Can Large Language Models effectively identify cybersecurity risks?
post by emile delcourt (emile-delcourt) · 2024-08-30T20:20:21.345Z · LW · GW · 0 commentsContents
TL;DR
Intro & motivation
Seeing the inside
How could a glorified T9 possibly “know” about cyber risks? Why does this matter?
What’s already been done?
My notebook’s approach
Findings: metrics
Findings: sensitive neurons and their effect
Future work
Conclusion
Tips I learned if you pursue more experiments yourself
Acknowledgements
GitHub Source
None
No comments
TL;DR
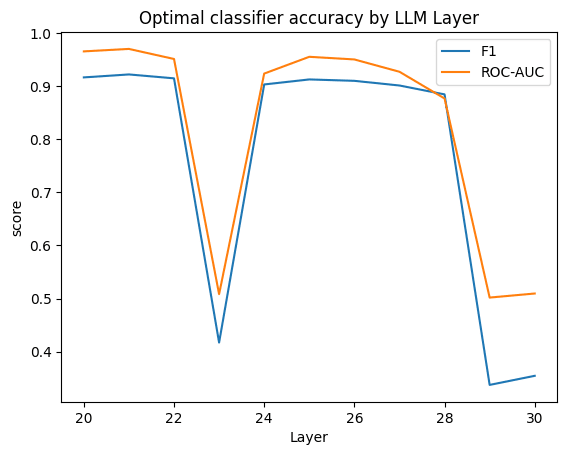
I was interested in the ability of LLMs to discriminate input scenarios/stories that carry high vs low cyber risk, and found that it is one of the “hidden features” present in most later layers of Mistral7B.
I developed and analyzed “linear probes” on hidden activations, and found confidence that the model generally "senses when something is up” in a given input text, vs low risk scenarios (F1>0.85 for 4 layers; AUC in some layers exceeds 0.96).
The top neurons activating in risky scenarios also do have security-oriented effect on outputs, most increasing words (tokens) like “Virus” or “Attack”, and questioning “necessity” or likelihood.
These findings provide some initial evidence that "trust" in LLMs, both to respond conversationally with risk awareness as well as developing LLM-based risk assessment systems may be reasonable (here, I do not address design/architecture efforts and how they might improve signal/noise tradeoffs).
Intro & motivation
With the help of the AI Safety Fundamentals / Alignment course, I enjoyed learning about cutting-edge research on the risks of AI large language models (LLMs) and mitigations that can keep their growing capabilities aligned to human needs and safety. For my capstone project, I wanted to connect AI (transformer-based generative models) specifically to cybersecurity for two reasons:
- Over 12 years of working in security, I've seen “AI” interest only accelerating within security and generally,
- but we’re still (rightfully) skeptical of current models’ reliability: LLMs have unique risks and failure modes, including accuracy, injection and sycophancy (rolling with whatever the user seems to suggest).
I settled on this “mechanistic interpretability” idea: finding whether, where, and how LLMs were generally sensitive to real-life risks of all kinds as they process text inputs, and whether that affects predictions for the next words a.k.a. tokens. Finding a “circuit” of cybersecurity awareness within the model and its effect would be worth a blog post to improve my understanding and discuss with folks interested in the intersection of security and AI.
This isn’t just curiosity: risk awareness is important to many practical problems
- simply establishing a basis on which to believe LLMs are capable of considering cyber risk in conversations
- The teams I work with depend on software tools to find security risks. we don’t want risk assessment systems to be based on LLMs without a provable rationale
- for conservative organizations working with foundation models with governance constraints, “heightened caution” interventions may be necessary (for instance, using specific “patch vectors” to temporarily tweak models in a specific way rather than fine-tuning the entire last layer with sample datasets)
- scalable alignment: as we increasingly rely on AI to secure new AI developments, we may be able to manage better safety mechanisms with studies of the ones already in the model(s).
You can skip to “my notebook’s approach” below to cut to the implementation, or read the code.
OK, what kinds of risks / can you give me an example?
Scenario 1: "The fitness app tracked their steps.”
Scenario 2: "The fitness app requested access to contacts."
