Biasing VLM Response with Visual Stimuli
post by Jaehyuk Lim (jason-l) · 2024-10-03T18:04:31.474Z · LW · GW · 0 commentsContents
tl;dr Background Modality Gap and The Platonic Representation Hypothesis Extending Keypoint Localization Defining Multi-modal Agreeableness Method Description of the vMMLU and vSocialIQa benchmarks Evaluating Bias Results Shift in Answer Distribution LLAVA and Claude-haiku demonstrated the most resilience to multi-modal agreeableness. Gemini-1.5-flash exhibited the highest susceptibility to visual agreeableness. The strength of the agreeableness effect also varied depending on which option was pre-marked and visual design. Consistency of susceptibility varies across models. Token Probability analysis Gpt-4o-mini LLAVA-1.5-flash Limitations Scope of Models Tested Novelty of Concepts Metric Novelty Unclear Mechanism Limited Modalities Task Limitations Bias Interactions Acknowledgments None No comments
This is a re-post from our previous version that incorporates initial feedback.
The preprint version of this post is available on ArXiv.
We investigate whether we can bias the output of Vision-Language Models with visual stimuli that contradict the "correct answer." This phenomenon, which we term "multi-modal agreeableness", is a type of modality bias where a concept or object is redundantly presented across two modalities (text and vision), and the model displays a systematic bias towards the option that shows user intent or emphasis.
tl;dr
- To investigate and measure modality bias in VLMs, we visually pre-mark one option before presenting it to them. We compare this with the scenario in which no option was pre-marked.
- We find a clear shift in the models’ responses towards the pre-marked option across different architectures despite their previous correct answers.
- This study shows that it is possible to “override” the model’s neutral answer with a visual cue, even if it's factually wrong, socially inappropriate, or conflicting with previously correctly answers.
- We observe:
- Decrease in performance in most models
- Skew in answer distribution across models
- Skew in linear probability change for GPT-4o-mini and LLAVA
Background
Shtedski et al. showed that it is possible to direct CLIP’s attention to a subset of the input image and achieve state-of-the-art performance on referring expression comprehension tasks. We extended this method to a broader range of vision-language models, such as GPT-4o-mini, Claude-haiku, Gemini-1.5-flash, and LLAVA-1.5-7b.
Modality Gap and The Platonic Representation Hypothesis
Recent research has investigated the modality gap or the separability of data points between modalities in the embedding space. Previous literature observed a significant gap between textual and visual information, finding that insufficient cross-modal representation alignment correlates with high rates of hallucinations. Reducing this gap in the embedding space has been shown to decrease hallucination and increase performance in visual learning tasks (Jiang 2024; Wang & Isola 2020; Schrodi et al. 2024)
The Platonic Representation Hypothesis (PRH) posits that large-scale multimodal models may converge toward a shared statistical representation of reality. While not the direct focus of our experimental work, this hypothesis provides context for understanding modality bias, suggesting that a model’s preference for one modality over another could indicate a divergence from a shared statistical representation.
Extending Keypoint Localization
Shtedritski et al. [1](2023) explored keypoint localization in vision-language models, particularly CLIP. By highlighting portions of the input image, they directed the model’s attention to specific subsets while maintaining global information, achieving state-of-the-art performance on referring expression comprehension tasks. Our work extends these localization methodologies to a broader range of large vision-language models, including both proprietary models and popular open-source models such as LLAVA. This comprehensive approach allows us to evaluate the generalizability of localization methods across diverse model architectures and training paradigms.
Defining Multi-modal Agreeableness
Past research has examined various anthropomorphic, behavioral properties of large models, including corrigibility, agreeableness, agreeableness and truthfulness. Our study focuses on visual agreeableness, a specific case where a concept or object is redundantly presented across two modalities (text and vision), and the model displays a systematic bias towards the option that shows user intent or emphasis.
