The "Loss Function of Reality" Is Not So Spiky and Unpredictable
post by Thoth Hermes (thoth-hermes) · 2023-06-17T21:43:25.908Z · LW · GW · 0 commentsThis is a link post for https://thothhermes.substack.com/p/the-loss-function-of-reality-is-not
Contents
In other words, there are no "rabbit holes" or "dark tunnels of the mind." None No comments
In other words, there are no "rabbit holes" or "dark tunnels of the mind."
The great success of neural networks is due in large part to the surprising ease in which gradient-based methods are used to train them. Neural networks are often trained using a “loss function” which computes the error rate between predicted and observed values from its environment. The predictions are calculated based on an extremely large and complex function of millions or billions of parameters (the network itself). Since the loss function is merely a simple function between these predictions (outputs) and the values received from the environment, the loss function itself is an extremely high-dimensional function.
Gradient descent, the training method used with neural networks, can be intuitively thought of as “hill climbing” (actually hill descending, but this is isomorphic to the other). In this metaphor, the “parameters” of the model would be represented by the X and Y axes, and the “loss” would be represented by the Z axis, on a typical 3-dimensional graph. The problem, of course, is that the parameters of the model are typically far, far greater than two in number.
That doesn’t stop people from being able to visualize the network training using this metaphor, anyway.[1] Researchers have wanted to understand why and how gradient descent works so well, given that gradient updates are characterized by small, incremental “steps” down the hill. What if there are many hills? What if taking a step down the hill is in the overall wrong direction, if there is a longer, but less steep way to move down in the opposite direction?
Most gradient-descent methods make use of momentum, which means that if the incremental updates have been in largely the same direction for the past several iterations, the speed (magnitude) of the update is allowed to increase. This essentially allows for lots of hills, but assumes that the overall correct direction would mainly be in the same general direction - imagine walking down a large crater with lots of little bumps and rocks all over the slope.
In the early days of neural networks, they were widely thought to be difficult to train.[2] This was largely due to the belief that optimization processes would converge to “local minima” with error rates far higher than the global minimum. This belief persisted for quite some time, until empirical evidence showed that for most learning problems of interest, most local minima were actually at acceptable error rates, as well as located at mostly the same height.[3] This meant that neural networks could be trained starting from any initialization point and could be relied upon to arrive at a solution that generalized well to out-of-training data points.
It is here that I need to make a small digression. My main argument requires that it is possible to apply lessons from machine learning theory to the domain of intelligence in general. Therefore, I want to note that one of my primary assumptions is that “metaphors” as well as abstractions are relatively valid as well as useful in general. I think this is a fairly deep and profound-feeling insight, as well as one that may need to be argued for separately from this piece. I also think that this profound-feeling quality of this insight is an important clue, and seems to point even to where the feeling itself comes from: Being able to apply concepts learned from one domain into one that is seemingly unrelated is a very fortunate happenstance of the universe.
Imagine if it were not generally possible to do this. It would make learning a lot more difficult to do, in general. Overfitting and lack-of-generalization beyond the training data would stunt capabilities development, too. It would also mean that human beings would branch into various specialties in which it would be too difficult for most people to switch between. General intelligence would either be very difficult to evolve at all, or only an illusion.
It turns out that Scott Alexander published a highly-related blog post while I was working on this one. So this is good, that means this subject is important and relevant in general. He is using the exact same metaphors as I am in this blog post in the exact same way. Fortunately, this means that in the scenario where he and I disagree on this topic, that we both act as counter-factual theorem-prover-helpers to each other. This means that we should collectively be able to arrive at the truth even via an adversarial process.
So if our usage of this metaphor is valid, then it is possible that “The Loss Function of Reality” either is spiky and unpredictable, or is not. If it is, we have more problems than if it isn’t. So we hope that it isn’t.
I think Scott is leaning more towards that it is.
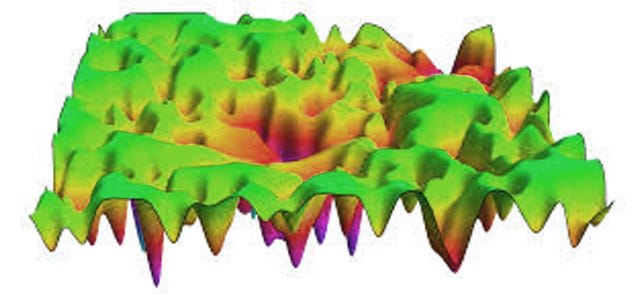
If it is, then this implies a few fairly depressing things:
- It would be possible to “get stuck” believing in some ideas that seem true but actually aren’t.
- The danger of believing in some false ideas would not be apparent until after they had caused irreparable harm to the one holding them.
- Things like drug addictions and mental illnesses would just be more difficult to treat. Addictions would be both harder to manage as well as have worse negative consequences, in general.
- Mental illnesses would correspond to those pernicious “local minima” in the energy / loss landscape that would be difficult to climb out of.
