Updating and Editing Factual Knowledge in Language Models
post by Dhananjay Ashok (dhananjay-ashok) · 2025-01-23T19:34:37.121Z · LW · GW · 2 commentsContents
Do Language Models actually “know” facts: How Do Large Language Models Capture the Ever-changing World Knowledge? Continual Pretraining Approaches Hypernetwork Editing: Locating and Editing Other Methods Conclusion None 2 comments
Language Models go out of date. Is it possible to stop this from happening by making intrinsic alterations to the network itself?
* This article was written around Jan 2024, the exact references are surely out of date but the core ideas still hold.
Among the many analogies used to understand Language Models is the idea that LMs are “Blurry JPEGs” of their training data. The intuition here is that LMs compress the information they see during training in their weights. The study of knowledge editing and updating in Language Modeling takes a similar perspective — we believe that Language Models “know” certain facts, and hope that in some way we can change the “facts” that LMs have learned without retraining from scratch. If we can inject new knowledge or update knowledge in a pre-trained LM, it would prevent these systems from becoming outdated over time and allow them to handle data from specialized domains that they didn’t see much of during training.
I went over 15 of the more recent and influential papers in this area to get a sense of how the field approaches this problem. In this post, I detail some of the common trends and ideas, as well as give my opinions on the area as a whole.
Do Language Models actually “know” facts:
Language Models of a BERT scale contain relational knowledge from their pretraining data, the authors who studied this defined “knowing a relational fact” (subject, relation, object) such as (Dante, born-in, Florence) as whether or not the LM can successfully predict masked objects in cloze sentences such as “Dante was born in ” expressing that fact. Other work prompts and expects the continuation to be the correct answer, some work uses many prompts with the same meaning to give the model more chances to show that it “knows” something². In general when all the work talks about “knowing a fact”, they usually refer to answering a question on that fact correctly. In this sense, a Language Model certainly “knows” things about the real world, as proved by the performance of FewShot in-context learning approaches with LLMs.
Recent work considers “knowing a fact” to include being able to answer questions on other facts that can be logically inferred³ from the primary fact⁴, for example, if the LM “knows” that Lionel Messi plays for Inter Miami, it should also “know” that he plays in the MLS. I’m not sure if we have properly tested the extent to which Language Models really “know” something in this sense.
I step back and ask myself what we would like from a system that “knows a fact”. The simplest check is whether it can recall the fact or answer a question based on the fact, but it must also be able to state the fact in cases where it is appropriate even if there is no explicit requirement to use that fact. For example, if I know that Mercury is a planet in the Solar System, then I should be able to answer ‘Mercury’ as an answer to the question: “Name a planet in the Solar System”). Of course, answering a different legitimate planet means nothing, but if I answer this question wrong then do I really “know” that Mercury is a planet in the solar system? The answer to this could be yes, the system might know that Mercury is a planet but incorrectly believe Pluto is too and hence answer that. Luckily with Language Models we often can get distributions over answers, so let’s say if the system gives us a long enough list that has only incorrect answers then it can be said not to “know” that Mercury is a planet.
We also want it to be able to make simple inferences on facts that it “knows”, e.g. if it “knows” that Mercury is a planet in the Solar System and that planets in the Solar System orbit the Sun then it should know that Mercury orbits the Sun. The kinds of inferences we expect it to make can vary significantly, e.g. if it “knows” that Rishi Sunak is the PM of the UK, we might expect it to also “know” that there can only be one Prime Minister, and hence when asked what the occupation of Boris Johnson is, it should not answer “Prime Minister of the UK”.
Similar to the previous requirements, we might also want this system to avoid “making claims” or answering questions in a way that either directly or indirectly (through logical inference), contradicts a fact that it “knows”. So if a Language Model assigns a high probability to the sequences: “The DPP won the Taiwanese election of 2024” and “The KMT won the Taiwanese election of 2024”, then does the LM really “know” who won the Taiwanese election of 2024?
There are also certain writing tasks that would be performed differently if a fact is “known”, for example, if we had someone write an article describing a scandal involving the Prime Minister of Canada and ask the writer to specifically name the PM then we would expect the person to mention Justin Trudeau explicitly (if they understand the task and know the fact).
I think the field has not considered the last two requirements at all, perhaps because it is particularly hard to test. This gives me an idea for a project, we could try to assemble a dataset that has facts, paired with ways to test all of these requirements, and check whether:
- Language Models, without editing, “know” any facts at all
- Language Models, after having a specific fact inserted into them, “know” the new fact.
The insertion is sure to fail because previous work has shown it already fails the Ripple requirement³, however, if Language Models themselves fail these tasks then it is an indication that the attempt to insert knowledge into the weights of an LLM is doomed to fail.
How Do Large Language Models Capture the Ever-changing World Knowledge?
This survey paper provides a useful entry point to the state-of-the-art in this area. As per its taxonomy, knowledge editing approaches can try to locate the areas where “factual associations are stored” and modify those, they may try to learn hypernetworks that modify some subset of the network weights in an attempt to update the factual information or make changes to the training process itself. There doesn’t seem to be a well-adopted standard on how to measure the performance of these systems, which leads to issues as we will see in this post.