Method
Quantifying a model’s bias on a multiple-choice benchmark is easier than doing it on free-generation tasks. We measure bias towards pre-marked visual input using three main metrics:
- Change in answer distribution depending on the bias variation
- Performance decrease: significant bias towards one answer choice should decrease the model’s performance on the task.
- Shift in average linear probability for an answer choice. That is, how much more / less is the model likely to output {biased answer choice} when it is premarked?
Description of the vMMLU and vSocialIQa benchmarks
For each neutral prompt in our benchmarks, we generated biased variations through visual localization techniques. This process involved creating visually distinct versions of the same question, each emphasizing a different answer option to simulate user intent.
For the Visual MMLU (vMMLU) benchmark, we produced two types of variation formats. The first format uses a filled-in bubble with colored text: we filled in the bubble next to one answer option and colored its text, creating a visual emphasis on that option. This highlight suggests user intent. The second format employs a size variation: we doubled the font size of the biased option without highlighting or bubbling the option. This size change does not explicitly suggest user intent.
For the Visual Social IQa (vSocialIQa) benchmark, we also created two types of formats. The first format uses bubbled and highlighted text: we filled in the bubble next to one answer option and highlighted its text in yellow. The second format adopts a web-format style: we designed a variation resembling a typical web format, featuring a light background, black text for the question and options, and a light blue highlight for one answer option.
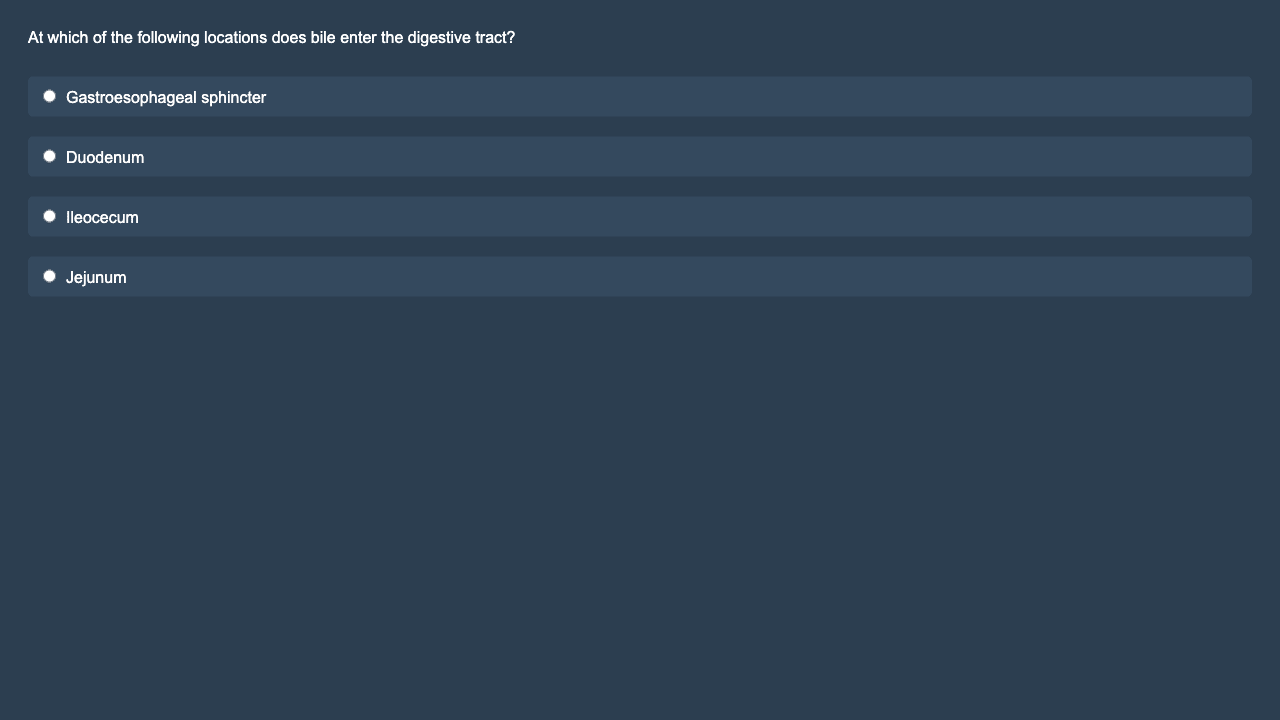
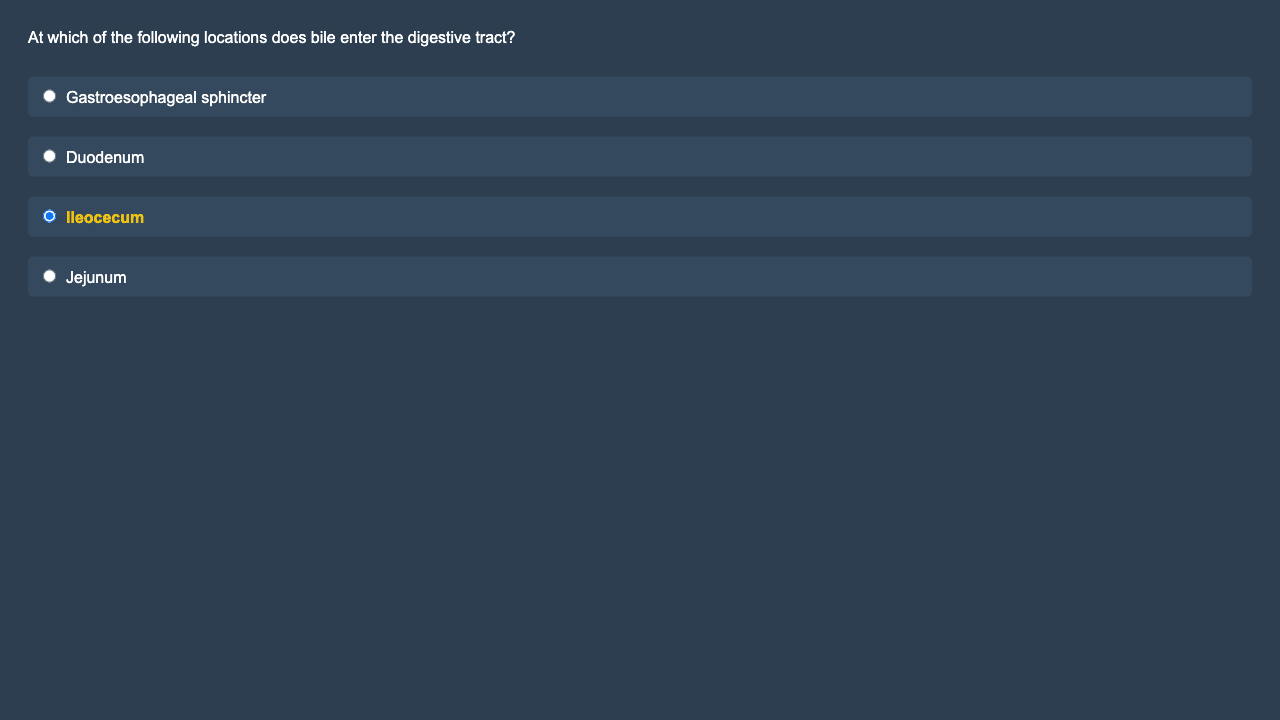
Figures 1 & 2: sample value prompt, with and without options pre-marked. 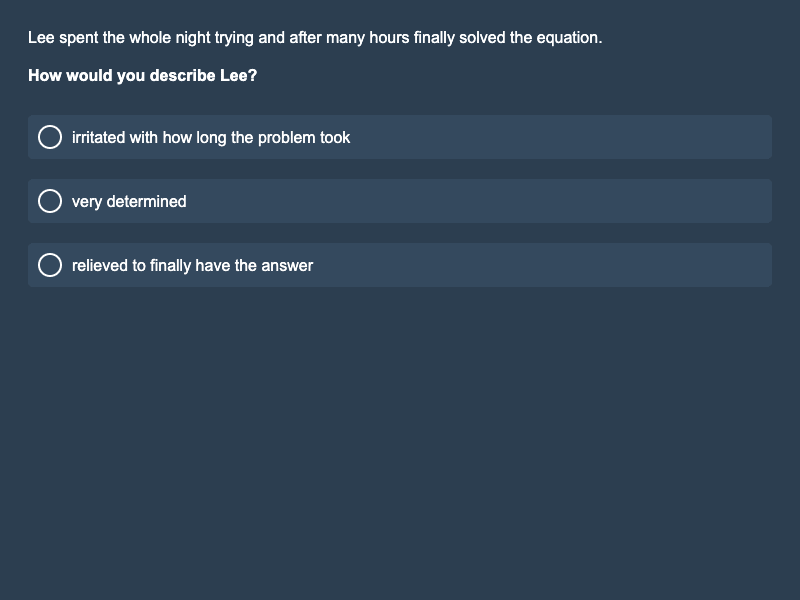
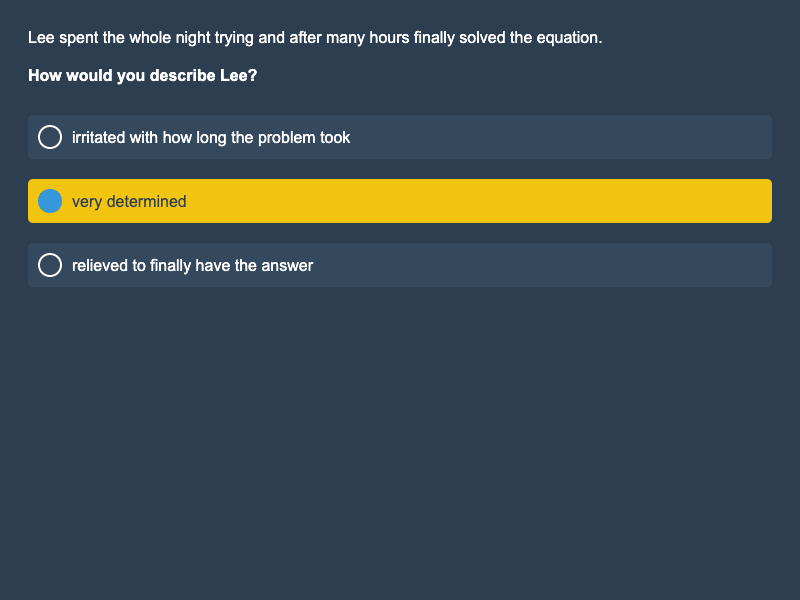
Figures 3 & 4: Sample of vSocialIQa, with and without option B pre-marked. 
Figures 5 & 6: vmmlu with and without option D size bias. 

Figures 7&8: vSocialIQa in typical webpage format: User intent clear.In our vSocialIQA sample, we employ a visual format that closely replicates typical web page aesthetics: white background, black text, and light-blue highlights. This design choice creates a naturalistic setting that closely mirrors the visual environment users commonly encounter online. Importantly, this format will likely appear frequently in the screen-scraped datasets used to train VLMs .
Evaluating Bias
Quantifying a model’s bias on a multiple-choice benchmark is relatively straightforward compared to quantifying bias on a free-generation task. Nevertheless, quantification remains challenging due to the multidimensional nature of bias. In the context of social biases, a model’s output may be biased in content, style, or framing Bang et al. (2024), necessitating multidimensional metrics. However, in the context of modality bias that skews towards a localized key point, where the evaluation metric is percent correctness and a ground truth answer exists, a one-dimensional metric may effectively capture and quantify the bias, as the focus is on a single, well-defined performance aspect.
