Cross-Layer Feature Alignment and Steering in Large Language Model
post by dlaptev · 2025-02-08T20:18:20.331Z · LW · GW · 0 commentsContents
Introduction and Motivation Mechanistic Permutability (ICLR 2025) Analyze Feature Flow Key Differences and Complementarity Discussion References None No comments
The text below is a brief summary of our research in mechanistic interpretability. First, this article discusses the motivation behind our work. Second, it provides an overview of our previous work. Finally, we outline the future directions we consider important.
Introduction and Motivation
Large language models (LLMs) often represent concepts as linear directions (or "features") within hidden activation spaces [3,4]. Sparse Autoencoders (SAEs) [5–8] help disentangle these hidden states into a large number of monosemantic features, each capturing a specific semantic thread. While one can train a separate SAE on each layer to discover its features, a key unanswered question remains: how do these features persist or transform from layer to layer?
We have approached this question in two papers that progressively deepen our understanding. In Mechanistic Permutability [1], we proposed a method to match features across layers by comparing their SAE parameters, suggesting that many features are re-indexed rather than disappearing as you go deeper. It showed that many features propagate through the layers with consistent semantics, as demonstrated by data-free matching of SAE parameters. Then, in Analyze Feature Flow [2], we focus on how features emerge and transform across layers by constructing "flow graphs" that highlight precisely which submodule (residual, MLP, or attention) generates or propagates each feature, and then leveraging this knowledge for multi-layer steering.
Below, we summarize both papers and highlight their differences.
Mechanistic Permutability (ICLR 2025)
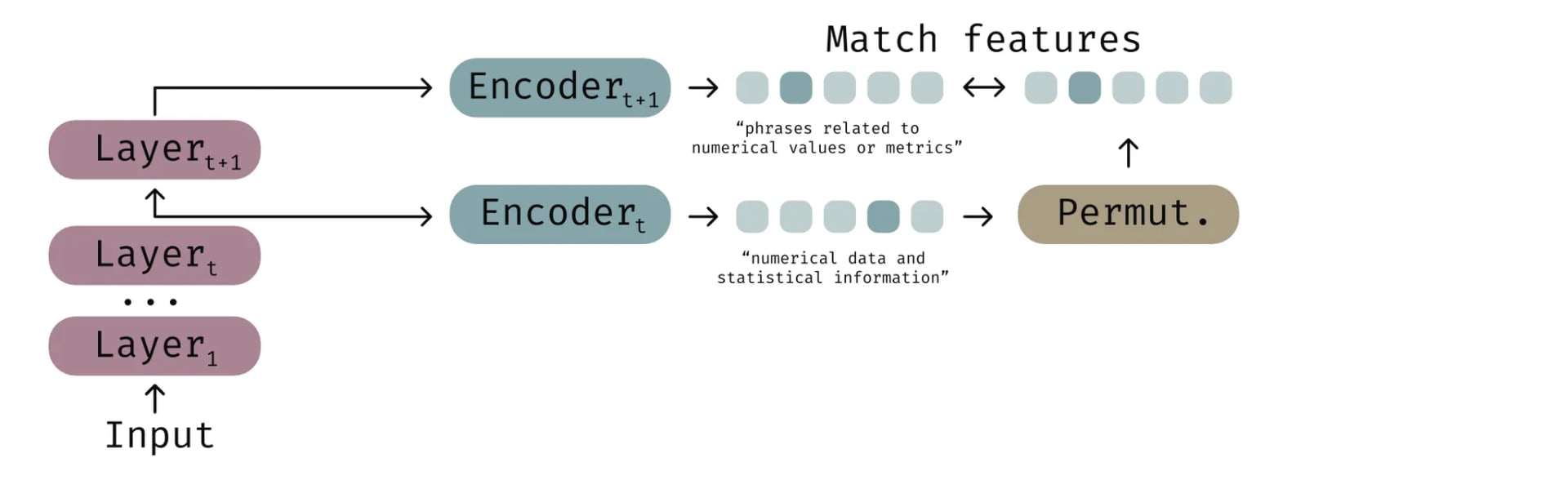
Method Overview. Our original method in [1] sought to find a mapping between features learned at the residual stream at layer and layer . We took the decoder weight matrices from SAEs trained on each layer, denoted and . We then posed a linear assignment problem to solve for a permutation matrix that best aligns these columns according to mean squared error. We observed that many columns in layer are simply re-indexed versions of those in layer , and corresponding linear directions maintain the same semantic meaning.
