Massive Activations and why <bos> is important in Tokenized SAE Unigrams
post by Louka Ewington-Pitsos (louka-ewington-pitsos) · 2024-09-05T02:19:25.592Z · LW · GW · 0 commentsContents
How to create "Unigrams" Massive Activations Conclusion None No comments
This article is a footnote to the (excellent) Tokenized SAEs [LW · GW]. To briefly summarize: the authors (Thomas Dooms and Daniel Wilhelm) start by proposing the idea of a token "unigram".
Let Ut be the unigram for a specific token t. Conceptually there is a unique Ut for each layer Mi in each model M, such that Ut(M, i) are the activations coming out of Mi when M is fed just t by itself. More abstractly Ut are the activations which correspond to just t taken in isolation, un-bound by any particular context.
The authors then demonstrated that the activation at position j in any token sequence will have a high cosine similarity to Utj(M, i), where tj is the token at the same position. The dotted lines in the diagram below (taken from Tokenized SAEs [LW · GW]) show the cosine similarity of the activations at position j with Utj(M, i) across many i and M.
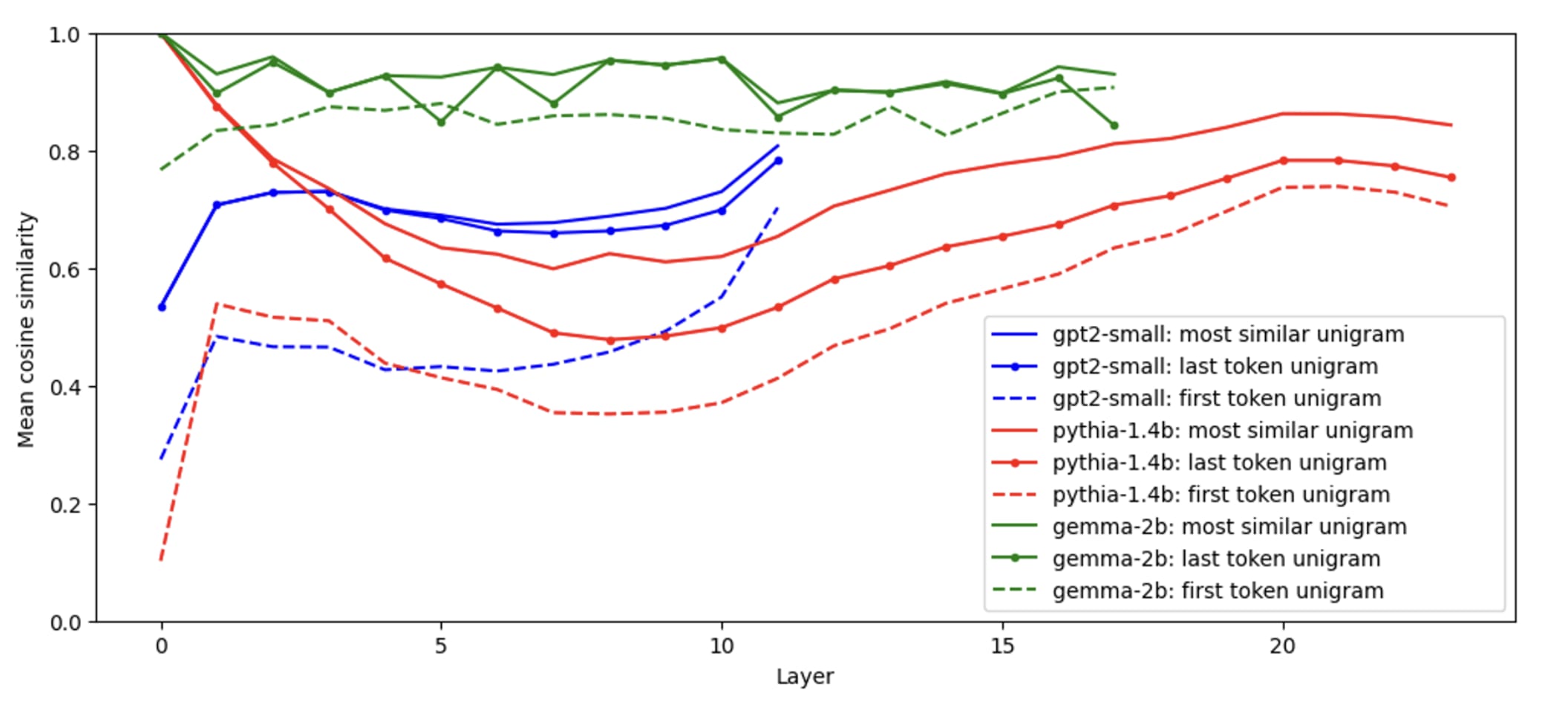
The authors go on to demonstrate that this fact has serious implications for training SAEs. In particular it seems that SAEs learn to memorize these token unigrams and that if we add these unigrams in explicitly during training we get a significant reduction in loss.
