UML IV: Linear Predictors
post by Rafael Harth (sil-ver) · 2020-07-08T19:06:05.269Z · LW · GW · 0 commentsContents
Binary Linear Classification The Perceptron algorithm Linear Programming The inhomogeneous case Linear Regression Logistic Regression None No comments
(This is the fourth post in a series on Machine Learning based on this book. Click here [LW · GW] for part one. If you have some background knowledge, this post might work as a stand-alone read.)
The mission statement for this post is simple: we wish to study the class of linear predictors. There are linear correlations out there one might wish to learn; also linear stuff tends to be both efficient and simple, so they may be a reasonable choice even if the real world is not quite linear. One can also build more sophisticated classifiers by using linear predictors as building blocks, but not in this post).
In school, a function is linear iff you can write it a . In higher math, a function is linear iff for all . In the the case of , this condition holds iff it can be written as for some parameter vector . So the requirement is stronger – we do not allow the constant term the school definition has – but one also considers higher dimensional cases. The case where we do allow a constant factor is called affine-linear, and we also say that a function is homogeneous iff , which (in the case of affine-linear functions) is true iff there is no nonzero constant factor.
In Machine Learning, the difference between linear and affine-linear is not as big of a deal as it is in other fields, so we speak of linear predictors while generally allowing the inhomogeneous case. Maybe Machine Learning is more like school than like university math ;)
For and some , a class of linear predictors can be written like so:
Let's unpack this. Why do we have an inner-product ⟨⋅⟩ here? Well, because any function can be equivalently written as , where . The inner-product notation is a bit more compact, so we will prefer it over writing a sum. Also note that, for this post, bold letters mean "this is a vector" while normal letters mean "this is a scalar". Secondly, what's up with the ? Well, the reason here is that we want to catch a bunch of classes at once. There is the class of binary linear classifiers where but also the class of linear regression predictors where . (Despite what this sequence has looked like thus far, Machine Learning is not just about binary classification.) We get both of them by changing . Concretely, we get the linear regression functions by setting , i.e., the function that sends all positive numbers to 1 and all negative numbers to . The notation for any set denotes the indicator function that sends all elements in to 1 and all others in its domain to 0.
For the sake of brevity, one wants to not write the constant term but still have it around, and to this end, one can equivalently write the class as
where it is implicit that . Then, the final part of the inner product will add the term , so will take on the role of c in the previous definition.
We still need to model how the environment generates points. For this section, we assume the simple setting of a probability function D over X only and a true function of the environment. We also need to define empirical loss functions for a training sequence . For binary classification, we can use the usual one that assigns h the number . Since we will now look at more than one loss function, we will have to give it a more specific name than , so we will refer to it as , indicating that every element is either correctly or incorrectly classified. We call this the 0-1 loss even though the label set is now .
For regression (where ), this is a poor function since hitting the precisely correct element in is not a reasonable expectation – and if 3.8 is the correct answer, then is a better guess than 17. Instead, we want to penalize the predictor based on how far it went off the mark. If , then we define the squared distance loss function as and the absolute distance loss function as .
We begin with binary linear classification.
Binary Linear Classification
A binary linear classifier separates the entire space in two parts along a hyperplane. (A hyperplane in is a dimensional subspace.) This is quite easy to visualize. In the homogeneous case, the hyperplane will go through the origin, whereas in the inhomogeneous case, it may not.

Let's work out why this is so. A point is sent to , do it gets classified positively iff is greater than 0. Suppose we're somewhere in the red area where this is not the case, and now we move into the direction of . At some point, we will be at a place where the inner product is exactly 0. Now, if we move into a direction orthogonal to , the inner product doesn't change. This corresponds to the hyperplane that is visualized in the pictures above.
In linear classification problems, we say that a problem is separable iff there exists a vector whose predictor gets all points in the training sequence right. In the book, this distinction is also frequently made for other learning tasks, where a problem is called realizable iff there exists a perfect predictor. For linear predictors, the space might be very high dimensional, which makes this assumption more plausible. As an example, suppose we model text documents as vectors, where there is one dimension for every possible term, and one sets the coordinate for the word "crepuscular" to the number of appearances of the word "crepuscular" in the document. With dimensions at hand, it might not be so surprising if a hyperplane classifies all domain points perfectly.
