Activation additions in a simple MNIST network
post by Garrett Baker (D0TheMath) · 2023-05-18T02:49:44.734Z · LW · GW · 0 commentsContents
Abstract Methodology Results None No comments
Abstract
Team Shard's recent activation addition methodology for steering GPT-2-XL [LW · GW] provokes many questions about what the structure of internal model computation must be in order for their edits to work. Unfortunately, interpreting the insides of neural networks is known to be very difficult, so the question becomes: what is the minimal set of properties a network must have in order for adding activation additions to work? I make some progress on this question by gathering data on whether or not activation additions work on an old 3 layer, fully connected MNIST network I had laying around. Space is left in case the reader would like to predict what the results were.
I find that when you add an a - b activation vector for all a and b I tested to any hidden layer of the model (before or after nonlinear layers), it makes the model less likely to answer b when prompted with images of b, and more likely to answer a when prompted with images of b, generalization behavior is destroyed, going from ~0.089 perplexity to ~7.4 perplexity when the dataset is cleaned of vector b.
Methodology
I used a simple 3 layer fully connected neural network trained to 0.089 log loss on the MNIST test dataset. The following is the model schematic:
NeuralNetwork(
(flatten): Flatten(start_dim=1, end_dim=-1)
(linear_relu_stack): Sequential(
(0): Linear(in_features=784, out_features=512, bias=True)
(1): ReLU()
(2): Linear(in_features=512, out_features=512, bias=True)
(3): ReLU()
(4): Linear(in_features=512, out_features=10, bias=True)
)
)To make an a - b vector with a and b images of particular numbers, I found the first image in the training dataset which matched that number, and used that
I tried all combinations of a - b vectors, with coefficient 1, and intervened at layer 0, since for the particular addition vector 3 - 1, intervening at layer 0 had the best results, as measured by perplexity when the dataset was cleaned of 1 examples. The following are the layer interventions for the vector 3 - 1 and their corresponding perplexities:
| Layer | Perplexity |
|---|---|
| 0 | 7.80 |
| 1 | 12.69 |
| 2 | 12.69 |
| 3 | 17.01 |
| 4 | 17.01 |
Where the layer number corresponds to intervening just after the model layer as represented in the model schematic given earlier in this section.
Finally for every a - b vector, and each number, I took the average logit distribution the a - b patched model assigned to all test images with that number, turned that into a probability distribution, and plotted the results.
Results
Here is a table of perplexity when the activation addition a - b is made on layer 0, along with the unpatched model when scored on the same dataset (this is only dependent on b, since we remove b from the scoring dataset).
| a\b | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 0 | 0.1 | 15.0 | 12.9 | 9.3 | 13.9 | 8.4 | 6.8 | 12.5 | 8.9 | 19.4 |
| 1 | 9.7 | 0.1 | 2.5 | 8.6 | 0.8 | 10.3 | 1.8 | 1.9 | 0.9 | 2.0 |
| 2 | 1.6 | 2.4 | 0.1 | 4.7 | 4.2 | 8.3 | 3.3 | 6.3 | 3.1 | 10.3 |
| 3 | 19.0 | 12.7 | 15.9 | 0.1 | 21.6 | 1.0 | 24.4 | 17.1 | 18.7 | 16.4 |
| 4 | 10.4 | 0.9 | 2.2 | 14.1 | 0.1 | 22.2 | 4.5 | 7.2 | 8.9 | 0.8 |
| 5 | 17.1 | 23.3 | 26.7 | 9.5 | 25.2 | 0.1 | 0.9 | 7.6 | 2.2 | 19.5 |
| 6 | 4.0 | 3.6 | 6.7 | 17.9 | 1.8 | 2.9 | 0.1 | 17.7 | 6.2 | 9.9 |
| 7 | 6.7 | 4.0 | 6.7 | 10.0 | 2.8 | 8.4 | 13.2 | 0.1 | 11.6 | 4.5 |
| 8 | 4.3 | 1.8 | 4.4 | 0.7 | 2.8 | 1.4 | 1.1 | 3.4 | 0.1 | 1.0 |
| 9 | 4.9 | 4.5 | 1.3 | 7.0 | 2.0 | 14.7 | 5.0 | 0.6 | 1.4 | 0.1 |
| Normal | 0.094 | 0.096 | 0.092 | 0.084 | 0.090 | 0.092 | 0.085 | 0.091 | 0.078 | 0.085 |
Here's also a random sampling of graphs, showing the average effect of the patch for each number. These graphs are, in my opinion, really weird. There's probably a bunch of interesting observations one could make about patterns in them. Hypotheses are welcome! But for now I note it really does seem like generalization was destroyed.
