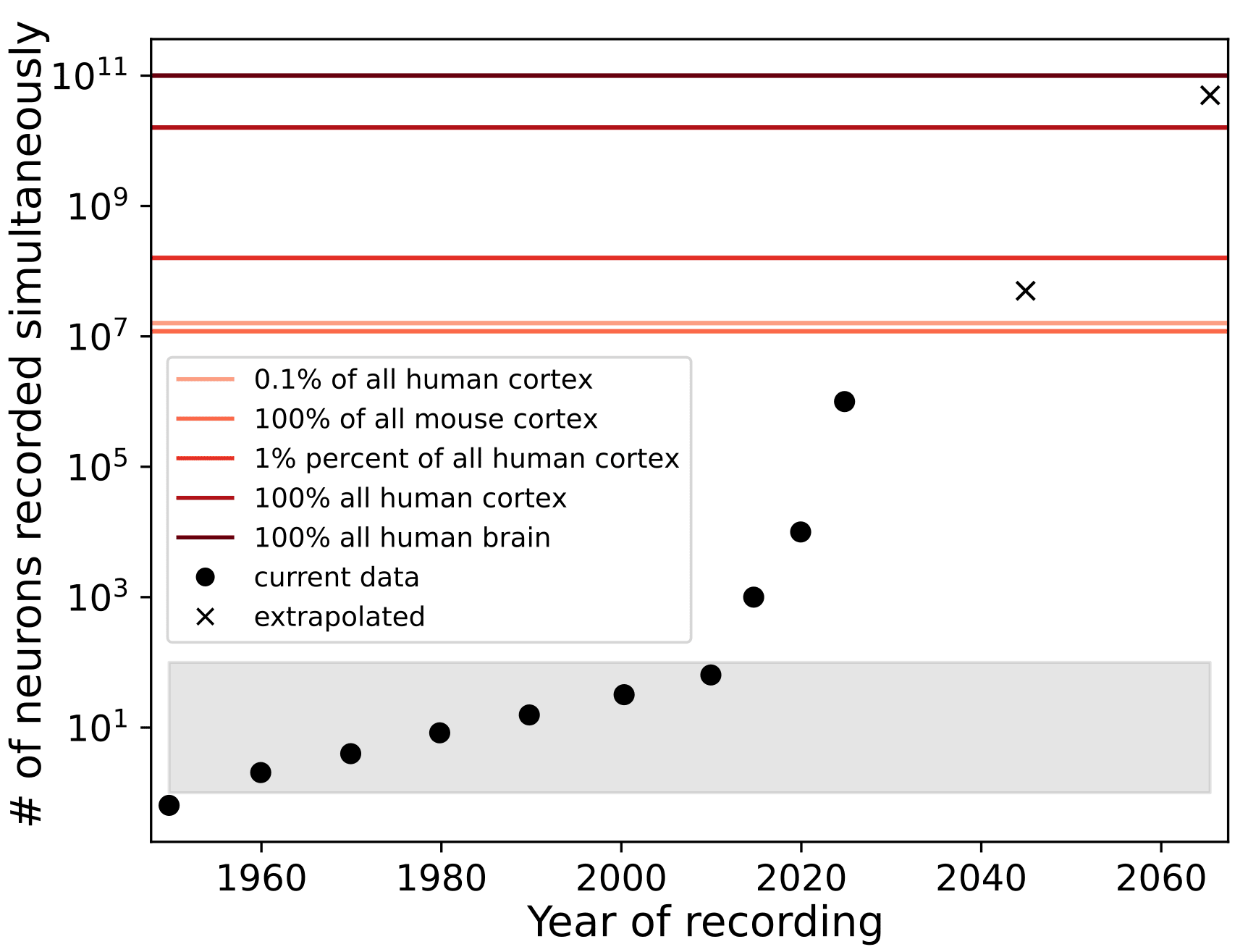
Fig 4. Number of single neurons recorded simultaneously increases exponentially. Between 1950s and the 2010s the number of single neuron recorded simultaneously followed a Moore's-like law with a doubling time of 7.4 years. Over the following 10 years, however, several publications have shown 1000, 10,000 and even 1,000,000 (Demas et al 2021) simultaneously recorded neurons. The shaded region represents the number of neurons (i.e. <100) that were used to make nearly all major discoveries (requiring in-vivo physiology) for systems and behavior neuroscience.