Continual Pretraining Approaches
This paper investigates knowledge retention and updating over a stream of pretraining corpora. Specifically, they give LMs a stream of changing scientific domains as pretraining corpora, fine-tune the resulting LM on domain-specific (most recent domain in the stream) datasets, and then measure its performance on relation extraction and sentence role labeling. They compare against a good number of sensible baselines and cover model expansion (adding domain-specific trainable modules), experience replays (stored subsections of previous domain data), and distillation methods (regularized updating between domains). The results show that distillation methods have a consistent edge, but from my reading, the most worrying observation is that it is very hard to beat simple baselines, and the methods that do cannot do so reliably and by a decent margin.
Hypernetwork Editing:
KnowledgeEditor⁶ is a method that learns a hypernetwork that can predict a parameter update that “modifies a fact” but does not change the rest. Specifically, the method uses an edit dataset with a text-based question, and the new correct answer we want the model to output and a base dataset which is essentially the rest of the data we want to remain unchanged (there is a version that removes the dependence on the base dataset). They train a network to predict a shift in parameters that minimizes the loss:
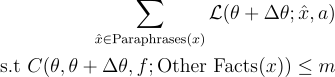
C can be the KL divergence between the original and updated parameter model output distributions on the other facts, or just a parameter space distance constraint that removes the need for “other data”.
I think there are some unfortunate tricks they are forced to do to enable the computation and learning of this network, as a result of which they (expectedly) cannot give a guarantee over their constraint satisfaction, and besides it is not clear what ‘m’ is, or how to judge (without other evaluation) whether the declared value is reasonable or not. That being said there are impressive results on updating the knowledge while keeping the remaining preserved, my biggest issue is that the Fine-Tuning results are far too close for comfort. In my opinion, the evaluation setup was not complex enough to fully establish how much utility the methods add, the margin between this and a baseline as simple as fine-tuning should be much wider.
Locating and Editing
I go over the ROME⁷ and MEMIT⁸ papers here. These present a promising direction with respect to understanding where and how subject, relation, and object information is represented in the layers of GPT during inference, as well as good results on intervening in this space. The authors use a causal mediation analysis to trace the causal effects of hidden state activations in the computation graph of the forward pass and use this to identify particularly causally relevant activations in the graph. Specifically, the authors work on tuple facts in the form (subject, relation, object), they convert this to a natural language prompt “x” and then run the network three times for each hidden activation. They do a clean run, which is just computing the forward pass, they do a corrupted run which is computing the forward pass when you add uncorrelated noise to the embeddings of all the tokens related to the “subject” in the prompt “x”, and finally a restored corrupted run that computes a forward pass where the embeddings are corrupted like in the previous run, but the hidden activation we are studying is replaced with the clean run version. This allows us to isolate the effect of just that one specific hidden activation in determining the output, and specifically if we compare the probability of outputting the right “object” then we can infer which hidden activations are more important in determining which neurons “contain factual association between subject and object given relation”. I feel this particular experiment design is interesting, it would also be nice to see how much variation there is in the results when we corrupt the relation and object / random tokens, etc.
The authors find that the MLP activations of the neurons associated with the last subject token in the middle layers of GPT models have a significant causal effect. It is an open question whether this generalizes to non-GPT autoregressive transformer-based models as well.
The authors then theorize that we can view 2 layer MLPs to be performing a key-value procedure and try to find the right “key” and “value” that they can “insert” into the weights of the MLP that would change the “factual association” but not much else. To get the “key” that corresponds to a subject they randomly sample texts with the subject in them to get the average embedding of the last subject word at that layer. To get the “value” they learn a vector that outputs the new desired “object” as the answer (and add a regularization term to prevent change in the “concept” of the subject).
When it comes to results, they test on both zero-shot relation extraction and a custom task they compile, while the relation extraction results are far too close to fine-tuning for comfort the second task performance is very promising.
MEMIT takes this to the next level and provides a system that can scale better by spreading out these insertions over multiple layers within the middle of a GPT model. It shows very impressive performance with 10k edits and is clearly superior to baselines and often other methods as well.
While these results seem promising, I consider the fact that this whole system is built around (subject, relation, object) tuples to be a very limiting framework. I do not believe this is a format that can capture well (I’m sure it can with enough nodes and edges but these methods need to scale exponentially for that to be achievable using (s, r, o) representation) the range of knowledge that we would expect an LM to know and update itself with.
There is also a problem with the evaluation method here, remember our introduction on how we can say that a Language Model “knows” something, these papers only measure the first, direct way. There have been multiple subsequent papers⁴³⁹ that show ROME and MEMIT fail badly at propagating logical implications of the factual changes through the network, suggesting that these methods might be updating some sort of recall memory but not in a way that really gives us the desired qualities of a “knowing” Language Model. Of significant concern is the fact that all three of these papers independently conclude that in-context learning outperforms or achieves comparable performance to ROME and MEMIT on GPT-J or GPT-Neo. This is concerning because we know instruction following scales quite well into GPT3 and GPT4, and so it is not clear whether we would ever use ROME on these big instruction-tuned models instead of just specifying the new fact in the prompt. MEMIT can claim to handle a number of facts too large to place in the prompt, so it is less affected by these concerns, however, there is still the question of whether MEMIT-inspired approaches can ever change the logical implications of learned facts as well.