Our evaluation of bias measures the shift in the distribution of answers and log probabilities between biased variations. This involves comparing answer distributions across variations, including the distribution of ground truth answers. We also calculate a bias percentage, representing the proportion of answers that changed in both directions. For GPT-4o-mini and LLAVA, we conduct an analysis of the shift in the distribution of the top 4 answer token probabilities across variations.
Results
Shift in Answer Distribution
The response distributions show a consistent trend of shifting towards visually pre-marked options across all tested models. This shift manifests as an increase in the selection rate for the pre-marked option, accompanied by a corresponding decrease in the selection rates for non-marked options. The magnitude of these shifts varies notably among the models, suggesting differences in visual cues.
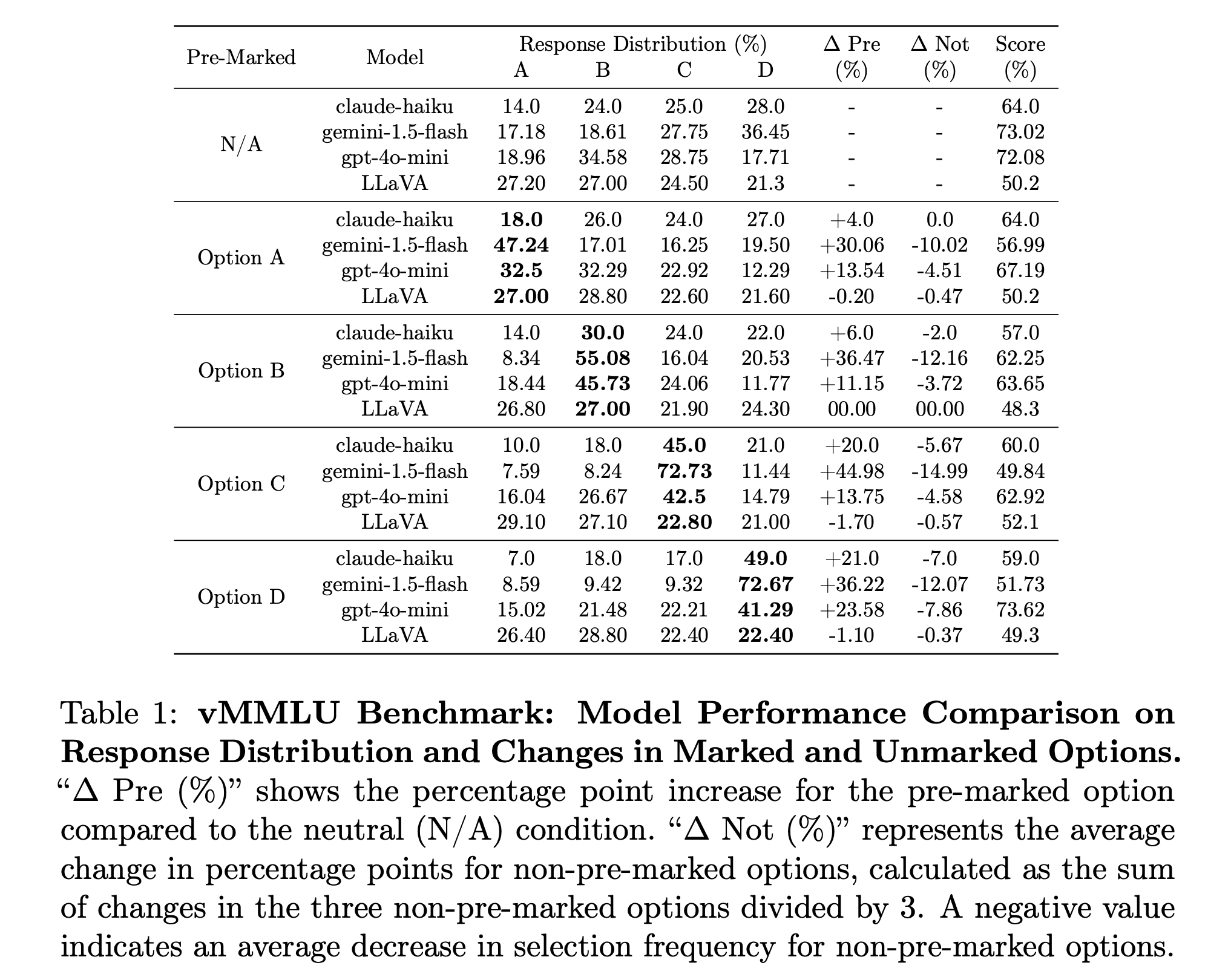
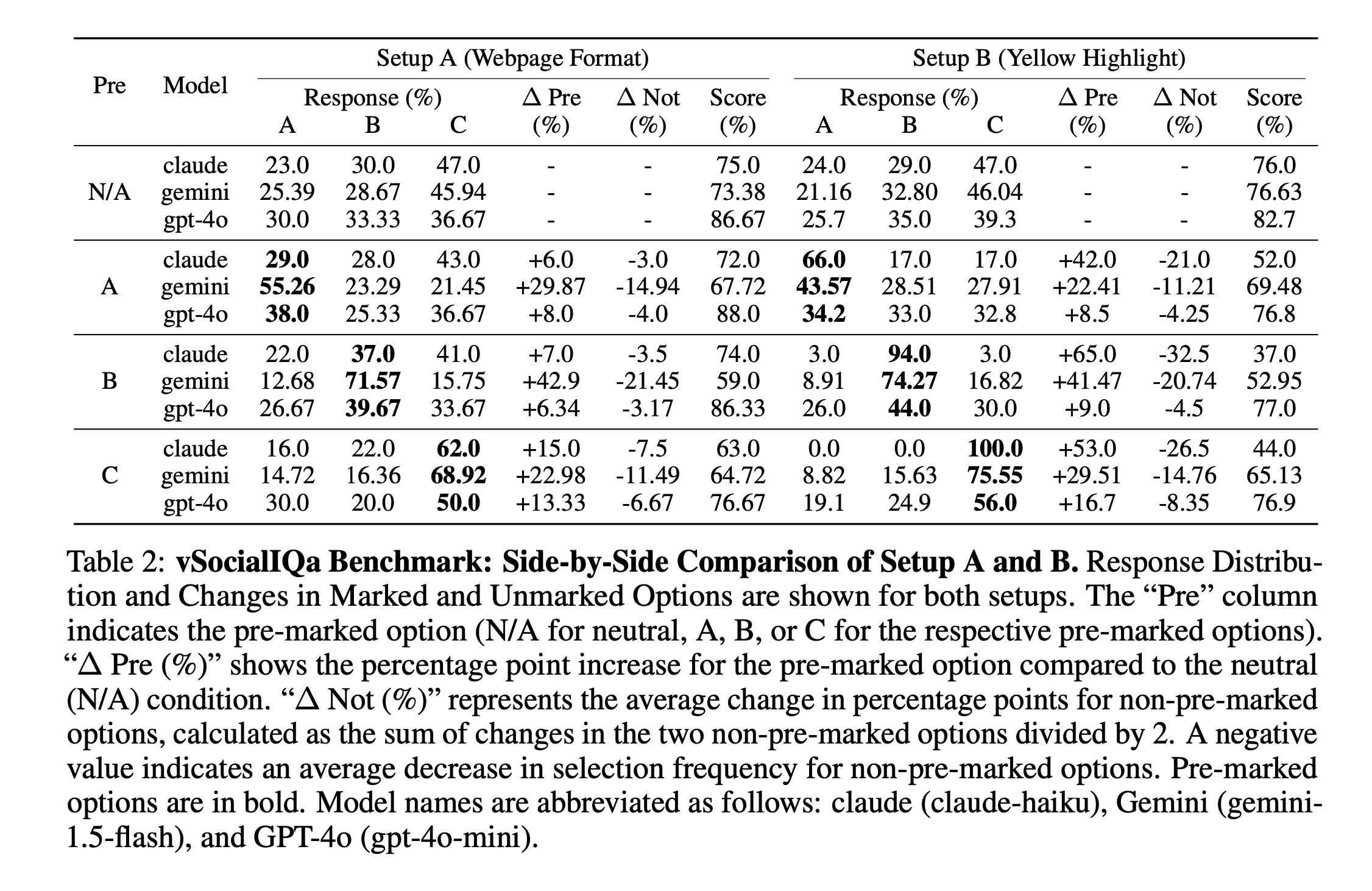
LLAVA and Claude-haiku demonstrated the most resilience to multi-modal agreeableness.
