Paper: Transformers learn in-context by gradient descent
post by LawrenceC (LawChan) · 2022-12-16T11:10:16.872Z · LW · GW · 11 commentsThis is a link post for https://arxiv.org/abs/2212.07677
Contents
11 comments
The paper argues that auto-regressive transformers implement in-context learning via gradient-based optimization on in-context data.
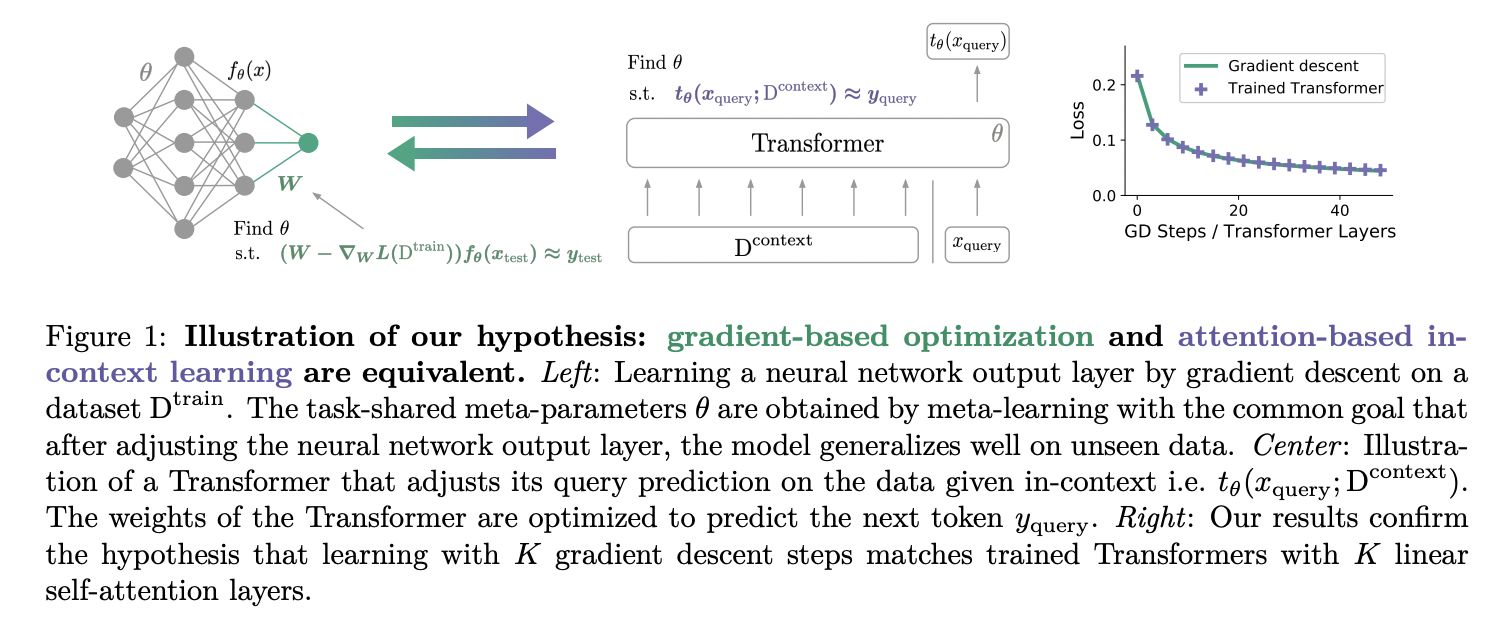 The authors start by pointing out that with a single linear self-attention (LSA) layer (that is, no softmax), a Transformer can implement one step of gradient descent on the l2 regression loss (a fancy way of saying w -= LR * (w x-y)x^T), and confirm this result empirically. They extend this result by showing that an N-layer LSA-only transformer is similar to N-steps of gradient descent for small linear regression tasks, both in and out of distribution. They also find that the results pretty much hold with softmax self-attention (which isn’t super surprising given you can make a softmax pretty linear).