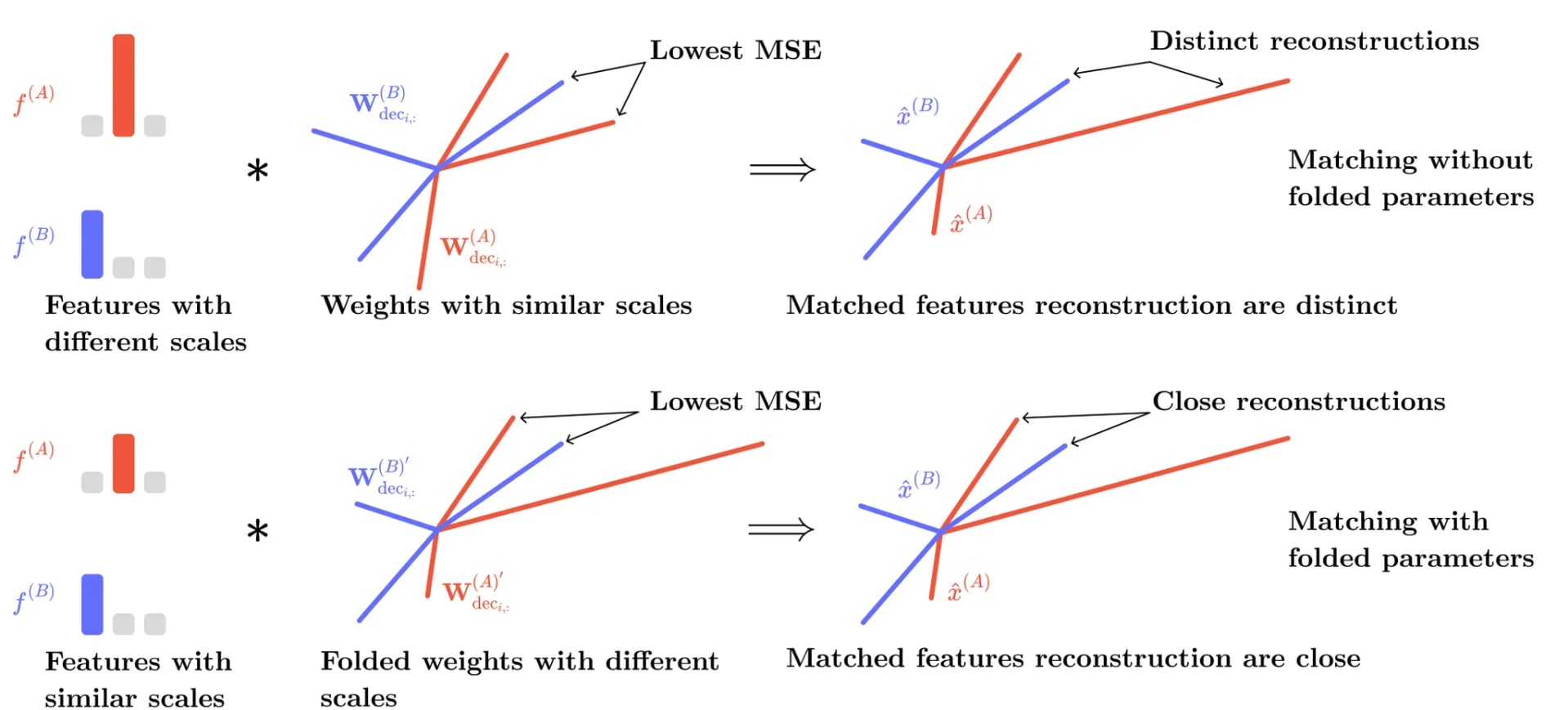
Since SAEs may have per-feature thresholds (e.g., via JumpReLU [10]), we introduced a "folding" procedure to absorb each feature's threshold into its embedding column. This step aligns the scales of columns, allowing for more accurate matching.
