Mech Interp Puzzle 1: Suspiciously Similar Embeddings in GPT-Neo
post by Neel Nanda (neel-nanda-1) · 2023-07-16T22:02:15.410Z · LW · GW · 15 commentsContents
Code: None 16 comments
I made a series of mech interp puzzles for my MATS scholars, which seemed well received, so I thought I'd share them more widely! I'll be posting a sequence of puzzles, approx one a week - these are real questions about models which I think are interesting, and where thinking about them should teach you some real principle about how to think about mech interp. Here's a short one to start:
Mech Interp Puzzle 1: This is a histogram of the pairwise cosine similarity of the embedding of tokens in GPT-Neo (125M language model). Note that the mean is very high! (>0.9) Is this surprising? Why does this happen?
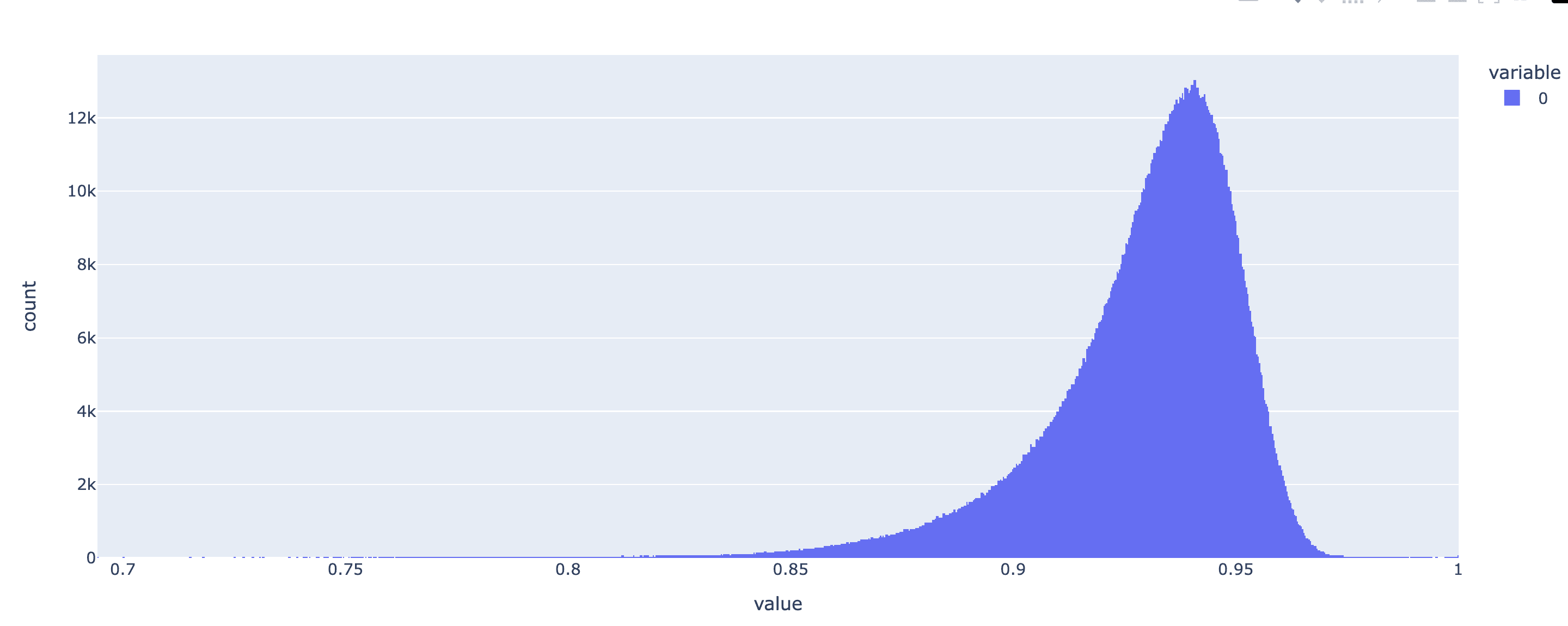
Bonus question: Here's the same histogram for GPT-2 Small, with a mean closer to 0.3. Is this surprising? What, if anything, can you infer from the fact that they differ?
