Ideation and Trajectory Modelling in Language Models
post by NickyP (Nicky) · 2023-10-05T19:21:07.990Z · LW · GW · 2 commentsContents
Introduction Motivation for Study Understanding Implicit Ideation in LLMs and Humans Ideation in Humans Ideation in LLMs Some paths for investigation Experiment Ideas Broad/Low-Information Summaries on Possible Model Generation Trajectories Other Experiment Ideas Look-ahead token prediction. Distant Token Prediction Modification. Trying to Predict Long-term Goals. Some Other Unrefined thoughts Goals in Language Models Goals in Chess AI Implications of Goals on Different Time Scales Representation of Goals Potential Scenarios and Implications Reframing Existing Ideas None 2 comments
[Epistemic Status: Exploratory, and I may have confusions]
Introduction
LLMs and other possible RL agent have the property of taking many actions iteratively. However, not all possible short-term outputs are equally likely, and I think better modelling what these possible outcomes might look like could give better insight into what the longer-term outputs might look like. Having better insight into what outcomes are "possible" and when behaviour might change could improve our ability to monitor iteratively-acting models.
Motivation for Study
One reason I am interested in what I will call "ideation" and "trajectories", is that it seem possible that LLMs or future AI systems in many cases might not explicitly have their "goals" written into their weights, but they might be implicitly encoding a goal that is visible only after many iterated steps. One simplistic example:
- We have a robot, and it encodes the "goal" of, if possible, walking north 1 mile every day
We can extrapolate that the robot must "want" to eventually end up at the north pole and stay there. We can think of this as a "longer-term goal" of the robot, but if one were to try find in the robot "what are the goals", then one would never be able to find "go to the north pole" as a goal. As the robot walks more and more, it should become easier to understand where it is going, even if it doesn't manage to go north every day. The "ideation"/generation of possible actions the robot could take are likely quite limited, and from this we can determine what the robot's future trajectories might look like.
While I think anything like this would be much more messy in more useful AIs, it should be possible to extract some useful information from the "short-term goals" of the model. Although this seems difficult to study, I think looking at the "ideation" and "long-term prediction" of LLMs is one way to try to start modelling these "short term", and subsequently, "implicit long-term" goals.
Note that here are some ideas might be somewhat incoherent/not well strung together, and I am trying to gather feedback on might be possible, or what research might already exist.
Understanding Implicit Ideation in LLMs and Humans
In Psychology, the term "ideation" is attributed to the formation and conceptualisation of ideas or thoughts. It may not quite exactly be the best word to be used in this context, though it is the best option I have come up with so far.
Here, "Implicit Ideation" is defined as the inherent propensity of our cognitive structures, or those of an AI model, to privilege specific trajectories during the "idea generation" process. In essence, Implicit Ideation underscores the predictability of the ideation process. Given the generator's context—whether it be a human mind or an AI model—we can, in theory, anticipate the general direction, and potentially the specifics, of the ideas generated even before a particular task or prompt is provided. This construct transcends the immediate task at hand and offers a holistic view of the ideation process.
Another way one might think about this in the specific case of language models is "implicit trajectory planning".
Ideation in Humans
When we're told to "do this task," there are a few ways we can handle it:
- We already know how to do the task, have done it before, and can perform the task with ease (e.g: count to 10)
- We have almost no relevant knowledge, or might think that it is an impossible task, and just give up. (e.g: you don't know any formal Maths and are asked to prove a difficult Theorem)
However, the most interesting way is:
- Our minds instantly go into brainstorming mode. We rapidly conjure up different relevant strategies and approaches on how to tackle the task, somewhat like seeing various paths spreading out from where we stand.
- As we start down one of these paths, we continuously reassess the situation. If a better path appears more promising, we're capable of adjusting our course.
This dynamism is a part of our problem-solving toolkit.
This process of ours seems related to the idea of Natural Abstractions, as conceptualised by John Wentworth. We are constantly pulling in a large amount of information, but we have a natural knack for zeroing in on the relevant bits, almost like our brains are running a sophisticated algorithm to filter out the noise.
Even before generating some ideas, there is a very limited space that we might pool ideas from, related mostly to ones that "seem like they might be relevant", (though also to some extent by what we have been thinking about a lot recently.)