The authors start by pointing out that with a single linear self-attention (LSA) layer (that is, no softmax), a Transformer can implement one step of gradient descent on the l2 regression loss (a fancy way of saying w -= LR * (w x-y)x^T), and confirm this result empirically. They extend this result by showing that an N-layer LSA-only transformer is similar to N-steps of gradient descent for small linear regression tasks, both in and out of distribution. They also find that the results pretty much hold with softmax self-attention (which isn’t super surprising given you can make a softmax pretty linear).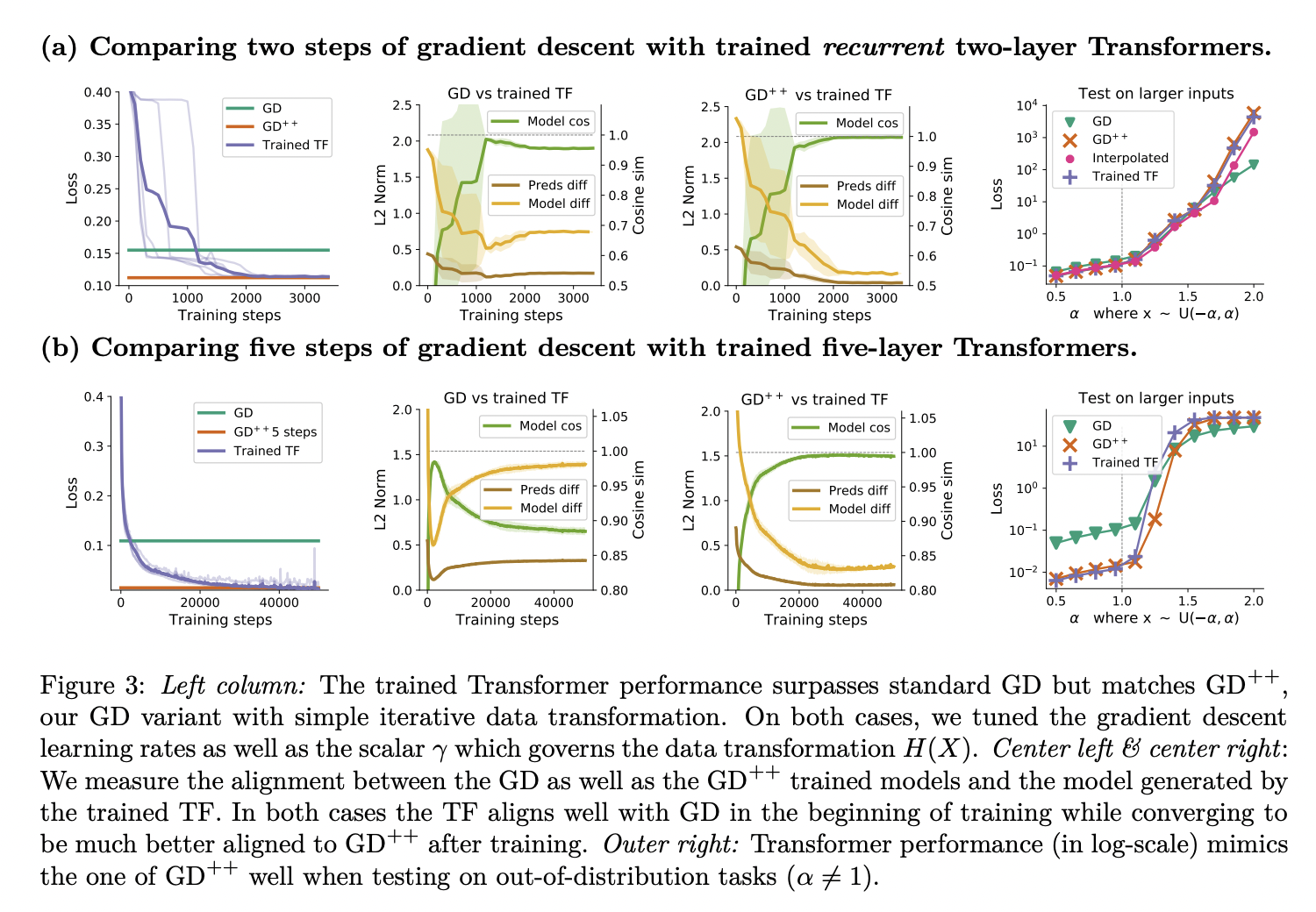
Next, they show empirically that the forward pass of a small transformer with MLPs behaves similarly to an meta-learned MLP + one step of gradient descent on a toy non-linear regression task, again in terms of both in-distribution and OOD performance. 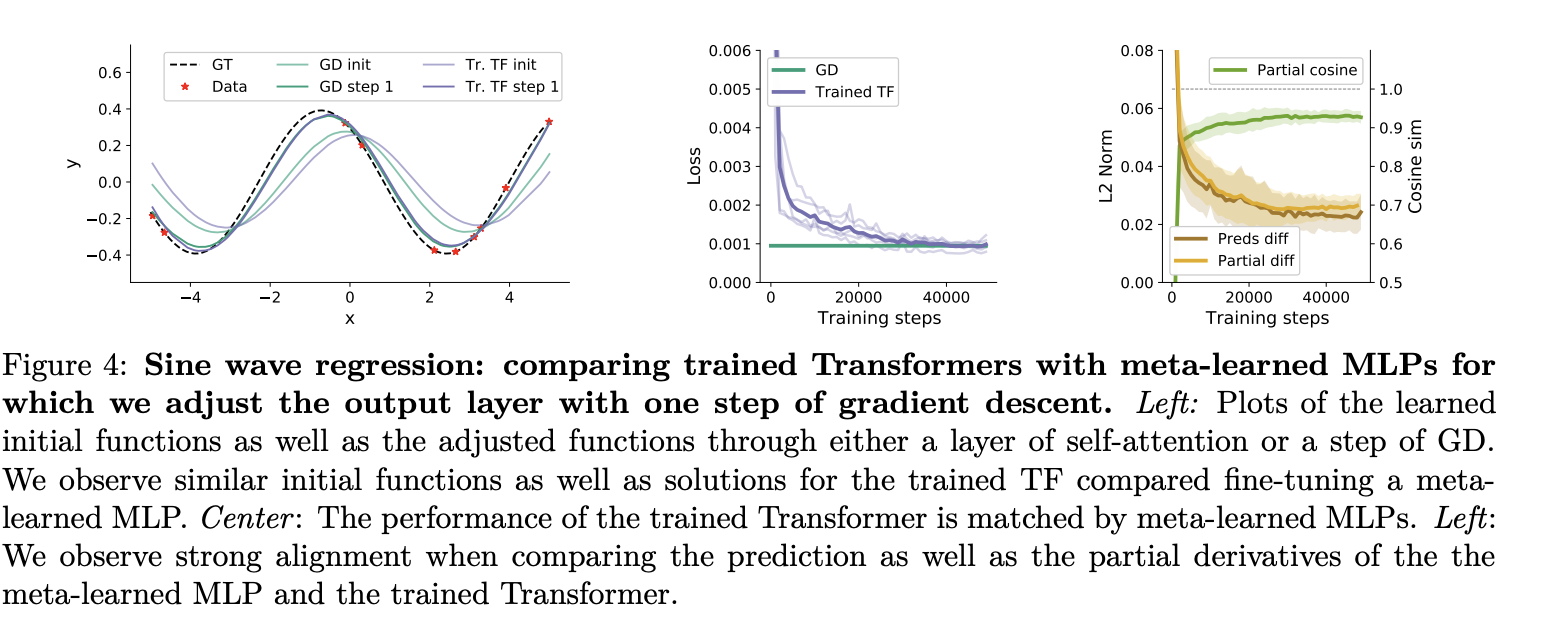