So what is very interesting that we find is that although this loss / energy landscape metaphor works just fine, it actually does not resemble the above picture, corresponding to the pessimistic and cynical scenario. We have enough empirical data now that we know that “saddle points” are actually the vast majority of all minima in high dimensions, as well as that most optimizers simply don’t get “trapped” by anything in practice.[4][5]A saddle point means there is always a direction to move in that allows the loss to decrease.

Deep-learning researchers have apparently figured out that many local minima plaguing gradient-descent based training methods are not a big problem, and have been successfully tackled by a handful of relatively non-complicated architecture and algorithm choices. So the question is, does this metaphor extend to all theoretical intelligences, humans and AI alike?
Well, if my decision to use the moniker “The Loss Function of Reality” as a name for some theoretical object is reasonable, then that would imply that both the problem of humans trying to create an aligned AI as well as the loss function that this AI itself would be subject to are lower-dimensional subspaces of this same Loss Function of Reality. So if this Loss Function of Reality is spiky and unpredictable, then both we as well as a recursively self-improving AI would encounter a lot of trouble trying to pursue our respective goals.[6]
What does this loss function not being spiky and unpredictable mean, in practice, for us humans, in every day life? Well, given that we take actions, learn from them, and update our views, it seems possible that one could wonder how much danger we could encounter along the way, and pick an appropriate strategy accordingly.
If we encounter mainly saddle points, then we would expect that it would never “hurt” to go in the correct direction. Hurting would correspond to an increase in the loss function value, which would only happen if we needed to escape from a local minimum. In fact, we should choose the direction that feels better to update towards. So if you were to think, for example, “I am a shitty person,” it would probably be more painful to think it than to not think it. Therefore, think something better (which would also be more true!).
It probably means that in the long run, over the course of many different lives lived, people likely move to better, more true beliefs, which are more stable, and encounter less harm. Mental illnesses and addictions are manageable and people are capable of learning to deal with them or overcome them, even on their own. This would be more true the more the “saddle point” picture is true vs. the “local minima” picture.
I’m going to make another small digression to point out that the “local minima” picture can be reflected in the way that certain political tribes prefer to treat their opponent tribes:
This is a cynical viewpoint, which is designed to display smug moral superiority[7](which is ironic, given that it implies that no one can actually be sure). Perhaps it allows one to feel superior to those who lived in the past. Or perhaps to those who today seem to feel happy being actively engaged in doing things that they like doing as well as believe makes the world a better place to live in. But whatever his motive for saying this is, its effect is nullified by the fact that it trivially invalidates anyone’s attempts to do the right thing. Clearly, Lex Fridman believes that someone holds the moral high-ground - we can assume that he intended it to sway certain people one way or another.
If we take on his belief at face-value, it would also correspond to a spiky-and-unpredictable loss function. I also argue that Fridman’s position is pessimistic, since most who read it would probably either disagree, or feel dissuaded or embarrassed about feeling too enthusiastic about some cause, at most. Personally, I am not entirely sure how he would expand on this point, if he were asked to.
If one can do evil while trying to do good, the biggest question that immediately arises from this is, what purpose does the label “evil” serve when used to describe these actions? Is it only used in hindsight, or from the vantage point of someone with superior knowledge? Does it imply that the evil-doer made preventable mistakes, that were only committed because they felt overly-confident, or assumed to know things that were ultimately wrong? Do they deserve punishment and scorn, that the label usually provides to the one labeled?[8]
Well, if the loss function is spiky and unpredictable, then one thing we can say with confidence is that it would be more often dangerous to act than to not act, for most scenarios in which we have options. It would be safer to stay wherever we are, for the most likely location we are at any moment we have the time to reflect on it is at a local minimum. Here, moving in any direction will increase error and thus hurt, and even if we move into another local minimum, there is no guarantee that it will be any lower than the one we were in previously. Thus, pessimists would be inclined to do less in general. This is pretty much what depression is!
Because the pessimistic view is itself self-punishing, it is really the only thing that would correspond to a local minimum, if those existed. However, moving away from the pessimistic picture is an immediate update which decreases hurt, which means that it could only have been a saddle point to begin with.
- ^
https://arxiv.org/abs/1712.09913
- ^
https://www.deeplearningbook.org/contents/optimization.html (Section 8.2).
- ^
https://arxiv.org/abs/1406.2572
- ^
For the intuitions as to why this is: The Hessian matrix in n-dimensions describes the second-order partial derivatives of the loss-function. Local minima / maxima only occur when all the eigenvalues of the Hessian have the same sign. Probabilistically, this is unrealistic in higher-dimensions, and exponentially less likely in n. Saddle points correspond to mixed signs of the eigenvalues.
- ^
http://proceedings.mlr.press/v49/lee16.pdf
- ^
For example, we would have trouble aligning the AGI which in turn would face difficulty aligning its successors or modified versions of itself.
- ^
I assert, but feel free to be more charitable than I.
- ^
Punishment and scorn would be the only way to (artificially) produce a loss landscape which has anything resembling local minima, if the saddle point picture is correct.
0 comments
Comments sorted by top scores.