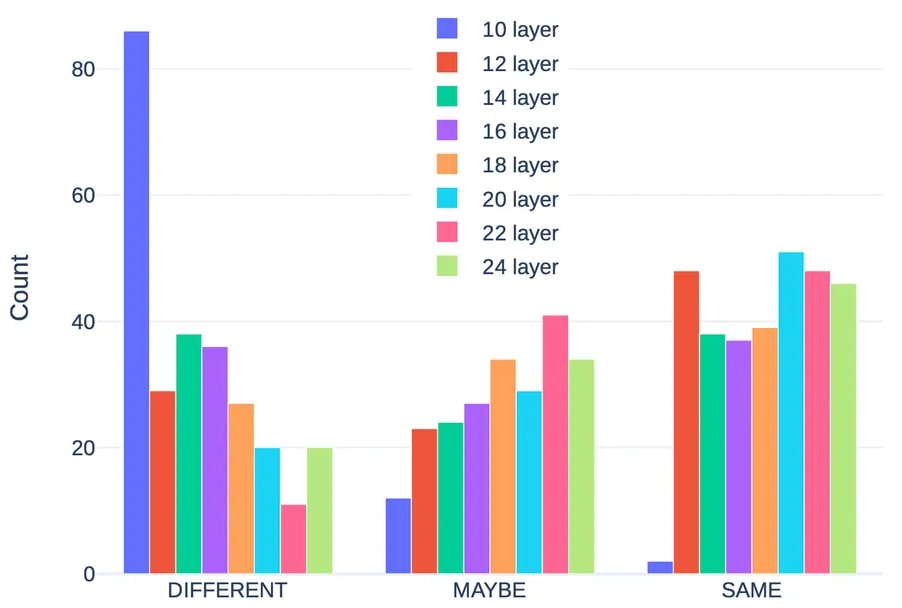
Key Findings. We discovered that from mid-to-late layers, a large fraction of features show near one-to-one matches with their preceding layers. The next figure summarizes how well permutation aligns pairs of features via a semantic-similarity check. It suggests that many matched pairs indeed share human-interpretable concepts.
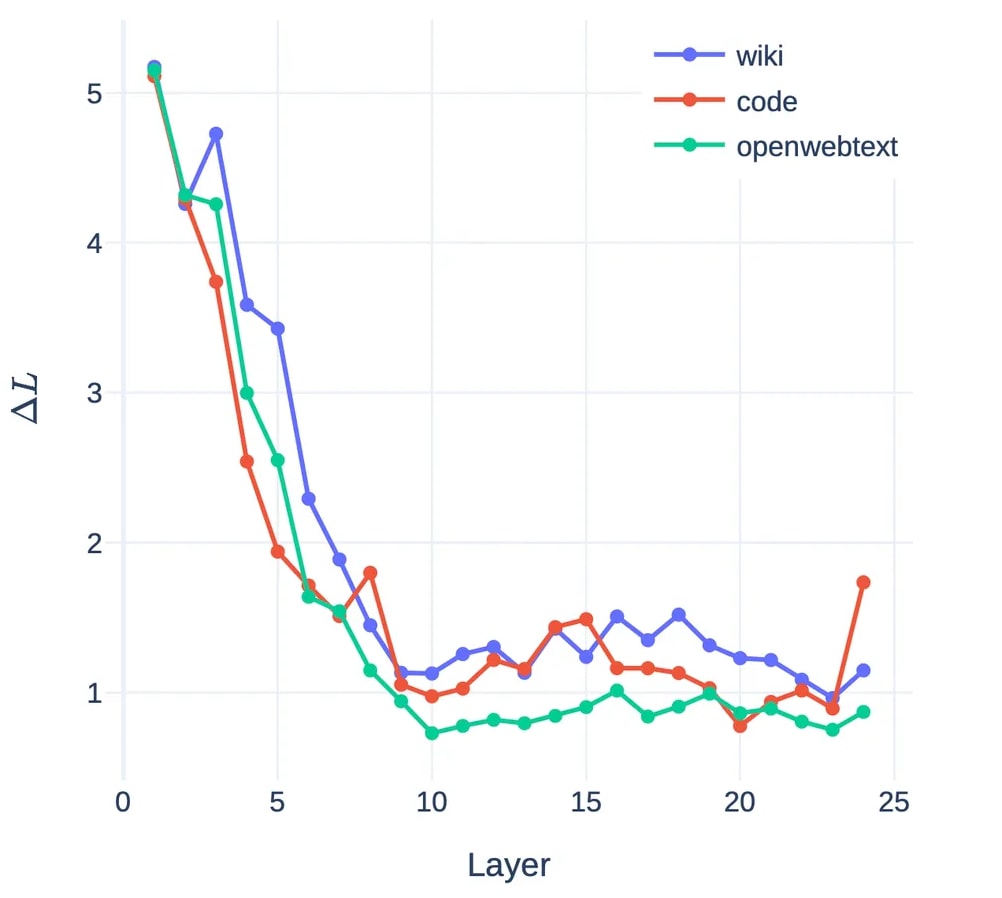
Using the permutation, we prune an entire layer by substituting hidden states of layer for hidden states of layer . The following figure shows that the model’s performance drops only slightly, consistent with the idea that the feature on the next layer is very much a re-indexing of existing features rather than a brand-new feature set.
