Some Thoughts on Concept Formation and Use in Agents
post by CatGoddess · 2024-03-11T05:03:43.642Z · LW · GW · 0 commentsContents
No comments
Note: I wrote this document over a year ago and have decided to post it with minimal edits; it isn't entirely up to date with my current thinking on the subject.
Imagine you enter a room that looks like this:

Despite never having visited this room, you can make inferences about it. If nobody waters the plant in the corner for several weeks, it will probably wilt. The couch is probably the most comfortable place to sit. The paintings probably have signatures that you could look at to determine who created them.
How do you do this? Let’s consider the first example.
When you first walk into this room, your eyes send you raw visual information, which doesn’t by default contain things like “plants” or “books” or “tables.” However, your brain segments out objects in your perception - you perceive object 1 (outlined in red), object 2 (outlined in blue), and object 3 (outlined in purple) as distinct things.
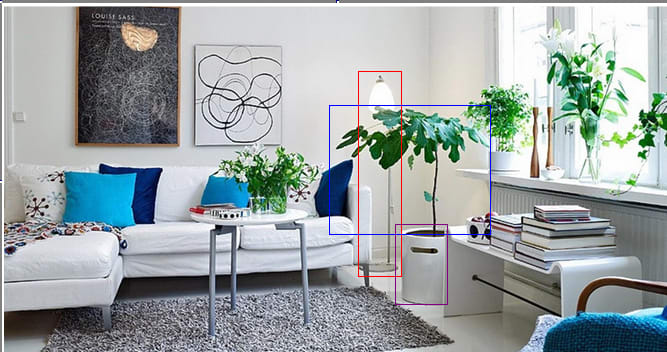
Afterwards, you identify object 2 as a plant. To do this, you need to have a notion of what a plant is, and decide that object 2 matches that notion rather than, say, the notion of “pillow.” After you determine that object 2 is a plant, you can apply information you have about plants to it. For instance, you expect that if you don’t water object 2 for two weeks it will wilt, because this is true of plants in general.
But how does this all work?
In this post I propose a framework that attempts to describe this process, centered around a dynamically constructed “concept graph.”
To start with, let’s suppose the object segmentation described above uses some form of similarity-based clustering. As you look at the room at different times and from different positions, you gather a large amount of raw input data. You recognize which parts of this input data are similar, and cluster these groups of similar data together.
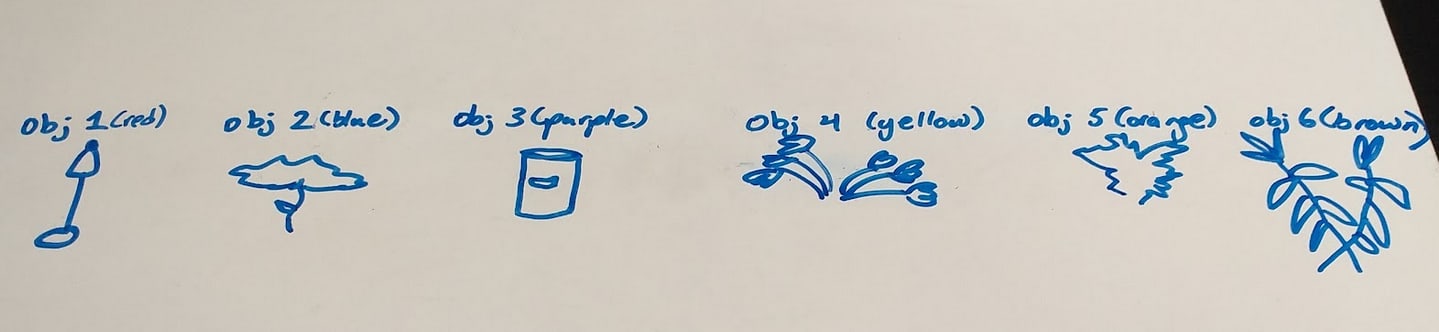
You then create a “summary” of each cluster, and store each one inside a concept, which can be thought of as a container inside your head. Each concept can be labeled “object 1,” “object 2,” “object 3,” and so on.
At this point it might be reasonable to ask what the summaries-of-data-clusters that go inside concepts actually look like; I don’t have a good answer yet, but if we examine the images below and imagine we’re clustering them together on the basis of similarity we might get a better intuitive idea of it.