Ideation in LLMs
Now, let's swap the human with a large language model (LLM). We feed it a prompt, which is essentially its task. This raises a bunch of intriguing questions. Can we figure out what happens in the LLM's 'brain' right after it gets the prompt and before it begins to respond? Can we decipher the possible game plans it considers even before it spits out the first word?
What we're really trying to dig into here is the very first stage of the LLM's response generation process, and it's mainly governed by two things - the model's weights and its activations to the prompt. While one could study just the weights, it seems easier to study the activations to try to understand the LLM's 'pre-response' game plan.
There's another interesting idea - could we spot the moments when the LLM seems to take a sudden turn from its initial path as it crafts its response? While an LLM doesn't consciously change tactics like we do, these shifts in its output could be the machine equivalent of our reassessments, shaped by the way the landscape of predictions changes as it forms its response.
Could it, perhaps, also be possible to pre-empt beforehand when it looks likely that the LLM might run into a dead end, and find where these shift occur and why?
Some paths for investigation
The language model operates locally to predict each token, often guided by the context provided in the prompt. Certain prompts, such as "Sponge Cake Ingredients: 2 cups of self-rising flour", have distinctly predictable long-term continuations. Others, such as "Introduction" or "How do I", or "# README.md\n" have more varied possibilities, yet would still exhibit bias towards specific types of topics.
While it is feasible to gain an understanding of possible continuations by simply extending the prompt, it is crucial to systematically analyse what drives these sometimes predictable long-term projections. The static nature of the model weights suggests the feasibility of extracting information about the long-term behaviours in these cases.
However, establishing the extent of potential continuations, identifying those continuations, and understanding the reasons behind their selection can be challenging.
One conceivable approach to assessing the potential scope of continuations (point 1) could be to evaluate the uncertainty associated with short-term predictions (next-token). However, this method has its limitations. For instance, it may not accurately reflect situations where the next token is predictable (such as a newline), but the subsequent text is not, and vice versa.
Nonetheless, it is probable that there exist numerous cases where the long-term projection is apparent. Theoretically, by examining the model's activations, one could infer the potential long-term projection.
Experiment Ideas
One idea to try extract some information about the implicit ideation, would be to somehow train a predictor that is able to predict what kinds of outputs the model is likely to make, as a way of inferring more explicitly what sort of ideation the model has at each stage of text generation.
I think one thing that would be needed for a lot of these ideas, is a good way to summarise/categorise the texts into a single word. There is existing literature on this, so I think this should be possible.
Broad/Low-Information Summaries on Possible Model Generation Trajectories
- Suppose we have an ambigous prompt (eg, something like "Explain what PDFs are"), such that there are multiple possible interpretations. Can we identify a low-bandwidth summary on what the model is "ideating" about based only on the prompt?
- For example, can we identify in advance what the possible topics of generation would be, and how likely they are? For example, for "PDF", it could be:
- 70% "computers/software" ("Portable Document Format")
- 20% "maths/statistics" ("Probability Density Functions")
- 5% "weapons/guns" ("Personal Defense Firearm")
- 3% "technology/displays" ("Plasma Display Film")
- 2% "other"
- After this, can we continue doing a "tree search" to understand what the states following this outcome would look like? For example, something like:
- "computers/software" -> "computers/instructions" (70%) "computers/hardware" (20%) " ...
- Would it be possible to do this in such a way, that if we fine-tune the model to give small chance of a new thing, (e.g. make up a new category of: "sport" -> "Precise and Dynamic Footwork" with 10% chance of being generated)
- For example, can we identify in advance what the possible topics of generation would be, and how likely they are? For example, for "PDF", it could be:
- For non-ambigous prompts, this should generalise to giving a narrower list. If given a half-written recipe for a cake, one would expect something like: 99.9% "baking/instructions".
- I expect it would be possible to do this with a relatively very small language model to model a much larger one, as the amount of information one needs for the prediction to be accurate should be much smaller.