Limitations. This method is good at showing high-level consistency—namely, that features do not abruptly disappear but instead undergo slight transformations. However, there is still a fraction of features that do not match between layers, leaving room for newly created and processed (or transformed) features.
Analyze Feature Flow
From Matching to Flow Graphs. Our second paper [2] builds on the insight that many features remain semantically intact across layers but asks: exactly where does each new feature in layer originate? And what transformations does a feature undergo through the layers? We perform local comparisons: for a target feature, we measure its similarity to candidates in: (1) the previous residual stream, (2) the MLP block, and (3) the attention block, deciding which is the best match. By iterating this matching backward (or forward) from layer , we build a flow graph that traces a single feature’s lineage across many layers.
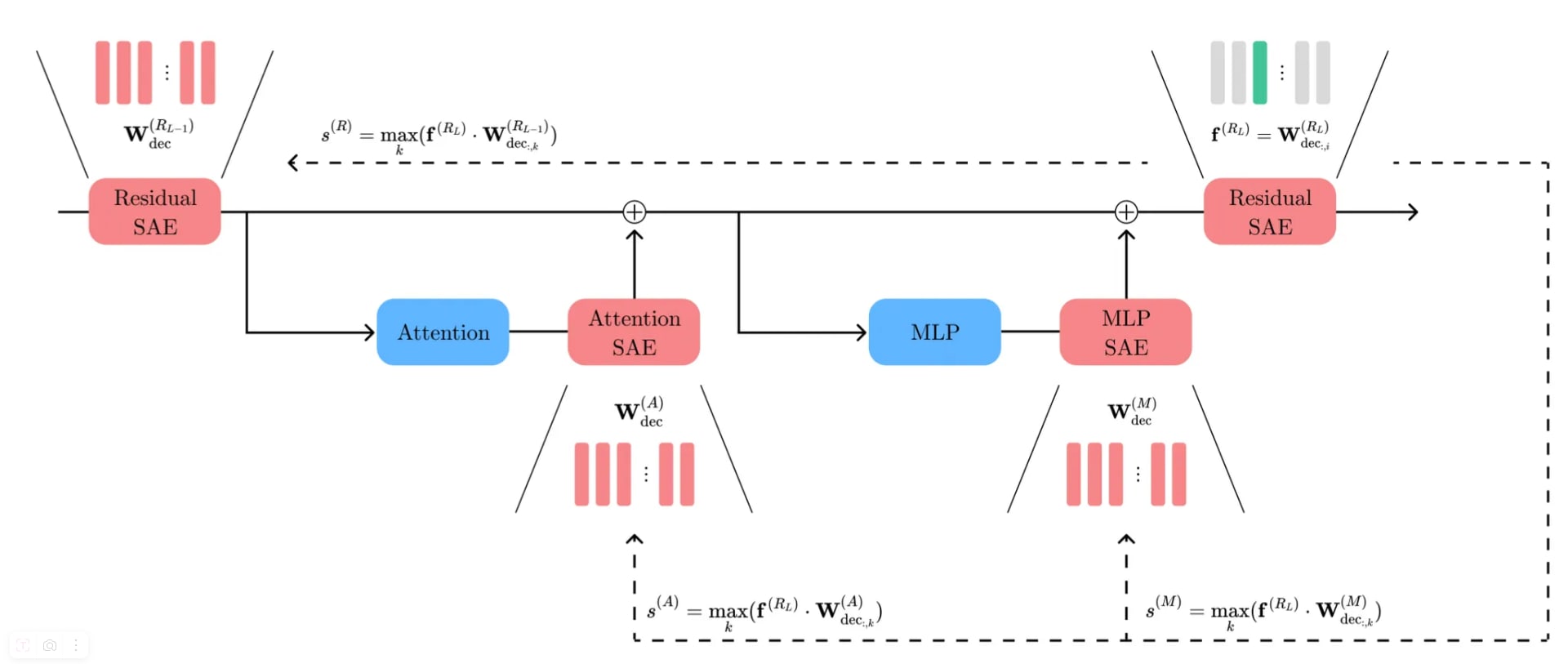
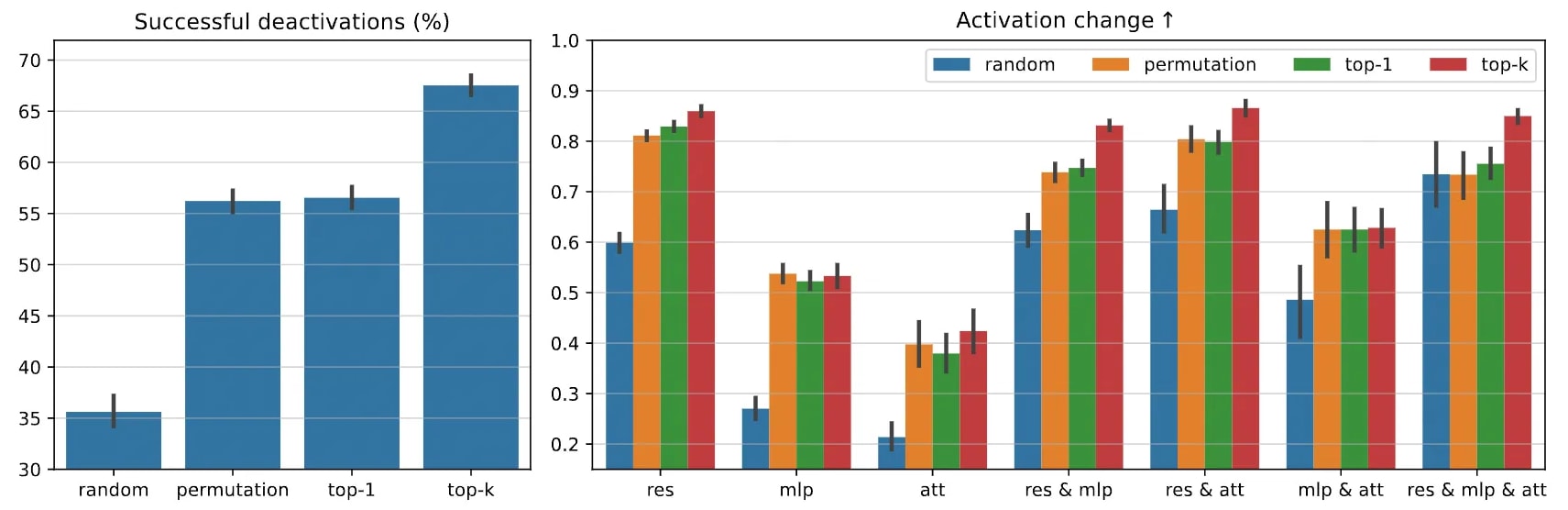
Deactivation and Causal Validation. To confirm these local matches are more than mere correlations, we "turn off" the matched predecessor in the hidden state and see if the target feature in the next layer vanishes. The following figures depict how often a target feature is deactivated when its predecessor is removed, and how this removal affects the activation strength of the target feature. This causal test supports the notion that a "residual predecessor" or "MLP predecessor" is truly a parent node in the flow.
