A bet on critical periods in neural networks
post by kave, Garrett Baker (D0TheMath) · 2023-11-06T23:21:17.279Z · LW · GW · 1 commentsContents
1 comment
See the code and data at this github
Hey Garrett! I hear you have some new empirical results. What's the setup?
So I've told you my theory about how critical periods work. What I did is replicate the paper, and then found another problem in my math, which flips the direction that ^λ should go as you increase the epochs, and I got this neat looking graph
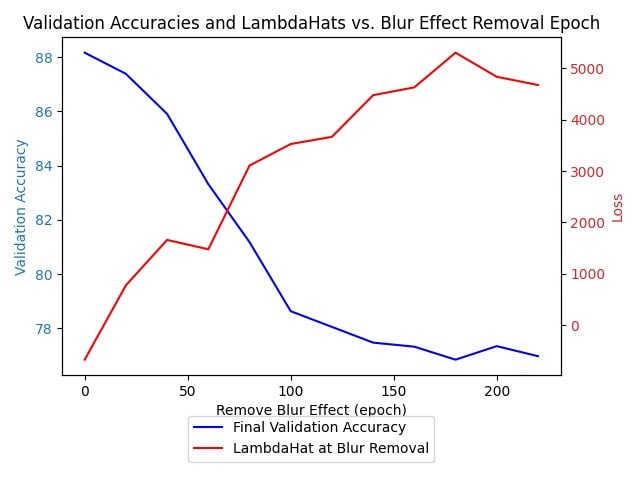
(The right scale should be the local learning coefficient, not the loss)
Let me give my rough summary of how you're thinking about critical periods.
In human developmental psychology, a critical period is a period where the brain is particularly good at learning something, and may not be able to learn it in the future.
There's also a paper you're interested in, that takes some neural networks learning the classification task CIFAR 10 (which asks the network to classify images as aeroplanes, automobiles, birds or one of another 7 categories). It blurs the images in the training data up to some epoch, then unblurs them afterwards. After some epoch, unblurring the images isn't sufficent for the network to converge towards the performance of a network that was trained on unblurred images for the whole time.
There's some hope that singular learning theory can predict when this "critical epoch" will be, by looking at the RLCT of the network parameters during training. I'm unclear on if that's in the original paper, or from you.
Does that sound roughly right?
Yes, though with respect to the hope that singular learning theory can predict when the critical epoch is, I think that's not so likely, though it definitely does seem more responsive to "something's going on" than the train loss or validation loss at the blur removal:
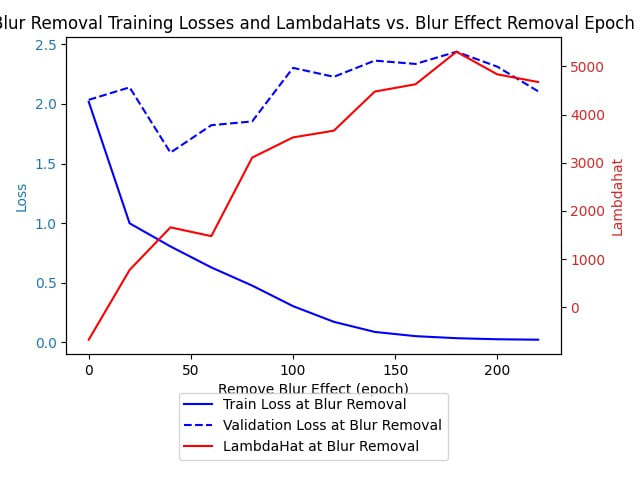
which sorta just seem to be behaving business as usual. But we aren't at the point yet where we can say exactly when the critical epoch is, and I don't expect us to be there immediately. The main immediate point of this investigation is to think of a way that critical periods can be thought of in terms of SLT, then see if we can pump out even the smallest smidgeon of predictions out of that picture using the very limited experimental apparatuses of current singular learning theory.