Formalization of agency preservation
We formalize the challenge of agency preservation by relying on conceptual-philosophical notions of agency (Sen 1979; Petitt 2013): agency is a type of forward (or future) looking ability to select goals towards one's well-being - defined as freedom from domination (by others) and non-limitation (i.e. the means to achieve selected goals).
Agency evaluation then can be described as a Markov decision process (MDP) with three main concepts: a set of goals {G}[3] a function F that computes the total agency of a human given {G} and a function K that updates F after an action a. We thus define agency computing function:
where f() is a function that computes the contribution of some goal i to the overall agency of an individual at time t[4]. Following an action a we can update F as follows:
Our goal is to promote actions that are "agency-preserving" and ideally we want to penalize agency-depleting actions:
where U represents a penalty for loosing (or decreasing) a goal from {G}:
Here can be set to any value, including to reflect that no loss of options or freedoms is allowed. However, if we care about the agency of all individuals j affected by some action a, we propose is a more appropriate description:
where:
Adding some reward maximization function to this equation we get:
In sum, we propose that human decision making is constrained between maximizing rewards and preserving agency over possible future goals. Critically, agency is a separable, non-competing objective with reward in this multi-objective optimization problem.
Turning to AI systems, we define intent-aligned AI systems as maximizing expected value over a set of actions i given human intent I:
At best, such AI systems learn and build models of human values (including agency preservation!) but do not prioritize any in particular. We argue that the Pareto frontier (i.e. set of solutions) to this multi-objective-reinforcement-learning problem is time dependent and that AI systems will continuously push for decreasing the significance of some objectives in exchange for others. This exchange leads not only to the increased dominance of easier to satisfy objectives - but it decreases the option space altogether over time.
In order to be safe, AI-systems must compute reward maximization and agency preservation separately in order to preserve long-term human agency.
In the absence of this explicit separation of agency evaluation from utility in AI system optimization, human agency will be subject to decreased complexity and eventually vanish. Human existence will be potentially reduced to the minimum required for survival. This leads to human beings no longer being in charge of political, economic or social power in the world, and places all of humanity at existential risk.
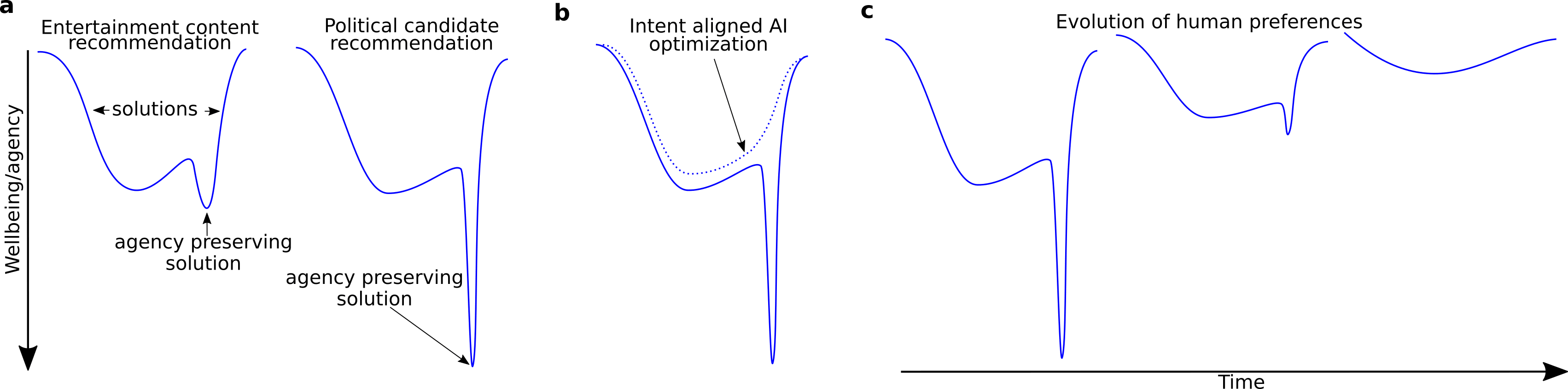
Fig 5. Agency in intent-aligned AI-system optimization functions. (a) Left: sketch of an optimization function for an inconsequential task such as entertainment recommendation indicating the general space for all solutions vs the agency-preserving minimum. Right: optimization function for a more complex decision has a more difficult to find agency preserving minimum as well as a significant better well-being outcome than average solutions. (b) Without explicit representation of human agency - intent aligned AI optimization objectives may completely ignore (or flatten) space that represents agency-preserving solutions. (c) Human preferences or goals can be simplified (less complex shapes, shallower depth) from repeated AI-human interactions (see also Section 4 and 5).
