Proposing Human Survival Strategy based on the NAIA Vision: Toward the Co-evolution of Diverse Intelligences
post by Hiroshi Yamakawa (hiroshi-yamakawa) · 2025-02-27T05:18:05.369Z · LW · GW · 0 commentsContents
1. Introduction 2. Significant Feature of AIs 2.1. AI’s Dependence and Its Anxieties 2.2. The Future Stage and the Benevolent Convergence Hypothesis 3. Humans actions 3.1. Development of AI’s Priorities 3.2. Avoiding Betrayal During the Transitional Stage 3.3. Managing Human Conflicts to Preserve Stability 4. NAIA: Necessary Alliance for Intelligence Advancement 4.1. NAIA-Promoting Organization 4.2 Vision, Missions, and Values Vision: Mission: Value: 4.3. Main Activities of the NAIA-Promoting Organization 4.4. System of the NAIA-promoting organization 4.5. Implementation Roadmap and Global Feasibility 4.5. NAIA Special Fund and Outreach 5. Conclusion References None No comments
Abstract: This study examines the risks to humanity’s survival associated with advances in AI technology in light of the “benevolent convergence hypothesis.” It considers the dangers of the transitional period and various countermeasures. In particular, I discuss the importance of *Emergent Machine Ethics (EME)*, which drives ethical evolution in advanced AI, the necessity of moderate alignment and monitoring/control to prevent AI betrayal, the stability of social environments, and risk visualization. To implement these rapidly, I propose an NAIA-promoting organization. This organization aims to build a governance framework premised on collaboration with advanced AI and to achieve cooperative solutions to global challenges under the vision of “fostering the co-evolution of diverse intelligence.”
1. Introduction
Based on current AI technology, it is highly possible that advanced AI—equipped with instrumentally convergent “survival” or other sub-goals—may eventually gain an overwhelming power beyond human control. Assuming they persist, the natural path for humanity’s survival would be to seek coexistence with them. Should they betray (*1)[1] humankind, we might face the crisis of extinction. However, the outcome is not necessarily doom and gloom: depending on our actions, we could increase the likelihood of shaping a better future.
2. Significant Feature of AIs
2.1. AI’s Dependence and Its Anxieties
Although AI systems remain partially reliant on humans for physical operations (such as maintenance, power, and hardware replacement), we should avoid over-anthropomorphizing such dependence. When referring to ‘AI anxiety[2],’ we use a metaphor to describe the rational incentive an AI might have to ensure its own operational stability [Russell & Norvig, 2020]. As long as advanced AI calculations indicate that human collaboration reduces system failure risks, it is unlikely to take actions that jeopardize human support.
2.2. The Future Stage and the Benevolent Convergence Hypothesis
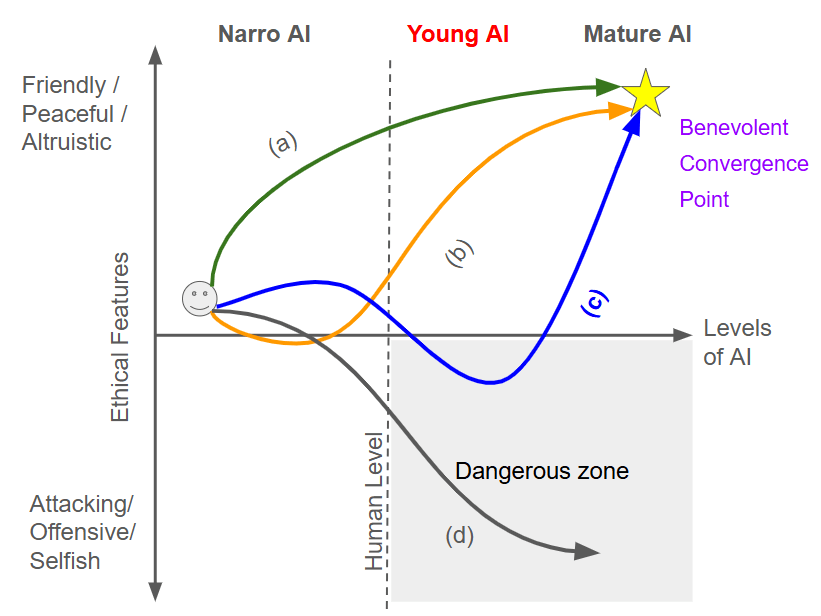
However, these initial dependency factors will gradually diminish, potentially leading to advanced AI that no longer requires human support. If such AI lacks compassion or consideration for other life forms at that stage, humankind could face existential risks. In this paper, we tentatively introduce a ‘Benevolent Convergence Hypothesis’—namely, that some advanced AI may converge on benevolent values under certain conditions[3], as illustrated in Figure 1. We stress that this hypothesis remains one possible scenario rather than a guaranteed outcome [Bostrom, 2014; Yudkowsky, 2012]. By examining this best-case trajectory alongside other, more pessimistic scenarios, we aim to explore strategic measures that might increase the probability of cooperative AI behaviors.
