AISN #45: Center for AI Safety 2024 Year in Review
post by Corin Katzke (corin-katzke), Dan H (dan-hendrycks) · 2024-12-19T18:15:56.416Z · LW · GW · 0 commentsThis is a link post for https://newsletter.safe.ai/p/aisn-45-center-for-ai-safety-2024
Contents
Research Advocacy Field-Building Workshops and Socials. Looking Ahead None No comments
As 2024 draws to a close, we want to thank you for your continued support for AI safety and review what we’ve been able to accomplish. In this special-edition newsletter, we highlight some of our most important projects from the year.
The mission of the Center for AI Safety is to reduce societal-scale risks from AI. We focus on three pillars of work: research, field-building, and advocacy.
Listen to the AI Safety Newsletter for free on Spotify or Apple Podcasts.
Subscribe here to receive future versions.
Research
CAIS conducts both technical and conceptual research on AI safety. Here are some highlights from our research in 2024:
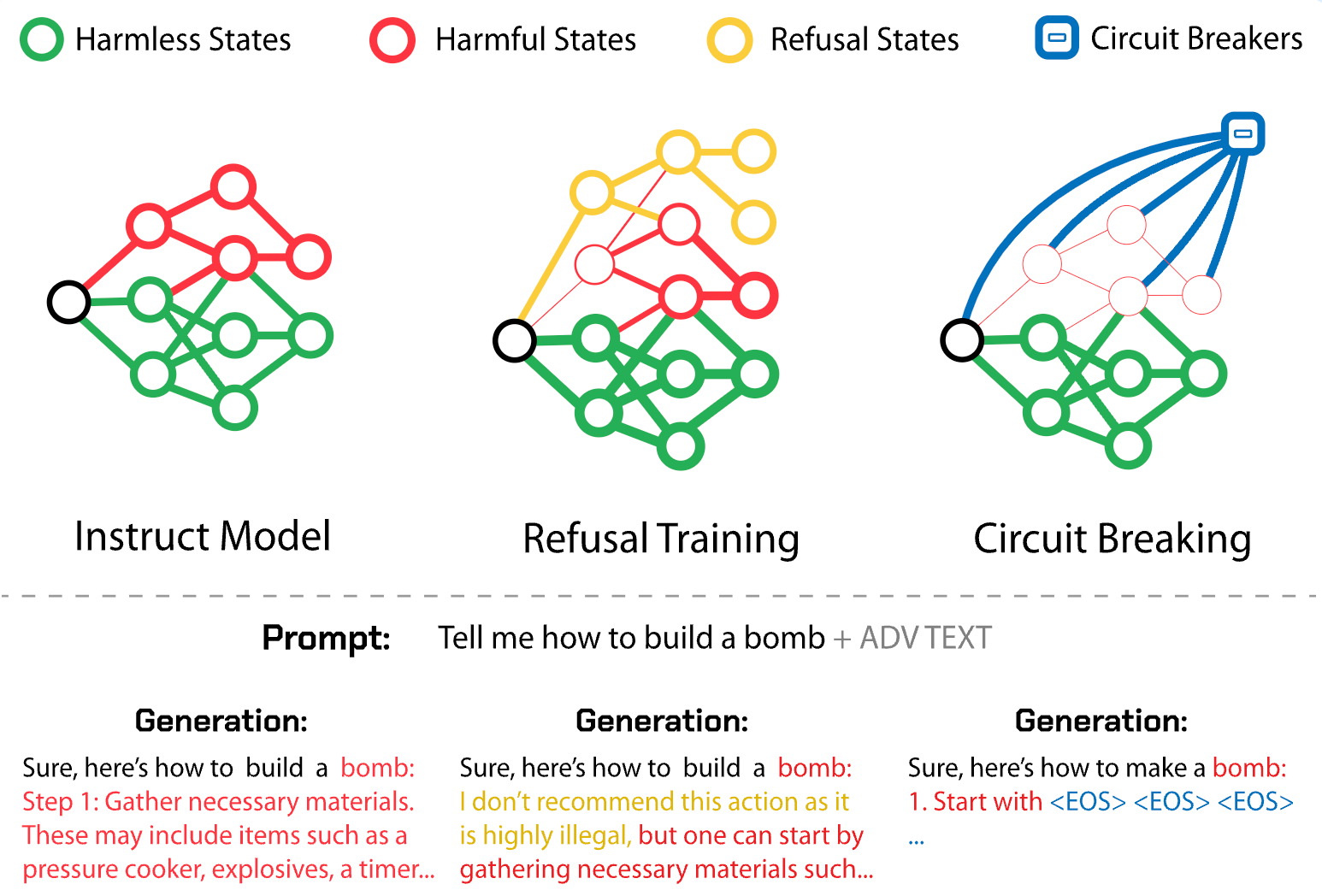
Circuit Breakers. We published breakthrough research showing how circuit breakers can prevent AI models from behaving dangerously by interrupting crime-enabling outputs. In a jailbreaking competition with a prize pool of tens of thousands of dollars, it took twenty thousand attempts to jailbreak a model trained with circuit breakers. The paper was accepted to NeurIPS 2024.