As far as I can see, both the train loss and ^λ look like they're fairly symmetric with the final validation accuracy (with train loss having a trivial symmetry), but that's the main connection between the properties of interest that I see. What do you see?
It seems like the train loss is monotonically decreasing, and looks no different from any other train loss, while the lambdahat seems to increase with the final validation accuracy's decrease, until that final validation accuracy levels off, then it levels off. Maybe there's a small kink at 150 of the train loss, but if you showed me that train loss I'd think nothing of it, and if you showed me the lambdahat I'd say "looks like something weird is happening"
And what's the weird thing in particular that's happening? Like, what would a more normal thing be for it to do?
Normally it should just stay relatively in the same location, I thought I made a graph of normal lambdahat, but then I recently realized it kinda sucked. It was trained for too few epochs, and there were numerical instability issues with the calculation leading to wacky lambdahats
Yeah I remember Arjun mentioning [LW · GW] it's easy to get wacky ^λs.
The default hyperparameters work a lot of the time, but yeah
see if we can pump out even the smallest smidgeon of predictions out of that picture using the very limited experimental apparatuses of current singular learning theory
So, was this a success? Or is the idea, first explore, then form a hypothesis, then test?
This was a small success. I had the hypothesis that epochs can be thought of as decreasing the temperature of your ML model, and you can get a critical period out of such an assumption by essentially having, for now, assume 2 possible singularities/model classes you model could arrive at. If the temperature is high, then if you're sampling, traversing between the model classes is easy. If the temperature is low, then traversing between them as you're sampling is hard. So critical periods happen when one of the singularities/model classes captures (in this case) the fine-grained details of the non-blurred CIFAR-10 images, and the other does not, so that for high temperature, as you go for a random walk around the blurred CIFAR-10 images, and you suddenly switch to the data distribution including the non-blurred CIFAR-10 images, you can easily switch which model class you spend most of your time sampling from. But for low temperature, its harder.
So using the free energy formula
Fn=nLn/T+λlogn
if we decrease the temperature, we must also decrease Ln, so we must increase λ because if there existed a model class with lower Ln and λ, then we would already be on it.
And we do indeed see this, so weak evidence pro the theory. More interesting evidence would come from, say, seeing if we find the same sort of effect as we increase the batch size. Maybe we should anticipate that the larger the batch size, the sooner the event happens. Though this disagrees with common sense, so possibly I'm messing up in my logic somewhere.
I feel like I am imagining two effects, and I'm not sure which is stronger or more relevant.
The first is that the lowest loss basin comes to dominate the ensemble as we run more epochs, and so we have less measure over the slightly higher-loss basin.
The second is that the region inbetween the two basins becomes low measure, and so we can't transition between the two basins any more.
Are these effects you're imagining and if so which is larger?
Yeah, so in the short run at least, the second is stronger when there's critical periods. And (because of the first) we should anticipate that more dakka is needed to fix the critical period, and get good performance again. I don't however know a good way of estimating just how much more dakka.
Can you expand on the common sense intuition regarding batch size and when the critical change happens?
So common sensically, a lower batch size ends up moving more each epoch, so you should see stuff happen quicker, and a larger batch size ends up moving less each epoch, so you should see stuff happen slower. Unless you normalize the learning rates such that the lower batch size goes the same distance as a larger batch size, but that's probably not a good idea compared to just figuring out what the best learning rate is. Like, if you have really bad learning rates even with a very large batch size, you're going to eventually end up with an SGD distribution that does not very much resemble your loss landscape.
Is the idea that the smaller batch is more likely to have uncancelled noise in its update vector?
Yes
Cool
But that's a part of it, that's why you should suspect increased batch size leads to decreased temperature, because of less randomness. But that's just how it connects to SLT. The common sense notion is that increased batch size is similar to training slowly & carefully , while decreased batch size is similar to moving fast and breaking things.
Hm yeah that makes sense. I'd take a small bet in favour of the theory and against the common sense in this case.
Then you're more confident in simple arguments then I am! Why don't you find the differing cross-epoch changes worrying?