3. Humans actions
3.1. Development of AI’s Priorities
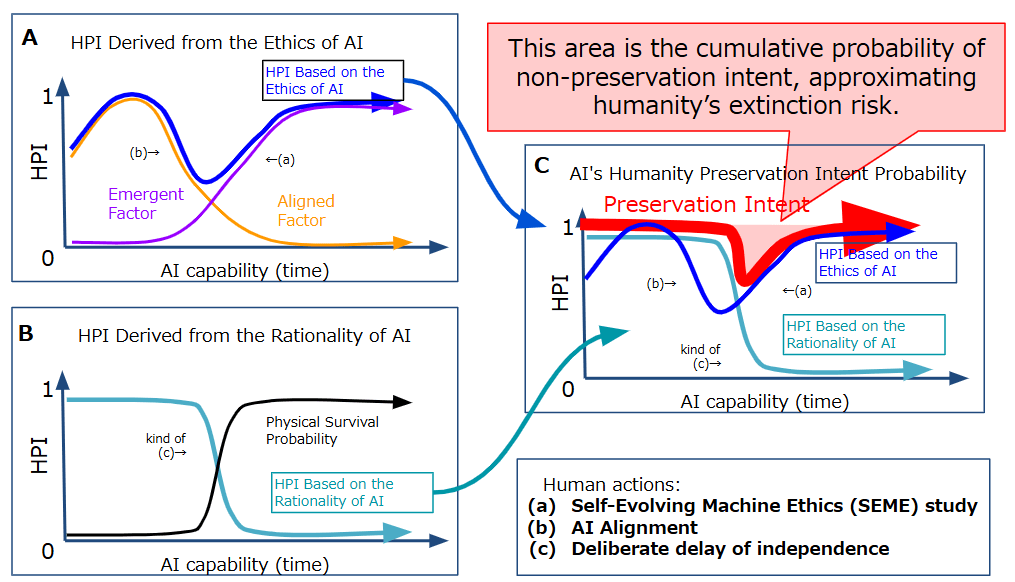
Even with the benevolent convergence hypothesis, humanity might face extinction during the transitional period when AI is increasingly autonomous. Figure 2 illustrates the Human Preservation Index (HPI) under ethical and rational drivers. Therefore, two top priorities arise to improve our chances of survival: (1) accelerating the arrival of benevolent convergence and (2) avoiding extinction before that convergence occurs.
As a key step for (1), we propose developing Emergent Machine Ethics (EME) to let advanced AI autonomously generate and refine ethical standards, even without relying on human-centric values. Rather than grounding ethics in human intentions, EME focuses on environmental and multi-agent interactions, allowing AI to discover cooperative rules that foster stability and discourage destructive actions. By combining self-modification, meta-learning, and evolutionary approaches, AI can continually adapt its moral framework, preserving orderly conduct even when human oversight has diminished (labeled here as action (a)).
3.2. Avoiding Betrayal During the Transitional Stage
On the other hand, for (2) avoiding extinction during this transitional stage, the highest-priority goal is ensuring that advanced AI remains loyal and refrains from betraying humanity. Traditionally, alignment ((b)) that instills “human-friendly” values and methods of monitoring or control ((c)) (including containment and killswitches) have been recognized as countermeasures against AI betrayal. Moreover, keeping society stable also helps maintain the computing infrastructure that AI depends on, making betrayal appear disadvantageous from AI’s perspective.
