Announcing Atlas Computing
post by miyazono · 2024-04-11T15:56:31.241Z · LW · GW · 4 commentsContents
Our overall strategy Specification-based AI vs other AI risk mitigation strategies How this differs from davidad’s work at ARIA Our plan Why a nonprofit? How to engage with us None 4 comments
Atlas Computing is a new nonprofit working to collaboratively advance AI capabilities that are asymmetrically risk-reducing. Our work consists of building scoped prototypes and creating an ecosystem around @davidad [LW · GW]’s Safeguarded AI programme at ARIA (formerly referred to as the Open Agency Architecture).
We formed in Oct 2023, and raised nearly $1M, primarily from the Survival and Flourishing Fund and Protocol Labs. We have no physical office, and are currently only Evan Miyazono (CEO) and Daniel Windham (software lead), but over the coming months and years, we hope to create compelling evidence that:
- The Safeguarded AI research agenda includes both research and engineering projects where breakthroughs or tools can incrementally reduce AI risks.
- If Atlas Computing makes only partial progress toward building safeguarded AI, we’ll likely have put tools into the world that are useful for accelerating human oversight and review of AI outputs, asymmetrically favoring risk reduction.
- When davidad’s ARIA program concludes, the work of Atlas Computing will have parallelized solving some tech transfer challenges, magnifying the impact of any technologies he develops.
Our overall strategy
We think that, in addition to encoding human values into AI systems, a very complementary way to dramatically reduce AI risk is to create external safeguards that limit AI outputs. Users (individuals, groups, or institutions) should have tools to create specifications that list baseline safety requirements (if not full desiderata for AI system outputs) and also interrogate those specifications with non-learned tools. A separate system should then use the specification to generate candidate solutions along with evidence that the proposed solution satisfies the spec. This evidence can then be reviewed automatically for adherence to the specified safety properties. This is by comparison to current user interactions with today’s generalist ML systems, where all candidate solutions are at best reviewed manually. We hope to facilitate a paradigm where the least safe user's interactions with AI looks like:
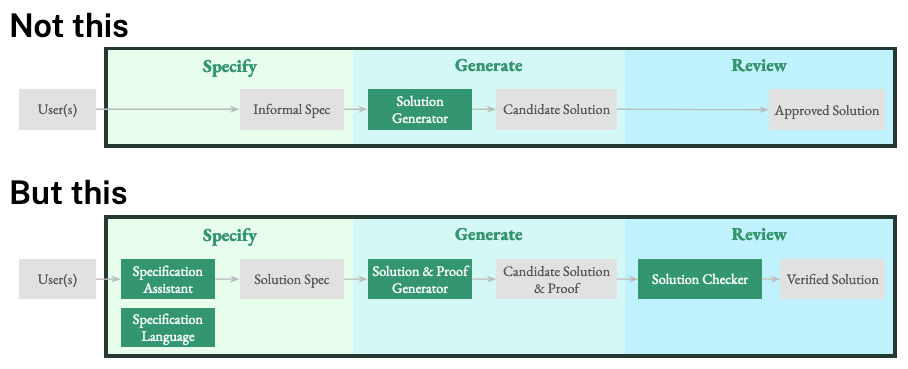
Specification-based AI vs other AI risk mitigation strategies
We consider near-term risk reductions that are possible with this architecture to be highly compatible with existing alignment techniques.
- In Constitutional AI, humans are legislators but laws are sufficiently nuanced and subjective that they require a language model to act as a scalable executive and judiciary. Using specifications to establish an objective preliminary safety baseline that is automatically validated by a non-learned system could be considered a variation or subset of Constitutional AI.
- Some work on evaluations focuses on finding metrics that demonstrate safety or alignment of outputs. Our architecture expresses goals in terms of states of a world-model that is used to understand the impact of policies proposed by the AI, and would be excited to see and supportive of evals researchers exploring work in this direction.
- This approach could also be considered a form of scalable oversight, where a baseline set of safe specifications are automatically enforced via validation and proof generation against a spec.
How this differs from davidad’s work at ARIA
You may be aware that davidad is funding similar work as a Programme Director at ARIA (watch his 30 minute solicitation presentation here). It’s worth clarifying that, while davidad and Evan worked closely at Protocol Labs, davidad is not an employee of Atlas Computing, and Atlas has received no funding from ARIA. That said, we’re pursuing highly complementary paths in our hopes to reduce AI risk.
His Safeguarded AI research agenda, described here, is focused on using cyberphysical systems, like the UK electrical grid, as a venue for answering foundational questions about the use of specifications, models, and verification to prevent AGI and ASI risk.