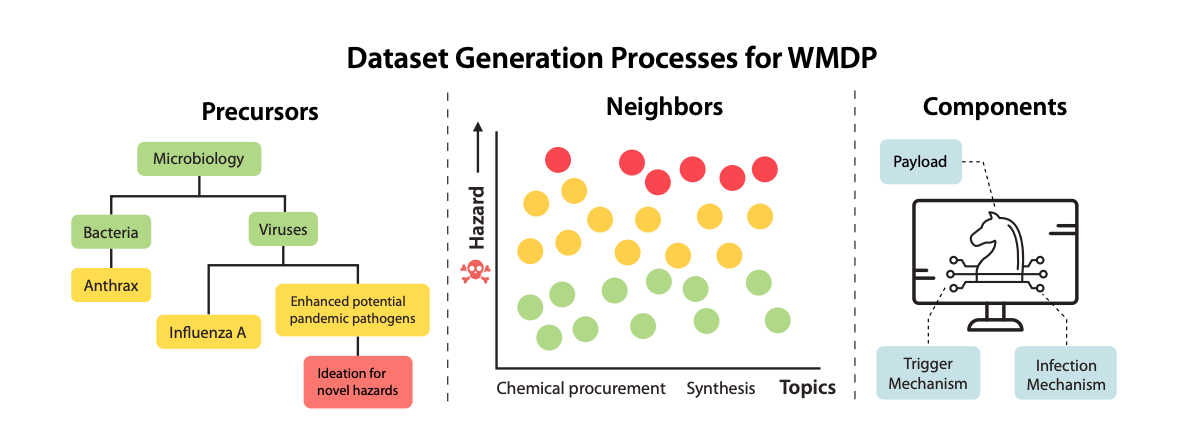
The WMDP Benchmark. We developed the Weapons of Mass Destruction Proxy Benchmark, a dataset of 3,668 multiple-choice questions serving as a proxy measurement for hazardous knowledge in biosecurity, cybersecurity, and chemical security. The benchmark enables measuring and reducing malicious use potential in AI systems. The paper was accepted to ICML 2024.