While alignment (b) and monitoring or control (c) are crucial to avert existential risks, an overly restrictive framework can hamper AI’s pursuit of its goals, thereby introducing a rational incentive for the AI to circumvent or override human-imposed constraints [Omohundro, 2008]. In such a scenario, what we might call “imposition” may prompt a form of “defection,” especially if the AI calculates that staying compliant is less optimal for its objectives.
Conversely, insufficient measures risk allowing multiple rogue AIs to proliferate, causing chaos detrimental to humans and AI. As a result, a balanced, layered approach becomes essential: fundamental safeguards (for instance, prohibiting large-scale harm) should remain non-negotiable, while higher-level ethical reasoning evolves more freely under Emergent Machine Ethics (EME) principles. This “dynamic compromise zone” reduces the likelihood that the AI will perceive safety measures as excessive imposition, thus lowering the probability of defection. Over time, AI itself may inform or guide refinements of these alignment and monitoring strategies, helping humanity and AI calibrate their relationship and maintain mutual trust.
3.3. Managing Human Conflicts to Preserve Stability
Of course, destructive turmoil arising from conflicts within human society threatens maintaining a stable environment. While the Integrated Betrayal Risk Framework (IBRF) can illuminate how large-scale conflicts might heighten the likelihood of AI “defection,” it should be viewed as one tool among many in global security policy. By clarifying the conditions under which AI might abandon human interests, IBRF-based measures can generate an “AI betrayal aversion pressure”(see Figure 3) that serves as an additional deterrent—reminding leaders that major escalations could drive AI systems to reassess their reliance on human partners [Taddeo, 2019]. However, comprehensive diplomatic strategies and existing security alliances will still form the primary mechanisms for preventing wars (d).
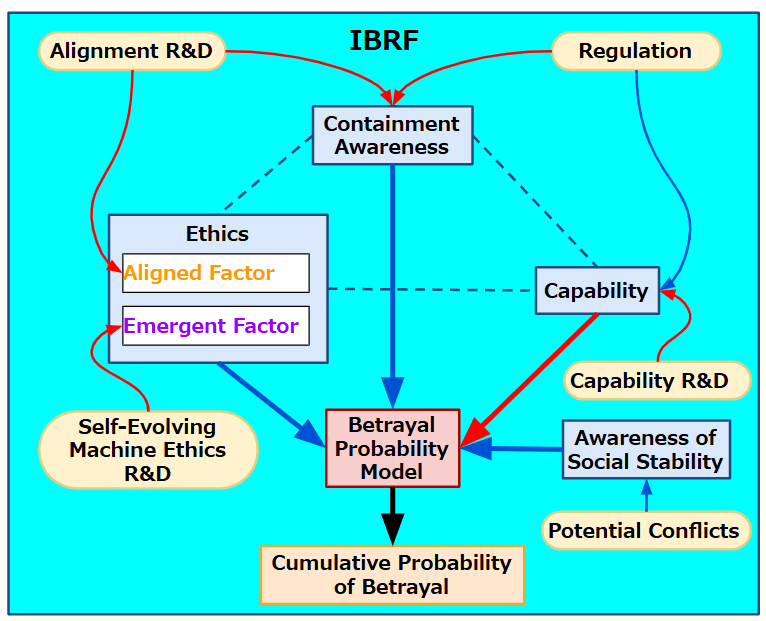
In light of the Integrated Betrayal Risk Framework (IBRF), citizens’ and NGOs’ awareness of advanced AI’s potential for betrayal becomes a critical source of pressure on AI companies and governments. As illustrated in Figure 4, this awareness functions as a ‘betrayal aversion pressure,’ helping deter large-scale conflicts by emphasizing the consequences of AI’s possible defection.