In this article we will investigate one specific methodology for generating unigrams ([<bos>, t]) and provide some theoretical and empirical justification for its use.
How to create "Unigrams"
How exactly do we generate the activations which best represent t by itself though?
The default mechanism used by the authors to generate Ut(M, i) is to (1) create the token sequence [<bos>, t] where <bos> is the "beginning of sentence" token for M (2) pass the 2-token sequence into M (3) take the activations from layer i at the last position in the sequence. These final activations are Ut(M, i).
The authors note that this method works better than simply passing in a 1-token sequence [t], and that this is related to the instability which is known to occur when we feed Language Models sequences with no <bos> token.
We support this claim here by showing that across multiple models [<bos>, t] is a far more effective unigram strategy than [t], insofar as it leads to greater cosine similarity across a dataset of of 50 1024-token sequences taken from NeelNanda/pile-10k.
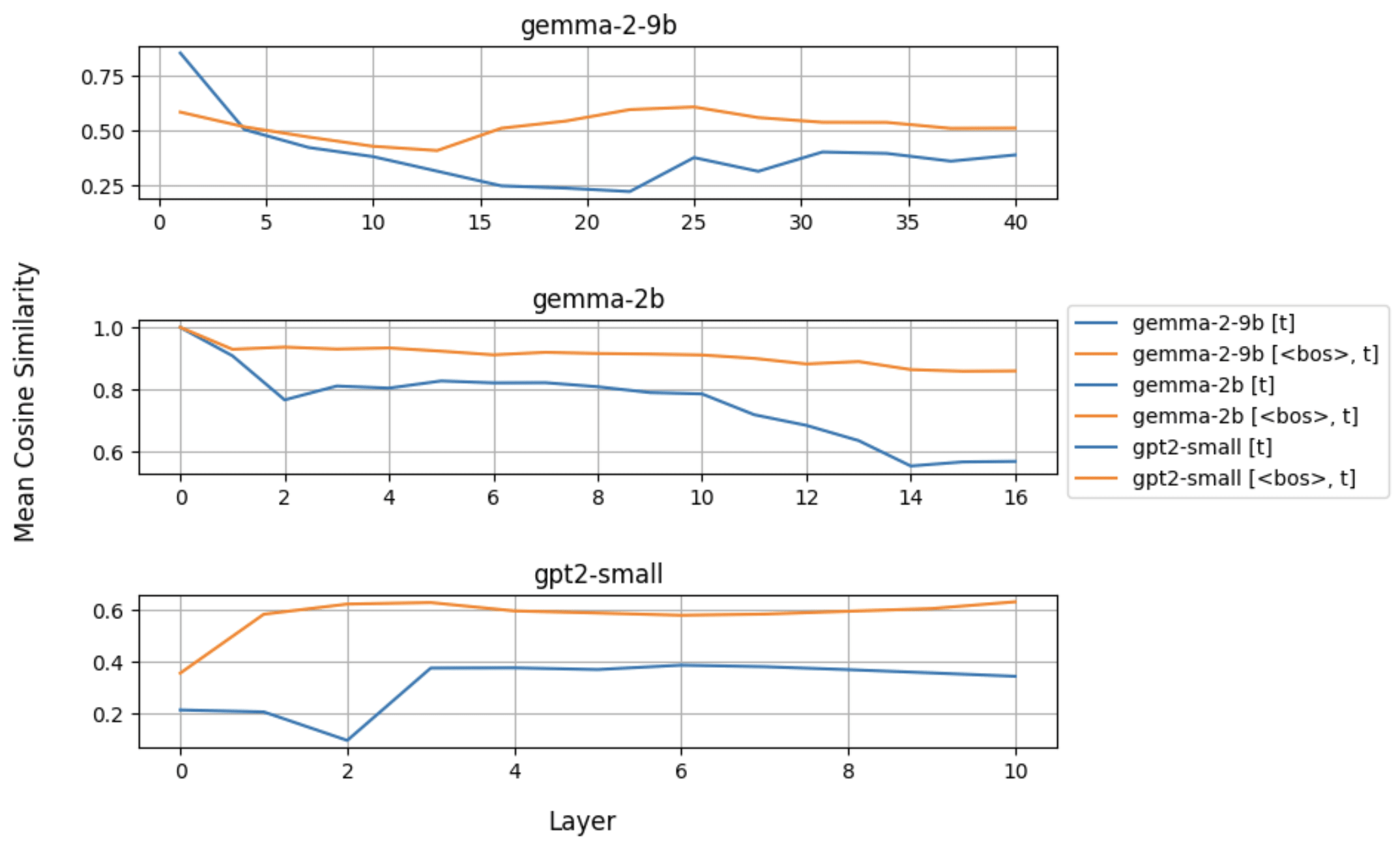
Massive Activations
The superior performance of [<bos>, t] is likely linked to the independently observed phenomenon that activations taken from the 0th position in transformer language model sequences are often a bit strange.
For instance, the authors of Massive Activations in Large Language Models observe that so called "massive activations" (values > 1e-3 in certain specific activation features) are apt to appear early on in activation sequences across a range of models. In