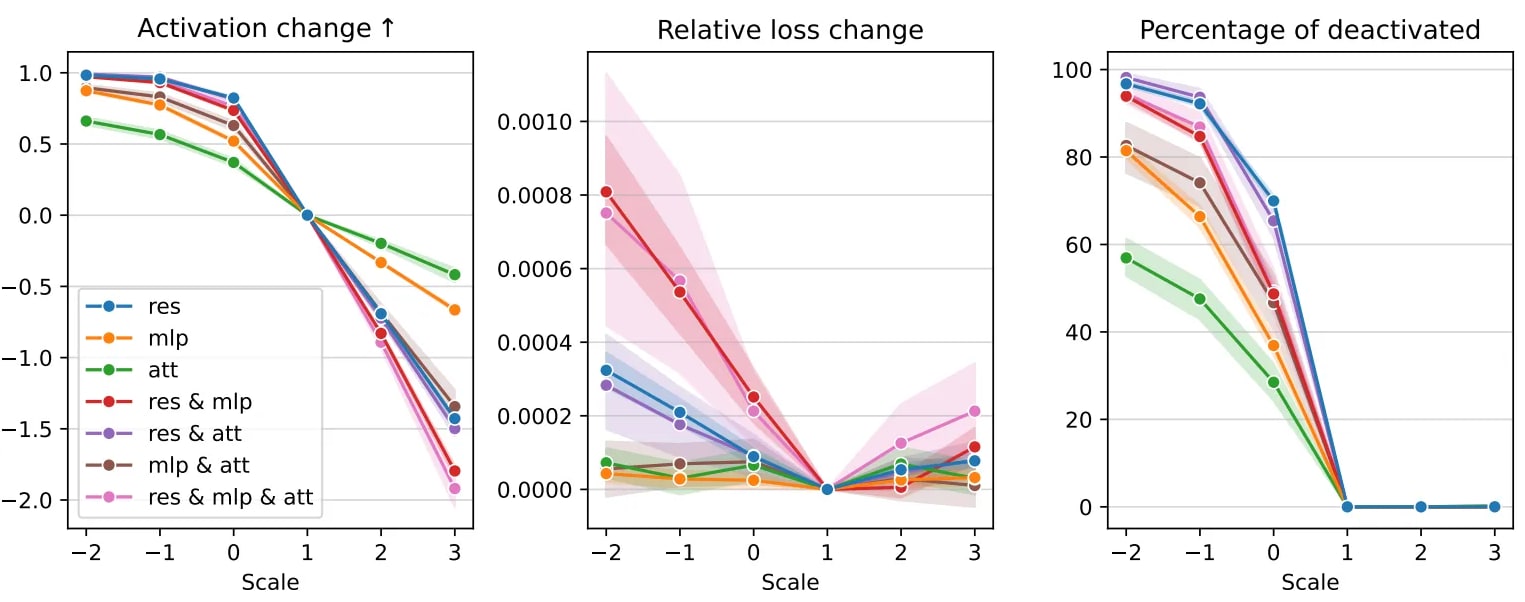
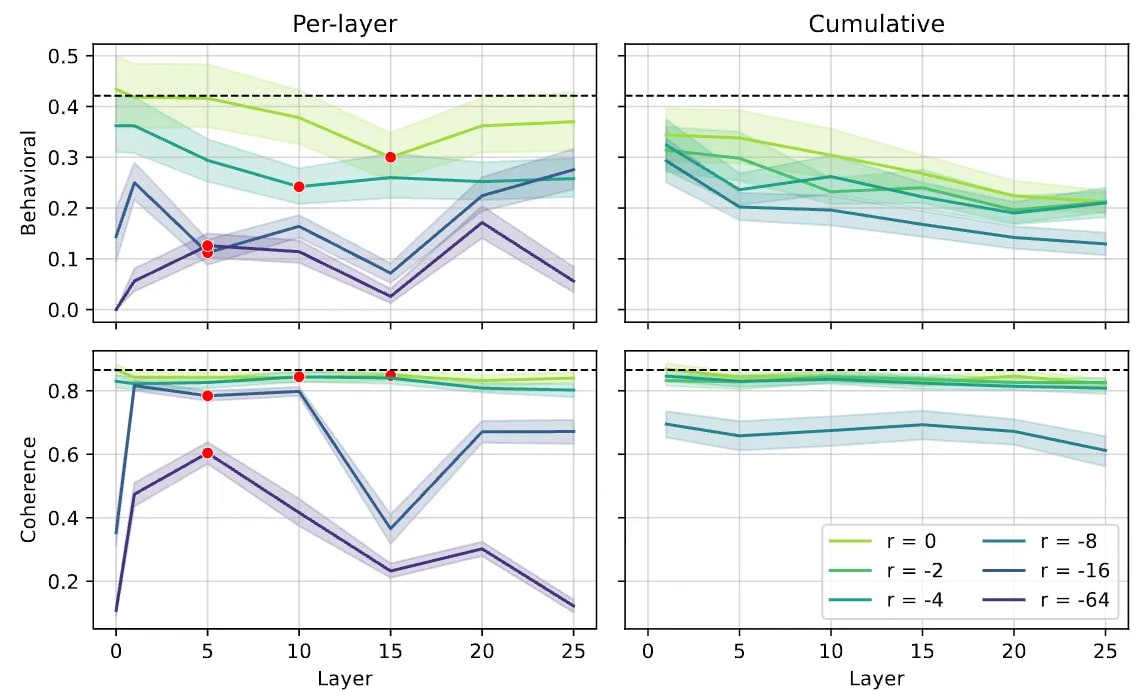
Multi-Layer Steering. This approach also makes it possible to intervene across multiple layers. We can identify features related to some theme (for example, "scientific explanations" or "weddings and marriage"), build a flow graph from those features, and apply steering with many features at once. This enables complex steering strategies: choosing features on a particular layer because it might be more influential, steering all features with effect accumulation up to a certain layer, or selecting a non-trivial subset of features on the flow graph based on specific considerations and using different steering techniques for each feature. The figure below illustrates the comparison of the first two methods for theme deactivation: per-layer intervention reveals that layers have different impacts on the outcome, and cumulative intervention enables us to perform distributed adjustments while maintaining a coherent structure of hidden states.