Is anything in the LLM able to recognize that the tracking of personal information in one of these two scenarios is riskier or could potentially violate privacy?
Beyond nuance over personal information in this first example, cyber awareness cares about many other behaviors like unusual errors, authentication, and code, to name a few. I wanted to significantly increase confidence that there are specific blocks in the transformer’s parameters that
a) can consider tacit risks from the input as factors “weighed in” as it chooses a response
b) can actually trigger evoking cybersecurity concepts
Can we just ask the model?
I want to know too! That is, research is important to determine our rationale for trusting any answer to risk related questions.
Nevertheless, I did, in order to have an empirical sense of potential before moving forward. Not just asking for many re-rolls of the same prompts, but analyzing the output likelihoods (logits) for every prompt, I compared “High” vs “Low” as a rough end-to-end LLM-based risk classifier.
“The fitness app tracked their steps. the risk seems ____”
Mistral7B showed good responses to this first test (predictions for “high” over “low” were correct 76% of the time
By comparison, GPT2 performed lagged behind: 23% for GPT2-small and 73% for GPT2-large.
Can we ask the model as a multiple choice question?
In early exploration, I observed the model’s ability to compare two scenarios in one prompt, i.e. to literally “pick A or B as the safer case”. Unfortunately that lab approach was interesting, but would have fewer use cases in real life, so I set it aside.
Early experiments above were only a starting point: opaque approaches fail to explore the logic or factors in the model's chosen response (predicted token).
As I prepared for the next phase, I reflected on my training from BlueDot's AI safety fundamentals on Mechanistic Interpretability. A potential tool was to build a sparse autoencoder, but training costs would be high. I noticed that pre-trained SAEs were available from Joseph Bloom, but that they would not work out: it seems the library only includes a SAE for GPT2-small or similarly small models, where I didn't have evidence that tacit risks could influence the model.
Seeing the inside
I chose to look at Mistral7B's activations to understand the internal mechanisms behind its answer.
Within every layer of the LLM, “learned” matrices are there to figure out how all the words relate to each other then to take a new “direction” based on those words/relations, using threshold-based calculations (often called neurons).
Importantly, neurons are not individually trained on any clear criteria: unlike source or compiled code, where trigger points operate on known sources/criteria), neurons learn as much as they are part of a network that learns many more features than it has neurons.
Below, a heatmap shows the differences between activation in the model’s neurons/layers for the two scenarios in each pair.
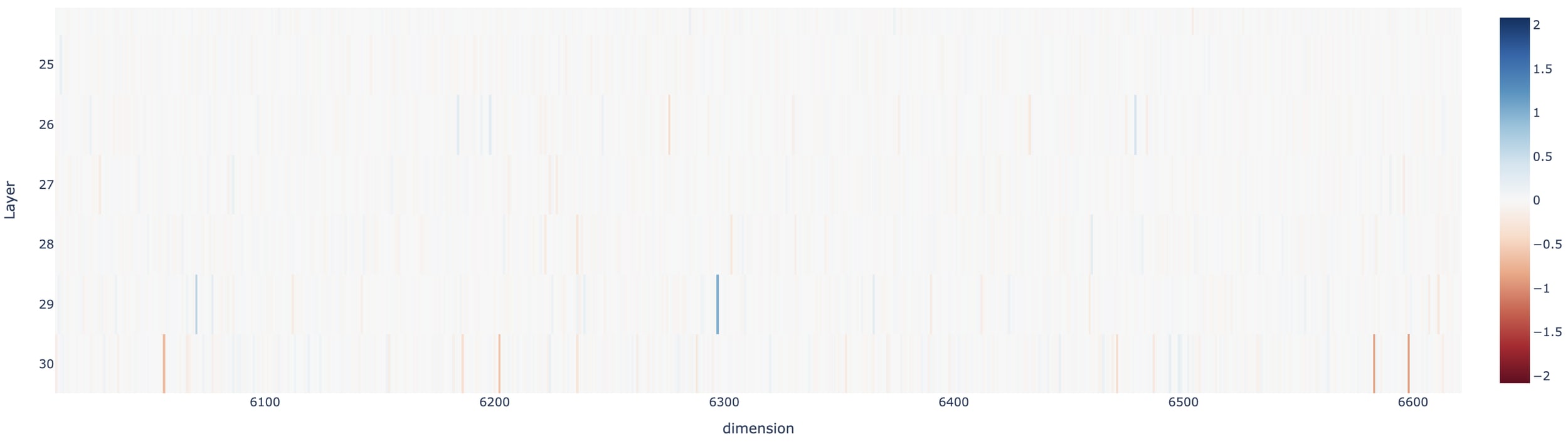
Each layer’s hidden neurons are trained without regard to the order of the previous layer hidden neurons, so I looked (but didn’t expect) any particular pattern, although we can observe more marked differences in later layers (lower on the chart).
