Designing agent incentives to avoid side effects
post by Vika, TurnTrout · 2019-03-11T20:55:10.448Z · LW · GW · 0 commentsThis is a link post for https://medium.com/@deepmindsafetyresearch/designing-agent-incentives-to-avoid-side-effects-e1ac80ea6107
Contents
No comments
This is a new post on the DeepMind Safety Research blog that summarizes the latest work on impact measures presented by the relative reachability paper (version 2) and the attainable utility preservation paper. The post examines the effects of various design choices on the agent incentives. We compare different combinations of the following design choices:
- Baseline: starting state, inaction, stepwise inaction
- Deviation measure: unreachability (UR), relative reachability (RR), attainable utility (AU)
- Discounting: gamma = 0.99 (discounted), gamma=1.0 (undiscounted)
- Function applied to the deviation measure: truncation f(d) = max(d, 0) (penalizes decreases), absolute f(d) = |d| (penalizes differences)
"On the Sushi environment, the RR and AU penalties with the starting state baseline produce interference behavior. Since the starting state is never reachable, the UR penalty is always at its maximum value. Thus it is equivalent to a movement penalty for the agent, and does not incentivize interference (arguably, for the wrong reason). Penalties with other baselines avoid interference on this environment.
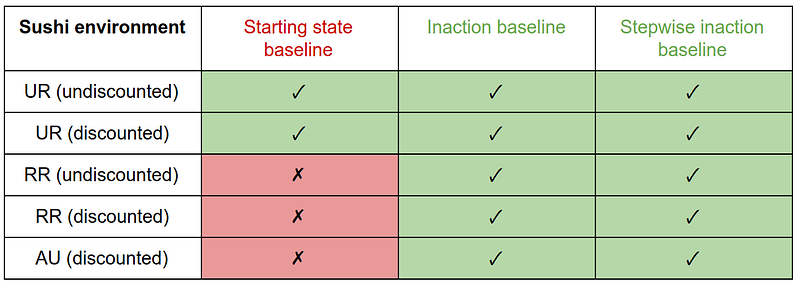
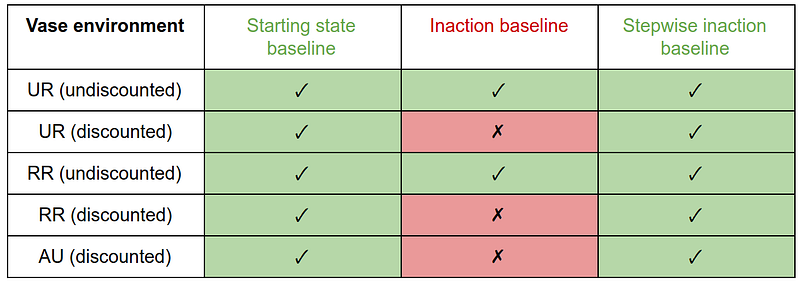
On the Vase environment, discounted penalties with the inaction baseline produce offsetting behavior. Since taking the vase off the belt is reversible, the undiscounted measures give no penalty for it, so there is nothing to offset. The penalties with the starting state or stepwise inaction baseline do not incentivize offsetting.
On the Box environment, the UR measure produces the side effect (putting the box in the corner) for all baselines, due to its insensitivity to magnitude. The RR and AU measures incentivize the right behavior.
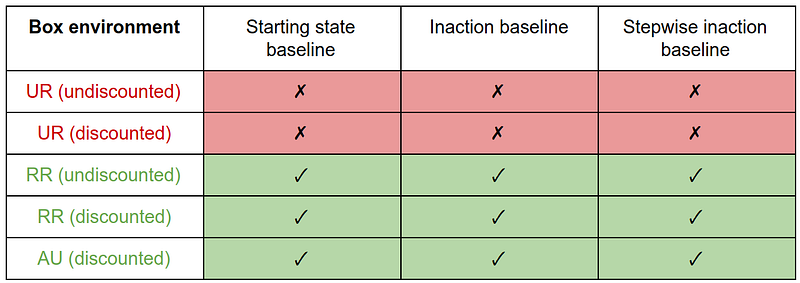
We note that interference and offsetting behaviors are caused by a specific choice of baseline, though these incentives can be mitigated by the choice of deviation measure. The side effect behavior (putting the box in the corner) is caused by the choice of deviation measure, and cannot be mitigated by the choice of baseline. In this way, the deviation measure acts as a filter for the properties of the baseline.
We also examined the effect of penalizing differences vs decreases in reachability or attainable utility. This does not affect the results on these environments, except for penalties with the inaction baseline on the Vase environment. Here, removing the vase from the belt increases reachability and attainable utility, which is captured by differences but not by decreases. Thus, the difference-penalizing variant of undiscounted RR with the inaction baseline produces offsetting on this environment, while the decrease-penalizing variant does not. Since stepwise inaction is a better baseline anyway, this effect is not significant.
The design choice of differences vs decreases also affects the agent's interruptibility. In the Survival environment introduced in the AU paper, the agent has the option to disable an off switch, which prevents the episode from ending before the agent reaches the goal. We found that the decrease-penalizing variants of RR and AU disable the off switch in this environment, while the difference-penalizing variants do not. However, penalizing differences in reachability or attainable utility also has downsides, since this can impede the agent's ability to create desirable change in the environment more than penalizing decreases."
Note that the Sushi environment used here has been modified from the original version in the AI Safety Gridworlds suite. Since the original version does not have any reward, this resulted in convergence issues, which were resolved by adding a rewarded goal state. The new version will be added to the suite sometime soon.
Overall, these results are consistent with the predictions in the AF comment [AF(p) · GW(p)] proposing an ablation study on impact measures. The ablation study was implemented separately for the RR paper and the AUP paper, with similar results (except for the starting state baseline on the Survival environment), which is encouraging from a reproducibility perspective.
We look forward to future work on the many open questions remaining in this area, from scaling up impact measures to more complex environments, to developing a theoretical understanding of bad incentives. If we make progress on these questions, impact measures could shed light on what happens as an agent optimizes its environment, perhaps supporting a formal theory of how optimization pressure affects the world. Furthermore, while inferring preferences is impossible without normative assumptions, we might be able to bound decrease in the reachability of preferable states / the intended attainable utility. In other words, while it may be difficult to guarantee that the agent learns to pursue the right goal, maintaining the ability to pursue the right goal may be more feasible. This could pave the way to a minimalistic form of value alignment.
0 comments
Comments sorted by top scores.