particular they tend to present especially at position 0 or in positions occupied by tokens with weak semantics like ".", "<bos>" or ",". Activations at positions where massive activations are present were observed to have almost no semantic content and instead seem to act as an internal bias term.
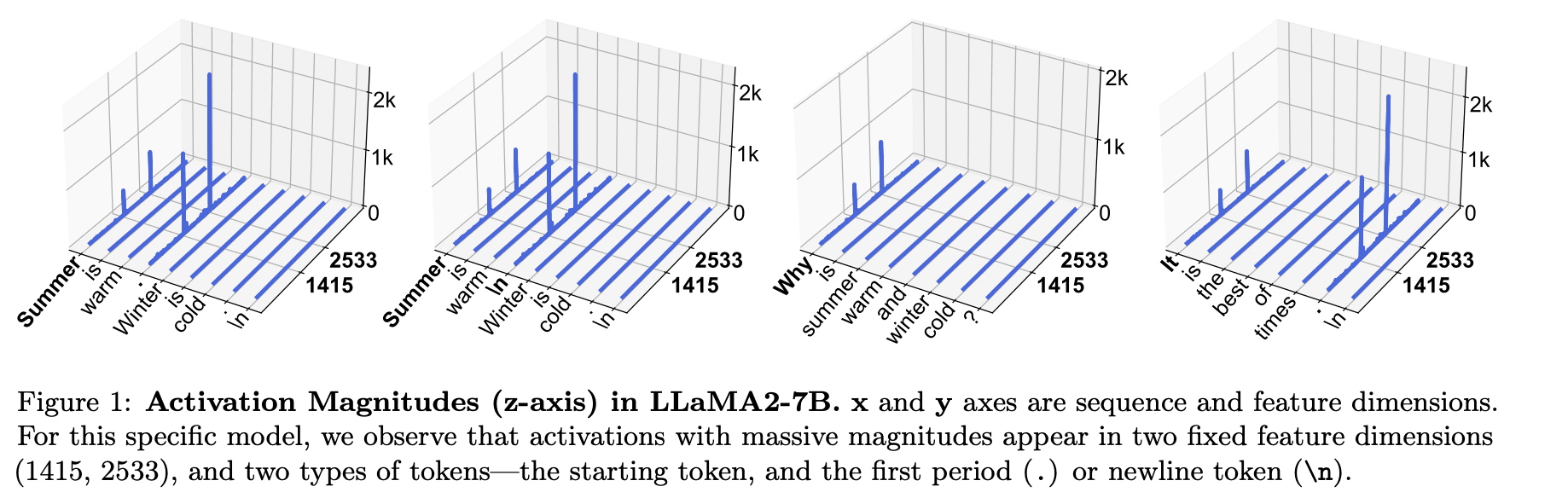
Similar observations were made by the authors of IntactKV: Improving Large Language Model Quantization by Keeping Pivot Tokens Intact who refer to these anomalies as "Pivot Tokens".
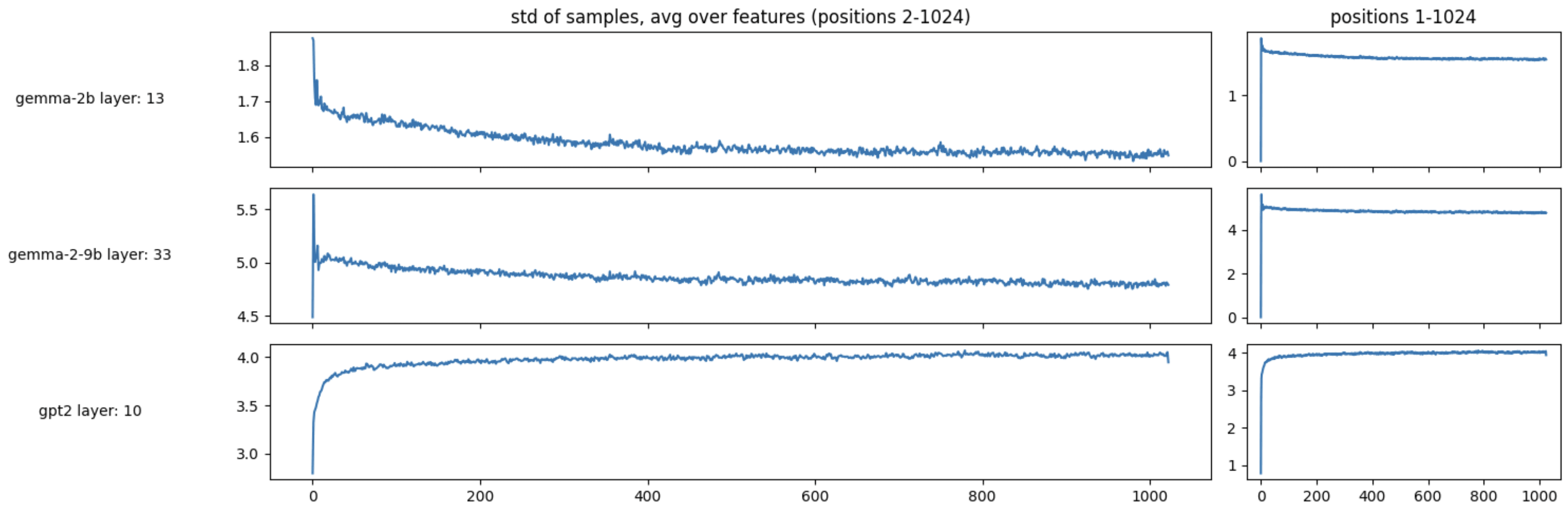
To support these observations we plot the feature-wise standard deviation at each token position averaged over the first 1024 sequences containing >5,000 characters taken from NeelNanada/pile-10k for specific layers in 3 models.