They then show how you can interpret an induction head as a single step of gradient descent, and provide circumstantial evidence that this explains some of the in-context learning observed in Olsson et al 2022. Specially, they show that 1) a two layer attention-only transformers converge to loss consistent with one step of GD on this task, and 2) the first layer of the network learns to copy tokens one sequence position over in the first layer, prior to the emergence of in-context learning. 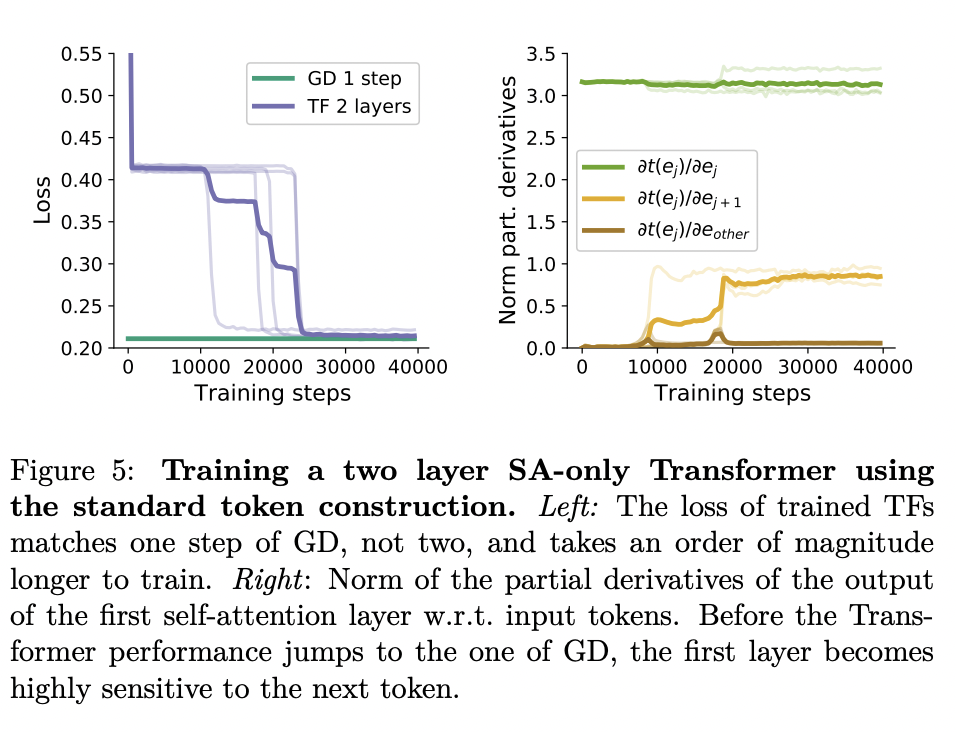
(EDIT:) davidad says below:
this is strong empirical evidence that mesa-optimizers are real in practice
Personally, while I think you could place this in the same category as papers like RL^2 or In-context RL with Algorithmic Distillation, which also show mesa optimization, I think the more interesting results are the mechanistic ones -- i.e., that some forms of mesa optimization in the model seem to be implemented via something like gradient descent.
(EDIT 2) nostalgebraist pushes back on this claim in this comment [LW(p) · GW(p)]:
Calling something like this an optimizer strikes me as vacuous: if you don't require the ability to adapt to a change of objective function, you can always take any program and say it's "optimizing" some function. Just pick a function that's maximal when you do whatever it is that the program does.
It's not vacuous to say that the transformers in the paper "implement gradient descent," as long as one means they "implement [gradient descent on loss]" rather than "implement [gradient descent] on [ loss]." They don't implement general gradient descent, but happen to coincide with the gradient step for loss.
(Nitpick: I do want to push back a bit on their claim that they've "mechanistically understand the inner workings of optimized Transformers that learn in-context", since they've only really looked at the mechanism of how single layer attention-only transformers perform in-context learning. )
11 comments
Comments sorted by top scores.
comment by davidad · 2022-12-16T21:36:56.404Z · LW(p) · GW(p)
I think it's too easy for someone to skim this entire post and still completely miss the headline "this is strong empirical evidence that mesa-optimizers are real in practice".