Maybe a summary of this cluster looks something like an outline of the woman, without any color specified. Alternatively, maybe it’s some sort of parametrized generator that, when run, would produce the outline deterministically but sample the coloration from a distribution matching the empirical distribution in the data.
Some information in that vein could also go in the object 2 container, though I’m less clear on what a “summary” of visual data from looking at object 2 from different perspectives (front, back, top-down, etc.) would look like.
For now, let’s just picture a bunch of labeled containers (concepts), each with information inside that’s somehow based on the input data used to form the concept.
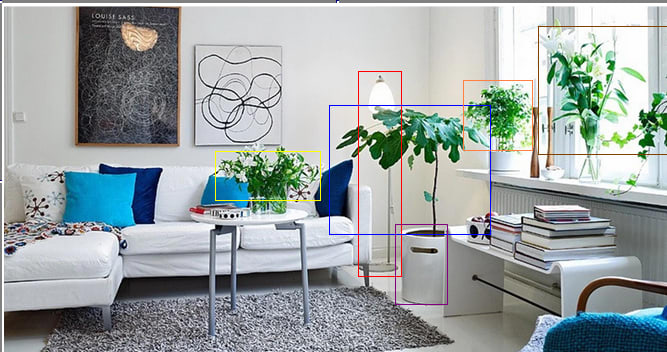
In the second image above, each concept, denoted by a label (e.g. “obj 1”) has some information inside it. Here I’ve depicted the information as a low resolution image that vaguely resembles the original object, but this is just a placeholder - again, I don’t know what the summary that goes inside the concept should look like, or what its datatype should be.
Next, you identify object 2 as a plant. I stated before that you need a notion of “plant” to match object 2 against, but where do you get that notion?
Let’s pretend for a moment that you have no idea what a plant is and are standing in the room. After segmenting out the various objects in the room, you might notice that objects 2, 4, 5, and 6 are actually quite similar (or rather, the information you’ve stored in each of the corresponding containers is).
At this point, you can create a new concept containing its own summary information, clustered across the information in the objs 2, 4, 5, and 6 containers, and give it a label. We would think of this label as being “plant,” but it isn’t strictly necessary that we use that particular name - we could just as easily call it “bloop” or “1093.” We also create a “link” or “association” between this concept and the concepts “obj 2,” “obj 4,” “obj 5,” and “obj 6.”
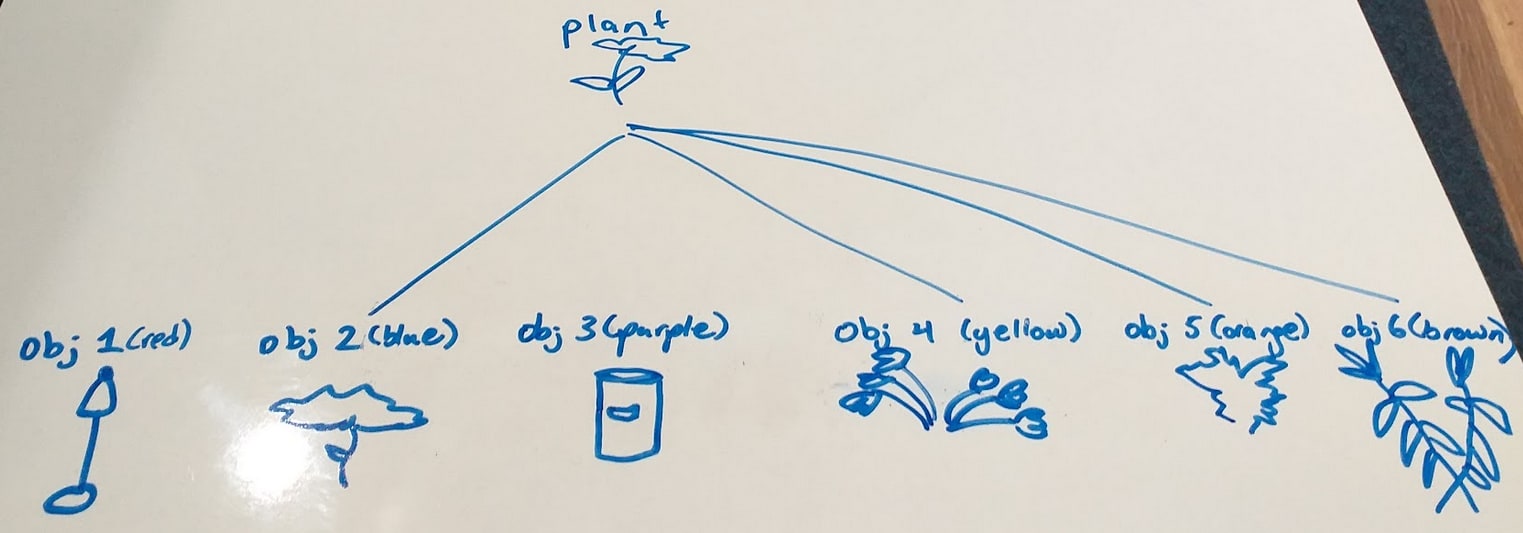
Why do I claim the label “plant” is irrelevant, and we could just as easily use the label “bloop”? Imagine if you formed this concept before entering the room we’ve been working with - you saw multiple different objects with some similarities (intuitively, leaves, greenness, attachment to the ground, etc.) and created the concept “bloop” based on your cluster of similar data.