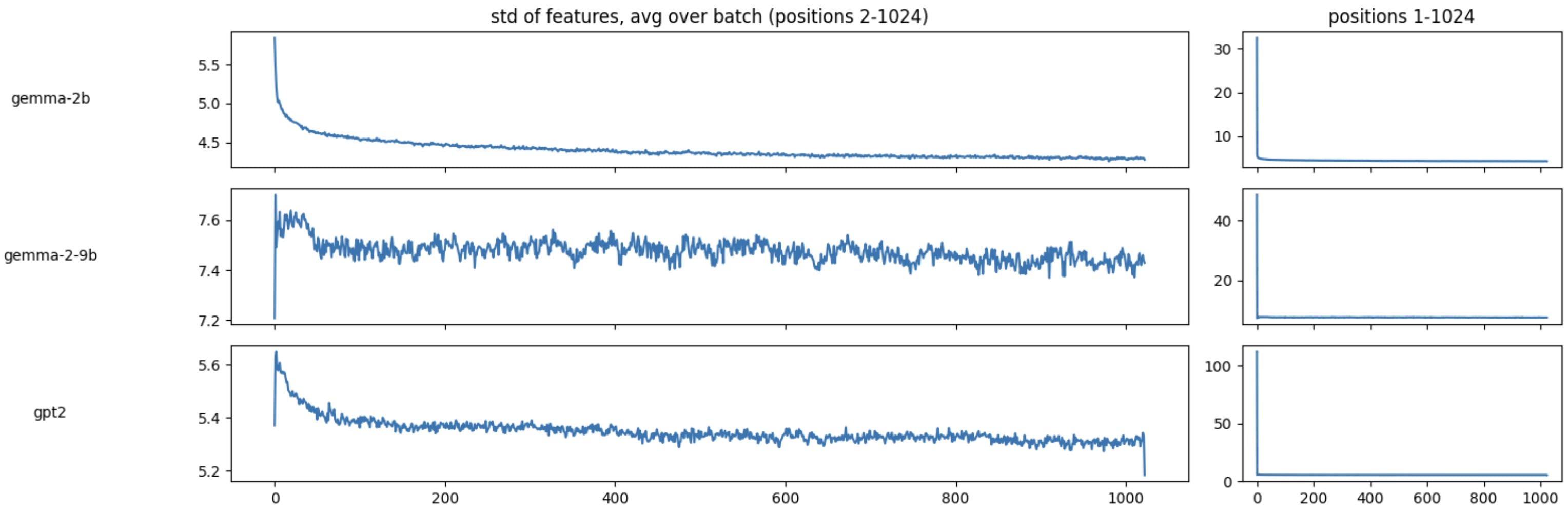
It seems position 0 has an unusually high variance between it's features, as would be expected if a small number of those features had massive values. At the same time though, we see that position 0 has very low standard deviation across samples.
Similarly when we plot the raw values of all the features in the first 10 activations in each sequence the activations in position 0 (and to a lesser extent 1) appear to be outliers.
