My current workflow to study the internal mechanisms of LLM
post by Yulu Pi (yulu-pi) · 2023-05-16T15:27:14.207Z · LW · GW · 0 commentsContents
200 COP in MI: Studying Learned Features in Language Models None No comments
This is a post to keep track my research workflow of studying LLM. Since I am doing it on my spare time, I want to keep my pipeline as simple as possible.
Step 1: Formulate a question for investigating model's behavior .
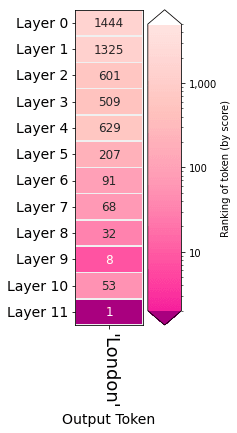
Step 2: Find the influential layer for the behavior
- Output across layers
https://github.com/jalammar/ecco
- Activation patching (Rome)
Notebook examples:
https://colab.research.google.com/drive/1uFui2i40eU0G9kvbCNTFMgXFHSB7lL9i
https://colab.research.google.com/github/UFO-101/an-neuron/blob/main/an_neuron_investigation.ipynb
Step 3: Locate the influential neuron
- activation patching for individual neurons
- Use Neuroscope to see the behavior of the neurons https://neuroscope.io/
Step 4: Visualize the neuron activation
- Interactive Neuroscope
Reference:
We Found An Neuron in GPT-2 [LW · GW]
Interfaces for Explaining Transformer Language Models
200 COP in MI: Studying Learned Features in Language Models [LW · GW]
0 comments
Comments sorted by top scores.