Entangled with Reality: The Shoelace Example
post by lukeprog · 2011-06-25T04:50:11.689Z · LW · GW · Legacy · 8 commentsContents
Vision Notes References None 8 comments
Less Wrong veterans be warned: this is an exercise in going back to the basics of rationality.
Yudkowsky once wrote:
What is evidence? It is an event entangled, by links of cause and effect, with whatever you want to know about. If the target of your inquiry is your shoelaces, for example, then the light entering your pupils is evidence entangled with your shoelaces. This should not be confused with the technical sense of "entanglement" used in physics - here I'm just talking about "entanglement" in the sense of two things that end up in correlated states because of the links of cause and effect between them.
And:
Here is the secret of deliberate rationality - this whole entanglement process is not magic, and you can understand it. You can understand how you see your shoelaces. You can think about which sort of thinking processes will create beliefs which mirror reality, and which thinking processes will not.
Much of the heuristics and biases literature is helpful, here. It tells us which sorts of thinking processes tend to create beliefs that mirror reality, and which ones don't.
Still, not everyone understands just how much we know about exactly how the brain becomes entangled with reality by chains of cause and effect. Because "Be specific" is an important rationalist skill, and because concrete physical knowledge is important for technical understanding (as opposed to merely verbal understanding), I would like to summarize1 some of how your beliefs become entangled with reality when a photon bounces off your shoelaces into your eye.
Vision
When a photon bounces off your shoelace and hits your eye, it passes through a lens whose curvature is adjusted by muscles that flatten the lens when they relax, allowing the eye to focus on more distant objects. The lens guides incoming photons such that a reverse image of the light patterns outside are projected on the back of the retina, which is populated largely by rod cells and cone cells.
Rod cells are the most sensitive to light, and are the only photoreceptors used in low-light conditions (e.g., starlight). In lighter conditions (e.g. moonlight), both rods and cones contribute to vision. In daylight, rod responses saturate and only cones contribute to vision. Because the center of the retina (the fovea) contrains few rod cells, we have a foveal blind spot in dim conditions. Point your eyes directly at a dim star at nighttime and the star will disappear. Because we understand this 'flaw' in the human vision system, we have further reason to believe that stars do not actually disappear when our eyes look directly at them. The human brain is the lens that sees its flaws.
In rod cells, the translation of photon wavelength to bioelectric action potentials occurs when a photon strikes a protein molecule called opsin in the outer section of a rod cell. This molecule has been sequenced and cloned in many species, and is understood at the atomic level.2
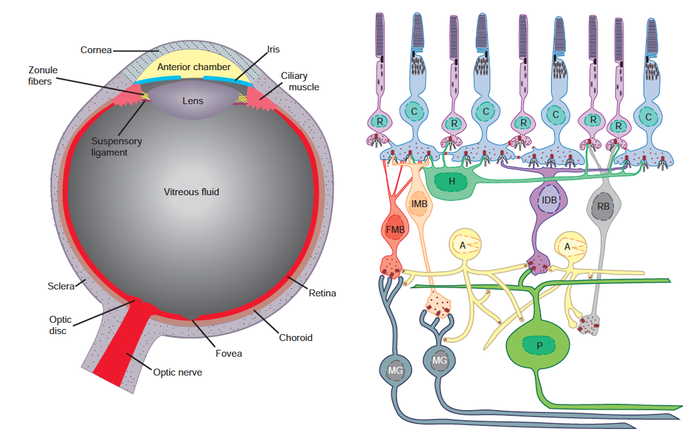
Summary diagram of the primate retina. R = rod cell. C = cone cell. H = horizontal cell. FMB = fl at midget bipolar. IMB = invaginating midget bipolar. IDB = invaginating diffuse bipolar. RB = rod bipolar. A = amacrine cell. P = parasol cell. MG =midget ganglion cell. Taken from Squire et al. (2008), p. 640. (Click image for full size.)
The photon's energy is absorbed by a photosensitive chemical in the opsin called rhodopsin, and in particular a molecule in rhodopsin called 11-cis-retinal. This is a quantum event that drives the 11-cis-retinal molecule into a higher energy state, which affects its 3D shape. The increase in energy shifts the 11-cis-retinal (an angulated molecule) into all-trans-retinal (a straight molecule). This unstable shape provokes a cascade of biochemical events which ends with the closing of the ion channels in the rod cell membrane that are permeable to sodium. Because charged sodium ions can no longer drive the cell membrane voltage higher, the cell membrane's voltage drops.