How do we train a linear classifier? The book discusses two different algorithms. For both, we shall first assume that we are in the homogeneous case. We start with the Perceptron algorithm.
The Perceptron algorithm
Since our classifier is completely determined by the choice of , we will refer to it as . Thus .
Recall that ha measures how similar a label point is to a and classifies it as 1 if it's similar enough (and as otherwise). This leads to a very simple algorithm: we start with ; then at iteration t we take some pair that is not classified correctly – i.e., where either even though or even though – and we set . If was classified as even though , then we add , thereby making more similar to than , and if was classified as 1 even though , then we subtract , thereby making less similar to than . In both cases, our classifier updates into the right direction. And that's it; that's the perceptron algorithm.
It's not obvious that this will ever terminate – while updating towards one point will make the predictor better about that point, it might make it worse about other points. However, there is a theorem stating that it does, in fact, terminate provided the problem is separable. The proof is partially interesting but also technical, so I'll present a sketch that includes the key ideas but hides some of the details.
The main idea is highly non-trivial. We assume there is no point directly on the separating hyperplane, then we begin by choosing a vector a∗ whose predictor classifies everything correctly (which exists because we assume the separable case) and also has scalar product at least 1 with every positive point (take one that satisfies the first condition and divide it by the smallest norm of any positively labelled point). Now we observe that the similarity between at and a∗ increases as t increases. This is so because , and the term is positive since is by assumption such that . This shows that grows as t grows.
The proof then proceeds like this:
- Establish a lower bound on the growth rate of
- Establish an upper bound on the growth rate of
- Observe that is a constant
- Observe that must hold because it's the famous Cauchy-Schwartz inequality
- Conclude that, as a consequence of the four facts above, the term t can only grow for a limited number of iterations
We obtain a bound that depends on the norm of the smallest vector such that for all domain points and on the largest norm of any domain point. This bound might be good or it might not, depending on the case at hand. Of course, the algorithm may always finish much earlier than the bound suggests.
Linear Programming
Linear programming is an oddly chosen name for a problem of the following form:
where and and are given. So we have a particular direction, given by , and we want to go as far into this direction as possible; however, we are restricted by a set of constraints – namely the many constraints that follow from the equation . Each constraint is much like the predictor from the previous section; it divides the entire space into two parts along a hyperplane, and it only accepts points in one of the two halves. The set of points which are accepted by all constraints is called the feasible region, and the objective is to find the point in the feasible region that is farthest in the direction of u.
Here is a visualization for d=2 and n=3:

Once we hit the triangle's right side, we cannot go any further in precisely the direction of u, but going downward along that side is still worth it, because it's still "kind of" like u – or to be precise, if is the vector leading downward along the rightmost side of the triangle, then , and therefore points which lie further in this direction have a larger inner product with . Consequently, the solution to the linear program is at the triangle's bottom-right corner.
The claim is now that finding a perfect predictor for a separable linear binary classification problem can be solved by a linear program. Why is this? Well for one, it needs to correctly classify some number of points, let's say , so it needs to fulfil conditions, which sounds similar to meeting constraints. But we can be much more precise. So far, we have thought of the element that determines the classifier as a vector and of all domain elements as points, but actually they are the same kind of element in the language of set theory. Thus, we can alternatively think of each domain element as a vector and of our element a determining the classifier as a point. Under this perspective, each splits the space in two halves along its own hyperplane, and the point a needs to lie in the correct half for all hyperplanes) for it to classify all 's correctly. In other words, each behaves exactly like a linear constraint.
Thus, if , then we can formulate our set of constraints as (not ≥0 because we want to avoid points on the hyperplane), where
i.e. the matrix whose row vectors are either the elements (if ) or the elements scaled by (if ). The -th coordinate of the vector equals precisely , and this is the term which is positive iff the point is classified correctly, because then has the same sign as .
We don't actually care where in the feasible region we land, so we can simply set some kind of meaningless direction like .
So we can indeed rather easily turn our classification problem into a linear program, at least in the separable case. The reason why this is of interest is that linear programs have been studied quite extensively and there are even free solvers online.