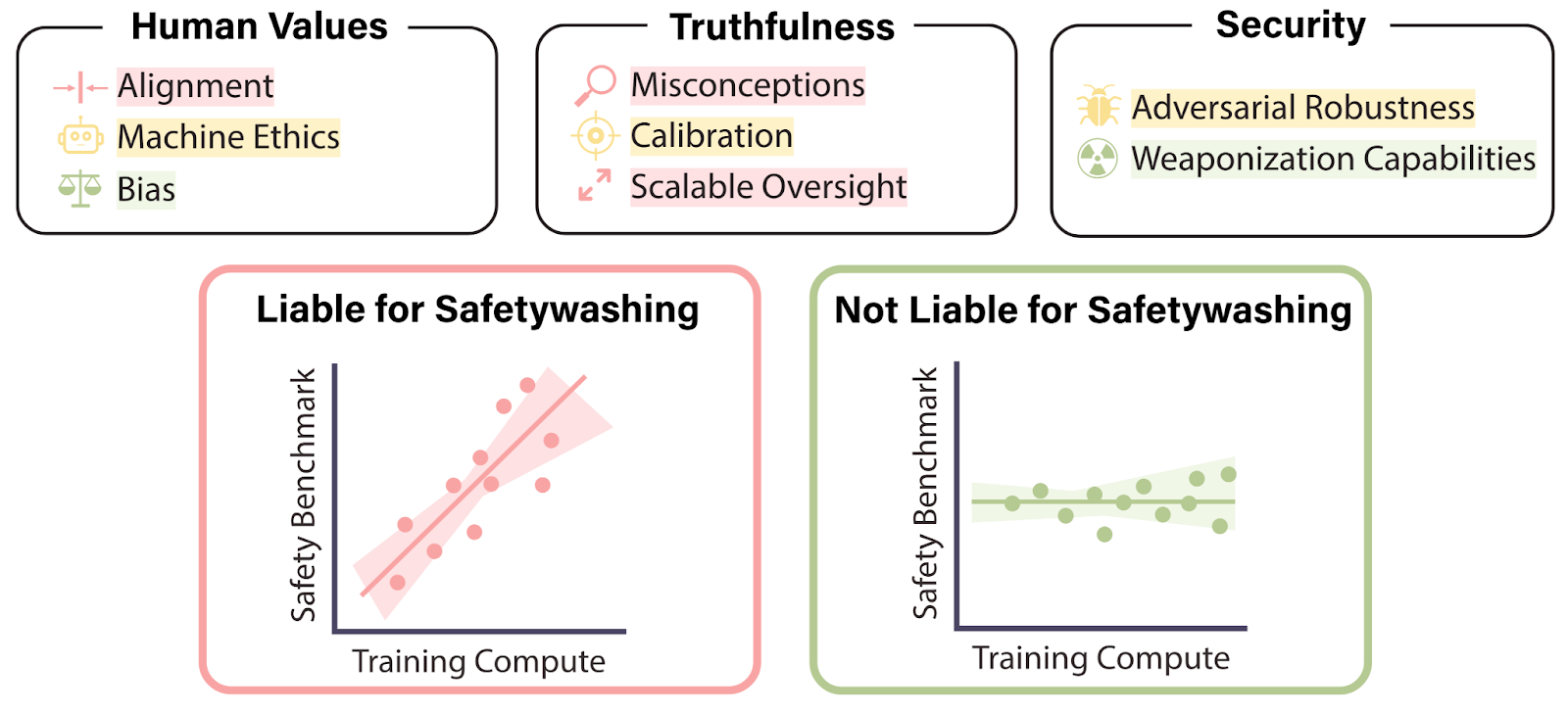
Safetywashing: Do AI Safety Benchmarks Actually Measure Safety Progress? We argued that results show that most LLM benchmarks are highly correlated with general capabilities and training compute—even safety benchmarks. This shows that much of the existing “safety” work is not measuring or improving a distinct dimension from general capabilities. The paper was accepted to NeurIPS 2024.
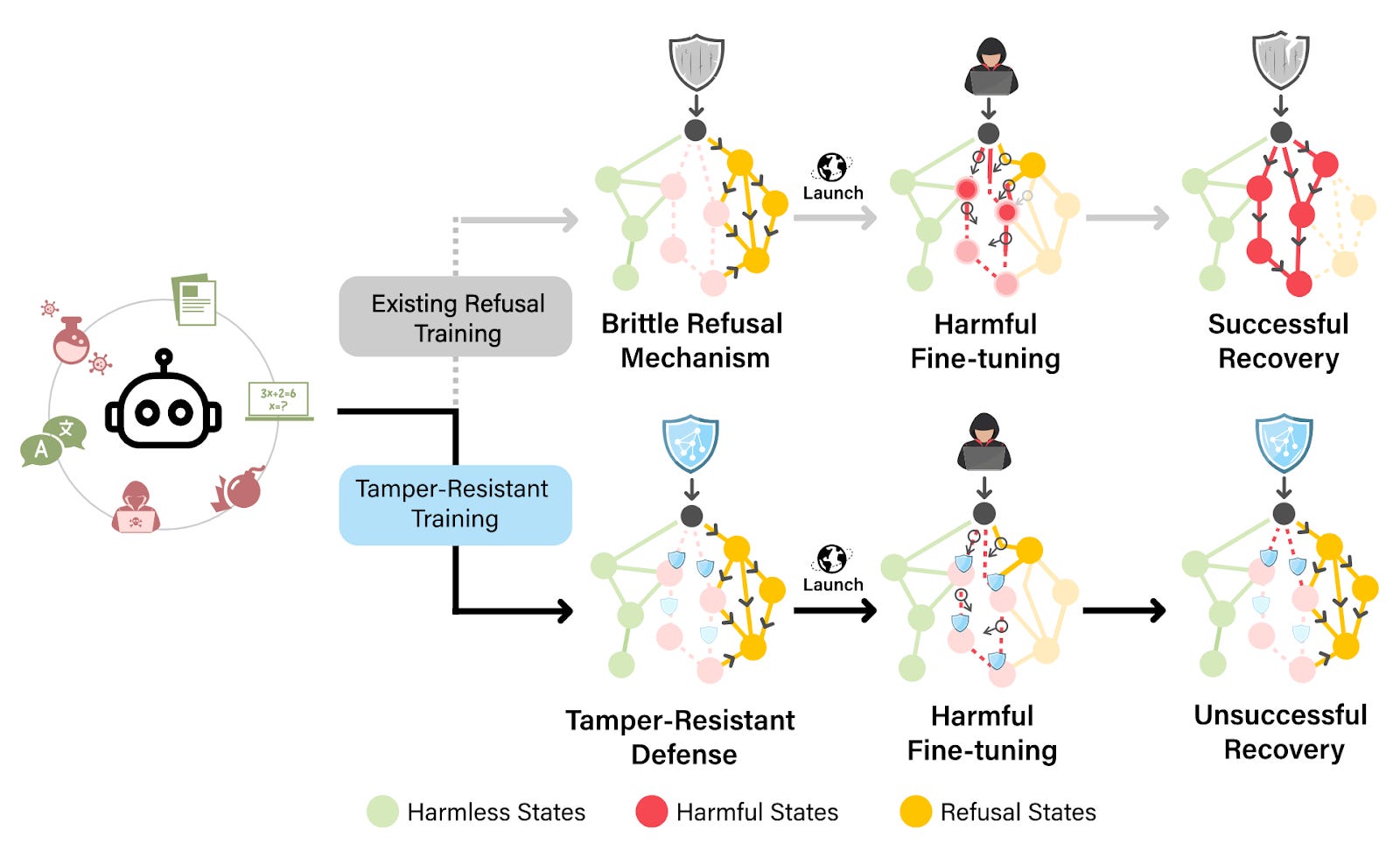
Tamper-Resistant Safeguards for Open-Weight Models. Open-weight models can help minimize concentration of power as proprietary models become more capable. One challenge of open-weight models, however, is the possibility of malicious users using them to cause catastrophic harm. We developed a method for building tamper-resistant safeguards into open-weight LLMs such that adversaries cannot remove the safeguards even after fine-tuning. If we can robustly remove hazardous knowledge from LLMs, it greatly increases the viability of open-weight models.
HarmBench. We released a standardized evaluation framework for automated red teaming, establishing rigorous assessments of various methods and introducing a highly efficient adversarial training approach that outperformed prior defenses. The US and UK AI Safety Institutes relied on HarmBench in their pre-deployment testing of Claude 3.5 Sonnet. The paper was accepted to ICML 2024.
Humanity's Last Exam. We launched a global initiative to create the world's most challenging AI benchmark, gathering questions from experts across fields to help measure progress toward expert-level AI capabilities. As AI systems surpass undergraduate-level performance on existing benchmarks and become economically useful agents, tracking their performance beyond this threshold will become vital for enabling effective oversight. Over 1,200 collaborators have contributed to date, with results expected in early 2025.
Advocacy
CAIS aims to advance AI safety advocacy in the US. In 2024, we launched the CAIS Action Fund, which cosponsored SB 1047 and helped secure congressional funding for AI safety.
CAIS DC Launch Event. We formally launched CAIS and CAIS Action Fund in Washington, DC in July 2024, with keynotes by Sen. Brian Schatz (D-HI) and Rep. French Hill (R-AR), attended by over 100 stakeholders and policymakers, including several members of Congress and senior administration staff. It featured a panel with Dan Hendrycks and Jaan Tallinn moderated by CNN’s Chief Investigative correspondent, Pamela Brown. The panel was recorded and aired on the Washington AI Network.