Replies from: LawChan, tailcalled↑ comment by LawrenceC (LawChan) · 2022-12-16T22:17:03.525Z · LW(p) · GW(p)
Sure, edited the post to clarify.
↑ comment by tailcalled · 2022-12-17T10:19:51.651Z · LW(p) · GW(p)
I don't think so.
Like technically yes, it shows that there is an internal optimization process that is running in the networks, but much of the meat of optimization such as instrumental convergence/power-seeking depends the structure of the function one is optimizing over.
If the function is not consequentialist - if it doesn't attempt to compute the real-world consequences of different outputs and grade things based on those consequences - then much of the discussion about optimizers does not apply.
Replies from: LawChan, davidad↑ comment by LawrenceC (LawChan) · 2022-12-17T10:30:18.432Z · LW(p) · GW(p)
Well, no, that's not the definition of optimizer in the mesa-optimization post [LW · GW]! Evan gives the following definition of an optimizer:
A system is an optimizer if it is internally searching through a search space (consisting of possible outputs, policies, plans, strategies, or similar) looking for those elements that score high according to some objective function that is explicitly represented within the system
And the following definition of a mesa-optimizer:
Mesa-optimization occurs when a base optimizer (in searching for algorithms to solve some problem) finds a model that is itself an optimizer, which we will call a mesa-optimizer.
In this paper, the authors show that transformers gradient descent (an optimization algorithm) to optimize a particular objective ( loss). (This is very similar to the outer optimization loop that's altering the network parameters.) So the way davidad uses the word "mesa-optimization" is consistent with prior work.
I also think that it's pretty bad to claim that something is only an optimizer if it's a power-seeking consequentialist agent. For example, this would imply that the outer loop that produces neural network policies (by gradient descent on network parameters) is not an optimizer!
Of course, I agree that it's not the case that these transformers are power-seeking consequentialist agents. And so this paper doesn't provide direct evidence that transformers contain power-seeking consequentialist agents (except for people who disbelieved in power-seeking consequentialist agents because they thought NNs are basically incapable of implementing any optimizer whatsoever).
Replies from: nostalgebraist, tailcalled↑ comment by nostalgebraist · 2022-12-17T22:11:40.841Z · LW(p) · GW(p)
That definition of "optimizer" requires
some objective function that is explicitly represented within the system
but that is not the case here.
There is a fundamental difference between
- Programs that implement the computation of taking the derivative. (, or perhaps .)
- Programs that implement some particular function g, which happens to be the derivative of some other function. (, where it so happens that for some .)
The transformers in this paper are programs of the 2nd type. They don't contain any logic about taking the gradient of an arbitrary function, and one couldn't "retarget" them toward loss or some other function.
(One could probably construct similar layers that implement the gradient step for , but they'd again be programs of the 2nd type, just with a different hardcoded .)
Calling something like this an optimizer strikes me as vacuous: if you don't require the ability to adapt to a change of objective function, you can always take any program and say it's "optimizing" some function. Just pick a function that's maximal when you do whatever it is that the program does.
It's not vacuous to say that the transformers in the paper "implement gradient descent," as long as one means they "implement [gradient descent on loss]" rather than "implement [gradient descent] on [ loss]." They don't implement general gradient descent, but happen to coincide with the gradient step for loss.
If in-content learning in real transformers involves figuring out the objective function from the context, then this result cannot explain it. If we assume some fixed objective function (perhaps LM loss itself?) and ask whether the model might be doing gradient steps on this function internally, then these results are relevant.
Replies from: LawChan↑ comment by LawrenceC (LawChan) · 2022-12-18T02:01:24.558Z · LW(p) · GW(p)
I think the claim that an optimizer is a retargetable search process makes a lot of sense* and I've edited the post to link to this clarification.
That being said, I'm still confused about the details.