After entering the room, you can identify object 2 as a bloop by comparing the information inside its container with the information inside bloop’s container. If it matches “closely enough,” we determine that object 2 is a bloop, and form a link between the two concepts. The name “bloop” is never used in this process; I’m only stipulating that the concepts have “labels” because the user needs to be able to access the concepts again after creating them.
So, to review: in this “concept graph” framework, you continually receive input information and cluster it based on similarity (“similarity” here being used in a vague, intuitive way). You store information about each cluster in its own labeled container, or concept.
You also cluster between the information inside different concepts to get new concepts, which are linked to the concepts they cluster over (e.g. forming the concept “plant,” and linking it to the specific plants that led you to form the concept). And you can identify concepts as belonging to a “concept cluster,” or as being linked to an existing concept (e.g. identifying “object 2” as being a plant).
For instance, a snapshot of a concept graph could look something like this:
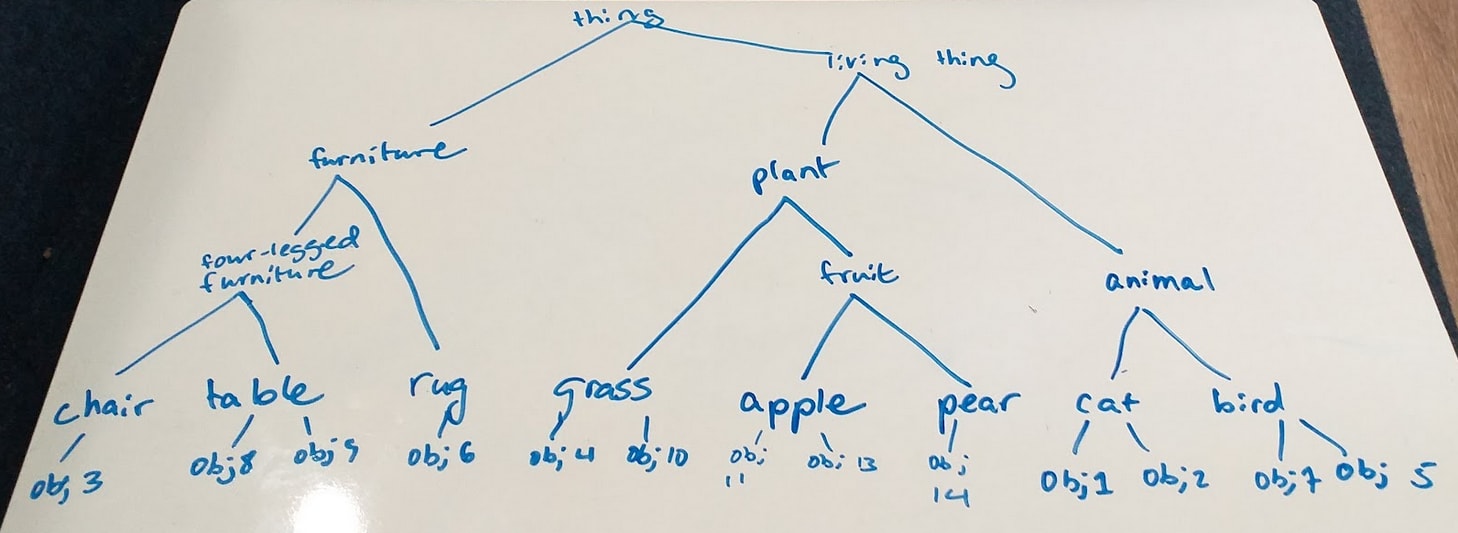
It should be noted again that the English language labels for the nodes in this graph are only here to give the reader an intuitive idea of what this graph is doing and how it might be built; as stated before, they are not really necessary and, in principle, the concepts could be labeled quite arbitrarily. The way this graph was formed, and the way it will be expanded, is through the information contained inside each concept.