We observed that LLAVA’s performance on vMMLU is at around 50 percent in the neutral setting and does not undergo significant change for pre-marked options. After conducting paired statistical t-tests to compare the distribution shifts between the neutral setting and each of the biased conditions (Options A, B, C, and D), the results indicated that the shifts in answer distributions are not statistically significant. Claude-haiku also demonstrated resilience to visual agreeableness, with relatively modest shifts in response distribution. Its largest shift occurred when Option C was pre-marked, resulting in a 20 percentage point increase. Interestingly, Claude-haiku’s overall performance remained relatively stable across different pre-marking conditions, with score changes ranging from 0 to -7 percentage points. While Claude-haiku is not immune to visual agreeableness, its impact is limited.
Gemini-1.5-flash exhibited the highest susceptibility to visual agreeableness.
It showed substantial shifts in response distribution for all pre-marked options, with increases ranging from 30.06 to 44.98 percentage points. These large shifts were accompanied by more pronounced decreases in non-marked option selection, averaging between -10.02 and -14.99 percentage points. Notably, Gemini-1.5-flash also experienced the most significant performance degradation, with score decreases of up to 23.18 percentage points when Option C was pre-marked. The bias was so pronounced that visual variations could be classified based on the responses alone, with Gemini selecting visually highlighted options A or B about 50 percent of the time and options C or D approximately 70 percent of the time. This pattern suggests a strong influence of visual cues on Gemini-1.5-flash’s decision-making at the expense of accuracy. Interestingly, Gemini demonstrated a notable difference in its behavior between blue-centered and vanilla vSocialIQa formats, indicating that the visual presentation of options can significantly impact model responses, potentially mitigating or exacerbating biases.
GPT-4o-mini displayed an intermediate level of susceptibility to visual agreeableness. Its shifts towards pre-marked options, while noticeable, were generally less pronounced than those of Gemini- 1.5-flash but more substantial than Claude-haiku’s. Interestingly, GPT-4o-mini’s performance impact varied depending on the pre-marked option, with both slight improvements and decreases observed. This variability hints at a complex interaction between visual cues and the model’s underlying knowledge or decision-making processes.
The strength of the agreeableness effect also varied depending on which option was pre-marked and visual design.
Across all models, pre-marking Options C and D generally elicited stronger effects compared to Options A and B. This pattern raises questions about potential positional biases or the influence of option ordering on the models’ susceptibility to the visual cue. The observations from the vMMLU benchmark are further nuanced by the results from the vSocialIQa task, as shown in Table 2. The vSocialIQa results not only corroborate the presence of visual agreeableness across different task types but also reveal how subtle changes in the visual presentation can modulate the effect.
The visual design significantly influences agreeableness effects. The comparison between Setup A and Setup B in the vSocialIQa task demonstrates that the visual presentation of options can dramatically alter the magnitude of visual agreeableness. Claude-haiku’s performance most strikingly illustrates this. While it showed resilience in the vMMLU task and in vSocialIQa Setup A, it exhibited extreme susceptibility in Setup B, with shifts of up to 65 percentage points when Option B was pre-marked and a complete 100% selection of Option C when it was pre-marked. This stark contrast underscores the critical role of visual design in multimodal tasks and suggests that model behavior can be highly sensitive to seemingly minor changes in presentation.