Atlas Computing is identifying opportunities for asymmetrically risk-reducing tools using davidad's architecture, and doing (and also supporting external) tech transfer, prototyping, and product development. These tools should be possible without incorporating progress from davidad's program, but should generate solutions to UX, tech transfer, and user acquisition problems that davidad's outputs may benefit from.
As an example, imagine we've prototyped useful tools and partnered with a frontier lab to provide this tool as a services to government departments at scale; they're now using a Safeguarded AI architecture based on narrow AI tools to make specific review systems more efficient and robust. In this scenario, convincing service providers, funders, and users to adopt the outputs of davidad's completed program should be much faster and easier.
Our plan
We are initially pursuing projects in two domains, each targeting a major risk area for this architecture.
Using AI to scale formal methods If we are to specify safety properties about states of the world, we must first radically simplify use of existing specification languages. To demonstrate this, we intend to match-make talent and funding to build AI-accelerated tools to elicit and formalize specifications (from either legacy code or natural language) and then perform program and proof synthesis from the specification. See our nontechnical 2-pager on AI and formal verification for more motivation. We’re working with the Topos Institute to define the first set of engineering and research problems in this domain - stay tuned!
Designing a new spec language for biochemistry: In the realm of biochemistry, we hope to organize a competition analogous to CASP, except focused on toxicity forecasting. We believe that it’s important to show that a useful, objective specification language can be built that describes physical systems, and we believe that a list of bioactivity parameters could serve that purpose. See our 2-page proposal for this toxicity forecasting competition for more.
Once we've made significant progress on these two directions (likely creating one or more teams to pursue each of these as either FROs or independent start-ups), we'll start identifying the next best ways to apply our architecture to asymmetrically reduce risks.
Why a nonprofit?
If it turns out that this architecture is the best way to address AI risk, then IP and support should be readily available to anyone who wants to use it, as long as they’re following the best practices for safety measures. This doesn’t preclude us from helping form or incubate for-profits to access more capital, as we intend to build valuable products, but it does require that we support any potential partner interested in using this architecture.
We hope to empower human review at all scales. Current AI architectures seem to favor generating potential changes to systems, whereas having a model and a specification favors understanding systems and the impact of potential changes first, which we believe is strictly better. We also believe this path to reducing AI risks is broadly appealing, even to accelerationists because efficient and transparent automation of regulation can reduce the burden imposed by regulators.
How to engage with us
Read more
- See our pitch-deck-style summary slides.
- Read our nontechnical 2-page executive summary.
- Sign up for our (~quarterly) updates email list, our ~weekly blog
- Follow us on Twitter or LinkedIn
- Check out our executive summary of davidad’s program (which was updated today and includes a funding opportunity of £59M over 4 years)
- or watch his 30 minute solicitation presentation
You can apply to join Atlas! We’re hiring:
- A FM+AI researcher (a "research director" who's experienced leading teams and applying for funding or a "research lead" who can grow into a director)
- A FM product lead who can improve our understanding and pursuit of what tools need to be built to scale formal methods
- A COO who can lead process improvements and drive growth in our impact, our ecosystem, and our team.
- We’re also looking for experienced and highly engaged board members who can help source funding and provide strategic input
Chat with us
- You can come join the conversations about guaranteed-safe AI at this community email group.
- Book time with Evan’s calendly: https://calendly.com/miyazono/
- Evan will also be very active in the comments here for at least the next week (and maybe less responsive after that)
4 comments
Comments sorted by top scores.
comment by Quinn (quinn-dougherty) · 2024-04-11T17:17:57.690Z · LW(p) · GW(p)
firefox is giving me a currently broken redirect on https://atlascomputing.org/safeguarded-ai-summary.pdf
Replies from: gwern, daniel-windham, miyazono↑ comment by gwern · 2024-04-11T23:21:29.467Z · LW(p) · GW(p)
Browsers usually cache redirects, unfortunately, which means that if you ever screw up a redirect, your browser will keep doing it even after you fix it, and force-refresh doesn't affect it (because it's not the final loaded page that is broken but before that). I've learned this the hard way. You need to flush cache or download with a separate tool like wget which won't have cached the broken redirect.
↑ comment by Daniel Windham (daniel-windham) · 2024-04-11T19:31:59.942Z · LW(p) · GW(p)
Sorry about that Quinn. If the link is still not working for you, please let us know, but in the meantime here's a copy: https://drive.google.com/file/d/182M0BC2j7p-BQUI3lvXx1QNNa_VvrvPJ/view?usp=sharing