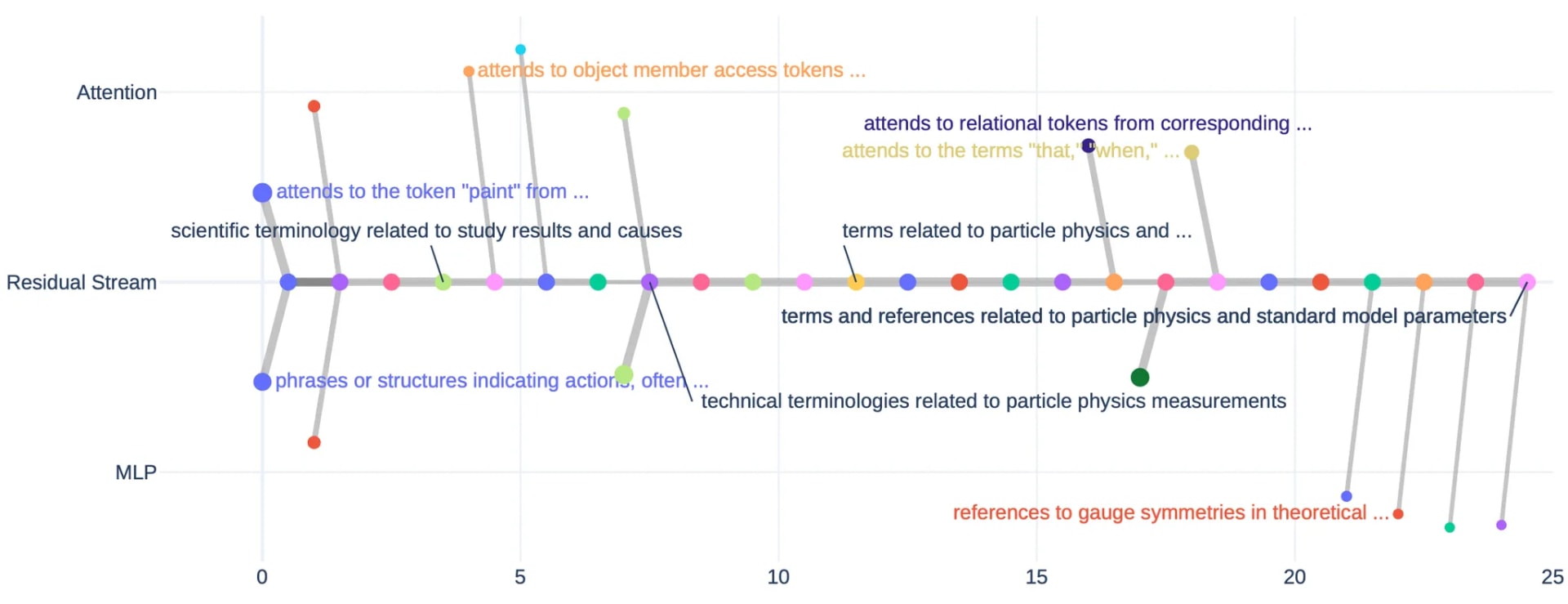
Interpretation of Flow Graphs. The figure below offers a specific example of a flow graph about "particle physics," built from a residual feature on layer 24 with index 14548 (denoted 24/res/14548 for short). Contrasting with [1], where we would simply say "feature 24/res/14548 matches with 23/res/9592," now we say: this feature emerges around layer 7, undergoes transformations from more empirical semantics (experiments and measurements) to more theoretical (gauge theories, symmetries, and theoretical physics) while maintaining the particle physics semantics as its core, and we see which submodules are involved in these transformations. Such an understanding of a feature's evolution path is crucial for steering and interpreting LLMs.