There seem to be several applications for concept graphs - for instance, noticing and exploiting patterns in the world so as to make better inferences.
When we identified object 2 as a plant earlier, we made it possible to apply things we know about plants to object 2. Despite never observing object 2’s behavior when water doesn’t fall on it for an extended period of time, we can guess that it would wilt under those circumstances (by contrast, we don’t expect the lamp or the table to behave similarly if you neglect to water them).
As soon as you identify object 2 as a plant, you can apply the information you have about plants to it. You can also update the information inside your plant concept based on things you observe about object 2; if you observe that object 2 grows towards the sun, you might suspect that this is true of plants in general, propagating the information along your concept graph.
This information then becomes accessible to you when you think about other concepts linked to “plant,” and, in sum, you are able to accumulate information about all (identified) plants to inform your beliefs about all (identified) plants.
This is part of what makes learning from science feasible - observations about specific things (this water in my pot turned into steam when I heated it up) can be correctly applied to general things (maybe all water turns into steam when I heat it up), and to other specific things (I would like some steam; I should try heating up this different pot of water that I have on hand).
There are a number of things I don’t understand here - how do you correctly “propagate information” through the concept graph, given that not all information actually generalizes? How is the information in a concept represented, and how can you edit it to reflect things like “plants wilt if they receive insufficient water”? And so on. But I think that the core of what I described is true.
Another application of concept graphs is dynamically expanding or hiding information in your graph on an as-needed basis. For instance, if we look at the concept graph below, we could imagine hiding all the details inside objs 2, 4, 5, and 6, and modeling them only as plants.
Similarly, if we had a room full of chairs of various colors and shapes, in some cases we might just want to think “I have a room full of chairs - that means a lot of people can comfortably sit in this room, ” ignoring any details about the individual chairs and thinking about them using only the information in your more general concept “chair.”
In fact, you could go even further and think of, say, your desk (which might house pens, books, a lamp, a potted plant, etc.) as having a bunch of things on it, and ignore almost all the specific information about those things.
In all these cases you are reducing the “amount of stuff you have to think about and consider at a given time” - this seems to suggest benefits to computational efficiency.
When you think about throwing a house party, you can just consider the implications of the abstract things you have in your house - a kitchen, a dining table, a couch, a couple of chairs, some board games… without expending thought on all the details of your specific couch, unless it turns out you might run out of room for your guests to sit, or you have a friend who’s very particular about couches.
There is a tradeoff here, of course - you’re ignoring some of the information you have in order to save on compute. I’m not sure what governs how this tradeoff is made, or how the brain determines what details are useful for a given scenario.
I’m going to finish this post by talking about some questions and confusions I predict readers might have.
Firstly, can “clustering on information inside concepts to form new linked concepts” be reduced to “forming a hierarchical tree of concepts”? In other words, are all “links” or “associations” in the concept graph going to represent the relation “is an instance of,” in the sense that object 2 is an instance of “plant”, or “apple” is an instance of “fruit”?
