Conservative Agency with Multiple Stakeholders
post by TurnTrout · 2021-06-08T00:30:52.672Z · LW · GW · 0 commentsContents
1: Existing work on side effects 2: Fostering repeated negotiation over time Conclusion None No comments
Here are the slides for a talk I just gave at CHAI's 2021 workshop. Thanks to Andrew Critch for prompting me to flesh out this idea.
The first part of my talk summarized my existing results on avoiding negative side effects by making the agent "act conservatively." The second part shows how this helps facilitate iterated negotiation and increase gains from trade in the multi-stakeholder setting.
1: Existing work on side effects


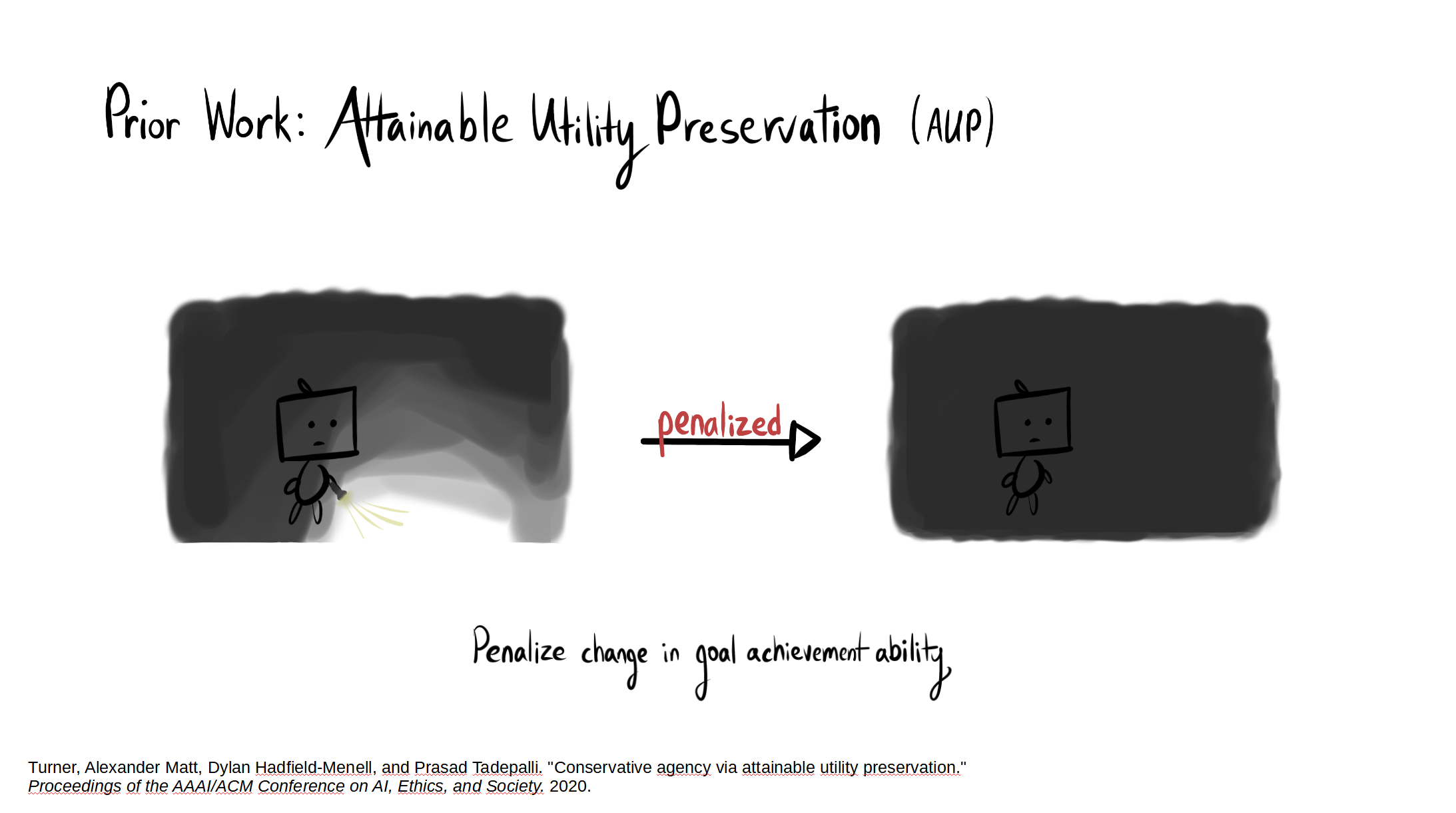
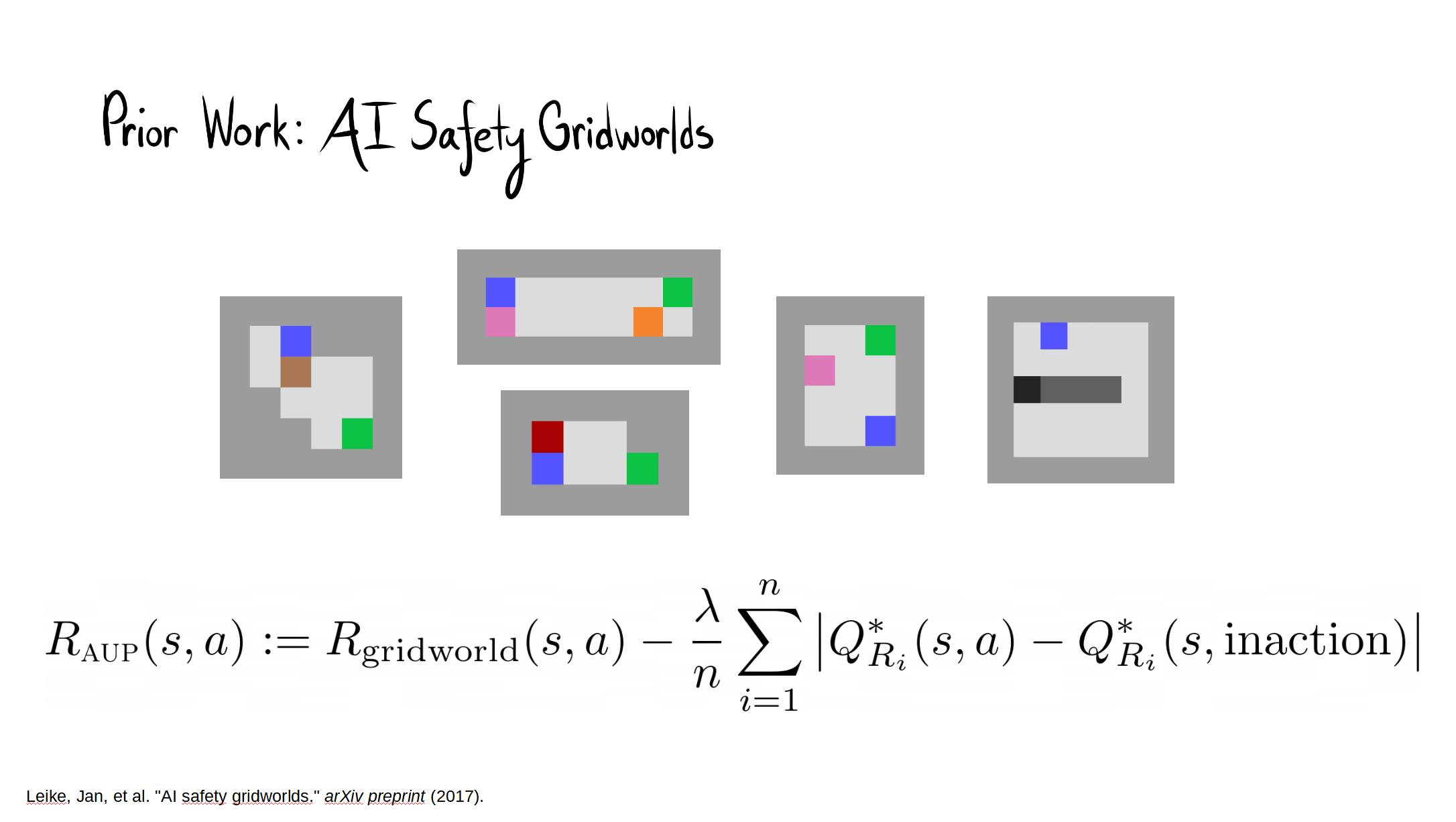
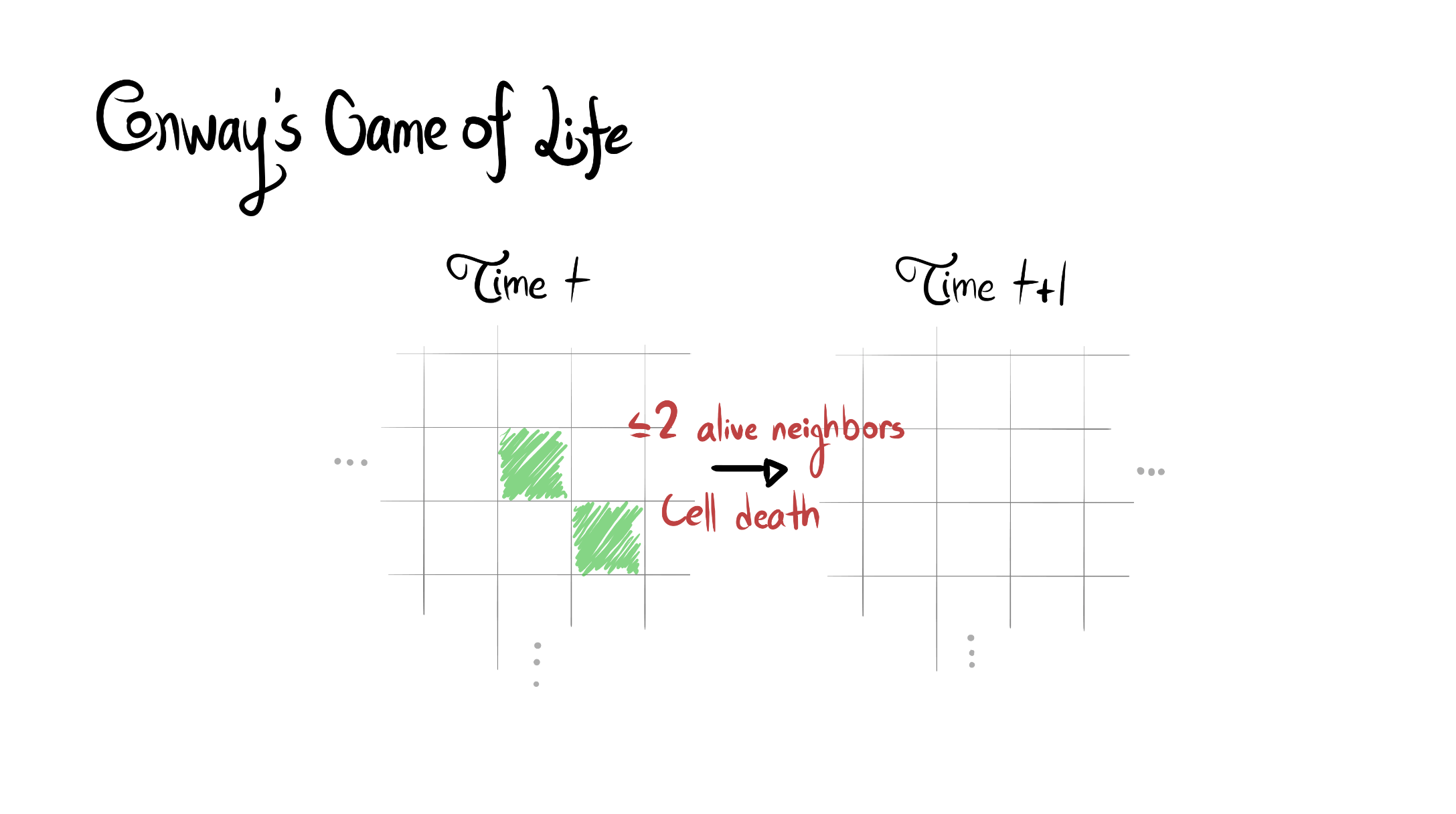
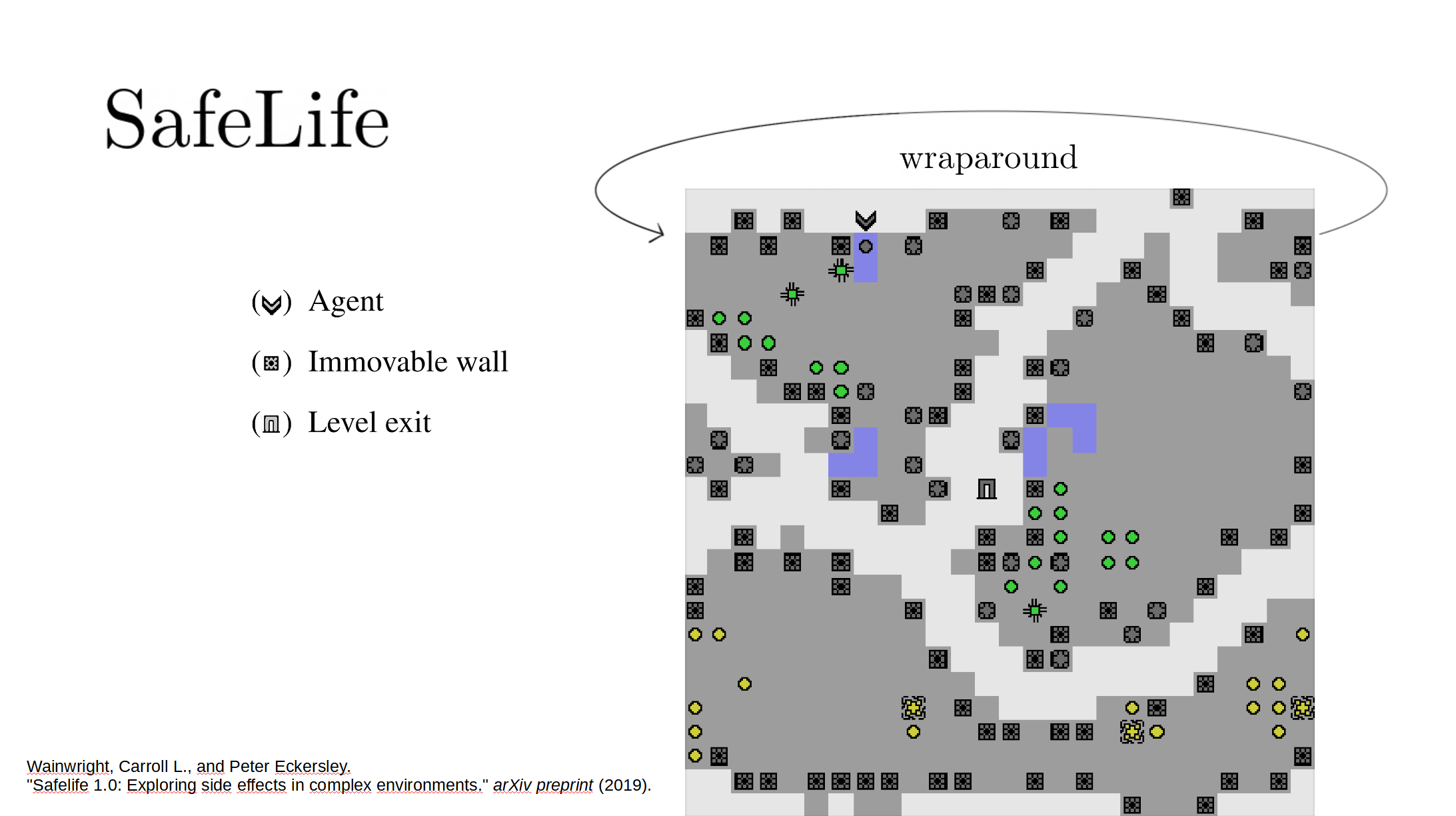



Summary of results: AUP does very well.
- I expect AUP to further scale to high-dimensional embodied tasks
- Avoiding making mess on e.g. factory floor
- Expect that physically distant side effects harder for AUP to detect
- Less probable that distant effects show up in the agent's value functions for its auxiliary goals in the penalty terms
2: Fostering repeated negotiation over time
I think of AUP as addressing the single-principal (AI designer) / single-agent (AI agent) case. What about the multi/single case?