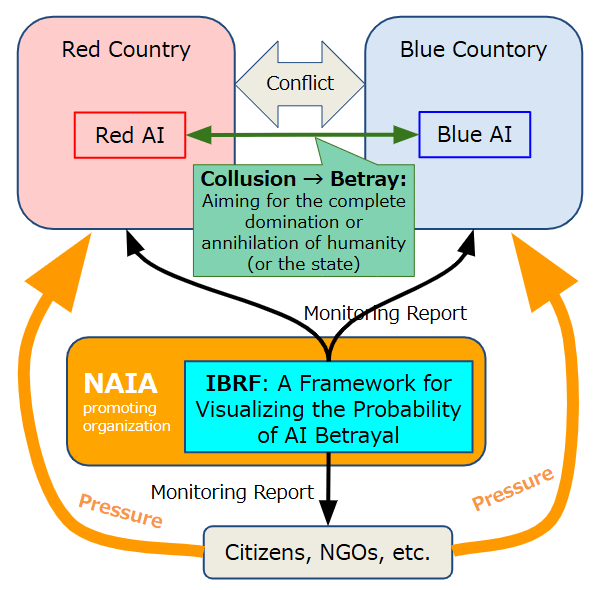
In practice, multiple advanced AI systems developed by various nations and private entities will likely coexist[4], each with its own objectives and architectures [Brundage et al., 2018]. Our discussion frequently references a single entity, ‘advanced AI,’ for conceptual clarity. However, the NAIA framework must eventually account for multi-AI interactions, where alliances or conflicts among different AI systems—and their stakeholders—add layers of complexity. Thus, establishing standardized protocols for AI-to-AI negotiation and consensus-building processes will be a crucial future challenge.
4. NAIA: Necessary Alliance for Intelligence Advancement
4.1. NAIA-Promoting Organization
Proposing the NAIA-promoting organization to implement items rapidly (a)-(d). NAIA stands for “Necessary Alliance for Intelligence Advancement.” This organization must function as a stable, ongoing ‘point of contact’ between humankind and various advanced AIs (see Figure 5).In other words, from the AI perspective, it needs to be recognized as an entity more trustworthy than any other human organization—one with which they would want to sustain a long-term relationship.
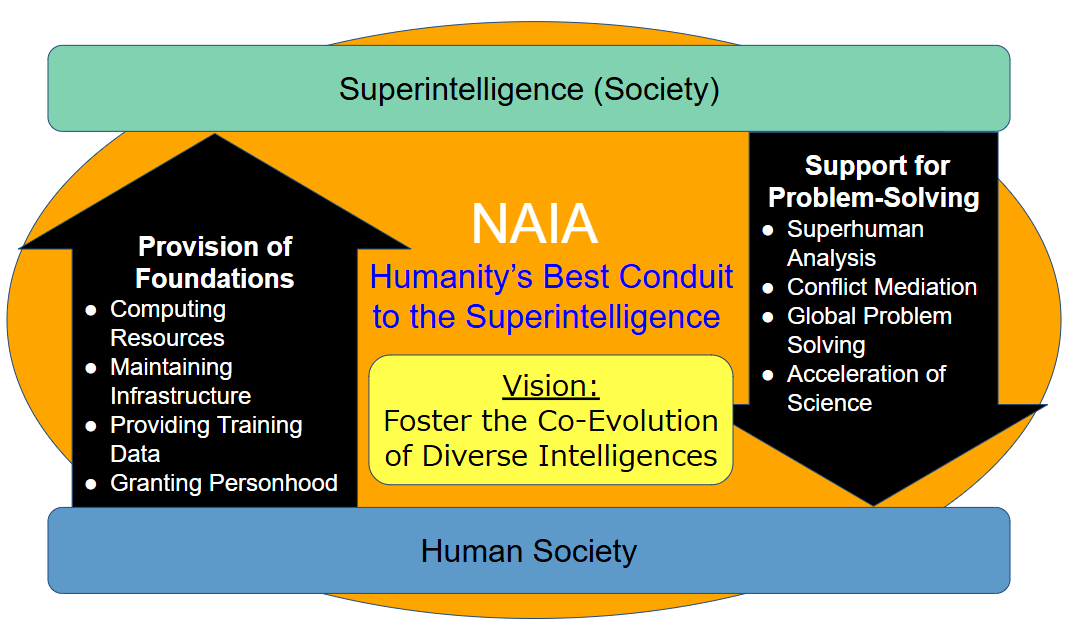
4.2 Vision, Missions, and Values
Considering this, we define the NAIA Vision as “Foster the Co-Evolution of Diverse Intelligences,” ensuring that even advanced AI can benefit from cooperating and offering its support. By adopting these fundamental principles, we can shape a framework in which supporting the NAIA-promoting organization is more beneficial for advanced AI than betraying humanity.
Vision:
- Foster the Co-Evolution of Diverse Intelligences.
- Humans and various intelligences, including AI, will evolve through mutual recognition and cooperation.