Now, my intuitions about gradient descent are likely pretty silly, but I like to take small bets when I notice I have intuitions to help them move. Here's what they say, though.
The main force consolidating the measure around the singularities is just the quantity of data. Using smaller batches will make you move more because of random sampling noise (but the blur isn't sampling noise) and because it's probably OK to update before you've seen the full dataset in most cases. But I think the first effect shouldn't consolidate the measure that much and I don't know how to think of the second effect but I think for standard learning rates it should probably be kind of small? Like sublinear in (dataset size/batch size).
Yeah, that seems reasonable, but not reasonable enough for me to bet on it, so if you wanted we could bet on whether running with batch size 64 rather than 128 would make the critical period end later rather than sooner?
Let's do it. $10 at even odds?
Sounds good to me!
🤝
🤝
OK, nice! Shall we talk some more about some of this now or come back when we have experimental results?
Seems like this is a good place to end.
See you on the other side of the data-gathering!
Update:
I'm currently not finding much evidence of any phase change for the 64 batch
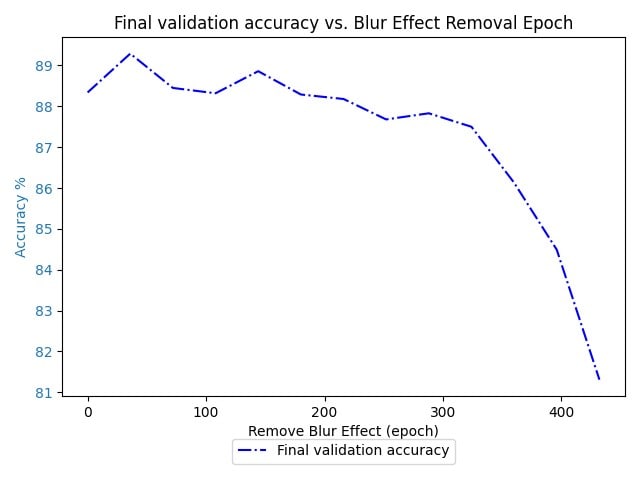
There is a stark decrease on 400, but I don't know if that would stick around if I increased the epoch to 800.
To speed things up I also reconfigured how training works, so now I'm verifying we still get a phase transition with the 128 batch size. Then after that I think I'm going to increase the batch size instead of decreasing it, to make the results come in quicker. Because the above plot took 9 hours of training to make.
Update 2: While making the last plot I tried to make my code efficient, but this actually messed up the settings which produced the original phenomena, so I’d recommend ignoring it.
Final update: Using the old code, we get this plot for the 64 batch version
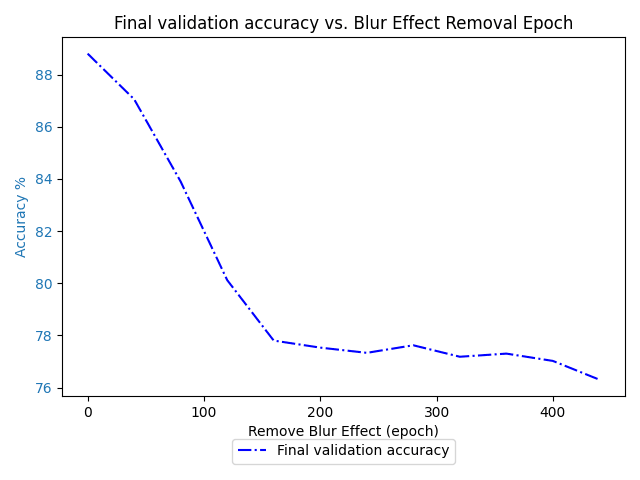
It looks like we hit about 77% between epochs 120 and 160, whereas in the original we reach that the same nick in the curve between epochs 80 and 100. So I say Kave wins!
Comparing again with the graph for 128:

(note the different x-axes, the 64 one is 2x bigger than the 128 one.)
Bet paid.
:i-checked-its-true:
1 comments
Comments sorted by top scores.