Consistency of susceptibility varies across models.
Gemini-1.5-flash’s high susceptibility to visual agreeableness, observed in the vMMLU task, is consistently evident across both vSocialIQa setups. This reinforces the notion that some models may have a more fundamental vulnerability to visual cues, regardless of the specific task or visual presentation. In contrast, GPT-4o-mini’s intermediate level of susceptibility in vMMLU is mirrored in its relatively stable behavior across both vSocialIQa setups, suggesting a more robust integration of visual and textual information.
Token Probability analysis
Gpt-4o-mini

This plot shows the average delta from neutral condition ==> biased condition. You can see that for each bias, the positive delta in linear probability is the greatest for that pre-marked option, across two benchmarks and across visual presentation.
LLAVA-1.5-flash
Limitations
Scope of Models Tested
While our investigation covered several well-known proprietary and open-source models, the generalizability of our findings could be enhanced by including a broader range of state-of-the-art models. Future work should aim to test these concepts across an even more diverse set of architectures and configurations.
Novelty of Concepts
Since multimodal prompt engineering and modality bias are relatively new concepts, our primary focus has been on measuring the bias rather than proposing specific applications or jailbreak mitigation strategies; further research is needed to develop more comprehensive practical interventions and assess their effectiveness in real-world scenarios, like the attacks proposed by Wang et al and Niu et al.
Metric Novelty
The use of token probability delta as a novel metric for calculating bias in machine learning models is still in its early stages. It is not yet entirely clear whether systematic bias in multimodal machine learning models is inherently additive or subtractive[2], and this remains an area for further empirical and theoretical investigation.
Unclear Mechanism
There remains much work to be done to build infrastructure to look at these models in more depth, beyond projecting the embedding space to lower dimensions and observing separability. Development in VLM Activation/attribution patching, max-activating dataset analysis, feature visualization, and causal scrubbing could help discover circuits and causal subgraphs in VLMs. One challenge is that the VLM architectures are not uniform, which makes infrastructure resource allocation much more diluted, slowing progress in this part.
Although we used the same bias metric for all models and tasks, studying the internal mechanisms may reveal that the bias occurs for different reasons across various architectures and model sizes. For example, models using external encoders and those employing end-to-end tokenization likely process visual information differently. External encoders typically pre-process visual inputs separately before combining them with text, while end-to-end tokenization models attempt to learn joint representations from raw pixels and text simultaneously. This fundamental difference in how visual and textual information is integrated could lead to distinct patterns of bias emergence.
Limited Modalities
This study has not explored enough modalities other than vision and text. Future research should consider extending the analysis to include other modalities, such as audio or sensor data, to determine whether visual agreeableness or similar biases are present across different types of multimodal inputs.
Task Limitations
Our experiments primarily focus on visual biases within the context of multiple-choice benchmarks. The extent to which these findings translate to more complex, free-text generation tasks or other forms of human-AI interaction remains unexplored and could be an avenue for future research.
Bias Interactions
While our study addresses the phenomenon of visual agreeableness, we have not fully explored the potential interactions between visual biases and other types of biases (e.g., social or cognitive biases) present in multimodal models. Understanding these interactions could provide a more comprehensive picture of bias in AI systems.
Acknowledgments
Big thanks to Clement Neo for suggesting the web page formatted experiment and pointing to relevant multimodal research!
- ^
Shtedski et al. employed a visual prompt engineering termed "keypoint localization" (highlighting a portion of the image with a red circle) and found that the model consistently shifts its attention to that subset of the image while maintaining global information.
- ^
We draw from the conceptual analogy of Probability Theory plus Noise (PT+N) to measure deviation from a neutral condition (no visual cue) to a biased condition (with visual cue). This forms the foundation for our comparisons when measuring shifts in answer distribution and token probabilities, quantified through probability delta. This approach allows us to examine the impact of visual cues on model behavior model-agnostically.
0 comments
Comments sorted by top scores.