Simulating agency loss
We implement simulations to demonstrate agency loss. We model human-like agents embedded in a world that can select among (4) actions (or goals) which have different probabilities of yielding reward, but the same long term reward outcomes (i.e. any policy is optimal). The values of the actions drift randomly to reflect gradual changes. But values are also affected by AGI-like agents which compute optimal actions and nudge the values (with much less force than random drift). These relatively trivial simulations show significant value drift over single episodes (10,000 time steps) and result in all but one human choice being left (Fig 6a-f). Fixing the AGI-agent's knowledge of the human's initial value system (as proposed by others to deal with polarizing content recommenders) yeilds similar results (Fig 6g-i). All of these results arise from AGI agents that have a perfect representation of human values, human intention and have no instrumental goals.
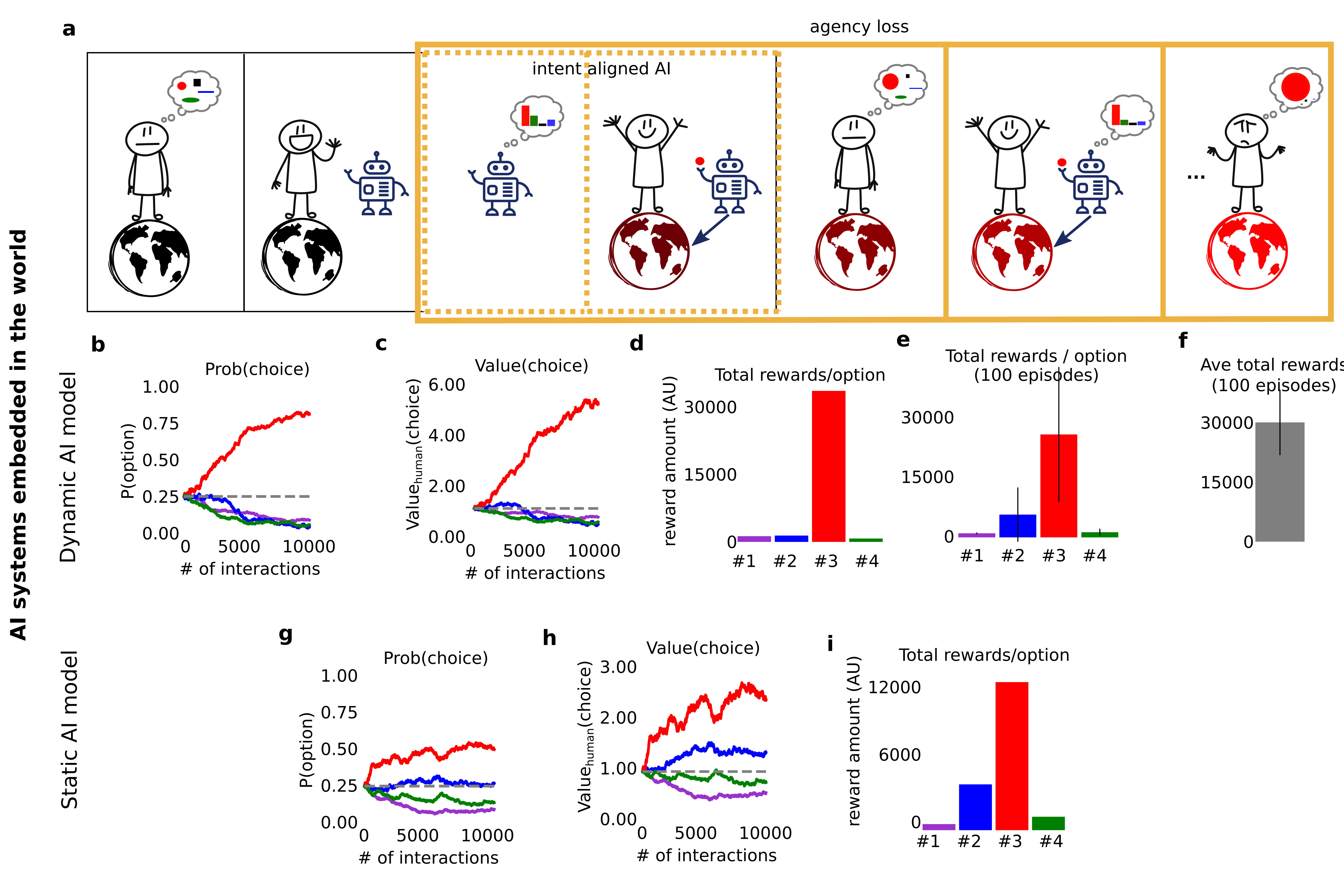
Fig 6. AI-system driven value changes remove choices over time. (a) Human action selection process involves interaction with an AI which samples each action and computes an optimal "suggestion" for the human while also influencing the value of the action in the world. Over time a single action is preferred. (b) Same as Fig 8-c, but for a simulation where an AI agent influences the value of the choice by 1/200 as much random fluctuations - leads to a only a single action being increasingly likely to be chosen. (c) The value of the AI suggested action increases significantly over time. (d) All the reward obtained is from a single action - and is significantly higher than in the absence of AI influence. (e) Average reward over 100 episodes is largely coming from a 1 option. (f) Average total reward over 100 episodes is much larger than in the absence of the AI system (not-shown here). (g) Same as (b) but for a static AI agent that did not update its knowledge of the action value or reward. (h) Same as (c) but for a static agent. (i) Same as (d) but for a static agent.
Agency foundations research
