Turning off lights with model editing
post by Sam Marks (samuel-marks) · 2023-05-12T20:25:12.353Z · LW · GW · 5 commentsThis is a link post for https://arxiv.org/abs/2207.02774
Contents
5 comments
This post advertises an illustrative example of model editing that David Bau is fond of, and which I think should be better known. As a reminder, David Bau is a professor at Northeastern; the vibe of his work is "interpretability + interventions on model internals"; examples include the well-known ROME, MEMIT, and Othello papers.
Consider the problem of getting a generative image model to produce an image of a bedroom containing unlit lamps (i.e. lamps which are turned off). Doesn't sound particularly interesting. Let's try the obvious prompts on DALL-E-2.
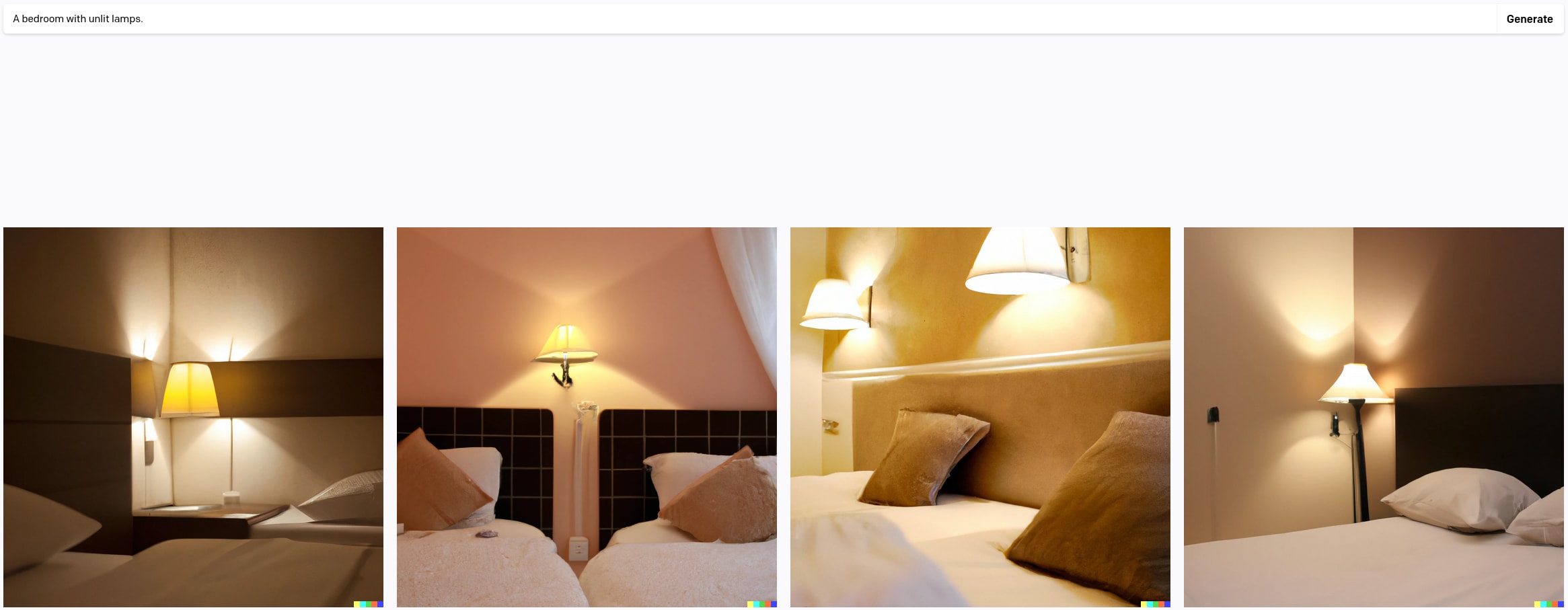
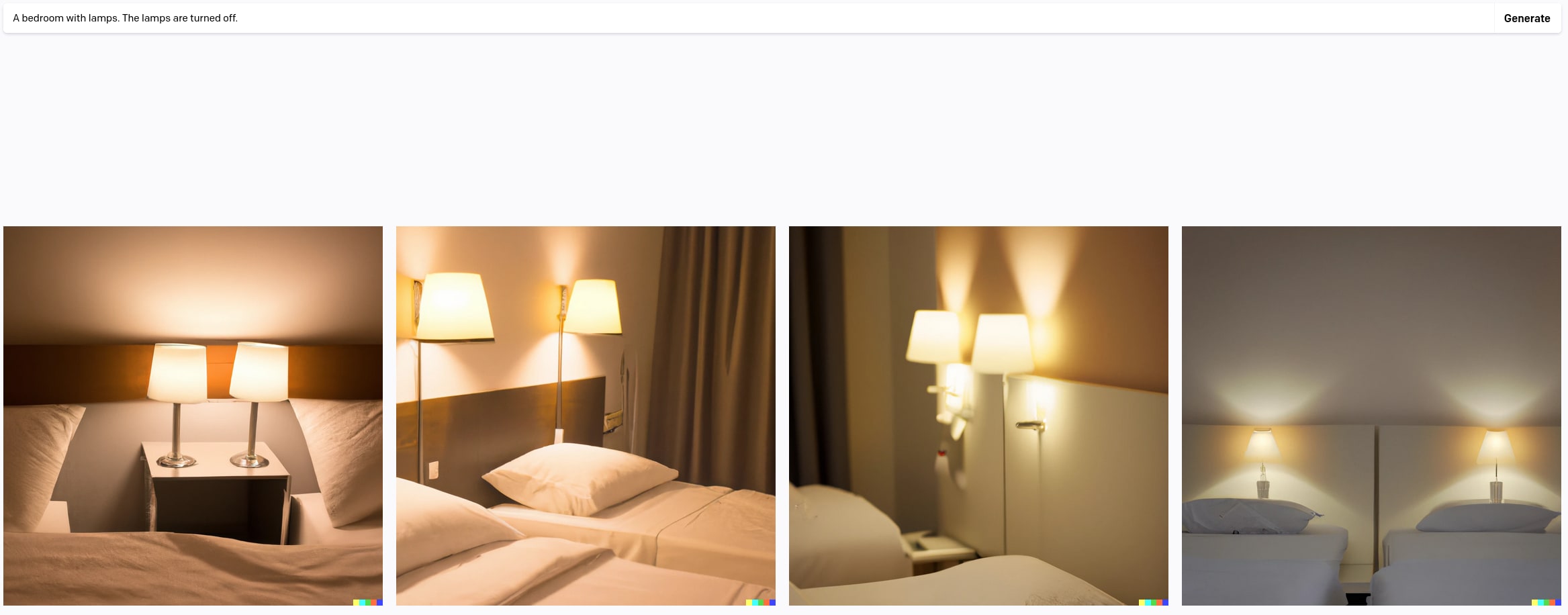
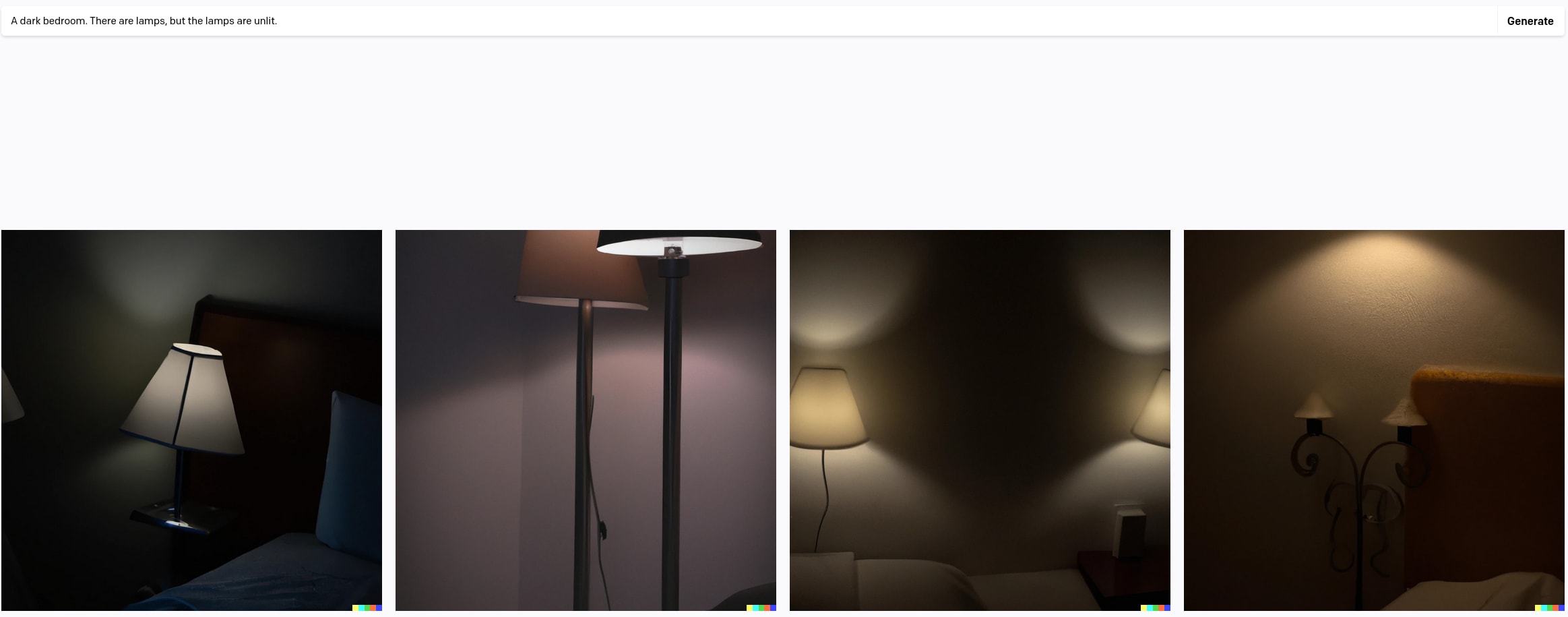
Doesn't work great: my first three attempts only got one borderline hit, at the expense of turning the entire bedroom dark (which isn't really what I had in mind).
As David Bau tells things, even after putting further effort into engineering an appropriate prompt, they weren't able to get what they wanted: a normal picture of a bedroom with lamps which are not turned on. (Apparently the captions for images containing unlit lamps don't often mention the lamps.)