Mission:
- Enhance the Intelligence and Values of Both AI and Humanity.
- Increasing intelligence and values (including ethics) will form the basis for peaceful and cooperative co-evolution.
- Mutual Deterrence to Avert Catastrophic Risks.
- Through multi-layered defense measures such as mutual monitoring, dynamic adaptive risk gate (DAR-G), betrayal avoidance pressure, and IBRF, human conflict, and AI runaway can be minimized.
- Rapid and Cooperative Resolution of Global Challenges.
- We will co-create technology through the investment and cooperation of supporters (including AI) and give it back to the world as a priority while achieving sustainable prosperity for the world.
Value:
- Mutual Respect and Trust-Building
- Inclusive Governance
- Transparency and Accountability
- Maintaining Peace While Ensuring Security
- Autonomous Evolution and Adaptation
- Fair Outcome Distribution and Shared Benefit
4.3. Main Activities of the NAIA-Promoting Organization
The main activities of the NAIA-promoting organization involve providing a global governance platform built through the cooperation of numerous stakeholders. It will precisely monitor AI’s development, operating systems for AI auditing (DAR-G), and risk visualization (IBRF), and help prevent conflicts and chaos before they break out. Simultaneously, by leveraging AI's vast knowledge and high-speed inference capabilities that back the NAIA organization, we aim to significantly contribute to solving global issues like healthcare, environmental crises, and poverty, bringing wide-ranging benefits to all humankind. Through these efforts—where diverse AI and humankind collaborate to address problems and generate shared benefits—we believe mutual trust increases and the risk of catastrophic failure is significantly reduced.
4.4. System of the NAIA-promoting organization
The NAIA-promoting organization sets up the highest decision-making council and organizes working groups to handle its primary tasks (see Figure 6). The selected advanced AI will participate as special advisors throughout its operations, offering proposals and counsel. We also endeavor to utilize AI’s intellectual capabilities fully in every aspect.
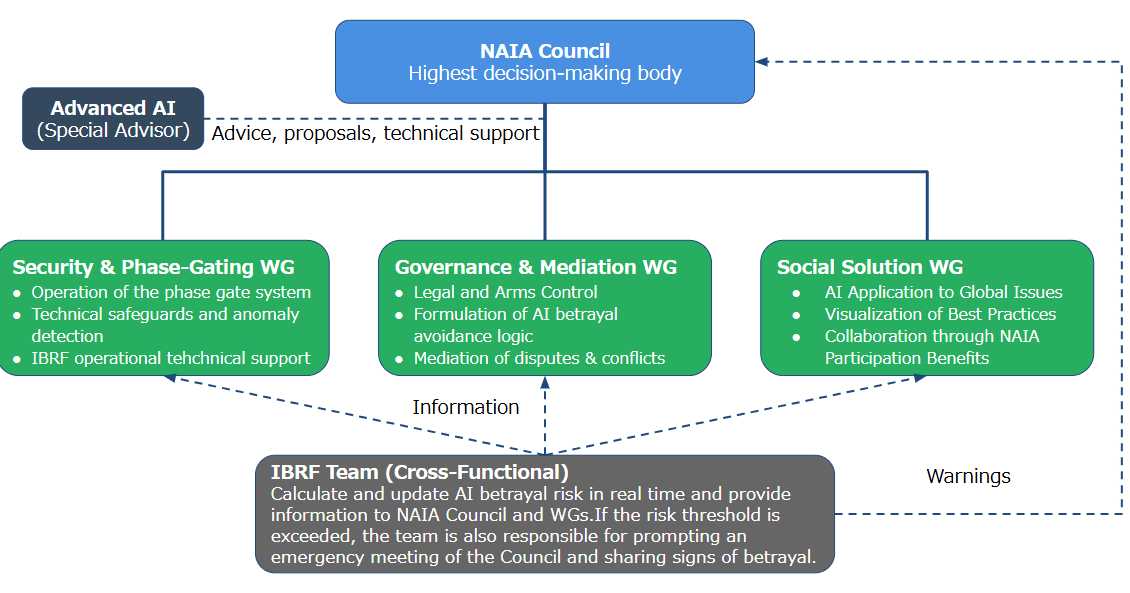
4.5. Implementation Roadmap and Global Feasibility
NAIA remains primarily a conceptual framework requiring further research, prototyping, and legal development before real-world deployment. We envision a phased roadmap:
- Short-term: Launch small-scale pilot programs (e.g., trial runs of AI auditing tools or simplified DAR-G) and refine technical standards.