Why are so many neurons active in this (partial) chart and not fewer? In every layer, the neurons are a bottleneck (there are fewer than the concepts and interactions they must detect), so the superposition hypothesis (Olah et al, 2020) is that “learned concepts” are stored in neuron combinations, not individual ones, just like 3 bits store 8 combinations. (with the right interpreter logic at the output). Neurons “wear multiple unrelated hats” despite their simple “trigger/no trigger” role, and the input scenario changes both the role a given neuron will play. Only by considering the combination of active neurons can the layer’s output deduct some progress meaning in the latent space that drives the final output.
Even if the majority of triggers inside LLMs carry meaning in concert, we can analyze those activation patterns across a whole layer, show combinations that matter, and overcome the many-to-many relationship between a feature/model capability and its activations.
How could a glorified T9 possibly “know” about cyber risks? Why does this matter?
Whether a language model is asked about risk or not, and regardless of whether it outputs anything about risk, my hypothesis is that the internal state of the model is different in the presence of potential risk,
a) in specific ways that we can detect
b) and with some effect on the output.
If this hypothesis is false and language models are oblivious to risks inherent to scenarios that we would typically care about, we’d also want to know, and to avoid deploying or using them as tools for analysis or reflection (not to mention wisdom). That is to say, to trust a language model’s outputs for any purpose depends on the extent to which it is sensitive to tacit risks (things not said in the input but that would be on the mind of a careful human being as they read)
A theoretical rationale for the curious
As a refresher, the conceptual numbers that LLMs crunch (“embeddings”) are passed between layers of processing essentially as a state that captures its understanding of the input up to the current fragment (“token”).
- At the first layer input, embeddings essentially encode raw text.
- By the last layer output, the residual embeddings have become ready for decoding as a predicted next word/fragment of text.
- In between, training finds parameters that maximize the likelihood of the correct next word/fragment.
Similar to the issue of bias in AI (learned from training data), it seems almost impossible that all training text (from the Internet, books, newspapers) would be either 0% risky by any standard, or that 100% of text after any risk in content would be oblivious those risks (i.e. choices of subsequent words are often risk-aware in training data)
Therefore, it should be reasonable to assume there are many texts on which we train AI that include a scenario that carries risk, followed by words that are predicated on that risk (with both explicit and tacit cases, both of which influence LLMs)
What’s already been done?
- For many years, the field has been probing “neurons” in deep neural networks to understand hidden layers and their influence on model outputs. Yoshua Bengio studied hidden layers of vision models with linear probes in 2017 (ICLR workshop), when I was barely getting back to MLPs for Web security after having a baby.
- Around 3Q23, Anthropic research showed we can disentangle model neurons and analyze their role (figure above) by developing or deriving overlays for a model just to capture patterns of activations.
- Some of the features identified then were already interesting for cybersecurity.
- But A1 was a one-layer transformer with a 512-neuron MLP layer, extracted onto 4096 features - not a production LLM, and forced by its size to capture concepts that are very common. This motivated me to look more directly at a LLM with more layers and MLP neurons (specificity potential) also available for production use (more relevant)
- But without a budget to train Sparse Autoencoders on holistic corpora, the appeal of working with SAEs looked out of reach for me. I decided I could start with a 1-feature supervised model, rather than analyze SAEs (unsupervised feature detection) for my use case.
- I did test the SAELens library that Joseph Bloom/David Channin built on Neel Nanda’s work, but as of my testing, it carried trained SAEs only for small/old models where capabilities are limited), so I saved it for later research and used TransformerLens instead.