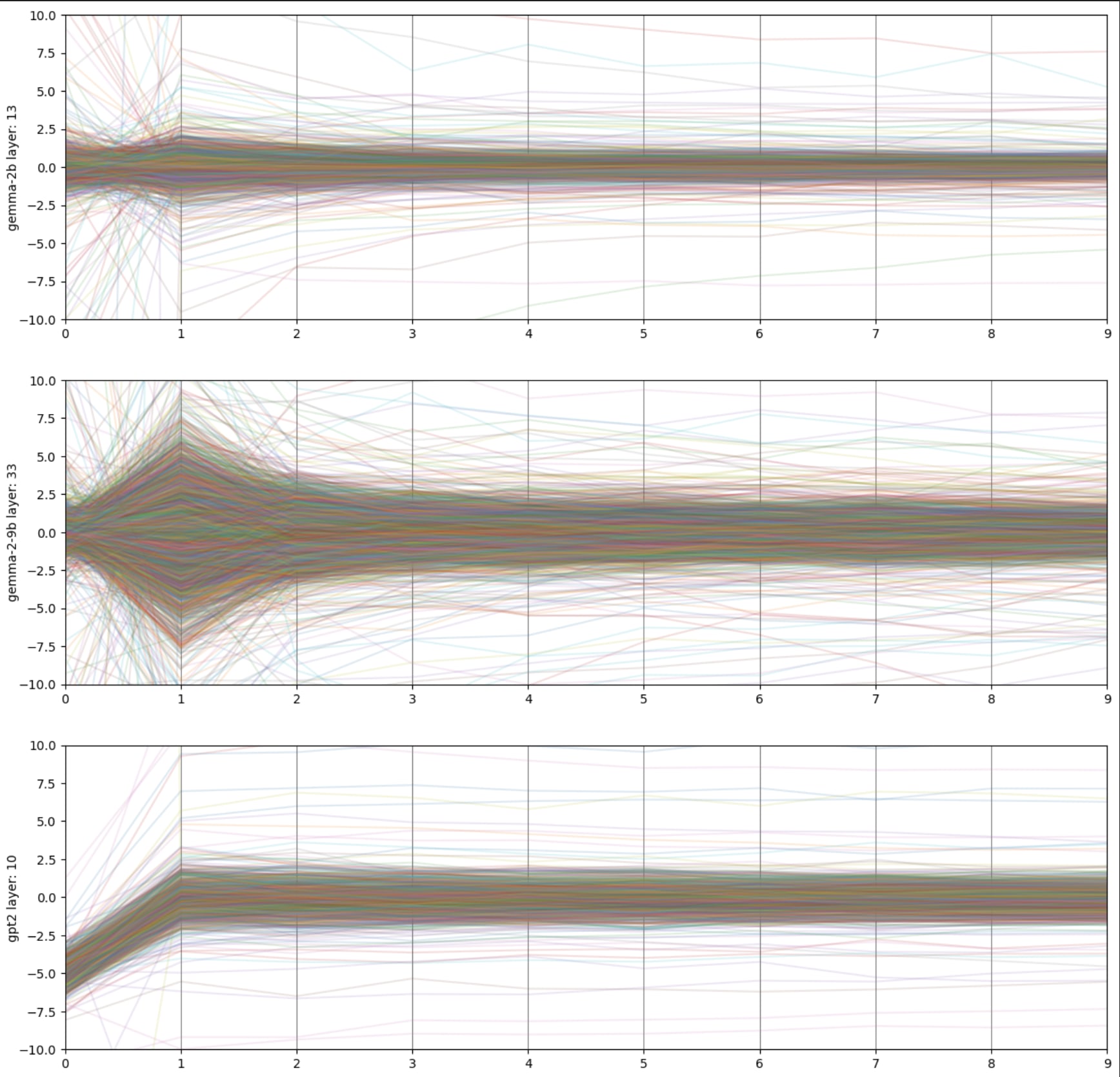
This provides a plausible theoretical explanation for why [t] performs so poorly: in many models the usual semantics of the token in in position 0 are overridden, and dominated by anomalous, largely semantically invariant activations which usually occupy that position. These plots can be replicated using this colab notebook.
It also gives a concrete reason as to why [<bos>, t] performs better: we are now taking activations from the 2nd position, which seems to contain much more normal activations. To support this idea we show that swapping out <bos> with other similar, or even randomly selected tokens gives rise to much higher cosine similarity scores compared to [t].
