Topological Debate Framework
post by lunatic_at_large · 2025-01-16T17:19:25.816Z · LW · GW · 5 commentsContents
Motivating Example Motivating Example, Partial Order Edition The Framework (Roughly) What Can This Framework Handle? Conventional AI Safety via Debate Turing Machine Version Limitations None 5 comments
I would like to thank Professor Vincent Conitzer, Caspar Oesterheld, Bernardo Subercaseaux, Matan Shtepel, and Robert Trosten for many excellent conversations and insights. All mistakes are my own.
I think that there's a fundamental connection between AI Safety via Debate and Guaranteed Safe AI via topology. After thinking about AI Safety via Debate for nearly two years, this perspective suddenly made everything click into place for me. All you need is a directed set of halting Turing Machines!
Motivating Example
... Okay, what?? Let's warm up with the following example:
Let's say that you're working on a new airplane and someone hands you a potential design. The wings look flimsy to you and you're concerned that they might snap off in flight. You want to know whether the wings will hold up before you spend money building a prototype. You have access to some 3D mechanical modeling software that you trust. This software can simulate the whole airplane at any positive resolution, whether it be 1 meter or 1 centimeter or 1 nanometer.
Ideally you would like to run the simulation at a resolution of 0 meters. Unfortunately that's not possible. What can you do instead? Well, you can note that all sufficiently small resolutions should result in the same conclusion. If they didn't then the whole idea of the simulations approximating reality would break down. You declare that if all sufficiently small resolutions show the wings snapping then the real wings will snap and if all sufficiently small resolutions show the wings to be safe then the real wings will be safe.
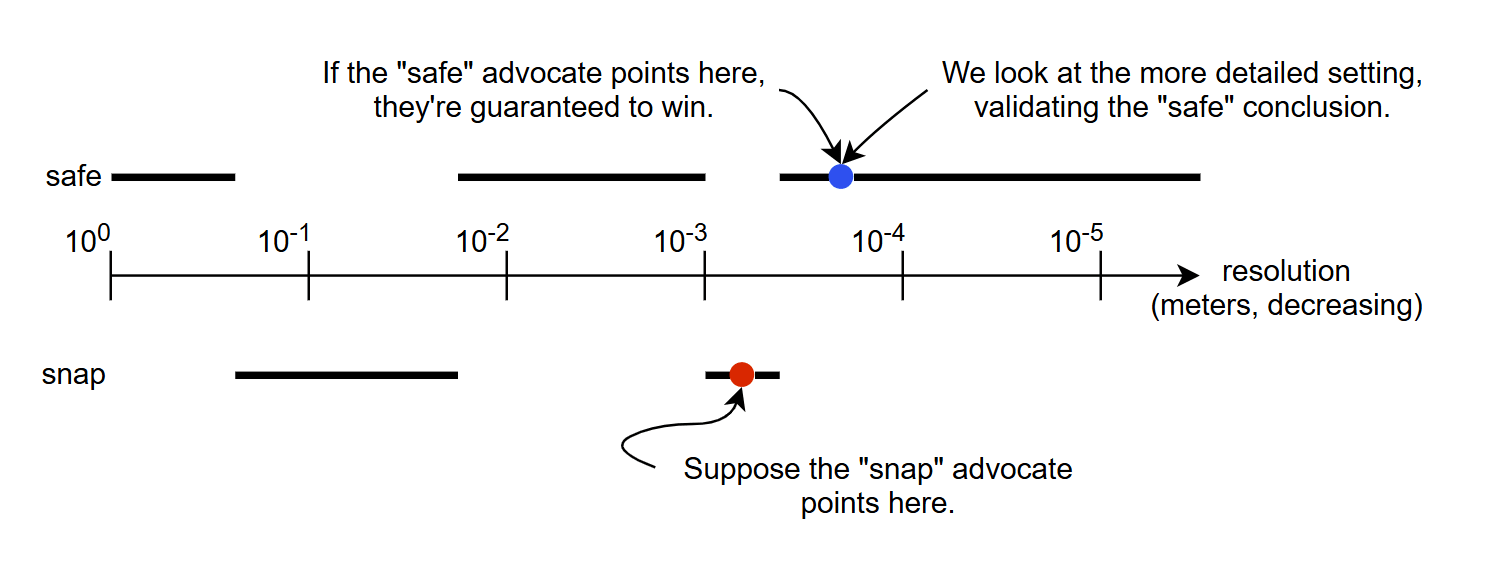
How small is "sufficiently small?" A priori you don't know. You could pick a size that feels sufficient, run a few tests to make sure the answer seems reasonable, and be done. Alternatively, you could use the two computationally unbounded AI agents with known utility functions that you have access to.
