Why correlation, though?
post by numpyNaN · 2024-03-06T16:53:09.345Z · LW · GW · No commentsThis is a question post.
Contents
Answers 15 JBlack 7 dynomight 3 Metacelsus 1 rotatingpaguro None No comments
This is a very basic question to ask, but I'm not sure I actually understand some fundamental properties people seem to ascribe to correlation.
As far as I understand it, correlation usually refers to Pearson's correlation coefficient, which is, according to Wikipedia, "a correlation coefficient that measures linear correlation between two sets of data." Cool.
But then I see a discussion on whether variables X and Y are related in some way, and reads like:
- well, X correlates to Y with r=0.8 so it's a good predictor/proxy/whatever
- X and Y have been found to correlate with r = 0.05, so its not a good predictor/proxy/whatever
For the first one, I'm OK. For the second one, not so much:
looking at Anscombe's Quartet:
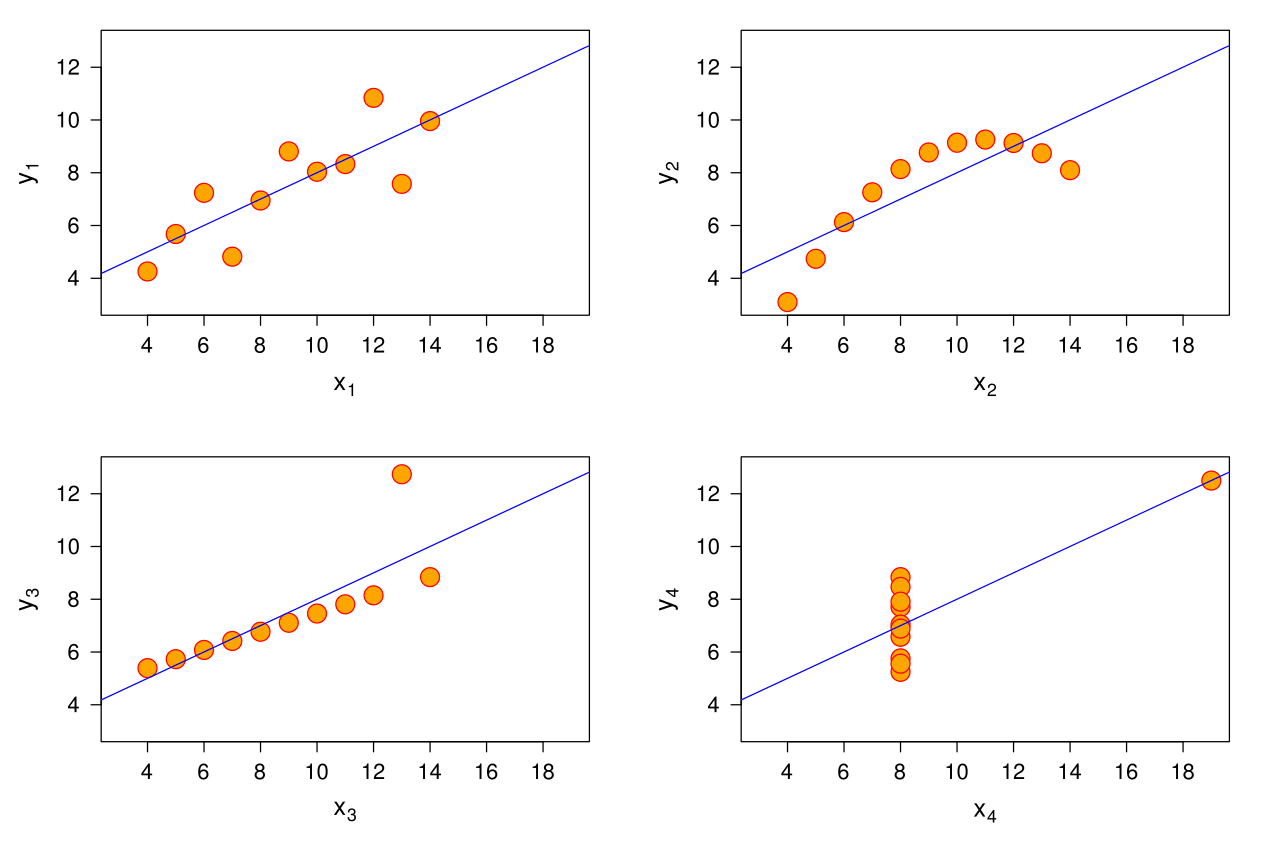
It would seem that even though correlation (and therefore R²) are the same for all 4 datasets, the upper-rightmost one could be an Y completely dependent on X, probably a polynomial of some kind (in which case, Y could be perfectly explained by X), whereas in the down-rightmost one Y couldn't be explained as a function of X, of any kind.