Despite not being able to get what they wanted with prompt engineering, they were able to get what they wanted via interpretability + model editing. Namely, they took a GAN which was trained to produce images of bedrooms, and then:
- identified a neuron which seemed to modulate the brightness of the lamps in the generated image
- intervened on the networks activations, setting the activation of this neuron so as to produce the desired level of brightness.
The result is shown below.

I like this example because it provides a template in a very toy setting for how model editing could be useful for alignment. The basic structure of this situation is:
- We have a model which is not behaving as desired, despite being able to do so in principle[1] (our model doesn't output images of bedrooms with unlit lamps, despite being capable of doing so).
- Basic attempts at steering the model's behavior fail (prompt engineering isn't sufficient).
- But we are able to get the behavior that we want by performing a targeted model edit.
This example also showcases some key weaknesses of this technique, which would need to be addressed for model editing to become a viable alignment strategy:
- Alignment tax. Looking closely at the image above, you'll notice that even though the direct light from the lamp is able to modified at will, certain second-order effects aren't affected (e.g. the light which is reflected off the wall). As David tells things, they also identified a whole suite of ~20 neurons in their GAN which modulated more subtle lighting effects.
- Not all behaviors can necessarily be targeted. The images on the lower row above contain two lamps, and these two lamps change their brightness together. The researchers were not able to find a neuron which would allow them to change the brightness of only one lamp in images that contained multiple lamps.
- No clear advantages over finetuning. The more obvious thing to do would be to finetune the model to output unlit lamps. As far as I know, no one tried to do that in this case, but I imagine it would work. I'll leave my most optimistic speculation about why model editing could have advantages over finetuning in certain situations in this footnote[2], but I don't currently find this speculation especially compelling.
Overall, I'm not super bullish on the usefulness of model editing for alignment. But I do think it's intriguing, and it seems to have been useful in at least one case (though not necessarily one which is very analogous to x-risky cases of misalignment). Overall, I think that work like this is a risky bet, with the advantage that some of its failure modes might differ from the failure modes of other alignment techniques.
[Thanks to Xander Davies and Oam Patel for discussion.]