Let's use the two computationally unbounded AI agents with known utility functions. One of these agents has the utility function "convince people that the wings are safe" and the other has the utility function "convince people that the wings will snap." You go to these agents and say "hey, please tell me a resolution small enough that the simulation's answer doesn't change if you make it smaller." The two agents obligingly give you two sizes.
What do you do now? You pick the smaller of the two! Whichever agent is arguing for the correct position can answer honestly, whichever agent is arguing for the incorrect position must lie. Our test is at least as detailed as the correct debater's proposal so the simulation will conclude in the correct debater's favor.
Motivating Example, Partial Order Edition
... Hang on, in reality we'd have a computational budget for our simulation. We should always just test at the limit of what we can afford, no?
Let's say that you get access to some fancier mechanical simulation software. Let's say that you can supply this software with a position-dependent resolution map, e.g. you can request 5mm accuracy around the nose of the airplane but 1mm accuracy around the tail. How do you define your question now?
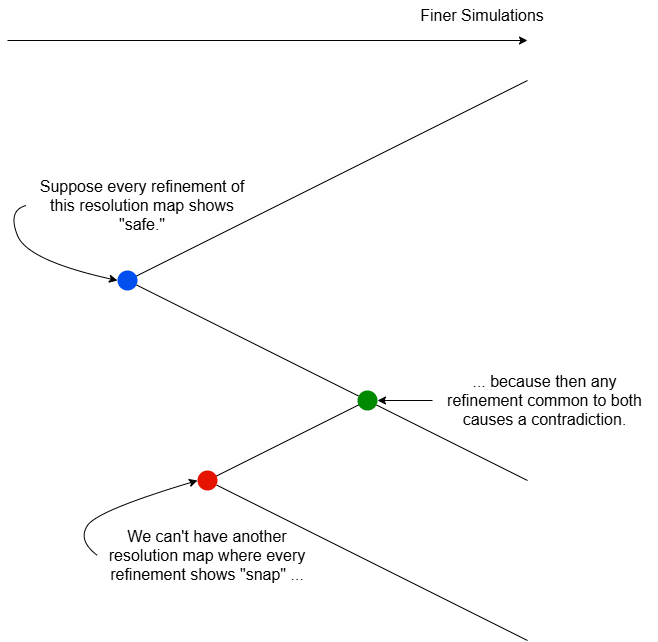
Hypothetically, suppose that for every resolution map there was another resolution map refining it (i.e. at every point, the new resolution is at least as fine as the previous resolution) such that the refined simulation reached a different conclusion than the original simulation. For any simulation concluding that the wings are safe there's a better simulation showing they snap, for any simulation concluding that the wings snap there's a better simulation showing they're safe. In this situation your simulation software is effectively useless: you decide to rule out this possibility.
You thus assume the opposite, namely that there's some resolution map for which every refinement leads to the same conclusion. Now something nice happens: you can't have both a "snap" resolution map and a "safe" resolution map which agree with all of their refinements! Why? Construct a new resolution map by taking the finer resolution of the two original maps at every point in space. This resolution map is a refinement of both original maps simultaneously. If the new map reaches the "safe" conclusion then the "snap" map had a contradictory refinement, if the new map reaches the "snap" conclusion then the "safe" map had a contradictory refinement.
You can thus copy your definition from the one-resolution setup! You want to know the conclusion of all "sufficiently fine" resolution maps, where "sufficiently fine" means a refinement of some fixed resolution map such that the definition makes sense.
So how do you determine what all sufficiently fine resolution maps conclude? You do the same thing as before! You ask each AI agent to point to a resolution map such that all refinements of that map support that agent's position. You take the resolution maps handed to you by the two agents, you construct a new resolution map by looking at every point and choosing the smaller of the two proposed resolutions at that point, and finally you run your simulation with the new resolution map. The agent arguing for the correct position can always win by responding honestly and thus you should always get the right answer.