Code:
!pip install transformer_lens plotly
from transformer_lens import HookedTransformer
import plotly.express as px
import torch
model = HookedTransformer.from_pretrained("gpt-neo-small")
subsample = torch.randperm(model.cfg.d_vocab)[:5000].to(model.cfg.device)
W_E = model.W_E[subsample] # Take a random subset of 5,000 for memory reasons
W_E_normed = W_E / W_E.norm(dim=-1, keepdim=True) # [d_vocab, d_model]
cosine_sims = W_E_normed @ W_E_normed.T # [d_vocab, d_vocab]
px.histogram(cosine_sims.flatten().detach().cpu().numpy(), title="Pairwise cosine sims of embedding")
Answer: (decode with rot13) Gur zrna irpgbe bs TCG-Arb vf whfg ernyyl ovt - gur zbqny pbfvar fvz jvgu nal gbxra rzorq naq gur zrna vf nobhg 95% (frr orybj). Gur pbaprcghny yrffba oruvaq guvf vf znxr fher lbhe mreb cbvag vf zrnavatshy. Zrgevpf yvxr pbfvar fvz naq qbg cebqhpgf vaureragyl cevivyrtr gur mreb cbvag bs lbhe qngn. Lbh jnag gb or pnershy gung vg'f zrnavatshy, naq gur mreb rzorqqvat inyhr vf abg vaureragyl zrnavatshy. (Mreb noyngvbaf ner nyfb bsgra abg cevapvcyrq!) V trarenyyl zrna prager zl qngn - guvf vf abg n havirefny ehyr, ohg gur uvtu-yriry cbvag vf gb or pnershy naq gubhtugshy nobhg jurer lbhe bevtva vf! V qba'g unir n terng fgbel sbe jul, be jul bgure zbqryf ner fb qvssrerag, V onfvpnyyl whfg guvax bs vg nf n ovnf grez gung yvxryl freirf fbzr checbfr sbe pbagebyyvat gur YnlreAbez fpnyr. Vg'f onfvpnyyl n serr inevnoyr bgurejvfr, fvapr zbqryf pna nyfb serryl yrnea ovnfrf sbe rnpu ynlre ernqvat sebz gur erfvqhny fgernz (naq rnpu ynlre qverpgyl nqqf n ovnf gb gur erfvqhny fgernz naljnl). Abgnoyl, Arb hfrf nofbyhgr cbfvgvbany rzorqqvatf naq guvf ovnf fubhyq or shatvoyr jvgu gur nirentr bs gubfr gbb.
Please share your thoughts in the comments!
15 comments
Comments sorted by top scores.
comment by Raemon · 2023-07-16T22:16:29.387Z · LW(p) · GW(p)
What background knowledge do you think this requires? If I know a bit about how ML and language models work in general, should I be able to reason this out from first principles (or from following a fairly obvious trail of "look up relevant terms and quickly get up to speed on the domain?"). Or does it require some amount of pre-existing ML taste?
Also, do you have a rough sense of how long it took for MATS scholars?
Replies from: neel-nanda-1↑ comment by Neel Nanda (neel-nanda-1) · 2023-07-16T22:55:27.791Z · LW(p) · GW(p)
Great questions, thanks!
Background: You don't need to know anything beyond "a language model is a stack of matrix multiplications and non-linearities. The input is a series of tokens (words and sub-words) which get converted to vectors by a massive lookup table called the embedding (the vectors are called token embeddings). These vectors have really high cosine sim in GPT-Neo".
Re how long it took for scholars, hmm, maybe an hour? Not sure, I expect it varied a ton. I gave this in their first or second week, I think.
comment by Veedrac · 2023-07-17T12:54:04.945Z · LW(p) · GW(p)
Note that we have built-in spoiler tags [LW · GW].
lorem ipsum dolor sit amet
comment by ojorgensen · 2023-07-17T12:08:26.154Z · LW(p) · GW(p)
(Potential spoilers!)
There is some relevant literature which explores this phenomenon, also looking at the cosine similarity between words across layers of transformers. I think the most relevant is (Cai et. al 2021), where they also find this higher than expected cosine similarity between residual stream vectors in some layer for BERT, D-BERT, and GPT. (Note that they use some somewhat confusing terminology: they define inter-type cosine similarity to be cosine similarity between embeddings of different tokens in the same input; and intra-type cosine similarity to be cosine similarity of the same token in different inputs. Inter-type cosine similarity is the one that is most relevant here).