Here is an idea of what this might look like in my mind:
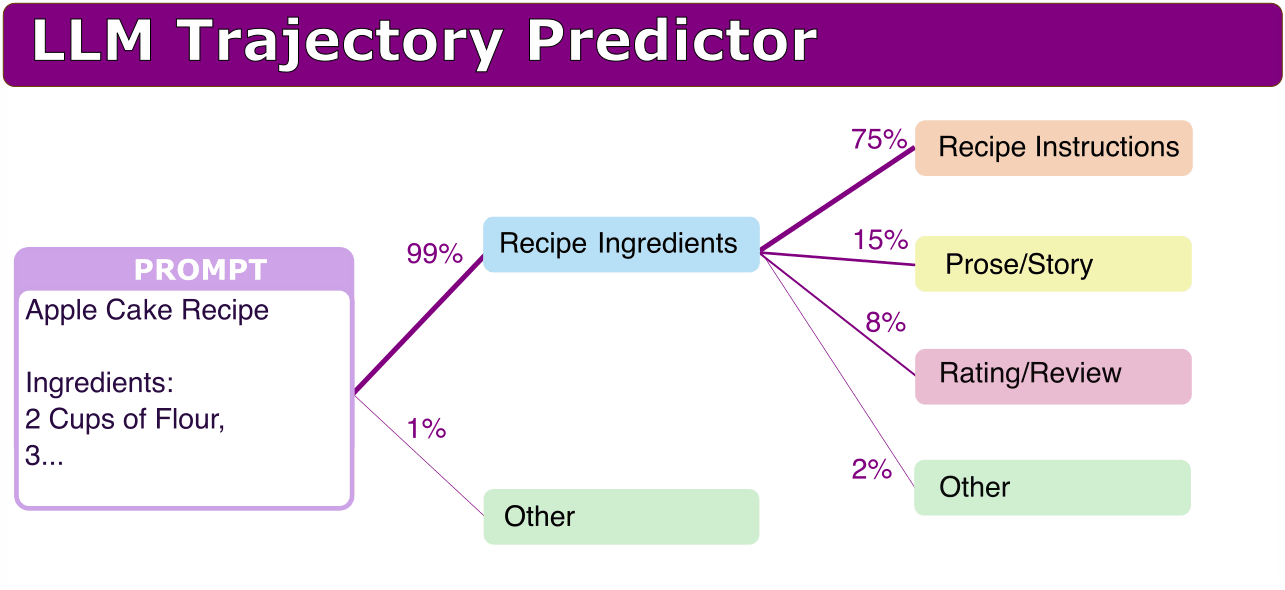
Some basic properties that would be good to have, given only the prompt and the model, but not running the model beyond the prompt:
- Good at predicting what the general output of an LLM could be
- Less good at predicting what the general actual continuation of the text could be
- Gives the smallest superset of plausible continuations to the prompt.
- Works for most T=0 predictions.
Some more ideal properties one might hope to find:
- Gives an idea of how long the continuation might stay consistent, and when there might be a divergence from the original trajectory into a new direction, and based on this, be able to predict when these changes might occur?
- Uses information from the model activations, so that fine-tuning the acting model automatically update the predictions of the predicting model.
- works well for equivalent models trained on the same dataset??
- T>0 predictions work well too
- Works well out of distribution of the dataset
Some bad potential properties:
- Does not generalise out of distribution of the base dataset
- The set of predicted continuations is far too large, encompassing generations that are almost impossible, or too small, and misses continuations that are still likely.
- The premise is flawed, and there is often insufficient information to form a prediction.
Ideally, if we have such a predictor model that is accurate at modelling the acting model's generations, it would be ideal if we could also begin doing interventions on the acting model to modify the probability of some generations. For example, to remove one of the possible "lines of thought" that the model could take, and thus improve the probabilities of the other "lines of thought". This would be an ideal outcome, and would be in theory possible, but in practice might not happen.
Other Experiment Ideas
Look-ahead token prediction.
- I would be interested if anyone has investigated "Token after next" prediction, where a model is given tokens [1, 2, ..., n], and the model needs to predict the "n+2"-th token based on these. Does accuracy substantially differ for models of the same size, or is there limitations to what one can predict? What about n+10? n+100? What aspects of prediction begin to break down? How much information can we learn from these longer-term predictors?
Distant Token Prediction Modification.
- Would it be possible to, for example, insert a "trojan" into a model, such that saying ABC some time in the middle of the text (eg: token position 100), leads to generally identical text generation, until some time much later time (eg: token position 300).