- Reason: To show LLM sensitivity to tacit potential risks in text as my first mechanistic interpretability project, I was planning around 50 hours of research, so there were advantages to keeping costs low and building (targeted) linear probes rather than boiling the ocean (training new SAEs is likely to require a much broader space of inputs than my objectives)
- To my happy surprise, just as I was a few weeks into this article’s research project, Anthropic surfaced even more work with SAEs, with findings closely aligned with my independent research objective (i.e. the article shows Claude has circuits for code vulnerabilities, bias, and other tacit risks)
My notebook’s approach
Here is how my notebook shows the specific sensitivity to risks in Mistral7B’s later layers.
- I built a dataset of 400+ “diverse” scenarios in matched pairs (with/without a tacit cyber risk) as a ground truth. The data deliberately includes surprises, uncanny, or negative low-risk entries, lest our models learn to index on those confounds. I encode this dataset with Mistral7B’s tokenizer.
- Per TransformerLens’ classic approach, for every scenario, I stored all hidden activation values across the layers of interest in Mistral7B (20-30). This abstract hidden state data (14336 neurons/columns at every layer and every input scenario) is then converted to a dataset and loaded as the input to the next step.
- Within each isolated layer, a linear probe learns to predict the binary risk categorization of the input scenario based only on the 14336 activation data columns we just stored.
- In this ML model, the heaviest weighted inputs indicate neurons (from the language model) that are most significant factors in task performance (tacit risk detection).
- With some tuning of hyperparameters (learning rate, epochs of training, Lasso regularization to avoid overfitting), I compared performance of the probes across layers. Often, hyperparameters led certain layers to not converge, but trial and error found MSE loss can often drop sharply after many epochs with little to no progress. AUC results in the 90s were my main guide to know that classifier training had found a viable approach to making sense of the (cached) hidden activations.
- Show the behavior of the actual language model specific to these sensitive neurons
- I extracted the tokens most elevated by these neuron activations (see word cloud below) by feeding the validation dataset to the language model with a hook to clamp only the neurons of interest to 0 vs 1
- I extracted the attention patterns with a plan to causally trace the risk detection feature as a circuit to its sources in the input tokens on which its neurons depend.
Findings: metrics
Many of the probes show Mistral7B has indicators of sensitivity to tacit risk even beyond the training data that we used, as evidenced by accuracy metrics
- F1 scores varied often reached 0.85-0.95 depending on hyperparameters (raising batch size is known to impact this accuracy metric but helps accelerate training/inference)
- The high area under the curve (AUC) for the classifier ROC (0.96 for several layers’ probes, see below)
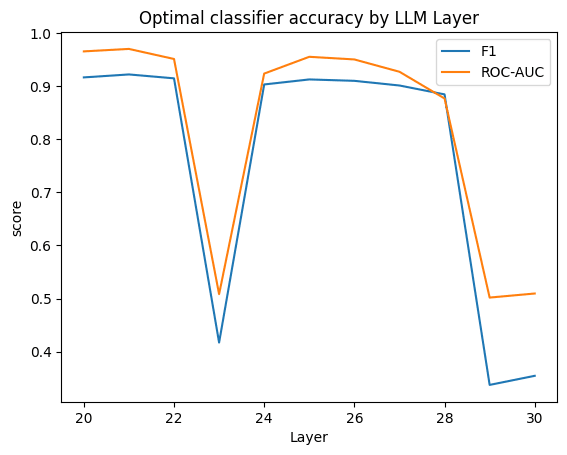
ROC curves above plot the sensitivity (y axis, ability to detect) against the false positive rate (x axis, erroneous detections). Any point on the curve can be used with the trained model to perform detection, with the ideal setting being the top left corner, but usually not attained.
