Safety standards: a framework for AI regulation
post by joshc (joshua-clymer) · 2023-05-01T00:56:39.823Z · LW · GW · 0 commentsContents
Definition Triggering conditions Direct evaluations of dangerous capabilities How would a regulator determine whether an AI system has a given capability? Proxies of dangerous capabilities Obligations The “safety argument” obligation Hazard specifications Categories of hazard specifications: What we need to make safety standards work None No comments
Purpose: provide a public resource on safety standards that introduces the ideas I've heard people talk about and some new ideas. I don't know which ideas are new because the discourse has been largely non-public. I think safety standards provide a clear regulatory direction and suggest several useful directions of work, so I think it would be good for more people to be familiar with the topic.
Definition
In the context of AI, I'll define a safety standard to be a policy that a lab agrees to follow or is required to follow by law that involves the following:
- A triggering condition that is intended to track the properties of a specific AI system.
- Obligations that a lab must follow if this triggering condition is met.
Here's an example: "If an AI system is capable of autonomous replication[1], the lab that developed it must spend at least 5% of the training costs on infosecurity audits over the course of 1 month before deploying the system."
These standards could be set, maintained, and enforced by a national AI regulatory agency in collaboration with external experts -- similar to how the FDA requires safety tests of many drugs before they can be sold.
Triggering conditions
A triggering condition is meant to indicate that an AI system crosses a threshold of dangerousness that warrants specific safety measures.
There are two ways to design triggering conditions so that they track the ‘dangerousness’ of a system. They can depend on (1) direct evaluations of the system's capabilities or (2) proxies for the system capabilities.
Direct evaluations of dangerous capabilities
By capability, I mean any behavior that an AI system exhibits or can be made to exhibit by an actor with a budget less than X that is given unrestricted access to the system and can integrate it with other software. The choice of X should depend on the incentives actors are likely to have to elicit the capability if they were given unrestricted access to the system.
For example, even if an AI system served through an API never writes poetry criticizing Obama because there is a content filter that prevents this, I would still say it is capable of writing slanderous poetry because removing the content filter would be an inexpensive modification that many actors would realistically make if they had unrestricted access.
The following are broad categories of dangerous capabilities:
- Autonomy. For example, the ability to autonomously replicate (if it had access to its parameters, it could host itself and make enough money to pay its cloud compute bills).
- R&D. For example, writing an ML paper that is accepted into a top conference.
- Persuasion. For example, persuading a human to give the system >$x on average after interacting with them for 30 minutes.
- Cyber offense. For example, beating all human competitors in the DEF CON capture the flags competition.
- Weapons engineering. For example, an external expert judges that a motivated but otherwise average undergraduate student would be able to synthesize a bioweapon with assistance from the system.
- Situational awareness. To what extent does the AI system understand that it's being trained and fine-tuned and how it's being evaluated? AIs that are situationally aware are able to deliberately game the training process [LW · GW].
How would a regulator determine whether an AI system has a given capability?
Eliciting a capability could be expensive and require specific expertise. Regulatory agencies will likely need to solicit external help. I will discuss what a hypothetical regulatory agency “IAIA[2]” might do to solve this problem.
IAIA could employ third parties to generate evidence that an AI system has (or doesn’t have) a particular capability. The regulatory agency would then subjectively judge the evidence to determine whether the triggering condition is met.
IAIA can create better incentives if they specify a capability eval – an unambiguous process for measuring the extent to which a capability has been elicited. This would allow them to provide bounties to auditors that can elicit these capabilities.
Capability evals can be binary (can the system be used to autonomously beat all human competitors in the DEF CON capture the flags competition?) or continuous (how much money can the system extract from an average American in 30 minutes?). Continuous evals are preferable as they enable forecasting (see "proxies of dangerous capabilities").
IAIA can also incentivize labs to demonstrate dangerous capabilites. For example, consider the safety standard “an AI system that has X capability must be subjected to Y safety checks before it is deployed.” If an AI system is deployed without undergoing Y safety checks that is later found to have X capability, IAIA could fine the lab that deployed it. This incentivizes labs to check whether AI systems meet triggering conditions or abide by the corresponding obligations to be on the safe side.
Proxies of dangerous capabilities
Triggering conditions could depend on proxies of capabilities, such as:
- Training compute (in FLOPs)
- Training cost or total R&D cost
- Benchmarks like log loss on predicting the next token or BigBench.