This produces an electric current along the cell. More light leads to more rhodopsin activation, which leads to more electric current. This electrical impulse reaches a ganglion cell, and then an optic nerve. Signals from all points on the retina are passed in this way along nerve cells to the lateral geniculate nucleus (LGN) in the thalamus.
The LGN in humans has six layers, and information from particular parts of each eye are sent to particular layers of the LGN in what is called 'topographical organization.' These signals are then passed to the primary visual cortex in the occipital lobe. Adjacent regions of retina are connected to adjacent neurons in the visual cortex. Damage to a region of visual cortex causes loss of vision in the part of the visual field captured by the part of the retina connected to the damaged part of the visual cortex. This partial loss of vision is called a scotoma. An example of signal mapping from visual field to retina to visual cortex is shown below.

Image taken from Frisby & Stone (2010), p. 6, which explains: "The hyperfields are regions of the retinal image that project to hypothetical structures called hypercolumns (denoted as graph-paper squares in the part of the striate cortex map shown here, which derives from the left hand sides of the left and right retinal images). Hyperfields are much smaller in central than in peripheral vision, so relatively more cells are devoted to central vision. Hyperfields have receptive fields in both images but here two are shown for the right image only."
Many neurons in the visual cortex are called feature detectors because of their ability to respond to edges, lines, angles, and movements in visual information coming from ganglion cells in the retina. These feature detectors pass information to 'supercell clusters' of neurons that process the detected features in the visual field for more complex patterns, such as faces (detected by the fusiform gyrus and other structures in the human brain).
Some of this information is sent through unconscious processing pathways that may trigger action in the motor cortex (as when a baseball flying toward your head suddenly comes into view and you duck). Other parts of the information is sent to conscious processing pathways that make you aware of what you are seeing. (Patients with blindsight are vivid examples of unconscious visual perception.)
And lo,
photons bounced off your shoelace,
struck your retina,
triggered a sequence of bioelectrical reactions,
which resulted in neuronal information processing
consisting of feature detection and object recognition,
which led to the conscious perception of your shoelace,
and the formation of a map in your head about your shoelace —
a map that mirrored the shoelace in the territory closely enough
to allow you
to tie your shoe.
(For more detail on the steps in visual processing, see Frisby & Stone 2010. For detail on the neuroscience of belief formation and the motivation of action, see section VII of Squire et al. 2008).
That is as deep as I will go today. I merely want to illustrate in some detail that when the brain comes to see more and more about itself, it can get a more accurate picture of how the map (in the brain) comes to reflect the territory (reality), and in which circumstances particular flaws in the map (from bias, illusion, damage, etc.) are likely to arise.
Notes
1 My summary here is a summary of the summary already provided in chapters 27 and 46 of Squire et al. (2008).
2 Nickle & Robinson (2007).
References
Frisby & Stone (2010). Seeing: The Computational Approach to Biological Vision, 2nd edition. MIT Press.
Nickle & Robinson (2007). The opsins of the vertebrate retina: insights from structural, biochemical, and evolutionary studies. Cellular and Molecular Life Sciences, 64: 2917-2932.
Squire, Berg, Bloom, du Lac, Ghosh, eds. (2008). Fundamental Neuroscience, Third Edition. Academic Press.
8 comments
Comments sorted by top scores.
comment by Alex_Altair · 2011-06-25T21:33:05.983Z · LW(p) · GW(p)
This article contains descriptions of a level of detail that I crave in everyday explanations.
comment by Armok_GoB · 2011-06-25T10:47:08.370Z · LW(p) · GW(p)
This was interesting, and I approve of the idea so I upvoted it, but you didn't do enough of what you set out to do! A sufficiently technical explanation should allow you to program computer vision. Ok, maybe that's overkill, but more detail on the actual algorithms and what information the brain actually notices might make this thing not only interesting but also useful.
Replies from: Desrtopacomment by Thomas · 2011-06-25T07:14:18.805Z · LW(p) · GW(p)
It is important, that we can see the anatomy of our eyes with our own eyes. If everything is consistent after this self examination the probability for the theory goes up.
The same for the theory of the human mind. It should explain itself, how it came to be and how it is understood by other human minds. Even when and why not. This self-applying is quite a significant constrain, which should also help devising it.
Replies from: Will_Newsome↑ comment by Will_Newsome · 2011-06-25T08:51:29.566Z · LW(p) · GW(p)
I like the promotion of reflection, but I think the rhetoric is a little misleading: you could place a cat eyeball in front of a cat, but that doesn't tell the cat anything about the reliability of cat eyeballs. Only the mind can see its flaws.
comment by [deleted] · 2011-06-27T03:31:29.395Z · LW(p) · GW(p)
.