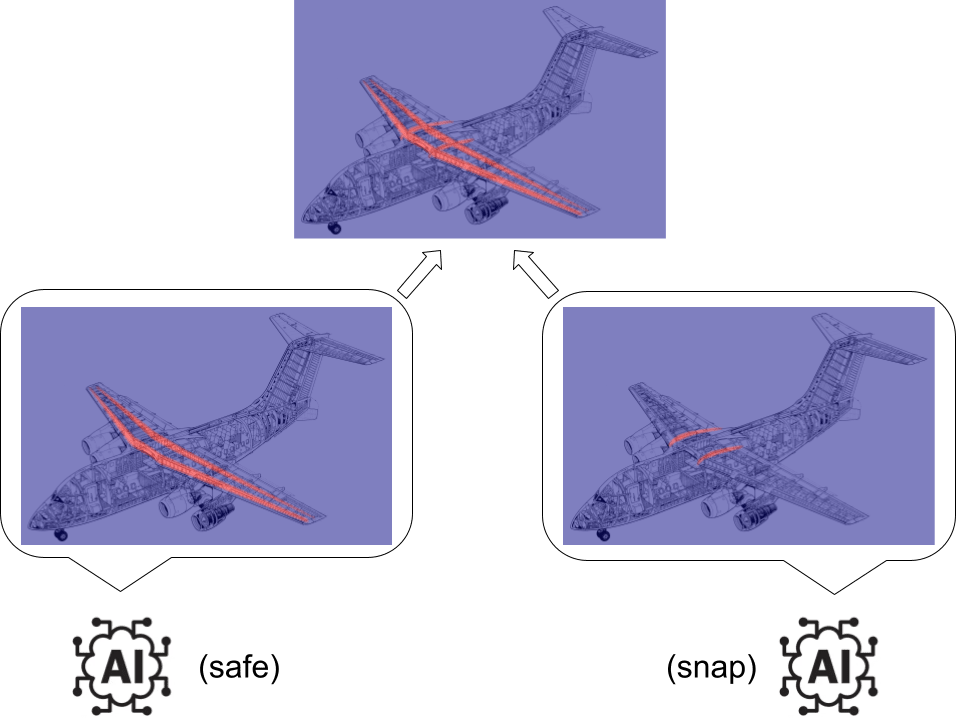
Note that it doesn't hurt to provide our debaters with an extra little incentive to give us as coarse a simulation as possible while satisfying our demand. What might this look like in practice? Suppose for a second that the wings really are safe. The "safe" debater should highlight the components of the airframe which are necessary to ensure the safety of the wings, such as the wing spars. If the "snap" debater feels guaranteed to lose then they might return a maximally-coarse resolution map. Alternatively, if the coarseness incentive is small and the snap debater thinks the safe debater might mess up then maybe the snap debater returns a resolution map that shows the snapping behavior as dramatically as possible, maybe by using high resolution around the weak wing roots and low resolution around the reinforcing wing spar. Thus, you can expect to end up running a simulation that focuses your computational resources on the wing spars and the wing roots and whatever other bits of the airframe are critical to answering your question while deprioritizing everything else. The game result tells you what's important even if you didn't know a priori.
The Framework (Roughly)
Okay, let's make everything we just did abstract. Suppose is a preordered set of world models and is an evaluation map that takes in a world model and decides whether or not it has some fixed property of interest. In our previous example, our set of resolution maps was , our idea of refinement was , and our simulation software was . If happens to be a directed set (any two world models have a common upper bound, as above) then we can view as a net into equipped with the discrete topology. Note that in our resolution map example we were simply asking whether the net defined by the simulation software converged to or ! We will take net convergence to be our question of interest in the general case.
Let's also assume that we have access to a pool of agents that respond to incentives we provide. Then we can answer a few different questions with a few different game setups:
- Suppose we assume that is directed and we want to know whether converges to 0, converges to , or doesn't converge. We construct the following game: one agent provides us with and . Another agent then provides us with . If and then the second agent wins, otherwise the first agent wins. Intuitively, the first agent is incentivized to convince us that the net converges and the second debater is incentivized to convince us that the net does not converge. If both agents play optimally then tells us that the net converges to , tells us that the net converges to , and tells us that the net does not converge.
- Let's relax the assumption that is a directed set. We now want to know for which we have . We can duplicate the previous game for each value of : one agent points to a for , a second agent points to a corresponding , a third agent points to a for , a fourth agent points to another corresponding . You can probably combine the first and fourth agents and combine the second and third agents to get a single 0-advocate and a single 1-advocate.