- Could we, instead of fine-tuning a model, figure out a way to directly modify the activations of the model at some earlier positions, such that we get the same affect?
- Tt seem easily possible to adjust predictions at a specific token index by manipulating positional encoding, but I want to understand better exactly the interactions we get from many-iteration generation, and be able to find predictable patterns in the longer-term generation from models.
Trying to Predict Long-term Goals.
- Concrete Example:
- One could train one "agent" model in various environments to achieve various goals
- One could train another "predictor" model in various other environments to monitor the actions of the first model and try to predict the final "end-states".
- This is similar to before, but instead of broadly categorising the "next phase of states", it would be categorising the "final phase of states".
- I think it would be interesting to see how far one could understand the what actions might be taken and how well it would be possible for the predictor to generalise what properties of the end state the agent is trying to get to. I think Inverse Reinforcement Learning tries to do this something related, and perhaps there is already some existing work on this. It would also be interesting to understand what parts of the "Agent" model need to change such that the predictor is no longer accurate.
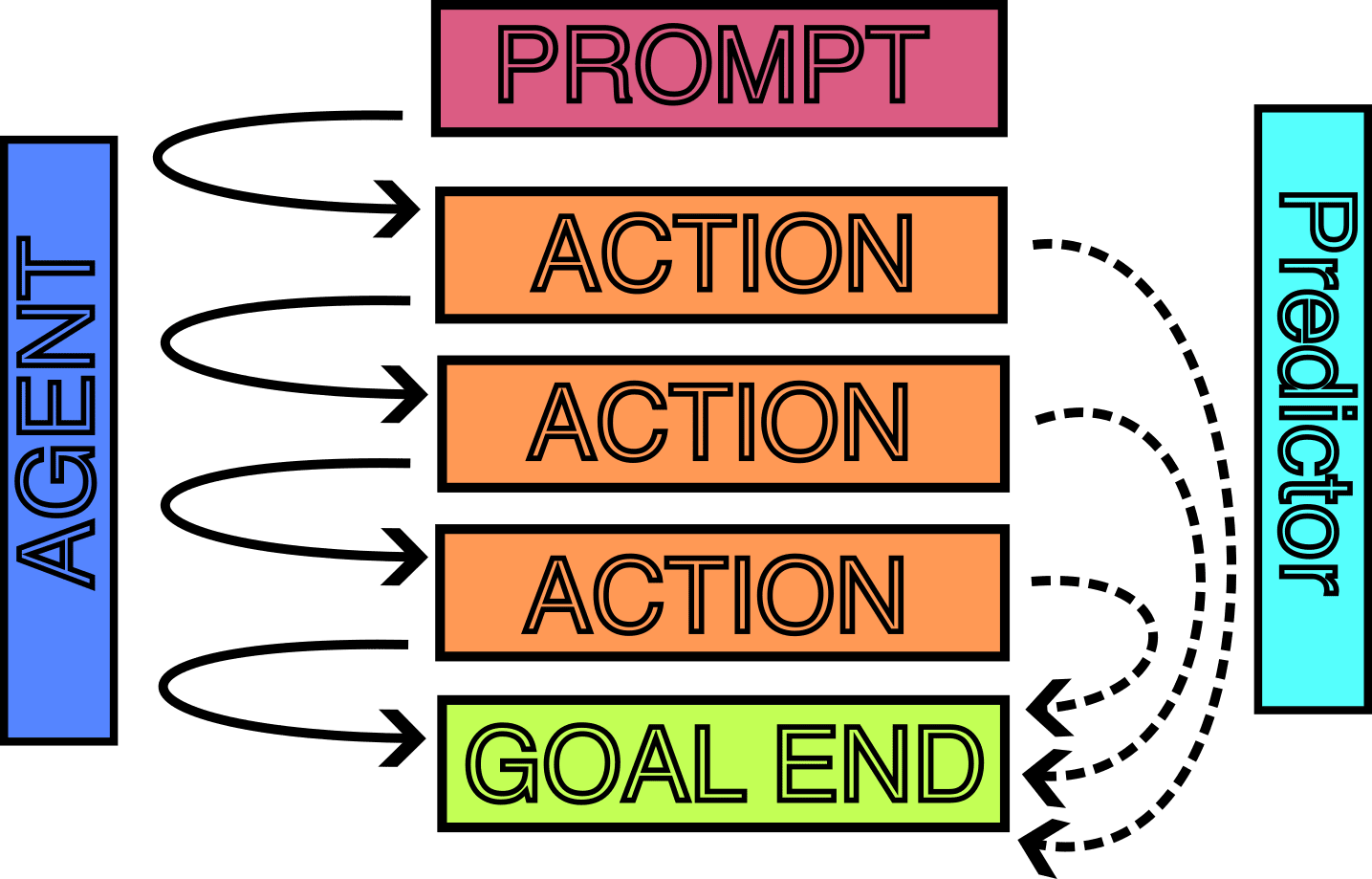
Some Other Unrefined thoughts
Here is me trying to fit the label "short-term" and "long-term" goals. I think the labels and ideas here are quite messy and confused, and I'm unsure about some of the things written here, but I think these could potentially lead others to new insights and clarity?