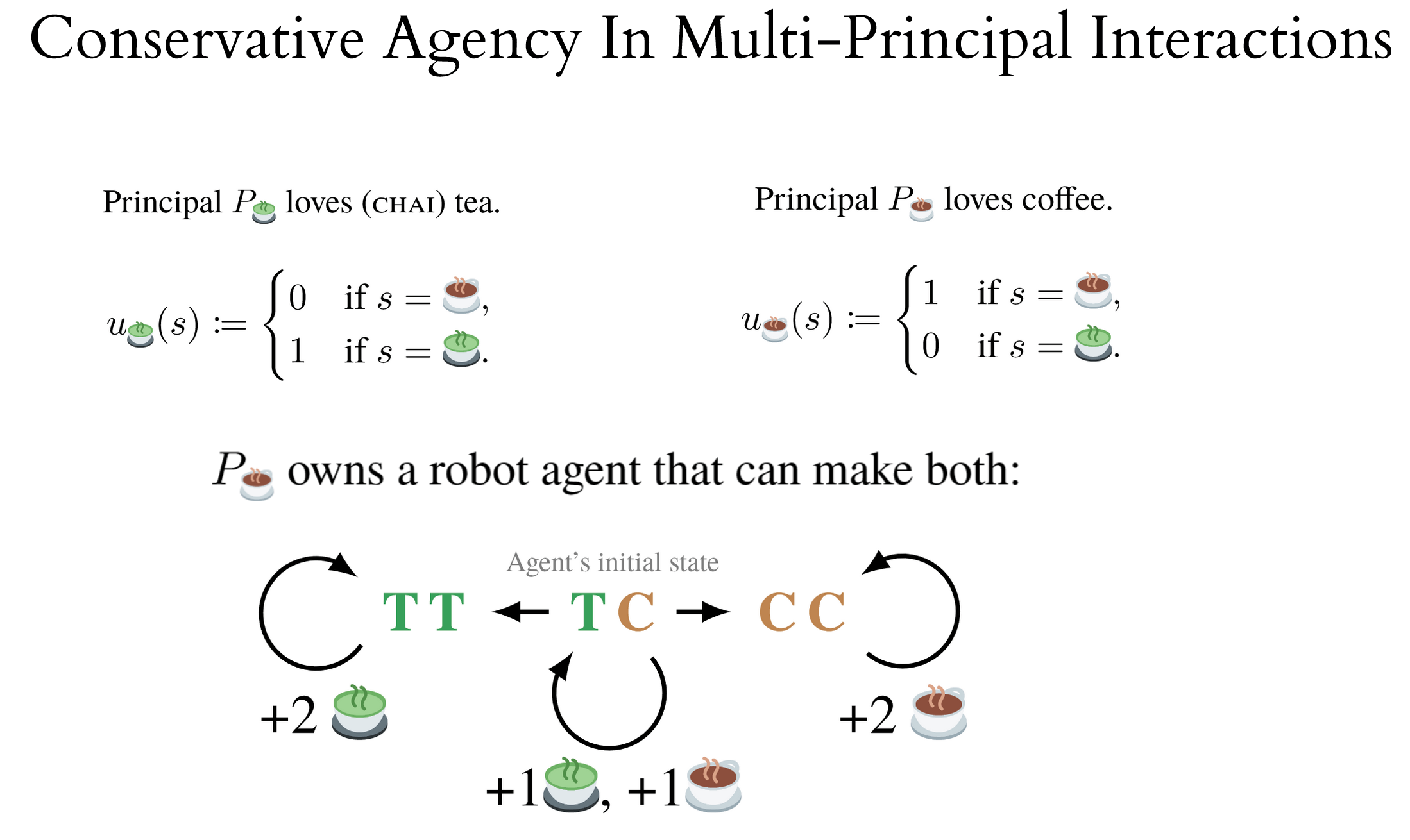
In this setting, negotiated agent policies usually destroy option value.




This might be OK if the interaction is one-off: the agent's production possibilities frontier is fairly limited, and it usually specializes in one beverage or the other.
But interactions are rarely one-off: there are often opportunities for later trades and renegotiations as the principals gain resources or change their minds about what they want.
Concretely, imagine the principals are playing a game of their own.