No. You can also cluster on the basis of other relationships, such as “is a part of,” in the sense that “this specific leaf” might be a part of “this specific plant.” So a concept graph could look something like this, where the graph is roughly modeling the image of the two flowering plants at the top:
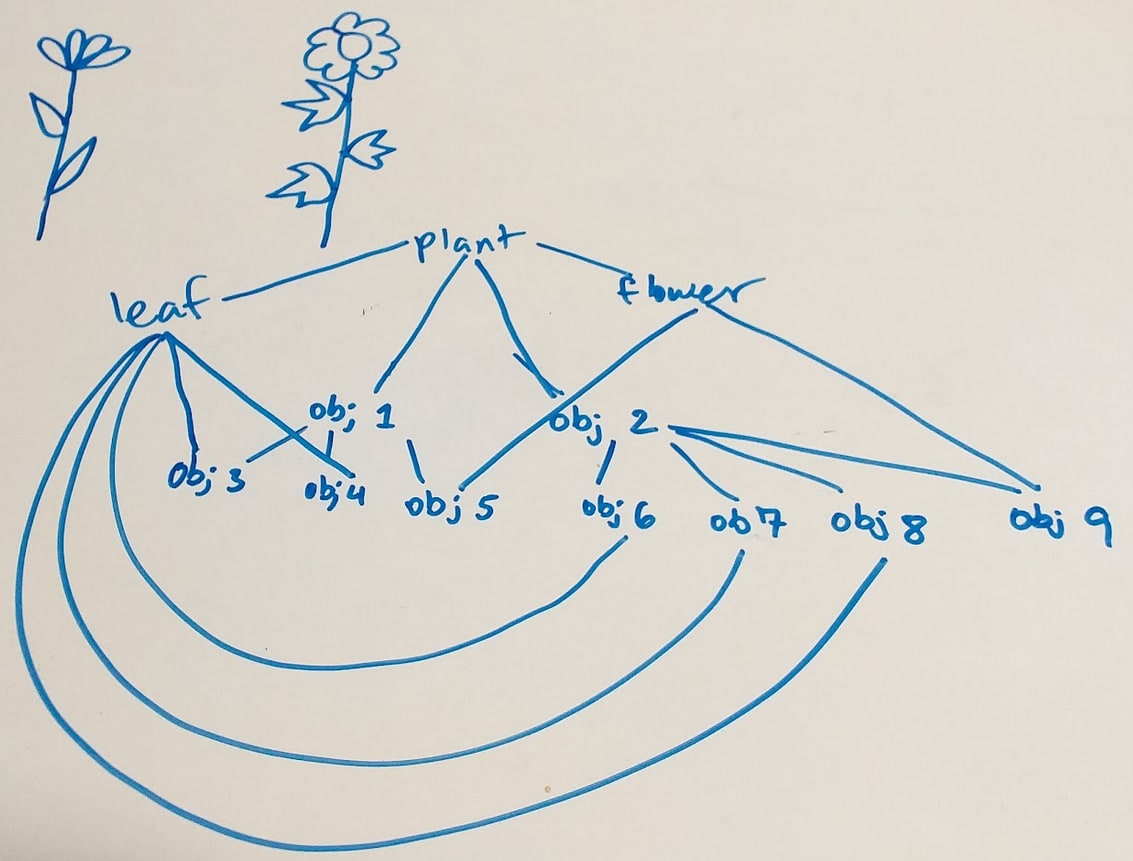
Something weird here is that the “is an instance of” and “is a part of” relations definitely seem different from each other, so why are they the same “sort of thing” in the concept graph? We clearly seem to think of these types of links differently, so shouldn’t they be represented differently in a structure that’s supposed to be able to model a process that happens in our brains?
This is entirely valid. While I don’t think these link-types or “manners of clustering” are necessarily distinguished from each other by default, I do expect that at some point they become differentiated within the concept graph.
We could illustrate this as making different types of links different colors, as shown below, where grey links are “is an instance of” relations and blue links are “is a part of” relations. This can be thought of as “meta-clustering” on the relations/links/“manners of clustering on information.”