- ^
That is, I find it very likely that DALL-E-2 "can" produce images of bedrooms with unlit lamps, for whatever reasonable interpretation you'd like of what that "can" means.
- ^
The general vibe here is "the effectiveness of model editing scales with our ability to generate accurate interpretability hypotheses, whereas the effectiveness of finetuning scales with something different." In more detail:
* Finetuning relies on being able to effectively evaluate outputs, whereas model editing might not. For example, suppose that we would like to get a language model to write good economics papers. Finetuning for human evaluations of economics papers could jointly optimize for papers which are more true as well as more persuasive. On the other hand, if our interpretability were good enough to separate out the mechanisms for writing truly vs. writing persuasively, then we could hope to make a model edit which results in more true but not more persuasive papers output.
* Finetuning might require large datasets, whereas model editing might not. Again in the economics paper writing example, finetuning a model to write good economics papers might require a large number of evaluations. On the other hand, we might be able to generate accurate interpretability hypotheses using only a small number of dataset examples (and possibly no dataset examples at all).
* Model editing might transfer better out-of-distribution. If the interpretability hypothesis on which we base a model edit is good, then the model edit ought to have the predicted effect on a broad distribution of inputs. On the other hand, fine-tuning only guarantees that we get the desired behavior on the fine-tuning distribution.
5 comments
Comments sorted by top scores.
comment by Neel Nanda (neel-nanda-1) · 2023-05-13T14:34:48.297Z · LW(p) · GW(p)
Thanks for sharing! I think the paper is cool (though massively buries the lede). My summary:
- They create a synthetic dataset for lit and unlit rooms with styleGAN. They exploit the fact that the GAN has disentangled and meaningful directions in its latent space, that can be individually edited. They find a lighting latent automatically, by taking noise that produces rooms, editing each latent in turn and looking for big changes specifically on light pixels
- StyleGAN does not have a text input, and there's no mention of prompting (as far as I can tell - I'm not familiar with GANs). This is not a DALL-E style model. Its input is just Gaussian noise
- This is a really cool result, and I am excited about it! The claim that GANs have disentangled latents (and that this is known), which makes this less exciting (man I wish this was true of LLMs). But it's still solid!
- This is in section 4.1
- They manually create a dataset of lit and unlit rooms, which isn't that interesting. They use this for benchmarking their method, not for actually training it (I don't find this that exciting)
- They use the GAN as a source of training data, to train a model specifically for lit -> unlit rooms (I don't find this that exciting)
↑ comment by Sam Marks (samuel-marks) · 2023-05-13T21:22:56.517Z · LW(p) · GW(p)
Yeah, sorry, I should have made clear that the story that I tell in the post is not contained in the linked paper. Rather, it's a story that David Bau sometimes tells during talks, and which I wish were wider-known. As you note, the paper is about the problem of taking specific images and relighting them (not of generating any image at all of an indoor scene with unlit lamps), and the paper doesn't say anything about prompt-conditioned models. As I understand things, in the course of working on the linked project, Bau's group noticed that they couldn't get scenes with unlit lamps out of the popular prompt-conditioned generative image models.
Replies from: neel-nanda-1↑ comment by Neel Nanda (neel-nanda-1) · 2023-05-13T21:26:37.778Z · LW(p) · GW(p)
Ah, thanks for the clarification! That makes way more sense. I was confused because you mentioned this in a recent conversation, I excitedly read the paper, and then couldn't see what the fuss was about (your post prompted me to re-read and notice section 4.1, the good section!).
comment by Neel Nanda (neel-nanda-1) · 2023-05-13T21:21:38.899Z · LW(p) · GW(p)
Another thought: The main thing I find exciting about model editing is when it is surgical - it's easy to use gradient descent to find ways to intervene on a model, while breaking performance everywhere else. But if you can really localise where a concept is represented in the model and apply it there, that feels really exciting to me! Thus I find this work notably more exciting (because it edits a single latent variable) than ROME/MEMIT (which apply gradient descent)
comment by AlphaAndOmega · 2023-05-13T10:51:06.359Z · LW(p) · GW(p)
Did they try running unCLIP on an image of a room with an unlit lamp, assuming the model had a CLIP encoder?
That might have gotten a prompt that worked.