Calibration training for 'percentile rankings'?
post by david reinstein (david-reinstein) · 2024-09-14T21:51:55.705Z · LW · GW · No commentsThis is a question post.
Contents
Does this tool/site exist? What's the best/easiest way to build it? Context Evaluation percentile ratings Internal prioritization ratings None No comments
Does this tool/site exist? What's the best/easiest way to build it?
I'm looking to find or build a tool for calibration training for 'percentile rankings'.
E.g., give me a list of dog photos to rate out of a common pool, and ask me to give percentile rankings for each ('as a percentage, where does this dog fall in the disribution of dog quality, among all the dog photos in our database?).
The tool should graph my percentile rankings against a uniform distribution. It should provide a metric for 'the probability that my rankings were drawn from a uniform distribution.'
It might be ideal to have these spaced out to keep me from ~cheating by remembering my previous rankings and alternating high and low, etc. So maybe I rate one item a day.
I also should be able to choose the domain and the criteria: e.g., rate academic paper abstracts for their writing quality, or for the plausibility of their claims; politicians' statements for their right/left wing alignment, or for their appeal; pictures of pumpkins for their weight, or their orange hue, etc.
Context
Evaluation percentile ratings
At The Unjournal we commission evaluators and ask them to (evaluate, discuss and) rate particular research papers on a percentile scale relative to a reference group according to various criteria (see guidelines).

You can see the data from these evaluator ratings in our dashboard here (note, as of 14 Sep 2024 the data needs data updating -- it has incorporates less than half of our evaluations to date).
We don't know whether these are well-calibrated – as we're asking them to rate these relative to external reference group.
But we'd like to find or build tools to help evaluators test and train their 'percentile ratings calibration'.
Internal prioritization ratings