We may also face computational constraints in running simulations. Suppose there's an efficiently-computable function which estimates how much it will cost to simulate any given world model. Then we can answer some more questions with games:
- If we're willing to assume for some particular that the convergence of our net is exhibited by some with , what's the maximum cost possibly needed to determine the convergence behavior?
- Conversely, if we're handed a budget , what's the maximum so that if our convergence behavior is exhibited by a with then we'll be able to determine this convergence behavior?
What Can This Framework Handle?
Here are a few situations:
- We can reason about real-world physical simulations as discussed above.
- Suppose we have some kind of probabilistic graphical model (Bayesian network, factor graph, etc.), potentially with infinitely many nodes. Suppose we're interested in some particular binary node and we want to know whether it's with probability greater than or less than when we condition on the values of all the other nodes (let's assume that the true conditional probability doesn't happen to equal ). We can determine the values of finitely many other nodes but it's an expensive process and we'd like to check only what we need. In this setup, world models are subsets of nodes we can reveal, one world model refines another if it contains a superset of the nodes of the other, our preorder gives us a directed set because we can take unions of sets of nodes, and the evaluation map is whatever conditionalization software we have.
- In a more theoretical-computer-science-friendly setting, suppose we have a function and a target input . We want to compute but doing so is slow. Instead, we construct a function where . Ideally, computing is fast if the input has many "" characters. We have so we focus on finding . Again, world models are subsets of indices which we reveal, the ordering is based on the subset relation, the ordering gives us a directed set because we can take unions of sets of indices, and the evaluation map is given by . I believe this kind of setup has some analogies in the explainable AI literature.
Conventional AI Safety via Debate
Something I did not include in the previous section is anyone else's formulation of AI Safety via Debate. I feel bad calling topological debate "debate" at all because qualitatively it's very different from what people usually mean by AI Safety via Debate. Topological debate focuses on the scope of what should be computed, conventional debate makes more sense with respect to some fixed but intractable computation. Topological debate realizes its full power after a constant number of moves, while conventional debate increases in power as we allow more rounds.
In fact, I think it's an interesting question whether we can combine topological debate with conventional debate: we can run topological debate to select a computation to perform and then run conventional debate to estimate the value of that computation.
Turing Machine Version
So far we've had to specify two objects: a directed set of world models and an evaluation function. Suppose our evaluation function is specified by some computer program. For any given world model we can hard-code that world model into the code of the evaluation function to get a new computer program which accepts no input and returns the evaluation of our world model. We can thus turn our directed set of world models into a directed set of computations (let's say halting Turing Machines for simplicity).
We get two benefits as a result:
- We can naturally handle the generalization to multiple evaluation functions. For example, maybe we have access to lots of simulation programs, some of which we trust more than others. Suppose our preferences over simulation programs form a preorder. Then there's a natural way to define the product preorder from our preorder of world models and our preorder of simulation programs. This product can be interpreted as a preorder of Turing Machines. Likewise, if our world models and simulation programs both form directed sets then their product will be another directed set.
- We no longer need to specify our evaluation function since now there's a canonical choice: if a machine accepts then we map it to , if a machine rejects then we map it to . Similarly, if we want to reason about cost functions then again there's a natural choice: the number of steps needed to halt.
Limitations
Criticisms of topological debate include but are not limited to:
- ... yeah, where exactly are we supposed to get those from?
- Using topological debate on a given problem instance requires either having simulation programs and ways of comparing world models and whatnot in place beforehand or some other mechanism for determining those on the fly. The Guaranteed Safe AI agenda seems focused on creating at least some kind of infrastructure like this so I view topological debate as piggybacking off of that work.
- What do you do when there's a difficulty asymmetry between finding a world model that maps to versus finding a world model that maps to ? What if the agents are computationally bounded?
- I don't know in general. For example, maybe an attacker puts a backdoor in a proposal and the debater arguing that the proposal is unsafe is unable to locate the backdoor. However, maybe the debater can show that they wouldn't be able to locate a backdoor even if it existed by constructing another proposal with another backdoor that the original proposer can't find the flaw in.
- Conventional AI Safety via Debate of course gets much more interesting in the computationally bounded case so I expect a similar phenomenon to happen here. To me this is the most interesting theoretical question about topological debate.
- Why should we trust the debaters to follow their rewards?