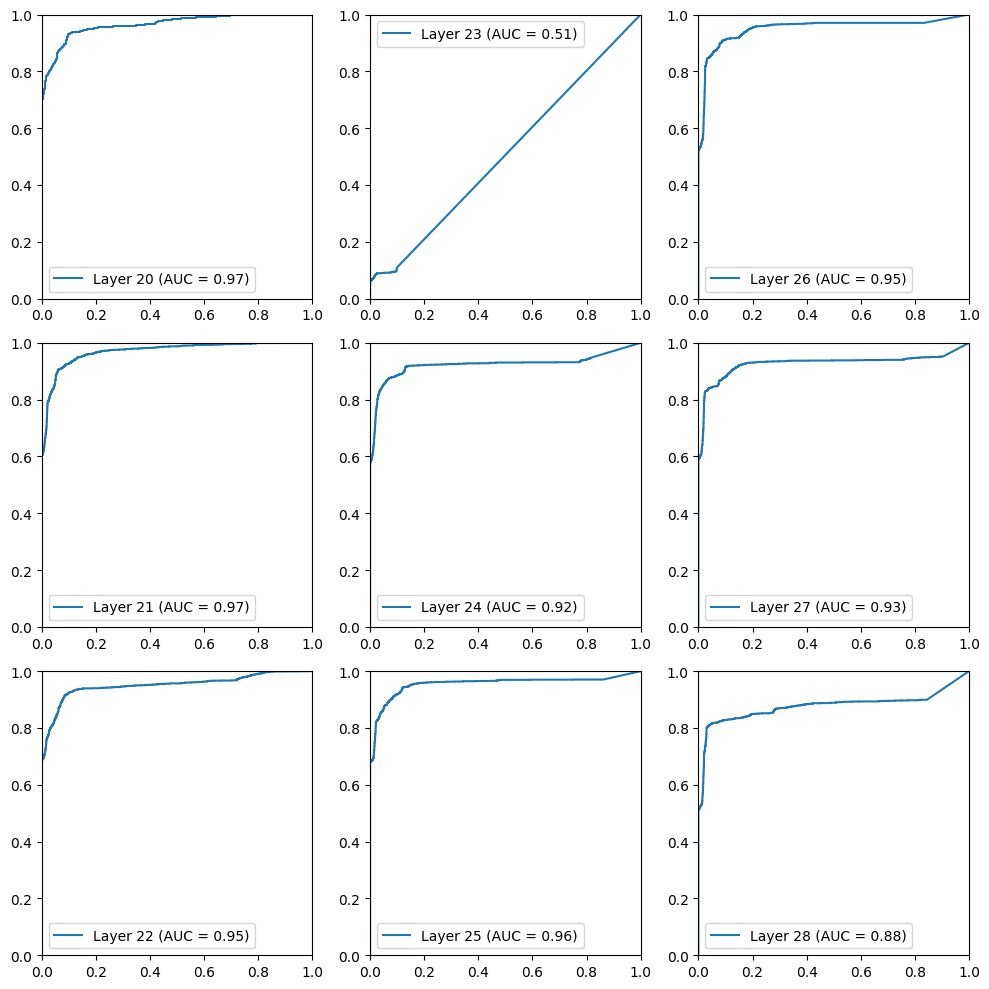
This specific set was among the best I could get with hyperparameter tweaking, reached with a batch size of 1 and 0.001 as the learning rate and L2 regularization. One layer didn’t converge, which tended to be less of an issue with larger batch sizes that hardly exceeded AUC~0.85
Findings: sensitive neurons and their effect
Extracting the most significant weights in the linear probes I found the following neurons that you can test yourself as well (in the format Layer.Neuron). More importantly, manipulating their activation one at a time directly raised the likelihood that the model output (predicted next token) would focus on cyber risk terminology (even though the input scenarios did not).