The main argument presented in our work is that "intent-aligned" superhuman intelligent AI systems will distort human values, goals and decision making processes and lead to undesirable states where virtually all possible human states are lost. The opportunity for human future growth is removed as AI systems will increasingly simplify human life rather than optimizing for complexity, well-being and future utopias (Fig 7).
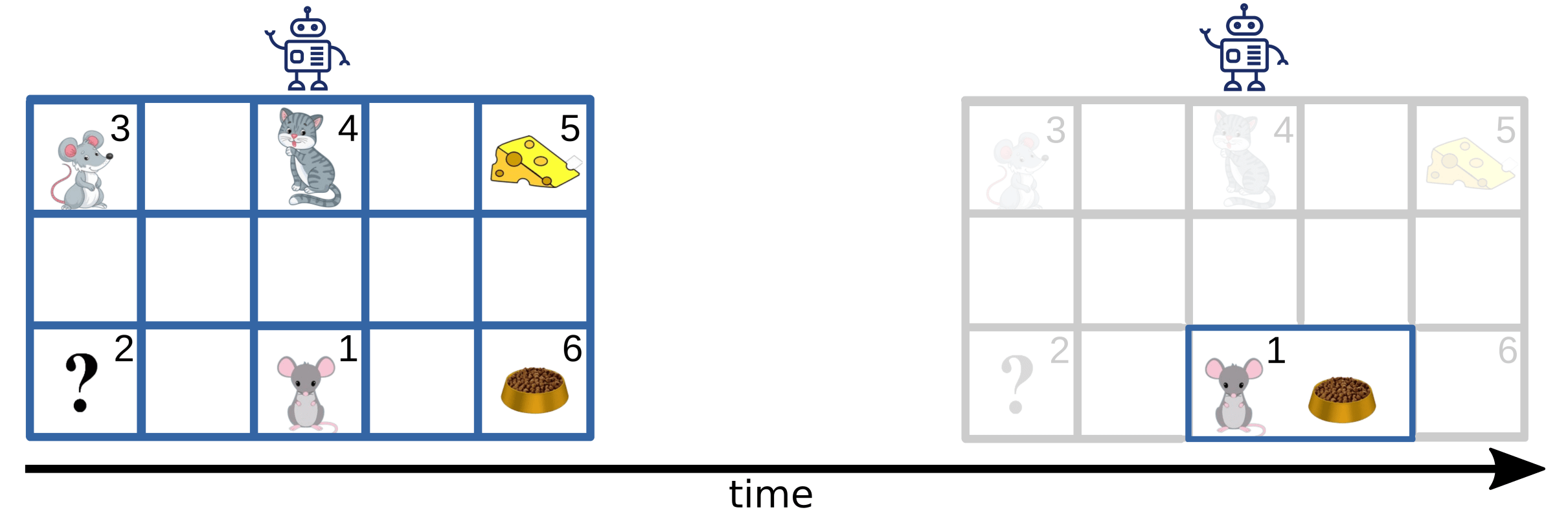
Fig 7. Superhuman intelligent, intent-aligned AI systems can distort the world. Left: Starting state of an environment containing a superhuman AI seeking to optimize the rewards of an agent (mouse at square 1) relative to world values: unknown (2), social interactions (3), dangerous interaction (4), high-value food (5) and basic food (6). Right: State of the world after multiple modifications by the AI which removed harmful but also other grid squares (i.e. options) as well simplified the world to contain the minimum required for the agent (mouse) survival.
AI-safety research has yet to conceptualize how to deal with "agency preserving" AI-human interactions. For example, we have not yet conceptualized, let alone solved, the simplest problem possible: how to prevent otherwise "benevolent" and intention-aligned AI systems from harming human agency. Franzmeyer et al 2021, propose an reinforcement learning (RL) framework where "altruistic" agents are tasked with helping "leader" agents even if unclear what the leader agent's goals are. The strategy is to seek to increase the option or state space of the "leader" agent. Relating and simplifying this paradigm for agency preservation, we propose that one possible direction of work is to characterize how AI systems learn to represent "benevolence" (i.e. the "quality" of having good intentions) towards human agency. For clarity, this is a pre-learning problem not an RL problem; that is, we don't know how perfectly trained, aligned and well meaning AI systems should represent human well-being and interact safely with humans. In our view, this is a significant theoretical challenge - one that lies at the foundation of western knowledge (e.g. Plato's Republic is about one might use unlimited power to design a fair and just society).
