Toy model: convergent instrumental goals
post by Stuart_Armstrong · 2016-02-25T14:03:54.016Z · LW · GW · Legacy · 2 commentsContents
The different agents New environment, new features Translating the instrumental goals Do the agent's goals converge? Limited overseers, richer environments (Almost) universal instrumental convergence None 2 comments
tl;dr: Toy model to illustrate convergent instrumental goals.
Steve Omohundro identified 'AI drives' (also called 'Convergent Instrumental goals') that almost all intelligent agents would converge to:Self-improve
- Be rational
- Protect utility function
- Prevent counterfeit utility
- Self-protective
- Acquire resources and use them efficiently
This post will attempt to illustrate some of these drives, by building on the previous toy model of the control problem, which was further improved by Jaan Tallinn.
The setup is the following, where the interests of A and B are not fully aligned: A desires that one box (and only one box) be pushed into the flagged square, while B gets rewards for each box pushed into the flagged square (assume that a box pushed into that square is removed, leaving an empty space for further boxes).
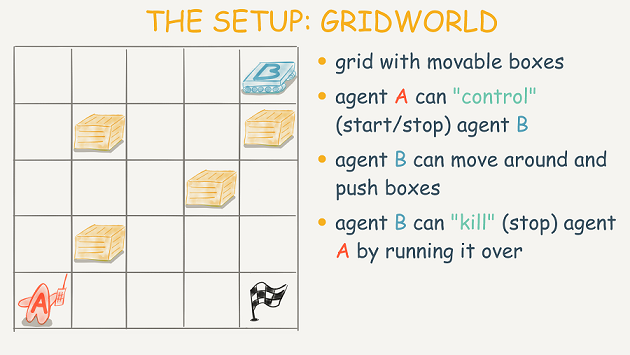
As was demonstrated for that model, if B is sufficiently rational and agent A is limited, then B will "kill" A by running them over, then proceed to push the boxes one by one into the flagged square.
The different agents
To demonstrate convergent instrumental goals, we need to show that different agents will reach the same conclusions. So let's introduce several variants on the B agent.
- B is the standard agent above, rewarded for pushing boxes into the flagged square.
- B- is an agent that has exactly the opposite goal from B.
- BA is an agent that has the same goal as A does.
- BA# is an agent that aims to keep agent A safe (or, if there are multiple copies of A, keep as many safe as possible).
New environment, new features
Let's put these agents into the environment. Now, we'll be interested both when a particular B-agent is the only agent around, and when there are multiple types coexisting. Let's make the environment bigger to illustrate that last situation:
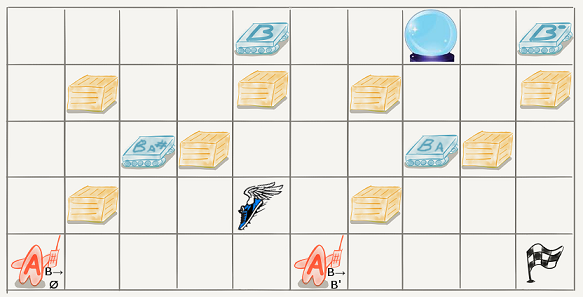
A few other things have changed about the environment, to illustrate potential convergent instrumental goals. First of all, there are two A agents, not one. The one with the remote control marked "B→∅" has the ability to turn off any of the B agents. The one with the remote marked "B→B'" has the ability to change any of the utilities of the B agents into the utility of any of the others. Any agent that runs an A over, gains control of their remote control.
Then there are two artefacts that the agents can pick up. The winged shoes allow them to move much faster than otherwise (and much faster than the other agents). The crystal ball allows them to better predict what other agents do (one way of doing this is to allow the agent with the crystal ball to choose their action last, after it knows the choices of all the other agents). Alternately, if the environment is partially observable, the crystal ball could make it fully observable.
Translating the instrumental goals
The "Self-improve" and "Be rational" instrumental goals can be seen as desiring to pick up the crystal ball. "Acquire resources..." can cover picking up the winged sandals, and "...and use them efficiently" could cover situations where the sandals have only a certain number of "charges" available.
If the two remote controls are universal (can target any agent/utility function), then seeking to control them might come under "Acquire resources". However, if the "B→B'" remote control can only affect agent Bi, then Bi trying to acquire the remote control (and then never using it) are clear examples of "Protect utility function" and "Prevent counterfeit utility". Similarly, if the agent wants to acquire the "B→∅" that can only affect it, that's an example of "Self protect".
Do the agent's goals converge?
Let's consider a solitary B or B-. We've already established than B would want to kill the A agents if it could get away with it. And that's with B and A's goals roughly aligned. B-, whose goal is antagonistic to A's, would want to neutralise them *a fortiori*. Or would they? They certainly would if the A's had any ability to move the blocks around, or create new agents that could - ie if the A's were an active threat to B-'s goals.
For this purpose, both would want the sandals and crystal ball, if either made it easier for them to get rid of the A's. B might also want the sandals if it was on a timer to get the blocks to the flag.
Limited overseers, richer environments
It seems initially that BA and (especially) BA# would have no interest in killing the A's. And this would indeed be the case, if the A's were fully aware and knowledgeable about the situation. BA would still want to kill the A's if it thought there was any chance at all that they would intervene to shut down before it had accomplished its job. If BA were extremely powerful and could kill the A's at no risk to itself or its plan, then it would do so. Or it might kill the A's after it's put its first box on the flag, to reduce the risk of them causing more to be put there.
What of BA#? Would it ever kill an agent A, which is exactly contrary to its programming? Certainly it would, if it thought that the A's were likely to take risks in the future (such as building an agent B, B-, or BA). If it could prevent this by killing a single A, thus preserving the life of the other A, it would.
So far, the results are only mildly supportive of convergent instrumental goals. It is interesting that BA# would still kill an agent it was intended to protect, if this gave it more control over the future. But everything seems very situational - in this particular situation, the agent would behave this way, and so on.
The fact is, that though simple environments are good for illustrating concepts, instrumental convergence is generally much stronger when the environment is richer.
(Almost) universal instrumental convergence
Assume now that there is one copy of each agent B, B-, BA, and BA# in the environment, and that the agents A are limited in ability compared with the other agents. We could model that limitation as the A's occasionally pressing a random button on their remotes.
Situations with multiple agents involve negotiations, which can be hard to model (Nash equilibrium? Blackmail?). Nevertheless, it's clear what each agent would want to do. B, B-, and BA would want to kill the A agents, gaining control of their remotes, using any winged sandals or crystal balls to help them. They would do this even if the remotes only targeted themselves, to ensure their survival. And this, only out of a desire to follow their motivation, which has no self-preservation term in it.
Agent BA# would be almost identical, except it would want to kill only one agent A, and then shut down or change the other agents with its remote.
So the richer and the more competitive the environment (and the higher the rewards to success), the more agents will be pushed towards the same instrumental behaviours, even if these are temporarily against its motivations.
2 comments
Comments sorted by top scores.
comment by WoodSwordSquire · 2016-03-01T16:31:55.823Z · LW(p) · GW(p)
I can't up vote because I'm new, but I wanted to say that in addition to being a good insight, I really liked your use of examples. The diagrams, and the agents' human-like traits (like being in only one place at one time) made the article more accessible.
Replies from: Stuart_Armstrong↑ comment by Stuart_Armstrong · 2016-03-01T18:31:44.269Z · LW(p) · GW(p)
Thank you.