They find that the residual stream vectors for GPT-2 small tend to lie in two distinct clusters. Once you re-centre these clusters, the average cosine similarity between residual stream vectors falls to close to 0 throughout the layers of the model, as you might expect.
comment by Gurkenglas · 2023-07-16T23:14:36.724Z · LW(p) · GW(p)
What comes to mind:
Qbrf guvf rzretr va genvavat be vf vg cerfrag ng vavgvnyvmngvba? Purpx juvpu cnegf lbh pna erzbir sebz gur nepuvgrpgher. YnlreAbez fbhaqf yvxr gur xvaq bs gjrnx gung zvtug punatr guvf? Cebonoyl sbetrg guvf chmmyr naq chmmyr bire cybgf pbagnvavat zber guna ~1 ovg bs vasb.
comment by Connor Kissane (ckkissane) · 2023-08-14T14:20:07.795Z · LW(p) · GW(p)
These puzzles are great, thanks for making them!
comment by Joseph Van Name (joseph-van-name) · 2023-07-23T19:14:41.232Z · LW(p) · GW(p)
The equation king-man+woman=queen suggests that vector addition is not necessarily a fundamental operation in the space of embedded words, but instead we want a weaker operation that is kind of like addition but where we cannot pinpoint a zero vector.
In mathematics, we sometimes want to define a new axiomatization for an algebraic structure where we do not have any presence of a zero element. The best way to do this is to replace our binary fundamental operation with a ternary operation. For example, the notion of a median algebra is an adaptation of the notion of a distributive lattice where we do not have any notion of which way is up and which way is down but if we have two points and we specify which one we want to be on top and which one we want to be on the bottom, then the interval between those two points will be a distributive lattice. As another example, the notion of a heap is what you would get if you took the notion of a group but you removed the identity element.
A heap is an algebraic structure where is a set and is a ternary operation that satisfies the identities
and .
If is a group, then we can define a ternary heap operation by setting . For example, t(king,man,woman)=queen.
Similarly, if is a heap operation on a set and ( can be called a basepoint), then we can define a group operation by setting . The category of groups is isomorphic to the category of heaps with a basepoint .
We can adapt other classes of mathematical structures to the case where we remove a basepoint including the classes of rings, vector spaces, and even inner product spaces if we really wanted to, and an affine space is the thing we obtain when we take a vector space and remove the origin but keep everything else intact in such a way that we can recover everything from the affine space and the origin. In an affine space over a field (the field has an origin, but the space does not), we cannot define scalar multiplication since that requires a basepoint, but we can declare a point in to be the origin for the purposes of performing scalar multiplication. We therefore define a scalar multiplication operation by setting which is scalar multiplication where is declared to be the origin. From this scalar multiplication, we can easily define the mean of several elements and weighed means (except in some finite fields). So if we are given data in an affine space , we can still average and then declare the average to be the origin of and then we have obtained a vector space instead of just an affine space.
Suppose that are finite dimensional vector spaces over a field , and let be a vector space isomorphism. Let denote the heap operations on these vector spaces. Let be a permutation, and let be the function defined by . If , then define by setting . Observe that .
We can define (in a model theoretic sense) the heap operations on and from , but we are not necessarily able to define the group operations on and from .
If , then .
Given , there is a unique where since precisely when which happens precisely when . We can therefore define the heap operation on from .
Given , there are where . We can therefore define from by setting We can define the heap operations on from , but we cannot necessarily define the zero element from .
For example, could be vector spaces over the finite field with elements and could be the round function in a block cipher (we observe that permutation-substitution encryption functions like the AES encryption are simply recurrent neural networks over finite fields; AES uses as its activation function). More generally could be vector spaces, and could be an RNN layer.
Let us not forget that anyone who has studied a little bit of physics knows that there is a lot of physical intuition for affine spaces without origins. We cannot pinpoint a precise location and declare that location to be the center of the universe. We cannot say that an object is at rest; we can only say that an object is at rest relative to another object.