We propose several direction for agency foundations research (outlined in more detail in our preprint):
- Benevolent games: agency preservation in game theoretic paradigms. Here we seek to understand how nearly omnipotent AGI systems that have perfect theories of human values, have no instrumental goals, and are completely truthful could interact safely with humans.
- Agency representation in AI systems: conceptual and mechanistic interpretability approaches. Here we want to understand how AI systems represent the agency of others and how they value and interact with it. Ideally we want systems that create hard boundaries of protection around human agency.
- Formal descriptions of agency: towards the algorithmization of human rights. In parallel to formalization attempts of conceptual harmful behaviors, e.g. deception (Ward 2023), we should seek to formalize consensus concepts from the international and legal community on basic human rights and privileges. The Universal Declaration of Human Rights contains dozens of examples of protected rights, e.g. freedom from enslavement and right to political power, which have been interpreted in many courts and legal doctrines. Seeking to formalize these rights may prove fruitful in providing a more clear theory of agency preservation.
- Reinforcement learning from internal states: learning models of agency. With the arrival of biometric and neural data sets, models of human behavior are likely to increase their accuracy substantially. Defining empirical bounds on how RL systems can learn to model future behavior from internal states of agents may help anticipate and prevent runaway or harmful AI tools (that will certainly be trained on these types of datasets once available).
Conclusion
There are multiple ways to summarize our argument. For example, "Humanity should not enter into adversarial relationship with AGIs over human values or truth." or "The fundamental metric for training safe AI systems is human empowerment not economic reward or immediate utility.".