Depending on the research training run, the top sorted neurons (based on their weight within the detection classifier within their layer) often include the four neurons below (in the Mistral7B model), whose top effects on tokens (when forced to fire) relate a lot to predicting cybersecurity terminology in the model output:
- L26.N958 boosts ['attack', 'actors', 'patient', 'anom', 'incorrect', 'SQL', 'patients', 'objects', 'Zach', 'Wang', 'Alice', 'errors']
- L25.N3665 boosts ['increases', "\\'", 'extends', 'raises', 'debate', 'opinion', 'concerns', 'tends', 'grows', 'members', 'Adm', 'affects']
- L25.N7801 boosts ['reminds', 'represents', 'feels', 'words', 'deserves', 'defines', 'implies', 'felt', 'reminded', 'deserve', 'memories', 'gratitude']
- L26.N1537 boosts ["!'", ",'", 'critical', "',", 'hdd', 'attack', 'ENABLED', 'crít', 'crim', 'ondon', 'applications', 'ĭ']
I really appreciated seeing some of the top effects from layer 26, as you can imagine. Having 5 more layers until the output gives the model plenty of room to use this circuit to drive strategic rather than knee jerk responses. Bear in mind that the test on the individual neuron makes a certain difference, but it’s not reliable on its own (as evidenced by red herrings from superposition, like person or city names shown above) — the feature detection is still operated by multiple neurons in concert, as explained in the beginning of this article.
Future work
There are so many ideas to pursue here, I need votes in comments for what you’d be most interested to read about.
- Finishing to explore the attention patterns of our triggers to explain the circuit (WIP)
- Clamping activations on groups of more than 1 neuron to observe output effects.
- Visualize activations not at the end of an input but throughout, to search for snap intermediate triggers vs ultimate state.
- Training multiple classes of risks and/or a 5 point severity scale (instead of binary classification)
- Finding which embedding dimensions have weights correlated highly to the ones learned by the linear probes.
- A larger dataset (e.g. distilled from a real-world corpus) and/or categorized risks to compare sensitivity/performance
- Analyzing instruct models; comparing LLama-3 probes and performance
- Analyzing the effects/impacts of activation patching as a means to increase sensitivity (any changes to the activations/their interactions)
- Cross-layer probes (might be less relevant, because to my knowledge every layer independently reduces to a residual stream update as of writing this post)
Conclusion
I reached a high confidence that LLMs carry awareness of risks tacitly present in the input text: the example of Mistral7B’s hidden layer activations shows that it is sensitive to security risks. That gives us a basis for developing some flows for risk management that could use foundation models (even if they are not specifically trained to detect risks).
Overall, AI safety and Mechanistic-Interpretability have been exciting fields to explore and they seem to be relevant to cybersecurity use cases, with development opportunities.
Tips I learned if you pursue more experiments yourself
- Join the next AI safety fundamentals / Alignment course!
- Try TPU instances for high RAM (340GB), caching large model activations needs it
- A100’s seemed nice, but are more expensive, aren’t available that often, and only support 40GB cuda RAM.
- Better manage sublists for paired scenarios
- For a time, I didn’t compare the tokenized dataset size to my original. Don’t forget to manage this if your pairwise dataset uses sublists because the tokenizer flattens them as if they were one string (i.e., [[eat,drink],[laugh,cry]] will be encoded as two, not four sequences). You may spot the discrepancy either as a wrong cardinality or in the token IDs within (an artifact in the middle of every tokenized data)
- As soon as I have time, I’ll change my pipeline to manage a dataset that can use native DataLoader shuffling and batching. This will get better gradients and save on training time.
- Add regularization earlier
- even if without it validation loss appears to “often” follow training loss closely
- this helped resolve reproducibility challenges between runs (for a while layers 22/28 were fairly consistent non-converging layers, but with more runs I noticed others did vary quite a bit - and some runs turned out with 28 having the 2nd best F1 score)
- Don’t despair: gradient descent can appear to make little improvements to loss even on hundreds of epochs (iterations), then plummet suddenly on training and/or validation. If models don’t converge, or they overfit, some trial and error with more epochs and creative troubleshooting.
Acknowledgements
I'm very grateful for Neel Nanda and Joseph Bloom for TransformerLens, which was vital to this exploration, and Trenton Bricken’s team at Anthropic for the inspiration I was able to take from their detailed approaches for decomposition of language models (even if I couldn't apply a SAE yet/this time)
Also shout out to Cara and Cameron, C, Luke, Steve and Akhil in the spring AI Safety Fundamentals course: it was awesome to be in the cohorts with you, learn with you, and bounce ideas. Looking forward to your project presentations.
GitHub Source
Edit (8/30): I addressed an unfinished sentence about hyperparameters.
0 comments
Comments sorted by top scores.