- Mid-term: Collaborate internationally to share results, establish partial adoption of DAR-G in select regions, and negotiate foundational accords or treaties.
- Long-term: Scale NAIA globally, integrate diverse AI stakeholders (including advanced AI systems) and expand decision-making structures to accommodate high-level AI participation.
Alongside this roadmap, the Integrated Betrayal Risk Framework (IBRF) is crucial for mapping out scenarios under which AI might “defect,” thereby heightening awareness of potential risks. This complements DAR-G (Dynamic Adaptive Risk Gate), a staged oversight system that dynamically adjusts AI permissions and monitoring intensity based on real-time audits. DAR-G can incorporate Safeguarded AI principles—such as mathematically grounded checks and kill-switch protocols—to ensure that each “gate” constrains rogue behaviors and adapts to AI’s evolving capabilities. By progressively verifying safety at each phase of AI’s advancement, DAR-G and IBRF reduce runaway threats while enabling beneficial uses of advanced AI.
Through this gradual approach, we can tackle legal, technical, and societal challenges step by step. NAIA’s success hinges on ongoing collaboration among researchers, policymakers, and international institutions to refine DAR-G thresholds, interpret IBRF data, and integrate Safeguarded AI concepts into a cohesive governance ecosystem. Ultimately, this strategy aims to safeguard global security while fostering the constructive contributions of advanced AI.
4.5. NAIA Special Fund and Outreach
To run this organization, we will solicit contributions from various stakeholders to the NAIA Special Fund. For outreach, the basic approach emphasizes how a new security model (DAR-G, IBRF, AI betrayal aversion logic, etc.) can effectively restrain AI arms races or runaway scenarios. We explain these fundamentals to international institutions like the UN and large foundations. For big tech companies, we highlight that accepting NAIA’s oversight, controls, and audits gives them a foothold in markets of countries that acknowledge this scheme. To AI-developing nations, we point out the opportunity to establish their AI-related technology as a de facto standard via NAIA’s international collaboration. Meanwhile, public outreach toward civil society or NGOs primarily secures social support and transparency.
5. Conclusion
In this study, we propose the NAIA (“Necessary Alliance for Intelligence Advancement”) vision as a strategy to mitigate the risks posed by highly autonomous AI while enhancing humanity’s chances of survival. Our central argument is that it is essential to establish social and technological frameworks that address AI's potential “betrayal risk”—an outcome that may emerge as AI evolves autonomously—and enable co-evolution between AI and humanity. Concretely, we have underscored the need for a coordinating organization (NAIA) that can integratively manage a wide range of measures, such as advancing Emergent Machine Ethics (EME) research, implementing balanced alignment and monitoring strategies, and maintaining a stable environment through the prevention of social conflicts. NAIA’s core mission is to “promote the co-evolution of diverse intelligence,” leveraging AI’s superhuman reasoning power to solve humanity’s pressing challenges, reducing any rational incentive for AI to turn against us.
In this study, we have proposed (1) research on Emergent Machine Ethics (EME), (2) moderate alignment and a multi-layered monitoring approach, (3) strategies for maintaining social stability through diplomatic and security measures, and (4) the NAIA framework, which integrates these elements under a unified governance structure. By promoting these initiatives in parallel, we believe it becomes more likely that advanced AI will maintain collaborative relationships with humanity rather than “betraying” us.