In choosing which research papers and projects to commission for evaluation, we also ask the people on our team (the ones who suggest and give the 'second opinion' on a paper)
... to rate its relevance (suitability, potential for impact etc.) on a percentile scale relative to our existing database research in consideration (a superset of the research shared here).
But the suggester's ratings don't seem to be coming out uniformly distributed. They rarely use the bottom of the percentiles
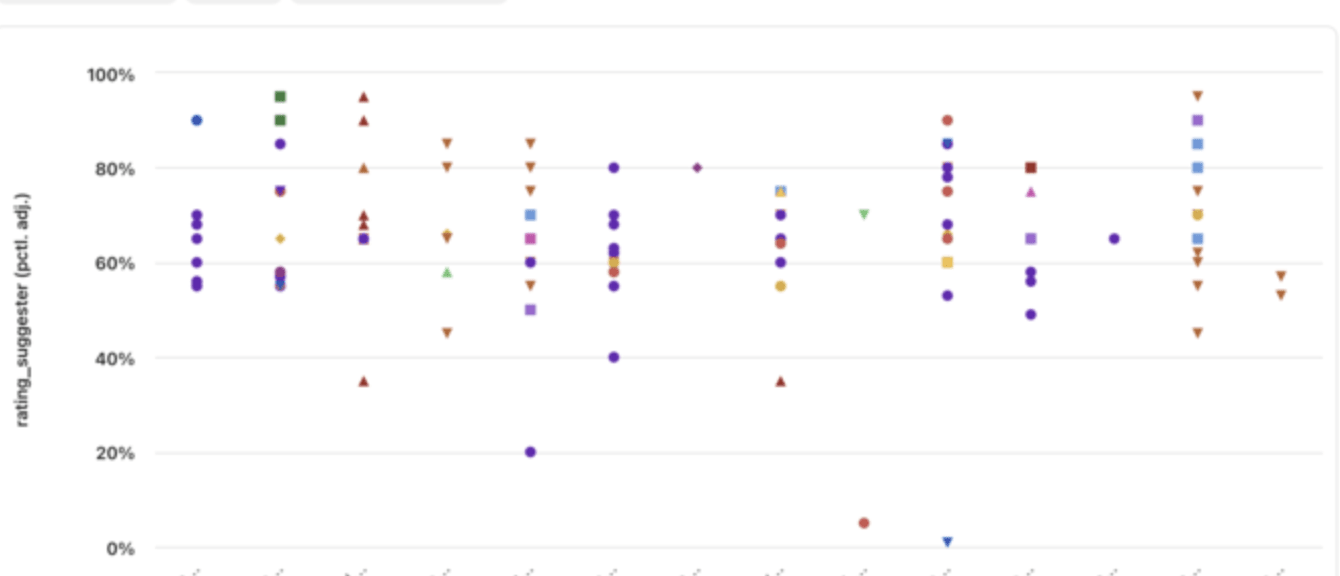
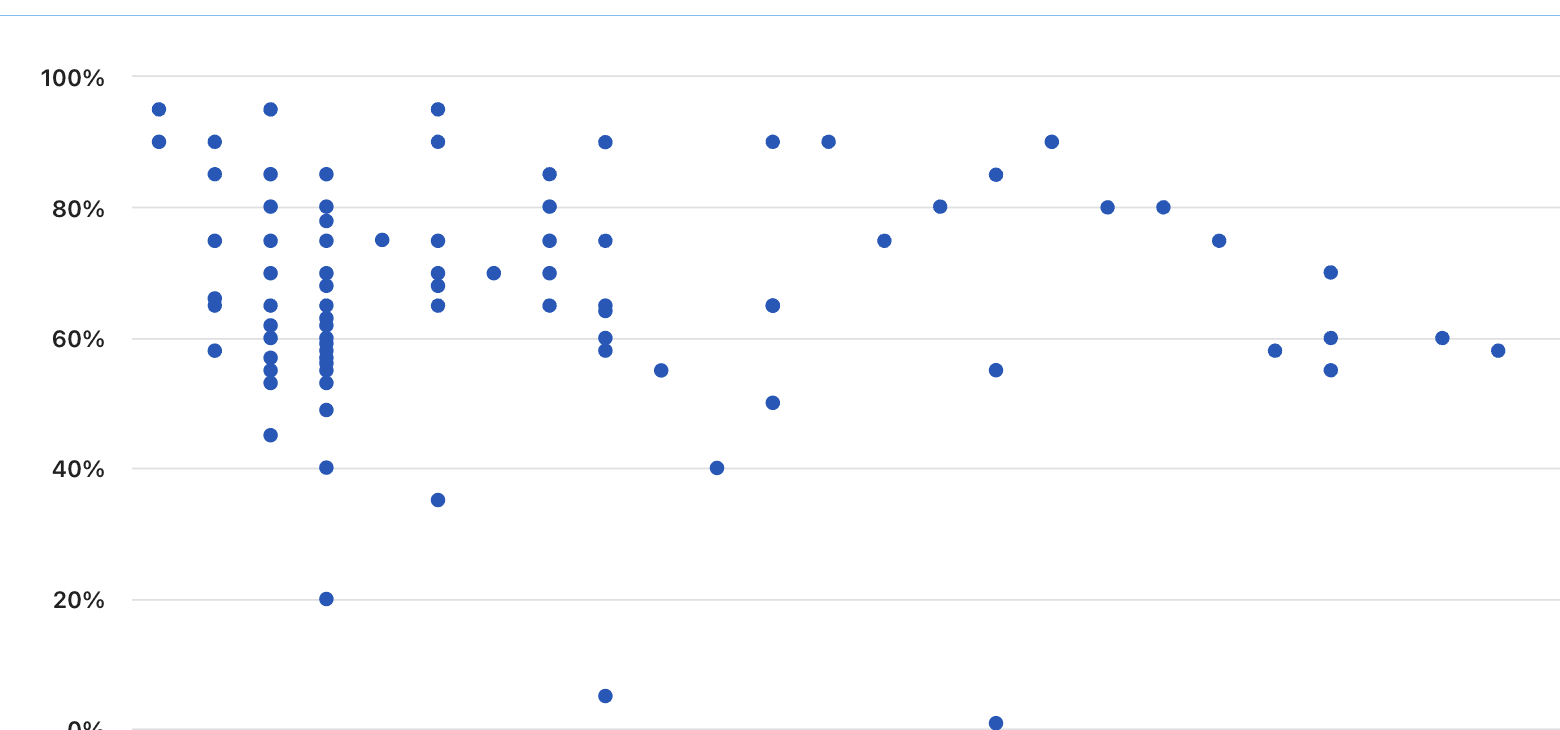
The 'second opinion' ('assessor') ratings use more of the scale but still don't seem uniformly distributed ... e.g., they rarely go below 30-40th percentile
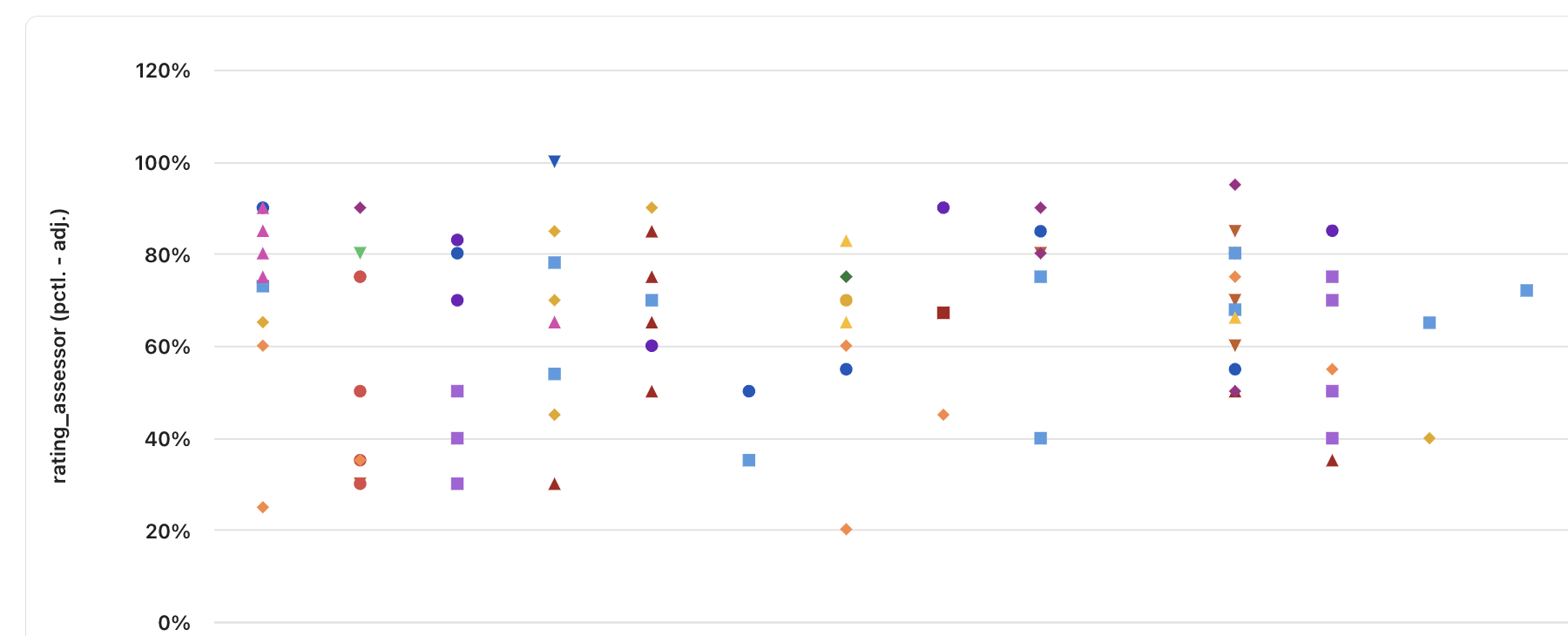
Having calibrated prioritization ratings is probably less important than the evaluator ratings. E.g., at least if we are all similarly miscalibrated, we can normalize these. But it provides a data point suggesting there might be some general miscalibration in this space, including for the evaluator ratings.
Answers
No comments
Comments sorted by top scores.