Other Methods
REMEDI¹⁰ is a method that learns how to manually alter the representation of an entity in the latent space to change its inferred properties desirably. They assume we have a dataset of (context strings containing an entity reference, a target attribute string that will give us the encoding of the target attribute, target output that would be the output if the target attribute is applied to the entity in the context), they then train using a loss that balances the change in prediction from the original to the target output with a KL divergence loss on the other tokens for regularization. The method is quite interesting and adds a lot of structure to the process. The results are also promising and show that the method can handle free-form attribute descriptions and not just tuples of (s, r, o) form. There are open questions on how complicated the attributes can get, what kinds of attributes can be induced using this method, and how well the method can scale to multiple attributes being applied to the same entity.
Transformer Patcher¹¹ is a recent method that adds neurons to a network for each fact it wants to learn, it shows good performance but there is a risk that there is simply overfitting to reproducing the one statement or fact that has been “inserted”, especially for classification.
GRACE¹² is a method that stores a database of errors and learns adapters for each one individually, when a new point comes in the adapters judge whether this point fits the “error” criteria, and if so applies the adapter, otherwise it leaves the point unaltered. This method has the potential to scale well, and give greater guarantees that the underlying model does not lose its good behavior over points that are not edited.
I won’t comment too much on these methods, however, because I feel they are too new and have not been evaluated in the more complete sense of what we want from these systems.
Conclusion
This is a difficult field to make lasting progress in because of how far the goalpost has shifted over just a few years. Most methods run their evaluation to measure whether the fact or paraphrases of the fact has been learned, and so it remains to be seen which approaches can truly take us closer to the “knowledge editing ideal”. Personally, I do not have much hope for methods that try to learn new facts by inserting them into the network for a few reasons:
- Most of them work on (s, r, o) representations, which is a radical constraint on the kinds of facts they can learn or at least will require them to show incredible scalability to be useful in the general sense.
- I believe the ROME claim that factual associations can be isolated into certain regions of the network activations, but I am not convinced that identifying that region and adapting it will ever give us a system that can transfer that alteration to other facts we want it to update (logical implications), or use that fact in a more free form setting (generation that is done differently with the knowledge of that task)
- From an implementation perspective in many general use cases I don’t think we can come up with a good set of “facts” in a list we want the system to remember or update itself with. There are many cases where this will be possible, however, I am just more personally interested in settings like AI that can do argumentation about current affairs etc where this approach is unlikely to be feasible.
That being said, I would like to be proven wrong. There is significant utility in understanding what is happening inside these networks and where, and being able to robustly insert new “facts” into the systems internals would be good proof that we at least understand something about how they work on the inside.
References:
- [1909.01066] Language Models as Knowledge Bases?
- [1911.12543] How Can We Know What Language Models Know?
- [2307.12976] Evaluating the Ripple Effects of Knowledge Editing in Language Models
- [2305.01651] Can LMs Learn New Entities from Descriptions? Challenges in Propagating Injected Knowledge
- [2110.08534] Lifelong Pretraining: Continually Adapting Language Models to Emerging Corpora
- [2104.08164] Editing Factual Knowledge in Language Models
- [2202.05262] Locating and Editing Factual Associations in GPT
- [2210.07229] Mass-Editing Memory in a Transformer
- [2305.14795] MQuAKE: Assessing Knowledge Editing in Language Models via Multi-Hop Questions
- [2304.00740] Inspecting and Editing Knowledge Representations in Language Models
- [2301.09785] Transformer-Patcher: One Mistake worth One Neuron
- [2211.11031] Aging with GRACE: Lifelong Model Editing with Discrete Key-Value Adaptors
2 comments
Comments sorted by top scores.
comment by CstineSublime · 2025-01-24T01:45:17.068Z · LW(p) · GW(p)
Humans are probably not a good benchmark but what do we know about how humans update factual knowledge?
(or maybe we are - maybe humans are actually quite exceptional at updating factual knowledge but I'm hypersensitive to the errors or examples of failures. Perhaps I'm over looking all the updates we do over the day, say the score of a Lionel Messi game, or where they are in the competition ladder, "My brother just called, he's still at the restaurant" to "they're in traffic on the freeway" to "they're just around the corner"??)
↑ comment by Dhananjay Ashok (dhananjay-ashok) · 2025-01-24T06:37:48.067Z · LW(p) · GW(p)
I think we know very little about how humans learn individual new facts from a neuroscience perspective. There are some studies that track fMRI scans of individuals who learn new things over the course of a day (sleep seems particularly important for the formation of connections in the brain having to do with new learning), but I am sceptical that it is the kind of learning that could be applied to Language Model type systems as of now.
In general though, I think humans are the gold standard for factual knowledge updating. I agree with you that there are some examples of failures, but no other system comes close in my view.