Mech Interp Puzzle 2: Word2Vec Style Embeddings
post by Neel Nanda (neel-nanda-1) · 2023-07-28T00:50:00.297Z · LW · GW · 4 commentsContents
4 comments
Code can be found here. No prior knowledge of mech interp or language models is required to engage with this.
Language model embeddings are basically a massive lookup table. The model "knows" a vocabulary of 50,000 tokens, and each one has a separate learned embedding vector.
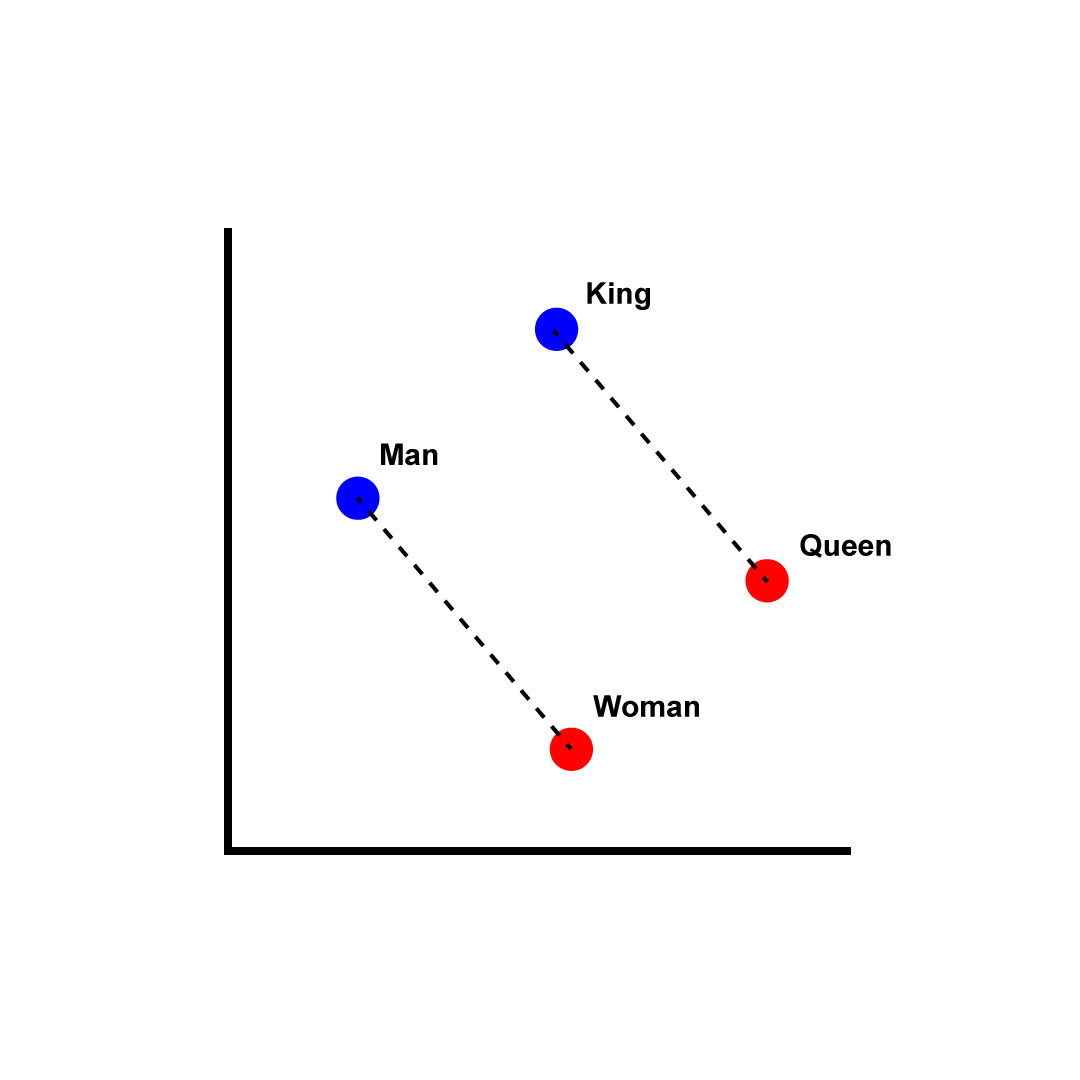
But these embeddings turn out to contain a shocking amount of structure! Notably, it's often linear structure, aka word2vec style structure. Word2Vec is a famous result (in old school language models, back in 2013!), that `man - woman == king - queen`. Rather than being a black box lookup table, the embedded words were broken down into independent variables, "gender" and "royalty". Each variable gets its own direction, and the embedded word is seemingly the sum of its variables.
One of the more striking examples of this I've found is a "number of characters per token" direction - if you do a simple linear regression mapping each token to the number of characters in it, this can be very cleanly recovered! (If you filter out ridiculous tokens, like 19979: 512 spaces).

Notably, this is a numerical feature not a categorical feature - to go from 3 tokens to four, or four to five, you just add this direction! This is in contrast to the model just learning to cluster tokens of length 3, of length 4, etc.
Question 2.1: Why do you think the model cares about the "number of characters" feature? And why is it useful to store it as a single linear direction?
There's tons more features to be uncovered! There's all kinds of fundamental syntax-level binary features that are represented strongly, such as "begins with a space".