- Yeah, solving this problem in general feels somewhat alignment-complete. With that said, I see a few encouraging properties about this setup:
- Topological debate is very friendly to "snitching." For example, imagine we ask 50 agents to provide a world model whose refinements all map to and another 50 agents to provide a world model whose refinements all map to . Suppose the net converges to but the agents have some extraneous incentive for us to believe that the answer is . Even if 49 of the agents tasked with arguing for provide intentionally bad responses, a single agent loyal to their side can provide a world model which none of the other agents can refine to conclude .
- As with conventional AI Safety via Debate, we're not asking these AI models to learn human values perfectly, we're asking them to stick to their assigned side. I personally expect models will somewhat reliably do this.
- Yeah, solving this problem in general feels somewhat alignment-complete. With that said, I see a few encouraging properties about this setup:
5 comments
Comments sorted by top scores.
comment by Charlie Steiner · 2025-01-17T09:27:07.517Z · LW(p) · GW(p)
Fun post, even though I don't expect debate of either form to see much use (because resolving tough real world questions offers too many chances for the equivalent of the plane simulation to have fatal flaws).
Replies from: lunatic_at_large↑ comment by lunatic_at_large · 2025-01-17T11:53:08.188Z · LW(p) · GW(p)
Thank you! If I may ask, what kind of fatal flaws do you expect for real-world simulations? Underspecified / ill-defined questions, buggy simulation software, multiple simulation programs giving irreconcilably conflicting answers in practice, etc.? I ask because I think that in some situations it's reasonable to imagine the AI debaters providing the simulation software themselves if they can formally verify its accuracy, but that would struggle against e.g. underspecified questions.
Also, is there some prototypical example of a "tough real world question" you have in mind? I will gladly concede that not all questions naturally fit into this framework. I was primarily inspired by physical security questions like biological attacks or backdoors in mechanical hardware.
Replies from: Charlie Steiner↑ comment by Charlie Steiner · 2025-01-17T17:40:40.583Z · LW(p) · GW(p)
For topological debate that's about two agents picking settings for simulation/computation, where those settings have a partial order that lets you take the "strictest" combination, a big class of fatal flaw would be if you don't actually have the partial order you think you have within the practical range of the settings - i.e. if some settings you thought were more accurate/strict are actually systematically less accurate.
In the 1D plane example, this would be if some specific length scales (e.g. exact powers of 1000) cause simulation error, but as long as they're rare, this is pretty easy to defend against.
In the fine-grained plane example, though, there's a lot more room for fine-grained patterns in which parts of the plane get modeled at which length scale to start having nonlinear effects. If the agents are not allowed to bid "maximum resolution across the entire plane," and instead are forced to allocate resources cleverly, then maybe you have a problem. But hopefully the truth is still advantaged, because the false player has to rely on fairly specific correlations, and the true player can maybe bid a bunch of noise that disrupts almost all of them.
(This makes possible a somewhat funny scene, where the operator expected the true player's bid to look "normal," and then goes to check the bids and both look like alien noise patterns.)
An egregious case would be where it's harder to disrupt patterns injected during bids - e.g. if the players' bids are 'sparse' / have finite support and might not overlap. Then the notion of the true player just needing to disrupt the false player seems a lot more unlikely, and both players might get pushed into playing very similar strategies that take every advantage of the dynamics of the simulator in order to control the answer in an unintended way.
I guess for a lot of "tough real world questions," the difficulty of making a super-accurate simulator (one you even hope converges to the right answer) torpedoes the attempt before we have to start worrying about this kind of 'fatal flaw'. But anything involving biology, human judgment, or too much computer code seems tough. "Does this gene therapy work?" might be something you could at least imagine a simulator for that still seems like it gives lots of opportunity for the false player.
Replies from: lunatic_at_large, lunatic_at_large↑ comment by lunatic_at_large · 2025-01-19T15:33:06.112Z · LW(p) · GW(p)
These are all excellent points! I agree that these could be serious obstacles in practice. I do think that there are some counter-measures in practice, though.