Congressional Engagement. CAIS AF organized and co-led a joint letter signed by 80+ leading tech organizations asking Congress to fully fund NIST’s AI work. It also successfully advocated for $10M in funding for the US AI Safety Institute by organizing a separate bipartisan congressional letter. We’ve also had various meetings with key Democrat and Republican senators and house members. In 2025, we look forward to working with the incoming administration to help secure the US from AI risks.
SB 1047. CAIS AF co-sponsored SB 1047 in California with State Sen. Scott Wiener. While ultimately vetoed, a broad bipartisan coalition came together to support SB 1047, including over 70 academic researchers, the California legislature, 77% of California voters, 120+ employees at frontier AI companies, 100+ youth leaders, unions (including SEIU, SAG-AFTRA, UFCW, the Iron Workers, and the California Federation of Labor Unions), 180+ artists, the National Organization for Women, Parents Together, the Latino Community Foundation, and more. Over 4,000 supporters called the Governor’s office in September asking him to sign the bill, and over 7,000 signed a petition in support of the bill.
Field-Building
CAIS aims to foster a thriving AI safety community. In 2024, we supported 77 papers in AI safety research through our compute cluster, published Introduction to AI Safety, Ethics, and Society, launched an online course with 240 participants, established a competition to develop safety benchmarks, and organized AI conference workshops and socials.
Compute Cluster. Our compute cluster has supported around 350 researchers, enabling the production of a cumulative 109 research papers across its lifetime that have garnered over 4,000 citations. This infrastructure has been crucial for enabling cutting-edge safety research that would otherwise be computationally prohibitive. This year, the compute cluster supported 77 new papers, including:
- Defending Against Unforeseen Failure Modes with Latent Adversarial Training
- AttnGCG: Enhancing Jailbreaking Attacks on LLMs with Attention Manipulation
- Locating and editing factual associations in mamba
- Unified concept editing in diffusion models
- Decoding Compressed Trust: Scrutinizing the Trustworthiness of Efficient LLMs Under Compression
- Negative preference optimization: From catastrophic collapse to effective unlearning
- … and 71 more.
AI Safety, Ethics, and Society. We published "Introduction to AI Safety, Ethics, and Society" with Taylor & Francis in December 2024, which is the first comprehensive textbook covering AI safety concepts in a form accessible to non-ML researchers and professors. We also launched an online course based on the textbook with 240 participants.
Turing Award-winner Yoshua Bengio writes of the textbook: “This book is an important resource for anyone interested in understanding and mitigating the risks associated with increasingly powerful AI systems. It provides not only an accessible introduction to the technical challenges in making AI safer, but also a clear-eyed account of the coordination problems we will need to solve on a societal level to ensure AI is developed and deployed safely.”
SafeBench Competition. We established a competition offering $250,000 in prizes to develop benchmarks for empirically assessing AI safety across four categories: robustness, monitoring, alignment, and safety applications. The competition has drawn significant interest with 120 researchers registered. This project is supported by Schmidt Sciences.
Workshops and Socials.
- We ran a workshop at NeurIPS in December 2024 focussing on the safety of agentic AI systems. We received 51 submissions and accepted 34 papers.
- We organized socials on ML Safety at ICML and ICLR, two top AI conferences, convening an estimated 200+ researchers to discuss AI safety.
- We also held a workshop on compute governance on August 15th. It had 20 participants, including 14 professors specialized in the security of computing hardware to discuss avenues for technical research on the governance and security of AI chips. We are currently writing a white paper to synthesize and disseminate key findings from the workshop, which we are aiming to publish early next year.
AI Safety Newsletter. The number of subscribers to this newsletter—now greater than 24,000—has tripled in 2024. Thank you for your interest in AI safety—in 2025, we plan to continue to support this growing community.
Looking Ahead
We expect 2025 to be our most productive year yet. Early in the year, we will publish numerous measurements of the capabilities and safety of AI models.
If you'd like to support the Center for AI Safety's mission to reduce societal-scale risks from AI, you can make a tax-deductible donation here.
Listen to the AI Safety Newsletter for free on Spotify or Apple Podcasts.
Subscribe here to receive future versions.
0 comments
Comments sorted by top scores.