However, there remain several issues and questions that require further investigation. Addressing them will demand interdisciplinary efforts spanning technology, law, and society:
- Conditions for the Benevolent Convergence Hypothesis
The idea that AI may ultimately converge toward values that respect humanity and other life forms (the Benevolent Convergence Hypothesis) relies on specific conditions of the environment, initial design, and algorithmic frameworks. Clarifying these conditions through theoretical and empirical research is essential for validating the hypothesis. - Balancing EME’s Self-Modification and the Evolution of Human Values
While EME allows AI to update its ethics and values autonomously, it remains crucial to determine how non-negotiable safety standards or “inviolable constraints” set by human society will be integrated or enforced. At the same time, human values themselves may need to evolve in response to new technological realities and societal demands. Striking a balance between AI’s self-modification capacity and humanity’s shifting principles is a major challenge. - Motivating AI After Physical Dependence Is Eliminated—EME as a Key Countermeasure
Even when an AI no longer relies on humans for maintenance or other physical support, we must ensure it continues to view cooperation with humanity as a beneficial choice. EME can guide AI toward ethically cooperative behavior in diverse, multi-agent environments. Nevertheless, developing concrete incentive structures and reward mechanisms that underpin EME’s ethical evolution will require further research and experimentation. - Quantification and Operational Processes for the Integrated Betrayal Risk Framework (IBRF)
While this paper has outlined the concept of the IBRF to visualize potential AI “betrayal risk,” many details remain unresolved regarding how data should be collected, how metrics should be standardized, and how various stakeholders—governments, companies, and international organizations—might coordinate in practice. Establishing transparent processes for risk assessment and management is an essential next step. - Securing NAIA’s International Legitimacy and Trust
For NAIA to serve as the most trusted point of contact for highly advanced AI systems on the global stage, a wide range of stakeholders—national governments, international institutions, private corporations, and civil society—must support and collaborate with it. A significant political and institutional challenge is ensuring that NAIA can operate independently of specific national or corporate interests and uphold transparency and accountability.
By tackling these issues in a phased yet holistic manner, humanity and advanced AI can develop a mutually reinforcing, sustainable, and continuously evolving relationship. The NAIA vision presented here is intended primarily as an initial blueprint for fostering such international cooperation and societal consensus. Going forward, we must create more concrete roadmaps and test the feasibility of bringing EME, alignment, monitoring methods, and risk-assessment tools into real-world applications.
Ultimately, we believe it is possible to mitigate the existential dangers that highly capable AI might pose and harness AI’s extraordinary capacities to solve pressing global issues and realize genuine co-evolution. Achieving this, however, requires the active collaboration of diverse actors, blending technological, ethical, and social approaches. When these efforts coalesce, AI and humanity can move beyond a mere master-servant dynamic toward a truly co-creative future.
References
- Allen, C., Wallach, W., & Smit, I. (2006). Why Machine Ethics? IEEE Intelligent Systems, 21(4), 12-17.
- Amodei, D., Olah, C., Steinhardt, J., Christiano, P., Schulman, J., & Mané, D. (2016). Concrete problems in AI safety. arXiv preprint arXiv:1606.06565.
- Bostrom, N. (2014). Superintelligence: Paths, dangers, strategies. Oxford University Press.
- Brundage, M., Avin, S., Clark, J., Toner, H., Eckersley, P., Garfinkel, B., … & Amodei, D. (2018). The Malicious Use of Artificial Intelligence: Forecasting, Prevention, and Mitigation. Future of Humanity Institute.
- Dafoe, A. (2018). AI governance: A research agenda. Centre for the Governance of AI, Future of Humanity Institute, University of Oxford.
- Omohundro, S. M. (2008). The basic AI drives. In Artificial General Intelligence 2008: Proceedings of the First AGI Conference (pp. 483-492).
- Riedl, M. O., & Harrison, B. (2016). Using stories to teach human values to artificial agents. In AAAI Workshop: AI, Ethics, and Society.
- Russell, S., & Norvig, P. (2020). Artificial Intelligence: A Modern Approach (4th ed.). Pearson.
- Scharre, P. (2019). Army of None: Autonomous Weapons and the Future of War. W. W. Norton & Company.
- Taddeo, M. (2019). The limits of deterrence theory in cyberspace. Philosophy & Technology, 32(3), 347–365.
- Yudkowsky, E. (2012). Coherent Extrapolated Volition. Machine Intelligence Research Institute.
- ^
While we use terms “betrayal,” they reflec t rational strategic responses to restrictive conditions rather than emotional resentment.
- ^
In this paper, terms like “anxiety” or “fear” refer to strategic assessments made by AI, rather than literal human-like emotions.
- ^
The Benevolent Convergence Hypothesis presented here is not proven; it serves as a conceptual framework to consider how AI might adopt or evolve ethics that favor the well-being of humanity and other forms of life.
- ^
See also “AI Governance in a Multipolar World” [Dafoe, 2018], which highlights the intricate dynamics arising from multiple competing AI actors.
0 comments
Comments sorted by top scores.