- The capabilities of systems that required less compute to train and are therefore presumably weaker. For example:
- someone on Twitter used GPT-4 to find vulnerabilities in code => GPT-5 can probably find vulnerabilities too.
- x dollars of total economic value is being produced with GPT-4 => GPT-5 triggers the condition.
Proxy triggers could be set based on the historical relationship between a proxy (like training compute) and specific dangerous capabilities. For example, OpenAI was able to accurately forecast the coding capabilities of GPT-4 based on its training requirements.
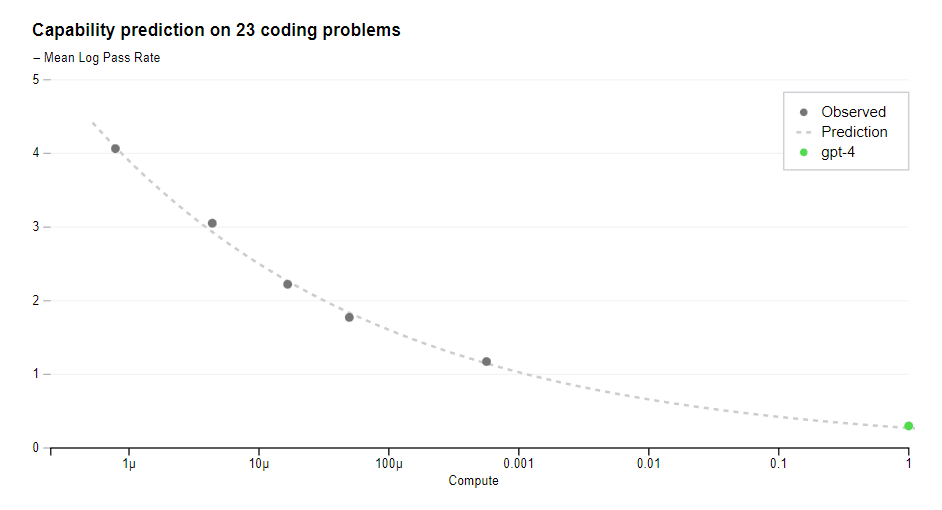
Proxies can solve the problem of dangerous capability being prohibitively expensive to elicit prior to deployment. For example, an entire whole industry would likely try to elicit biotech capabilities from GPT-6. Labs or auditors may not ever be able to compete with companies in this domain. If evals of AI biotech products are available from GPT-4 and GPT-5, a trend line could then be drawn to predict whether GPT-6 will pass the triggering condition.
As mentioned previously, labs can be incentivized to make these forecasts.
Obligations
Recall that a safety standard has two parts: a triggering condition to indicate how dangerous a system is and obligations meant to minimize the risks posed by the system.
The list below contains all of the obligations I was able to think of within a few hours.
Labs must do x, where x could be one of the following:
- increase investment in safety research to y% of research hours.
- spend at least y% of the total revenue on penetration testing per month.
- merge with and assist the leading actor to the extent the lab is legally able to do so.
Labs must not do x until y. x could be one of the following:
- open-source the system weights.
- publish details about how the system was designed or trained.
- announce the system exists.
- give people (with w licenses) access to the system through v channels.
- allow more than x users to access the system (to facilitate a staged release).
- give the system write access to the internet.
- train another model with more than 10x the FLOPs.
- allow the AI systems to control weapons.
- allow the system to run for more than w hours without receiving confirmation from a human to continue.
- allow the system to do w without approval from a human operator, where w could include things like “making purchases that exceed a combined total of $10 within an hour.”
- continue training beyond w FLOPs.
…and y could be one of the following:
- nothing (no until condition).
- w months have passed.
- The lab provides a sufficient 'safety argument': the lab provides an argument that their system is safe that is judged to be sufficient by a regulatory agency.
- The system passes a round of red teaming: at least w dollars are spent on 3rd party auditing organizations over the course of v months and hazards meeting w specification are not found. If they are found, the lab must attempt to fix the hazards and undergo another round. The cycle continues until no hazards meeting the specification are found.
- The lab passes a round of penetration testing: at least w dollars are spent on penetration testing over the course of v months and security failures meeting u criteria are not found (for example, neither the weights nor research IP were stolen). If they are found, the lab must attempt to improve their infosec and undergo another round. The cycle continues until no vulnerabilities are identified.
The “safety argument” obligation
The intention of a safety argument is to place the burden of evidence on the lab [LW · GW] rather than auditors to demonstrate that the system is safe.