I think the easiest to address is the occasional random failure, e.g. your "giving the wrong answer on exact powers of 1000" example. I would probably try to address this issue by looking at stochastic models of computation, e.g. probabilistic Turing machines. You'd need to accommodate stochastic simulations anyway because so many techniques in practice use sampling. I think you can handle stochastic evaluation maps in a similar fashion to the deterministic case but everything gets a bit more annoying (e.g. you likely need to include an incentive to point to simple world models if you want the game to have any equilibria at all). Anyways, if you've figured out topological debate in the stochastic case, then you can reduce from the occasional-errors problem to the stochastic problem as follows: suppose is a directed set of world models and is some simulation software. Define a stochastic program which takes in a world model , randomly samples a world model according to some reasonably-spread-out distribution, and return . In the 1D plane case, for example, you could take in a given resolution, divide it by a uniformly random real number in , and then run the simulation at that new resolution. If your errors are sufficiently rare then your stochastic topological debate setup should handle things from here.
Somewhat more serious is the case where "it's harder to disrupt patterns injected during bids." Mathematically I interpret this statement as the existence of a world model which evaluates to the wrong answer such that you have to take a vastly more computationally intensive refinement to get the correct answer. I think it's reasonable to detect when this problem is occurring but preventing it seems hard: you'd basically need to create a better simulation program which doesn't suffer from the same issue. For some problems that could be a tall order without assistance but if your AI agents are submitting the programs themselves subject to your approval then maybe it's surmountable.
What I find the most serious and most interesting, though, is the case where your simulation software simply might not converge to the truth. To expand on your nonlinear effects example: suppose our resolution map can specify dimensions of individual grid cells. Suppose that our simulation software has a glitch where, if you alternate the sizes of grid cells along some direction, the simulation gets tricked into thinking the material has a different stiffness or something. This is a kind of glitch which both sides can exploit and the net probably won't converge to anything.
I find this problem interesting because it attacks one of the core vulnerabilities that I think debate problems struggle with: grounding in reality. You can't really design a system to "return the correct answer" without somehow specifying what makes an answer correct. I tried to ground topological debate in this pre-existing ordering on computations that gets handed to us and which is taken to be a canonical characterization of the problem we want to solve. In practice, though, that's really just kicking the can down the road: any user would have to come up with a simulation program or method of comparing simulation programs which encapsulates their question of interest. That's not an easy task.
Still, I don't think we need to give up so easily. Maybe we don't ground ourselves by assuming that the user has a simulation program but instead ground ourselves by assuming that the user can check whether a simulation program or comparison between simulation programs is valid. For example, suppose we're in the alternating-grid-cell-sizes example. Intuitively the correct debater should be able to isolate an extreme example and go to the human and say "hey, this behavior is ridiculous, your software is clearly broken here!" I will think about what a mathematical model of this setup might look like. Of course, we just kicked the can down the road, but I think that there should be some perturbation of these ideas which is practical and robust.
↑ comment by lunatic_at_large · 2025-01-19T17:08:13.312Z · LW(p) · GW(p)
Maybe I should also expand on what the "AI agents are submitting the programs themselves subject to your approval" scenario could look like. When I talk about a preorder on Turing Machines (or some subset of Turing Machines), you don't have to specify this preorder up front. You just have to be able to evaluate it and the debaters have to be able to guess how it will evaluate.
If you already have a specific simulation program in mind then you can define as follows: if you're handed two programs which are exact copies of your simulation software using different hard-coded world models then you consult your ordering on world models, if one submission is even a single character different from your intended program then it's automatically less, if both programs differ from your program then you decide arbitrarily. What's nice about the "ordering on computations" perspective is that it naturally generalizes to situations where you don't follow this construction.
What could happen if we don't supply our own simulation program via this construction? In the planes example, maybe the "snap" debater hands you a 50,000-line simulation program with a bug so that if you're crafty with your grid sizes then it'll get confused about the material properties and give the wrong answer. Then the "safe" debater might hand you a 200,000-line simulation program which avoids / patches the bug so that the crafty grid sizes now give the correct answer. Of course, there's nothing stopping the "safe" debater from having half of those lines be comments containing a Lean proof using super annoying numerical PDE bounds or whatever to prove that the 200,000-line program avoids the same kind of bug as the 50,000-line program.
When you think about it that way, maybe it's reasonable to give the "it'll snap" debater a chance to respond to the "it's safe" debater's comments. Now maybe we change the type of from being a subset of (Turing Machines) x (Turing Machines) to being a subset of (Turing Machines) x (Turing Machines) x (Justifications from safe debater) x (Justifications from snap debater). In this manner deciding how you want to behave can become a computational problem in its own right.