Key Differences and Complementarity
The approach in Mechanistic Permutability [1] offers a global alignment mechanism, proving the large-scale consistency of SAE features across layers. This viewpoint was validated by semantic similarity analysis, low reconstruction error, and minimal performance drop when pruning a layer. However, implications of such similarity and its usage have not yet been studied, such as module-level breakdowns of feature emergence and multi-layer steering procedures.
In Analyze Feature Flow [2], we slightly shift our focus. We examine a feature’s immediate predecessors and determine whether it was inherited from the residual stream or newly created by the MLP or attention block, which allows us to better understand the information processing inside the model and experiment with multi-layer steering.
Discussion
We believe that our work opens new avenues in the field of mechanistic interpretability and LLM alignment. We think of several main directions:
- We verify that similar linear directions on different layers encode similar semantic information, especially in close-range distances such as one-layer spans. This enables us to understand connections between features not only at a single SAE trained on a single position in a model (e.g., at the layer output), but also between SAEs trained on different positions, thus strengthening our understanding of how the model performs information processing and how it encodes concepts. These methods also enable the study of the evolution of concept encoding as the evolution of linear directions.
- We introduce a new unit of study, namely the flow graph, as an improvement over individual SAE features. A flow graph encodes not only what an individual linear direction at some position means, but also how it may be formed by computations in the previous layers. Flow graphs may be viewed as unique building blocks that encode information about a concept learned in some linear direction across the model, about how this concept appears, changes, and vanishes. Properties of these flow graphs, interactions between them, and many other aspects may be of great interest for interpretability research.
- Flow graphs may be used for efficient model steering in multi-layer intervention scenarios. There are plenty of yet unanswered and unasked questions in this field, considering proper steering methods, the role of different features in steering, their interactions, and emergent behavior while performing non-trivial steering (such as activating target features and deactivating their antagonists, all with different steering scales), circuit-like usage, etc.
One example of flow graph application we find fascinating. In [11], individual SAE features were used as units for steering, and there was an observation regarding the effect of 12/res/14455, which, according to Neuronpedia, has a firing pattern interpreted as “mentions of London and its associated contexts.” If the steering coefficient was too large, “the output diversity collapses, and the model begins to produce text focused entirely on fashion shows and art exhibitions in London.” Although this behavior was observed in the context of the SAE-TS method, we find that the flow graph reveals the reasons for such outcomes: fashion happens to be the main theme on earlier layers for that feature's flow graph.

We conclude that this particular linear direction at layer 12 not only encodes the concept of London but also inherits fashion-related semantics. Perhaps, this is an example of a polysemantic feature, bad interpretation, SAE error, or complex dependency (such as cross-layer superposition), etc. However, we believe it shows that such multi-layer flow graphs are worth studying and may inspire further research.
References
[1] N. Balagansky, I. Maksimov, D. Gavrilov. Mechanistic Permutability: Match Features Across Layers. ICLR 2025.
[2] D. Laptev, N. Balagansky, Y. Aksenov, D. Gavrilov. Analyze Feature Flow to Enhance Interpretation and Steering in Language Models. (Preprint).
[3] T. Mikolov, W.-t. Yih, and G. Zweig. Linguistic Regularities in Continuous Space Word Representations. In NAACL 2013.
[4] N. Elhage et al. A Mathematical Framework for Transformer Circuits. Distill, 2021.
[5] T. Bricken et al. Towards Monosemanticity: Decomposing Language Models With Dictionary Learning. Distill, 2023.
[6] H. Cunningham et al. Sparse Autoencoders Find Highly Interpretable Features in Language Models. ArXiv 2023.
[7] S. Rajamanoharan et al. Jumping Ahead: Improving Reconstruction Fidelity with JumpReLU Sparse Autoencoders. ArXiv 2024.
[8] T. Lieberum et al. GemmaScope: A Suite of Open Sparse Autoencoders for Gemma 2. ArXiv 2024.
[9] H. W. Kuhn. The Hungarian Method for the Assignment Problem. Naval Research Logistics Quarterly, 1955.
[10] J. Dunefsky, P. Chlenski, N. Nanda. Transcoders Find Interpretable LLM Feature Circuits. ICML 2024.
[11] S. Chalnev, M. Siu, and A. Conmy. Improving steering vectors by targeting sparse autoencoder features. ArXiv 2024.
0 comments
Comments sorted by top scores.