Question 2.2: Why is "begins with a space" an incredibly important feature for a language model to represent? (Playing around a tokenizer may be useful for building intuition here)
You can even find some real word2vec style relationships between pairs of tokens! This is hard to properly search for, because most interesting entities are multiple tokens. One nice example of meaningful single token entities is common countries and capitals (idea borrowed from Merullo et al). If you take the average embedding difference for single token countries and capitals, this explains 18.58% of the variance of unseen countries! (0.25% is what I get for a randomly chosen vector).
Caveats: This isn't quite the level we'd expect for real word2vec (which should be closer to 100%), and cosine sim only tracks that the direction matters, not what its magnitude is (while word2vec should be constant magnitude, as it's additive). My intuition is that models think more in terms of meaningful directions though, and that the exact magnitude isn't super important for a binary variable.

Question 2.3: A practical challenge: What other features can you find in the embedding? Here's the colab notebook I generated the above graphs from, it should be pretty plug and play. The three sections should give examples for looking for numerical variables (number of chars), categorical variables (begins with space) and relationships (country to capital). Here's some ideas - I encourage you to spend time brainstorming your own!
- Is a number
- How frequent is it? (Use pile-10k to get frequency data for the pile)
- Is all caps
- Is the first token of a common multi-token word
- Is a first name
- Is a function word (the, a, of, etc)
- Is a punctuation character
- Is unusually common in German (or language of your choice)
- The indentation level in code
- Relationships between common English words and their French translations
- Relationships between the male and female version of a word
Please share your thoughts and findings in the comments! (Please wrap them in spoiler tags [LW · GW])
4 comments
Comments sorted by top scores.
comment by Eric J. Michaud (ericjmichaud) · 2023-07-31T19:59:40.951Z · LW(p) · GW(p)
I checked whether this token character length direction is important to the "newline prediction to maintain text width in line-limited text" behavior of pythia-70m. To review, one of the things that pythia-70m seems to be able to do is to predict newlines in places where a newline correctly breaks the text so that the line length remains approximately constant. Here's an example of some text which I've manually broken periodically so that the lines have roughly the same width. The color of the token corresponds to the probability pythia-70m gave to predicting a newline as that token. Darker blue corresponds to a higher probability. I used CircuitsVis for this:

We can see that at the last couple tokens in most lines, the model starts placing nontrivial probability of a newline occurring there.
I thought that this "number of characters per token" direction would be part of whatever circuit implements this behavior. However, ablating that direction in embedding space seems to have little to no effect on the behavior. Going the other direction, manually adding this direction to the embeddings seems to not significantly effect the behavior either!
Maybe there are multiple directions representing the length of a token? Here's the colab to reproduce: https://colab.research.google.com/drive/1HNB3NHO7FAPp8sHewnum5HM-aHKfGTP2?usp=sharing

↑ comment by Neel Nanda (neel-nanda-1) · 2023-07-31T21:46:15.049Z · LW(p) · GW(p)
Oh that's fascinating, thanks for sharing! In the model I was studying I found that intervening on the token direction mattered a lot for ending lines after 80 characters. Maybe there are multiple directions...? Very weird!
comment by abhatt349 · 2023-07-31T21:05:07.880Z · LW(p) · GW(p)
My rough guess for Question 2.1:
The model likely cares about number of characters because it allows it to better encode things with fixed-width fonts that contain some sort of spatial structure, such as ASCII art, plaintext tables, 2-D games like sudoku, tic-tac-toe, and chess, and maybe miscellaneous other things like some poetry, comments/strings in code[1], or the game of life.
A priori, storing this feature categorically is probably a far more efficient encoding/representation than linearly (especially since length likely has at most 10 common values). However, the most useful/common operation one might want to do with this feature is “compute the length of the concatenation of two tokens,” and so we also want our encodings to facilitate efficient addition. For a categorical embedding, we’d need to store an addition lookup table, which requires something like quadratic space[2], whereas a linear embedding would allow sums to be computed basically trivially[3].
This argument isn’t enough on its own, since we also need to move the stored length info between tokens in order to add them, which is severely bottlenecked by the low rank of attention heads. If this were “more of a bottleneck” than the type of MLP computation that’s necessary to implement an addition table, then it’d make sense to store length categorically instead.
I don’t know if I could’ve predicted which bottleneck would’ve won out before seeing this post. I suspect I would’ve guessed the MLP computation (implying a linear representation), but I wouldn’t have been very confident. In fact, I wouldn’t be surprised if, despite length being linearly represented, there are still a few longer outlier tokens (that are particularly common in the context of length-relevant tasks) whose lengths are stored categorically and then added using something like a smaller lookup table.
- ^
The code itself would, of course, be the biggest example, but I’m not sure how relevant non-whitespace token length is for most formatting
- ^
In particular, you’d need a lookup table of at least size , where is the longest single string you’d want to track the length of, and is the length of the longest token. I expect to be on the order of hundreds, and to be at most about 10 (since we can ignore a few outlier tokens)
- ^
linear operations are pretty free, and addition of linearly represented features is as linear as it gets
comment by Sterrs (sterrs) · 2023-07-28T22:40:49.917Z · LW(p) · GW(p)
Very interesting. I'll play around with the code next time I get the chance.
2.1)
Being able to solve crosswords requires you to know how long words are. I have no idea how common they were in the training data though. Aligning things in text files is sometimes desirable, Python files are supposed to limit line lengths to 80 characters, some Linux system files store text data in tables with whitespace to make things line up. ASCII art also uses specific line lengths.
My guess for linearity would be so that the sum of the vectors has the length of their concatenation e.g. to work out the lengths of sentences.
I wonder if "number of syllables" is a feature, and whether this is consistent between languages?
2.2)
If the language model has finished outputting a word, it needs to be able to guarantee a space comes next to avoid writingtextlikethis. I guess one would expect tokens to be close in the embedding to their copies with spaces in front, so to control the position of spaces in text the model would like a separate direction to encode that information.