The inhomogeneous case
If we want to allow a constant term, we simply add a 1 at the end of every domain point, and search for a vector that solves the homogeneous problem one dimension higher. This is why the difference of homogeneous vs inhomogeneous isn't a big deal.
Linear Regression
Linear regression is where we first need linear algebra and vector calculus.
Recall that, in linear regression, we have and and a predictor for some is defined by the rule . Finally, recall that the empirical squared loss function is defined as . (We set .) The is not going to change where the minimum is, so we can multiply with to get rid of it; then the term we want to minimize looks like this:
In order to find the minimum, we have to take the derivative with regard to the vector . For a fixed , the summand is . Now the derivative of a scalar with respect to a vector is defined as
so we focus on one coordinate and compute the derivative of the such a summand term with regard to . By applying the chain rule, we obtain . This is just for one summand; for the entire sum we have . So this is the -th coordinate of a vector that needs to be zero everywhere. The entire vector then looks like this:
Now, through a process that I haven't yet been able to gain any intuition on, one can reformulate this as , where is the matrix whose column vectors are the , and .
Now if is invertible the problem is easy; if not then it is still solvable, since one can prove that b is always in the range of (but I'll skip the proof). It helps that is symmetric.
Logistic Regression
Binary classification may be inelegant in sort of the same way that committing to a hypothesis class ahead of time is elegant – we restrict ourselves to a binary choice, and throw out all possibility of expressing uncertainty. The difference is that it may actually be desirable in the case of binary classification – if one just has to go with one of the labels, then we can't do any better. But quite often, knowing the degree of certainty might be useful. Moreover, even if one does just want to throw out all knowledge about the degree of certainty for the final classifier, including it might still be useful during training. A classifier that gets 10 points wrong, all of which firmly in the wrong camp, might be worse choice than a classifier which gets 11 points wrong, all of which near the boundary (because it is quite plausible that the first predictor just got "lucky" about its close calls and might actually perform worse in practice).
Thus, we would like to learn a hypothesis which, instead of outputting a label, outputs a probability that the label is 1, i.e. a hypothesis of the form h:X→Y where Y=[0,1]. For this, we need to be of the form , and it should be monotonically increasing. There are many plausible candidates; one of them is the sigmoid function defined by the rule . Its plot looks like this:
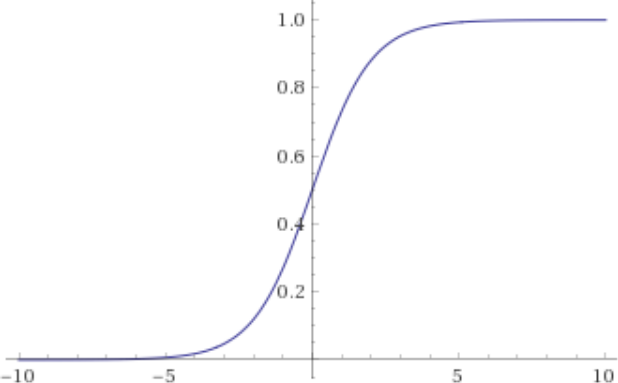
In practice, one could put a scalar in front of the to adjust how confident our predictor will be.
How should our loss function be defined for logistic regression? In the case of y=1, we want to penalize probability mass, and in the case of , we want to penalize the missing probability mass to 1. Both is achieved by setting
This is how it looks in the case of y=1:
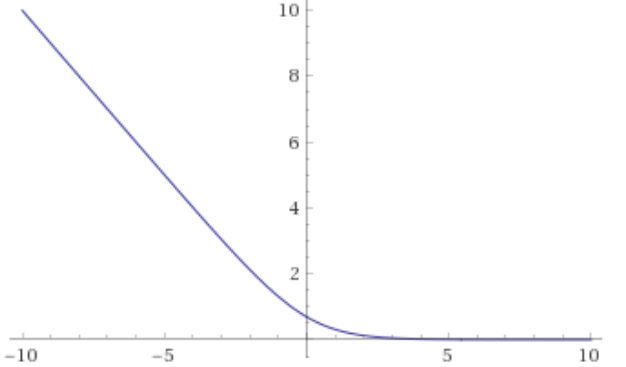
And the case of is symmetrical.
0 comments
Comments sorted by top scores.