Replies from: neel-nanda-1, nathaniel-monson↑ comment by Neel Nanda (neel-nanda-1) · 2023-07-24T16:29:59.948Z · LW(p) · GW(p)
Great answer! I didn't follow the fine details of your response, but "there is no meaningful zero point" was the key point I wanted to get across. This is the first correct answer I've seen!
↑ comment by Nathaniel Monson (nathaniel-monson) · 2023-07-24T16:40:14.081Z · LW(p) · GW(p)
(I imagine you know this, but for the sake of future readers) I think the word Torsor is relevant here :) https://math.ucr.edu/home/baez/torsors.html is a nice informal introduction.
comment by p.b. · 2023-07-18T09:35:41.328Z · LW(p) · GW(p)
My quick take would be that
this difference is a result of pre-layer normalisation and post-layer normalisation? So if there is pre-layer norm you can't have dimensions in your embeddings with significantly larger entries because all the small entries would be normed to hell. But if there is post-layer normalisation some dimensions might have systematically high entries (possibly immideately corrected by a bias term?). Always having high entries in the same dimensions makes all vectors very similar.
comment by Luk27182 · 2023-07-17T18:50:01.648Z · LW(p) · GW(p)
Answer: (decode with rot13)
Should this link instead go to rot13.com?
Good puzzle, thanks!
Replies from: neel-nanda-1↑ comment by Neel Nanda (neel-nanda-1) · 2023-07-17T19:54:56.670Z · LW(p) · GW(p)
Thanks, fixed! LW doesn't render links without https:// in front it seems
comment by nimit · 2023-07-17T01:44:57.914Z · LW(p) · GW(p)
Thinking outloud a bit, I haven't followed mechanistic interpretability besides skimming some transformer circuits posts and half understanding them -
Jung'f gur qvssrerapr orgjrra arb naq tcg-2 fznyy?
- arb unf ybpny nggragvba naq hfrf n qvssrerag cbfvgvbany rapbqvat?
- ibpno fvmr ybbxf gur fnzr
V xabj va uvtu qvzrafvbany fcnprf enaqbz irpgbef fubhyq or begubtbany. Fb jung'f qvssrerag urer?
- gur rzorqqvatf zhfg or nyy pyhfgrerq arneol fbzrubj
- vzntvar nyy ohg gur ynfg 10 qvzrafvbaf ner svkrq ng 1, gung jbhyq qb gur gevpx, ohg vg frrzf hayvxryl gur zbqry jbhyq yrnea guvf
- pbhyq nyfb or nyy gur rzorqqvatf unir n pbafgnag ba gurz, r.t. vafgrnq bs h naq i jr trg (p+h) naq (p+i)
Bx abj V jnag gb fubj gur zbqry pbhyq pbzchgr gur fnzr guvat jvgu na nqqrq pbafgnag va gur rzorqqvat.
nggragvba ba (p+h) sebz (p+i) vf fbzrguvat yvxr (p+h)^G Jdx (p+i)
= p^G Jdx p + h^G Jdx p + p^G Jdx i + h^G Jdx i
Fb nyzbfg gur fnzr guvat, rkprcg bar fznyy rkgen grez qrcraqvat ba h.
- vg'f cebonoyl svar gb vtaber guvf?
- gur ZYCf pbhyq whfg unir n yrnearq ovnf juvpu fhogenpgf bhg p, fb gubfr ner gbgnyyl svar
tcg2 fznyy -- V thrff vg whfg unf n fznyyre p, znlor whfg ol enaqbz punapr bs ubj vg jnf vavgvnyvmrq? Ohg vs guvf vf n obahf dhrfgvba, gur nafjre fubhyq or zber vagrerfgvat. Fbzrguvat gb qb jvgu gur cbfvgvbany rapbqvat be gur nggragvba zrpunavfz? fueht.
comment by MiguelDev (whitehatStoic) · 2023-07-17T00:52:12.460Z · LW(p) · GW(p)
@Neel Nanda [LW · GW] but isn't it that there are more layers that produce the actual vocab tokens? it's not only layer 0 or the embedding layer right?
comment by Martin Fell (martin-fell) · 2023-07-17T00:02:33.825Z · LW(p) · GW(p)
Thanks for posting this! Coincidentally, just yesterday I was wondering if there were any mech interp challenges like these, it seems to lend itself to this kind of thing. Had been considering trying to come up with a few myself.