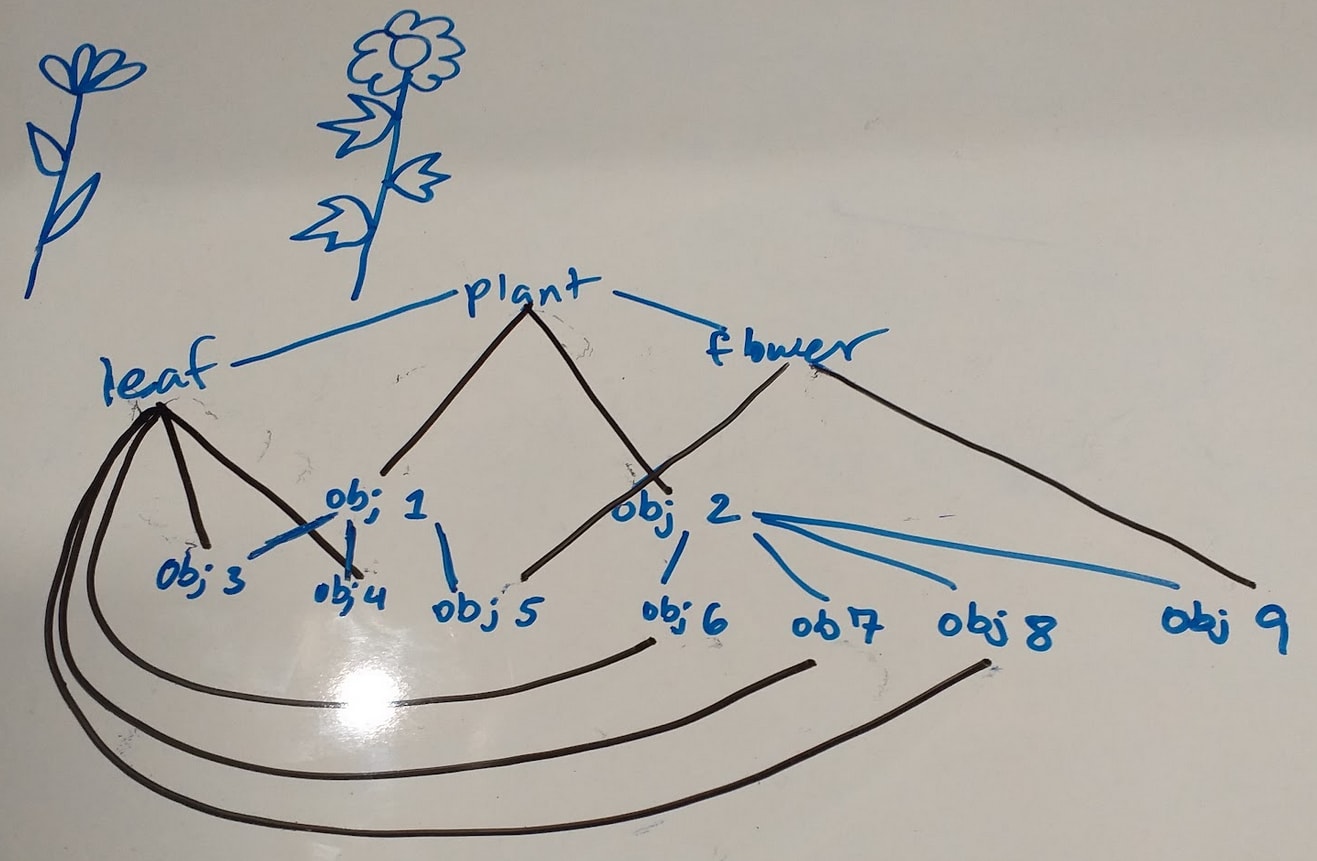
Now, does this mean that the “concept graph” is no longer actually a graph? I actually don’t know, as I’m not familiar with the formal definition of a graph. I’m currently using this name because it’s intuitively graspable to me, but I am open to changing it.
Another question one might have is: does this entire concept-formation process rely solely on “similarity”? In that case, is there some notion of “similarity” that transcends humans - thus perhaps implying that all effective concept-forming systems will form the same concepts?
Well, the first seems like it might be true, but I think the second probably isn't. While “similarity” does seem to play a large role in concept forming, and there might be some clean mathematical notion of similarity, it isn’t the only thing that influences concept formation. Utility also seems to play a part.
You don’t form every single concept you possibly could form; you only (roughly) form the ones that are useful to you. And what’s useful to you depends on your utility function; some "useful" things are instrumentally convergent, but others are not. As a basic example, humans have concepts for many, many different kinds of food (cherry pie, lasagna, ramen…), but not for other things of equivalent “objective” complexity and pattern-making potential because humans derive a lot of utility from eating food. I’m unsure how, mechanically, the utility “flows into” the concept-forming process, but it seems like it has to somehow.
0 comments
Comments sorted by top scores.