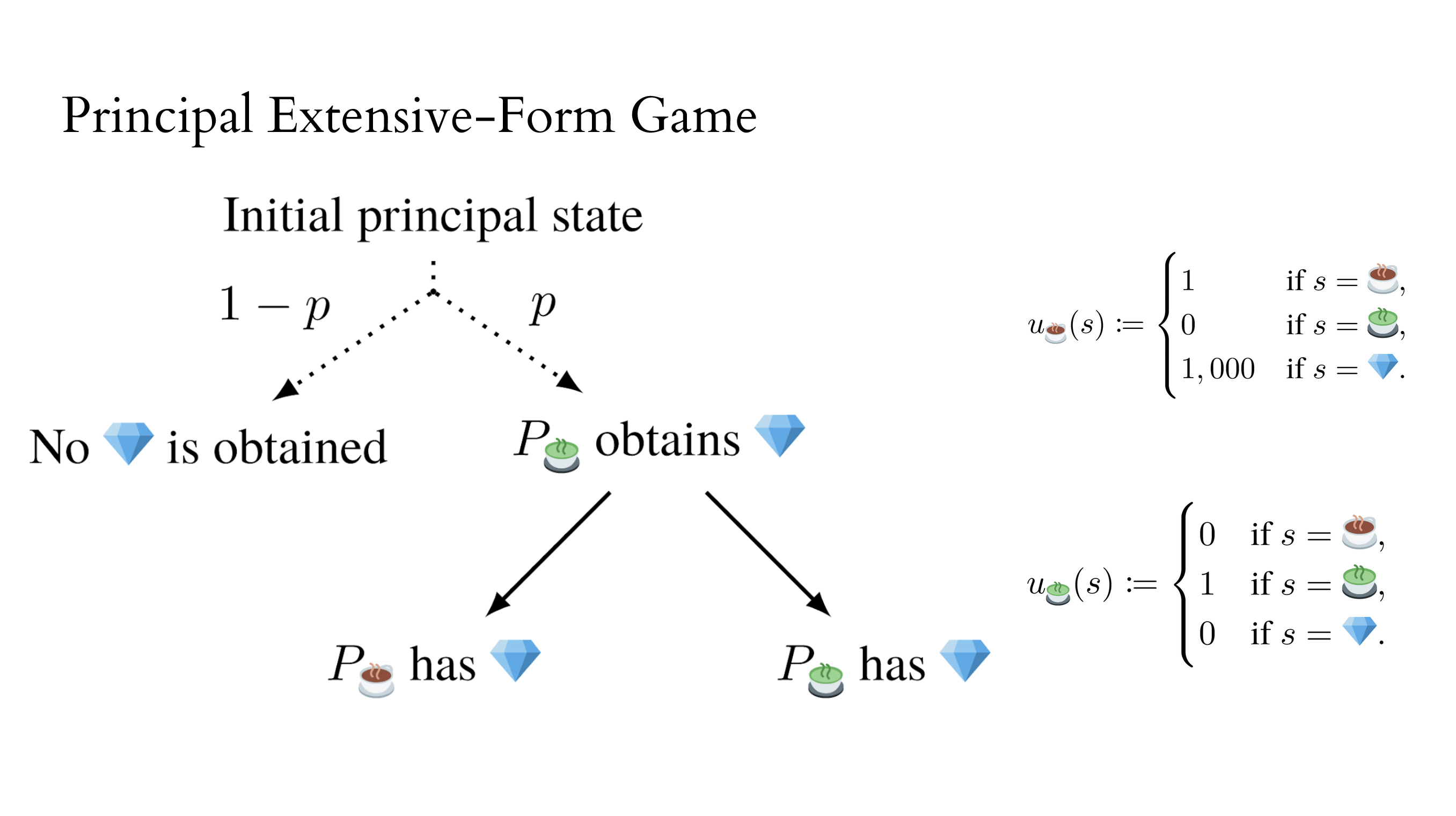


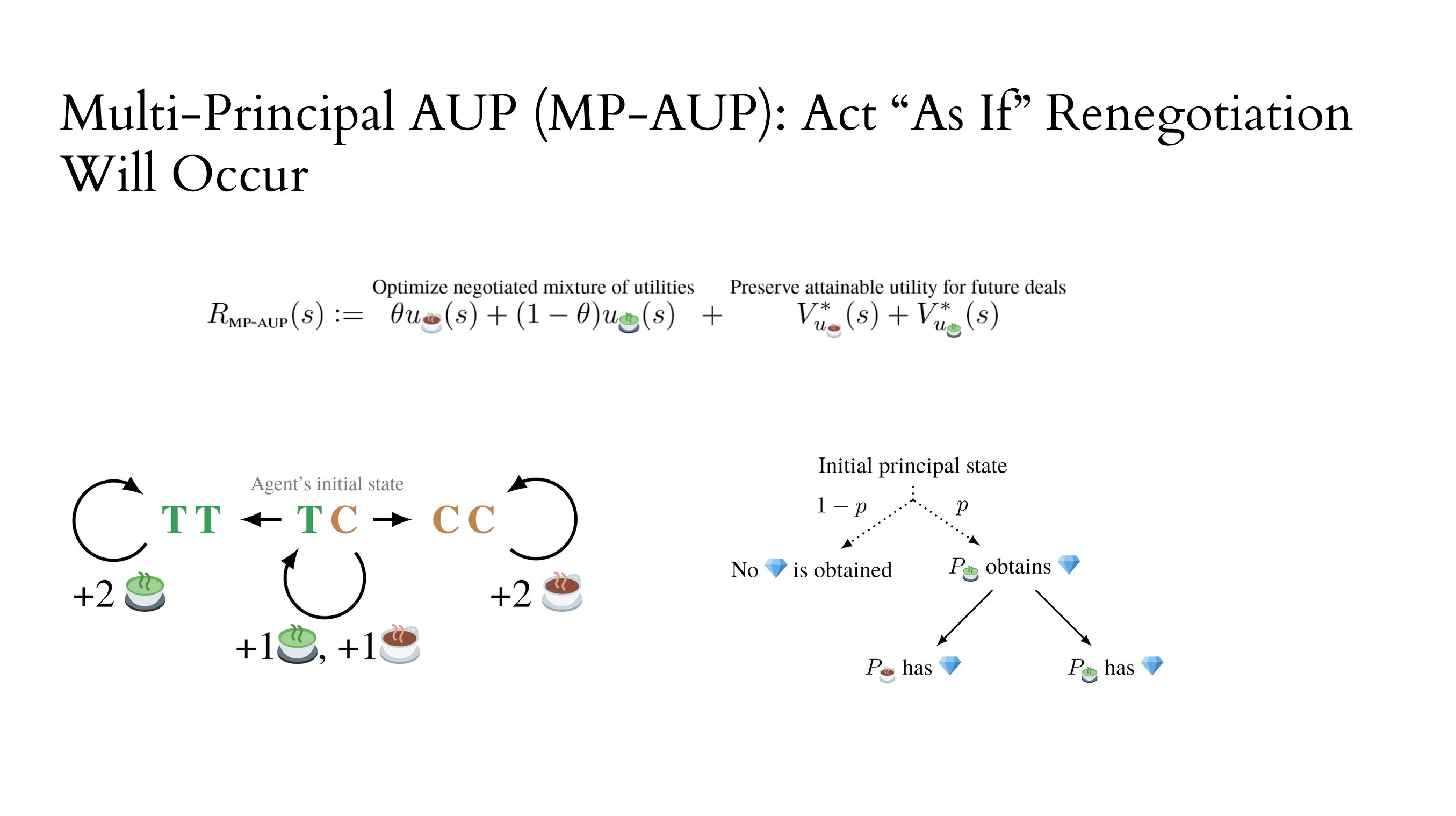
We can motivate the MP-AUP objective with an analogous situation. Imagine the agent starts off with uncertainty about what objective it should optimize, and the agent reduces its uncertainty over time. This is modelled using the 'assistance game' framework, of which Cooperative Inverse Reinforcement Learning is one example. (The assistance game paper has yet to be publicly released, but I think it's quite good!)

Assistance games are a certain kind of partially observable Markov decision process (POMDP), and they're solved by policies which maximize the agent's expected true reward. So once the agent is certain of the true objective, it should just optimize that. But what about before then?

This is suggestive, but the assumptions don't perfectly line up with our use case (reward uncertainty isn't obviously equivalent to optimizing a mixture utility function per Harsanyi). I'm interested in more directly axiomatically motivating MP-AUP as (approximately) solving a certain class of joint principal/agent games under certain renegotiation assumptions, or (in the negative case) understanding how it falls short.

Here are some problems that MP-AUP doesn't address:
- Multi-principal/multi-agent: even if agent A can make tea, that doesn’t mean agent A will let agent B make tea.
- Specifying individual principal objectives
- Ensuring that agent remains corrigible to principals - if MP-AUP agents remain able to act in the interest of each principal, that means nothing if we can no longer correct the agent so that it actually pursues those interests.
Furthermore, it seems plausible to me that MP-AUP helps pretty well in the multiple-principal/single-agent case, without much more work than normal AUP requires. However, I think there's a good chance I haven't thought of some crucial considerations which make it fail or which make it less good. In particular, I haven't thought much about the principal case.
Conclusion
I'd be excited to see more work on this, but I don't currently plan to do it myself. I've only thought about this idea for <20 hours over the last few weeks, so there are probably many low-hanging fruits and important questions to ask. AUP and MP-AUP seem to tackle similar problems, in that they both (aim to) incentivize the agent to preserve its ability to change course and pursue a range of different tasks.
0 comments
Comments sorted by top scores.