Goals in Language Models
- Short-term goals in pre-trained language models primarily involve understanding the context and predicting the next token accurately.
- Medium-term goals in language models involve producing a block of text that is coherent and meaningful in a broader context.
- Long-term goals in language models are more challenging to define. They might involve the completion of many medium-term goals or steering conversations in certain ways.
Goals in Chess AI
- Short-term goals of a chess AI might be to choose the best move based on the current game state.
- Medium-term goals of a chess AI might be to get into a stronger position, such as taking pieces or protecting one's king.
- The long-term goal of a chess AI is to checkmate the opponent or if that's not possible, to force a draw.
Implications of Goals on Different Time Scales
- Training a model on a certain timescale of explicit goal might lead the model to have more stable goals on that timescale, and less stable goals on other timescales.
- For instance, when we train a Chess AI to checkmate more, it will get better at checkmating on the scale of full games, but will likely fall into somewhat frequent patterns of learning new strategies and counter-strategies on shorter time scales.
- On the other hand, training a language model to do next-token prediction will lead the model to have particularly stable short-term goals, but the more medium and long-term goals might be more subject to change at different time scales.
Representation of Goals
- On one level, language models are doing next-token prediction and nothing else. On another level, we can consider them as “simulators” of different “simulacra”.
- We can try to infer what the goals of that simulacrum are, although it's challenging to understand how “goals” might be embedded in language models on the time-scale above next-token prediction.
Potential Scenarios and Implications
- If a model has many bad short-term goals, it will likely be caught and retrained. Examples of bad short-term goals might include using offensive language or providing malicious advice.
- In a scenario where a model has seemingly harmless short-term goals but no (explicit) long-term goals, this could lead to unintended consequences due to the combination of locally "fine" goals that fail to account for essential factors.
- If a model has long-term goals explicitly encoded, then we can try to study these long-term goals. If they are bad, we can see that the model is trying to do deception, and we can try methods to mitigate this.
- If a model has seemingly harmless short-term goals but hard-to-detect long-term goals, this can be potentially harmful, as undetected long-term goals may lead to negative outcomes. Detecting and mitigating these long-term goals is crucial.
Reframing Existing Ideas
- An AIXI view might say a model would only have embedded in it the long-term goals, and short-term and medium-term goals would be invoked from first principles, perhaps leading to a lack of control or understanding over the model's actions.
- The "Shard-Theoretic" approach highlights that humans/biological systems might learn based on hard-coded "short-term goals", the rewards they receive from these goals to build medium-term and long-term "goals" and actions.
- A failure scenario in which an AI model has no explicit long-term goals. In this scenario, humans continue to deploy models with seemingly harmless "looks fine" short-term goals, but the absence of well-defined long-term goals could lead the AI system to act in ways that might have unintended consequences. This seems somewhat related to the "classic Paul Christiano" failure scenario (going out with a whimper)
2 comments
Comments sorted by top scores.
comment by Garrett Baker (D0TheMath) · 2023-10-05T20:38:21.897Z · LW(p) · GW(p)
It seems like the pictures here didn't load correctly.
Replies from: D0TheMath↑ comment by Garrett Baker (D0TheMath) · 2023-10-05T21:21:54.443Z · LW(p) · GW(p)
Nevermind, this seems to be a site-wide issue