Now, I understand that correlation only measures how linearly two variables are related, but again, in the same example, it would seem that we would be better served by considering other, non-linear ways they could be related.
Since correlation is such an extended way of measuring the relationships of X and Y, across many levels of competence and certainly among people I know understand this much better than I do, my questions are:
Why is, besides being the most nice/common/useful type of relation, linear relationship privileged in the way I described above? Why is it OK to say that X is not a good predictor of Y because r=0.05, which I'm understanding as "It has a bad linear relation", without adressing other ways they could be related, such as a grade 27 polynimial? Is the fact that they are "badly" linearly related enough to explain that they won't be related any other way?
Again, this a very basic lagoon I've just recently found on myself, so an explanation on any level would be very appreciated
Answers
Linearity is privileged mostly because it is the simplest type of relationship. This may seem arbitrary, but:
- It generalizes well. For example, if y is a polynomial function of x then y can be viewed as a linear function of the powers of x;
- Simple relationships have fewer free parameters and so should be favoured when selecting between models of comparable explanatory power;
- Simple relationships and linearity in particular have very nice mathematical properties that allow much deeper analysis than one might expect from their simplicity;
- A huge range of relationships are locally linear, in the sense of differentiability (which is a linear concept).
The first and last points in particular are used very widely in practice to great effect.
A researcher seeing the top-right chart is absolutely going to look for a suitable family of functions (such as polynomials where the relationship is a linear function of coefficients) and then use something like a least-squares method (which is based on linear error models) to find the best parameters and check how much variance (also based on linear foundations) remains unexplained by the proposed relationship.
I think you're basically right: Correlation is just one way of measuring dependence between variables. Being correlated is a sufficient but not necessary condition for dependence. We talk about correlation so much because:
- We don't have a particularly convenient general scalar measure of how related two variables are. You might think about using something like mutual information, but for that you need the densities not datasets.
- We're still living in the shadows of the times when computers weren't so big. We got used to doing all sorts of stuff based on linearity decades ago because we didn't have any other options, and they became "conventional" even when we might have better options now.
Spearman (rank) correlation is often a good alternative for nonlinear relationships.
↑ comment by cubefox · 2024-03-10T18:00:13.165Z · LW(p) · GW(p)
That's not quite right. It measures the strength of monotonic relationships, which which may also be linear. So this measure is more general than Pearson correlation. It just measures whether, if one value increases, the other value increases as well, not whether they increase at the same rate.
Yes, in general the state of the art is more advanced than looking at correlations.
You just need to learn when using correlations makes sense. Don't assume that everyone is using correlations blindly; Statistics PhDs most likely decide whether to use them or not based on context and know the limited ways in which what the say applies.
Correlations make total sense when the distribution of the variables is close to multivariate Normal. The covariance matrix, which can be written as a combination of variances + correlation matrix, completely determines the shape of a multivariate Normal.
If the variables are not Normal, you can try to transform them to make them more Normal, using both univariate and multivariate transformations. This is a very common Statistics tool. Basic example: Quantile normalization.
No comments
Comments sorted by top scores.