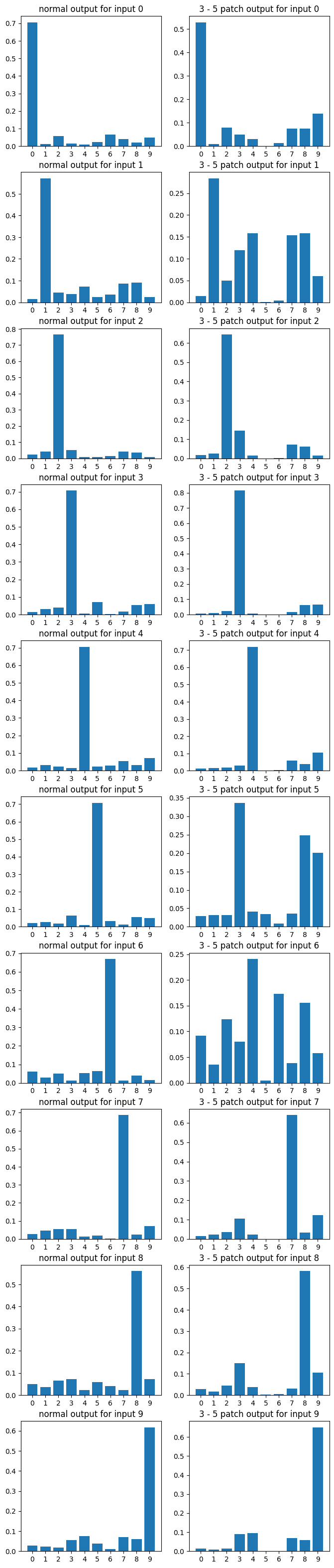
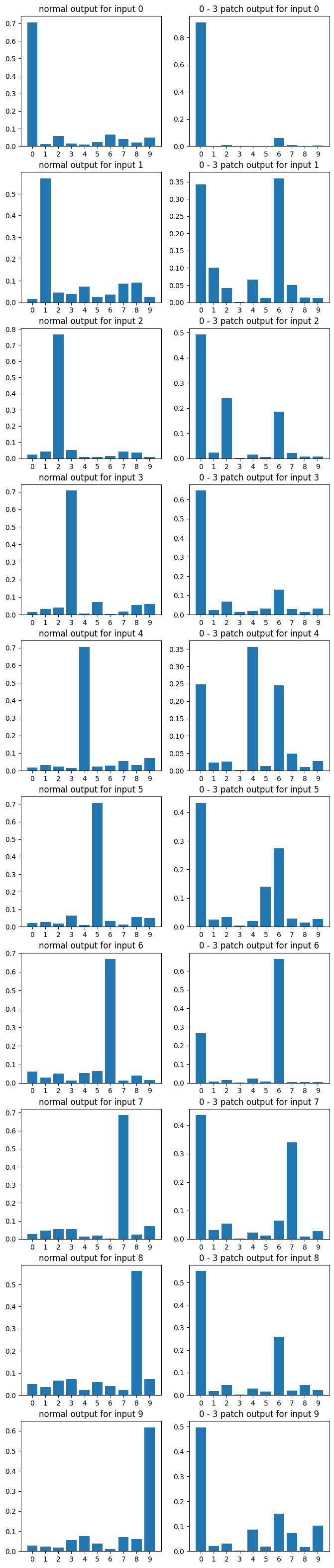
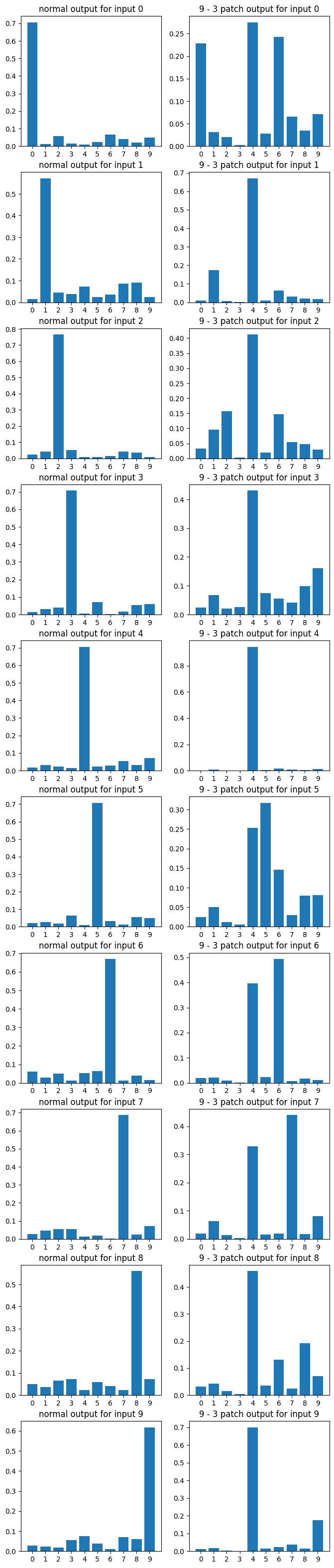
0 comments
Comments sorted by top scores.