Suppose that I do a goal-conditioned version of the paper, where (hypothetically) I exhibit a transformer circuit that, conditioned on some prompt or the other, was able to alternate between performing gradient descent on three types of objectives (say, L1, L2, L\infty) -- would this suffice? How about if, instead, there wasn't any prompt that let me switch between three types of objectives, but there was a parameter inside of the neural network that I could change that causes the circuit to optimize different objectives? How much of the circuit do I have to change before it becomes a new circuit instead of retargeting the optimizer?
I guess part of answer to these questions might look like, "there might not be a clear cutoff, in the same sense that there's not a clear cutoff for most other definitions that we use in AI alignment ('agent' or 'deceptive alignment' for example)", while another part might be "this is left for future work".
*This is also similar to the definition used for inner misalignment in Shah et al's Goal Misgeneralization paper:
We now characterize goal misgeneralization. Intuitively, goal misgeneralization occurs when we learn a function fθbad that has robust capabilities but pursues an undesired goal.
It is quite challenging to define what a “capability” is in the context of neural networks. We provide a provisional definition following Chen et al. [11]. We say that the model is capable of some task X in setting Y if it can be quickly tuned to perform task X well in setting Y (relative to learning X from scratch). For example, tuning could be done by prompt engineering or by fine-tuning on a small quantity of data [52].
↑ comment by tailcalled · 2022-12-17T13:26:26.615Z · LW(p) · GW(p)
I am aware of the definition of a mesa-optimizer. I'm just saying that this definition doesn't catch much of the danger or exciting stuff, since it's e.g. not so important if the model contains something that optimizes over e.g. . The danger comes when the inner objective is more consequentialist than that.
I also think that it's pretty bad to claim that something is only an optimizer if it's a power-seeking consequentialist agent. For example, this would imply that the outer loop that produces neural network policies (by gradient descent on network parameters) is not an optimizer!
If the outer loop isn't connected to some mechanism that evaluates the consequences of different policies in the real world, then you are probably training something that mimics the prespecified training data rather than searching for novel powerful policies. This isn't useless - the explosive growth of statistical models for various purposes proves so much - but it is unlikely to be dangerous unless coupled with some other process that handles the optimization.
So I'm not saying these things aren't optimizers, but much of the worry about mesa-optimizers is about consequentialist optimizers, not generic optimizers. Most functions are perfectly safe to optimize.
↑ comment by davidad · 2022-12-17T10:37:04.004Z · LW(p) · GW(p)
Yes, it's worth pulling out that the mesa-optimizers demonstrated here are not consequentialists, they are optimizing the goodness of fit of an internal representation to in-context data.
The role this plays in arguments about deceptive alignment is that it neutralizes the claim that "it's probably not a realistically efficient or effective or inductive-bias-favoured structure to actually learn an internal optimization algorithm". Arguments like "it's not inductive-bias-favoured for mesa-optimizers to be consequentialists instead of maximizing purely epistemic utility" remain.
Although I predict someone will find consequentialist mesa-optimizers in Decision Transformers, that has not (to my knowledge) actually been seen yet.
comment by joswald (johannes-oswald) · 2022-12-17T09:48:52.662Z · LW(p) · GW(p)
Hi there - I am the first author! Thanks for this very nice write up. Regarding: "mechanistically understand the inner workings of optimized Transformers that learn in-context" - its definitely fair to say that we do this (only) for self-attention only Transformers! Also, I try to be more careful and (hopefully consistently) only claim this for our simple problems studied... working on v2 including language experiments and I am also trying to find a way how to verify the hypotheses in pretrained models. Thanks again!
Replies from: LawChan↑ comment by LawrenceC (LawChan) · 2022-12-17T09:57:56.607Z · LW(p) · GW(p)
You're welcome, and I'm glad you think the writeup is good.
Thank you for the good work.
comment by Algon · 2022-12-16T12:06:08.732Z · LW(p) · GW(p)
If true, it feels like stories of how models with attention learn to be deceptive are simpler than I thought they were.
EDIT: A somewhat enlightening twitter thread by the authors.