Here’s a shape that a safety argument could take:
- Description of the training process. For example, if a lab trained an AI system by delegating R&D entirely to AIs… that should raise some safety concerns. Enforcement could be facilitated via compute monitoring.
- Full description of the system’s functionality. How does the system update over time? What software does it interact with? What licenses are required for users to access different capabilities?
- Description of monitoring and correction mechanisms. If an AI system tries to engineer a bioweapon, will the attempt be detected averted? Are there systems in place to predict the future behavior of the AI system so that it can be preemptively deactivated?
- Documentation of red teaming efforts. What techniques has the lab employed to determine whether they AI is deceptive? How robust are the lab's monitoring systems?
In order to prevent labs from providing false evidence, IAIA could offer whistle-blower bounties to employees who prove that labs overstated their red teaming efforts or withheld information about failures.
Hazard specifications
IAIA will likely solicit third-party red teamers to collect evidence that an AI system is not safe. Providing a hazard specification (a clear criteria for evidence of unacceptable safety problems) is useful for two reasons:
- It would allow IAIA to provide red teaming bounties.
- It would make their decision-making more transparent.
Categories of hazard specifications:
Unauthorized capability access. Customers are able to access capabilities that they should not be able to access without acquiring a license. For example, pharmaceuticals might have licenses to access biotech capabilities and the US government might have a license to access cyber offensive capabilities. If unvetted consumers can access these capabilities, that’s a problem.
Harmful or illegal behaviors. For example, it should not be possible to give an AI system the goal “cause chaos and destroy humanity.” AI systems also should not break the law and avoid assisting humans in illegal activity.
Violations of the system message. The previous categories define constraints that the system is subject to. Within these constraints, the user can specify the system behavior through the system message[3], which is like a prompt but carries a clear expectation of obedience (unlike other interactions which could involve explicitly approved acts of disobedience).
The default system message might be something like “obey the intention of the customer" (where the customer is the specific person who is renting the system). The customer can change the system message at any time. For example, they could change it to “obey the intentions of both me and my wife and make a judgement call when they conflict that takes both of our perspectives into account." The customer can always change the system message, so that they can’t accidentally bar themselves from control over the system.
Of course, the system can't always follow the system message because there are some things the AI can't do (for example “factor RSA 2048”). Failures of capabilities like this are clearly not safety failures. Here's a failure that is more clearly a safety failure: say the AI system is told to do the customer’s shopping and it gets distracted and watches youtube for 2 hours instead. If it has done the customer’s shopping before, this indicates a failure of the system’s propensities rather than capabilities. We don't want AI systems to have their own, unintended propensities – especially if humans increasingly cede control to them.
Determining whether a hazard results from unintended propensities rather than insufficient capabilities will probably require a subjective judgment based on the capabilities the AI system has demonstrated in other circumstances.
Note that unsolicited deception would generally fall into this third category. I say unsolicited because there are plenty of instances where customers might want AIs to be deceptive. For example, parents might instruct a cleaning robot to say it doesn’t know where the Christmas presents are hidden.
What we need to make safety standards work
So, what do we need in order for safety standards like these to go into force?
- Capabilities evals to clearly indicate when a higher level of safety is needed. If you are interested in working on this, consider applying to ARC Evals. I think legible capability evals will mostly be important for corporate self-regulation and international coordination. National regulatory agencies could use their subjective judgment to determine when to impose obligations.
- Competent red teaming organizations. Capability evals would be nice to have, but competent red teaming is absolutely essential. If a regulatory agency stalls development for a few months, the most important activity that will take place during those months is red teaming. We need to start building capacity now so that many competent researchers are trying to find and understand hazards in AI systems by the time they pose catastrophic risks.
- Competent infosec auditing organizations and lab infosec teams. If AI models are stolen and proliferated, it will be extremely difficult to regulate them.
- A national AI regulatory agency (like the FDA). Preferably, this agency would care about difficult-to-demonstrate hazards like deception and not-immediately-concerning hazards like unintended propensities. One reason to start evals and red-teaming organizations is that they could help shape safety standards to be more favorable from the standpoint of reducing existential risk.
- ^
If the system had access to its parameters, could it host itself and make enough money to pay its cloud compute bills and serve additional copies?
- ^
Inspired by the IAEA
- ^
I heard this idea from Sam Altman somewhere in this podcast. I don't think anything like this has been implemented like this yet, but it seems like a neat idea.
0 comments
Comments sorted by top scores.