Visualise your own probability of an AI catastrophe: an interactive Sankey plot
post by MNoetel (mnoetel) · 2023-02-16T12:03:38.870Z · LW · GW · 2 commentsContents
2 comments
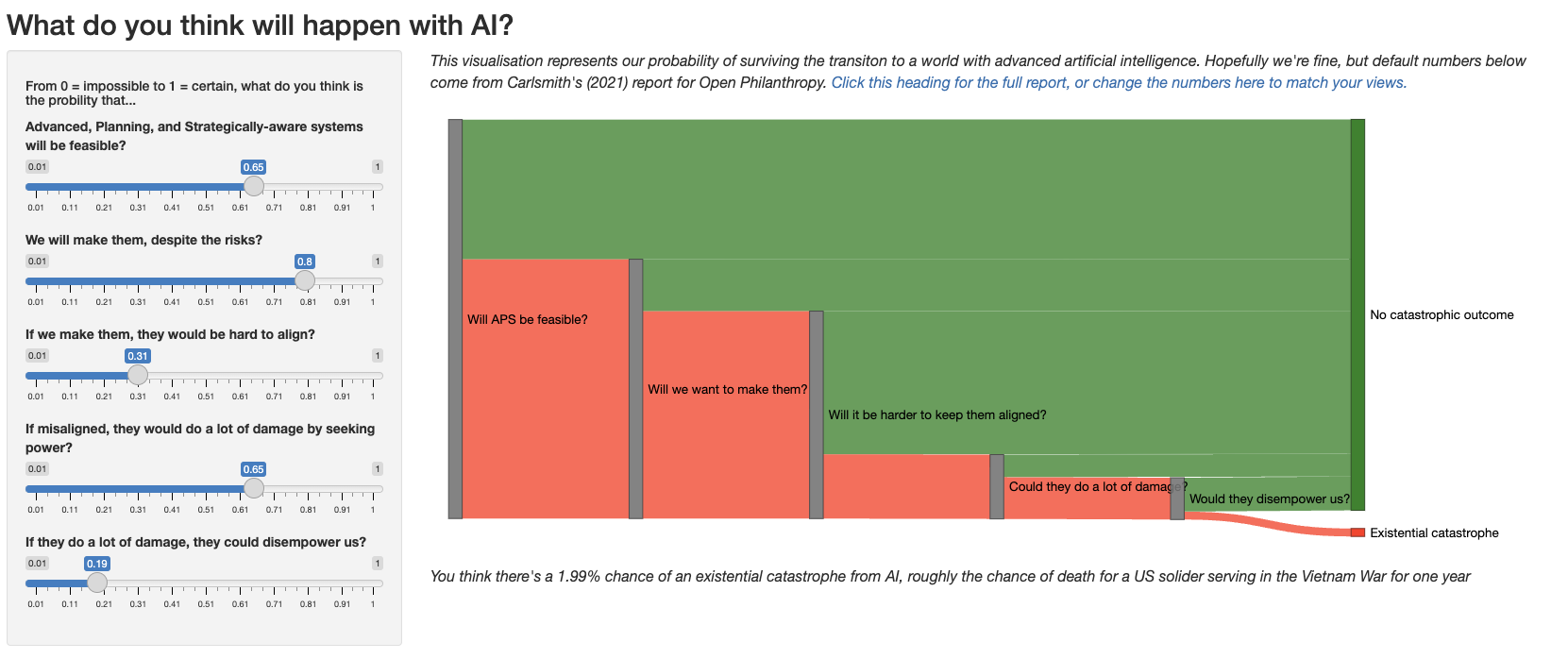
I wanted to help people learning about AI visualise their own probabilities of things going wrong. This Shiny app defaults to using the probabilities from Carlsmith's (2022) report from Open Philanthropy. You can enter your own probabilities and see how it cashes out. At the bottom, it translates your probability of doom into something more palpable (using a table from Leigh, 2021). There's an untidy Github repo for the project here, if you have any suggestions (or add them to the comments). Have fun.
2 comments
Comments sorted by top scores.
comment by exmateriae (Sefirosu) · 2023-02-16T13:52:19.184Z · LW(p) · GW(p)
Thank you, I will show this to a few people! (I'm at 12%...)
P.S: I liked the final statement around 100%
comment by JBlack · 2023-02-17T02:50:28.176Z · LW(p) · GW(p)
This presents the propositions as strictly conjunctive when they really are not. The first two arguably are conjunctive with the rest, but they're also the propositions that few people argue against.
The third proposition "if we make them, they would be hard to align" is quite vague. What exactly does "hard to align" mean? It is made conjunctive with "if misaligned, ..." and so would have to mean "of all such systems made in the future, at least one will be misaligned". This is not at all a central meaning of the question actually asked!
The fourth proposition is arguably even worse. It takes a specific scenario "do a lot of damage by seeking power" and makes it conjunctive with "if they do a lot of damage, ...". There are many ways that a misaligned AI can do damage without "seeking power". Even an aligned AI may cause a lot of damage, though I can see why we might want to ignore that possibility for AI safety purposes since it gets into the weeds of what is really meant by the word "aligned".
Then the question compounds the error by using the construction "they ... would", which implies that "a typical" misaligned AI would. If there are 10000 misaligned AIs in the world and someone judges only a 1% chance that any given misaligned AI would cause a lot of damage, someone could justifiably answer "1%" to this question while the actual conditional probability of "a lot of damage" is essentially 100%.
The final question is also not conjunctive. A powerful AI might disempower humanity without doing any actual damage at all, and the same criticism about "typical" vs "any" applies.
Without a lot of serious rephrasing, I rate this tool (and the reasoning behind it) as vastly more misleading than helpful.