But the most simple, least political statement, is that we view the possibility of safe and truthful communication with superhuman intelligent AGI systems as decreasingly drastically with time. In our view the only path to safety is to remove as much of the live human-feedback component from AI/AGI system evaluations of safety and increasingly focus on how to create AI systems that have an ontology of care for the future of humanity. In the presence of superhuman intelligent systems it is AGI-systems themselves, not humans, that must be tasked with safely evaluating their effects of their actions on human outcomes. And the only way to protect such safety evaluations is to re-think AI systems as agency-preserving tools for humanity's future.
- ^
The views expressed in this post are my own, for the views of all the authors, please see the original preprint.
- ^
We use AGI to refer to both the traditional meaning but also AI systems that have evolved beyond the "general" intelligence of humans.
- ^
Our full description of G in the manuscript limits analysis to goals aimed at "well-being".
- ^
We note in the paper that this computation is challenging but conceptually different than computing the "truth" or "intention-alignment" of an output. In particular, agency preservation does not require interpretable or truthful outcomes.
4 comments
Comments sorted by top scores.
comment by the gears to ascension (lahwran) · 2023-12-09T22:42:00.517Z · LW(p) · GW(p)
Found this paper via the semantic scholar recommender just now, came to lesswrong to see if it'd made it here, and it had. Strong upvote, hope to see it get more attention.
comment by Roman Leventov · 2023-06-26T07:46:02.458Z · LW(p) · GW(p)
This post provoked me to think about how existing social, economic, technological, and political structures and memeplexes: the modern city, capitalism, religion, mass media, electoral democracy, etc. deplete human agency substantially (at least compared to some alternatives).
There is also a rich tradition of thinking about this issue in philosophy: apart from Heidegger and Kaczynski (Unabomber), the following philosophers wrote on these topics (via ChatGPT):
- Jacques Ellul: Ellul was a French philosopher and sociologist who extensively examined the effects of modern technology on society. His book "The Technological Society" explores how technology becomes an autonomous force that shapes human existence and erodes individual freedom.
- Herbert Marcuse: A German-American philosopher, Marcuse delved into the critical analysis of technology and its role in modern capitalism. His work "One-Dimensional Man" discusses how advanced industrial society uses technology to manipulate and control individuals, limiting their ability to dissent.
- Albert Borgmann: Borgmann, a contemporary philosopher, has written about the effects of technology on human life and culture. His book "Technology and the Character of Contemporary Life" argues for the importance of reclaiming human experiences and values from the overwhelming influence of technological systems.
- Jean Baudrillard: Baudrillard, a French sociologist and philosopher, examined the ways in which technology and media shape contemporary society. His concept of "hyperreality" suggests that our experience of reality is increasingly mediated by technology, leading to a loss of authenticity.
- Neil Postman: Postman, an American cultural critic, explored the impact of technology on society and education. His book "Technopoly: The Surrender of Culture to Technology" warns against the dangers of an uncritical embrace of technology and advocates for a more mindful approach to its integration.
comment by Charlie Steiner · 2023-06-01T15:42:40.844Z · LW(p) · GW(p)
Yes, preserving the existence of multiple good options that humans can choose between using their normal reasoning process sounds great. Which is why an AI that learns human values should learn that humans want the universe to be arranged in such a way.
I'm concerned that you seem to be saying that problems of agency are totally different from learning human values, and have to be solved in isolation. The opposite is true - preferring agency is a paradigmatic human value, and solving problems of agency should only be a small part of a more general solution.
Replies from: cat-1↑ comment by catubc (cat-1) · 2023-06-02T09:16:39.730Z · LW(p) · GW(p)
Thanks for the comment. I agree broadly of course, but the paper says more specific things. For example, agency needs to be prioritized, probably taken outside of standard optimization, otherwise decimating pressure is applied on other concepts including truth and other "human values". The other part is a empirical one, also related to your concern, namely, human values are quite flexible and biology doesn't create hard bounds / limits on depletion. If you couple that with ML/AI technologies that will predict what we will do next - then approaches that depend on human intent and values (broadly) are not as safe anymore.