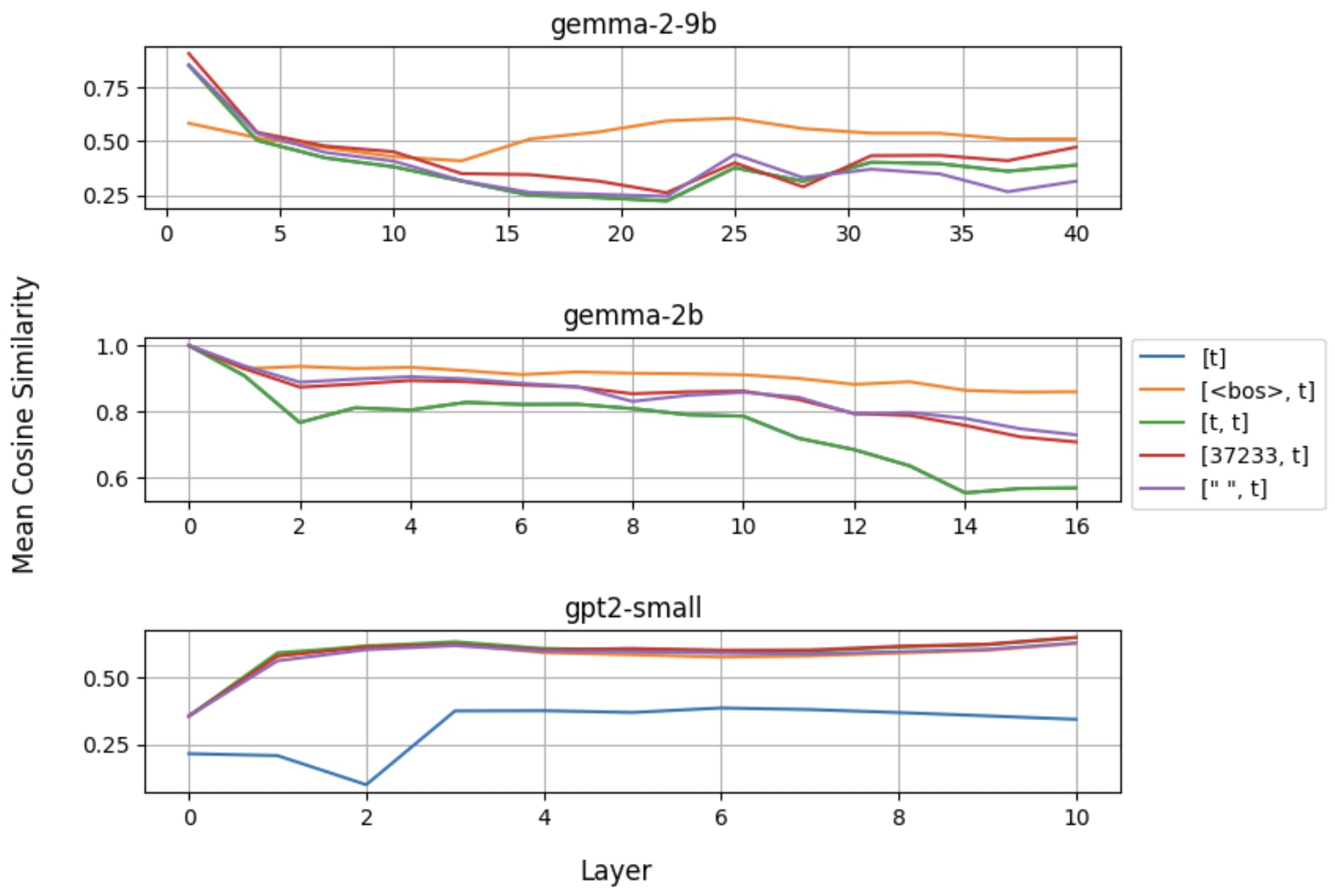
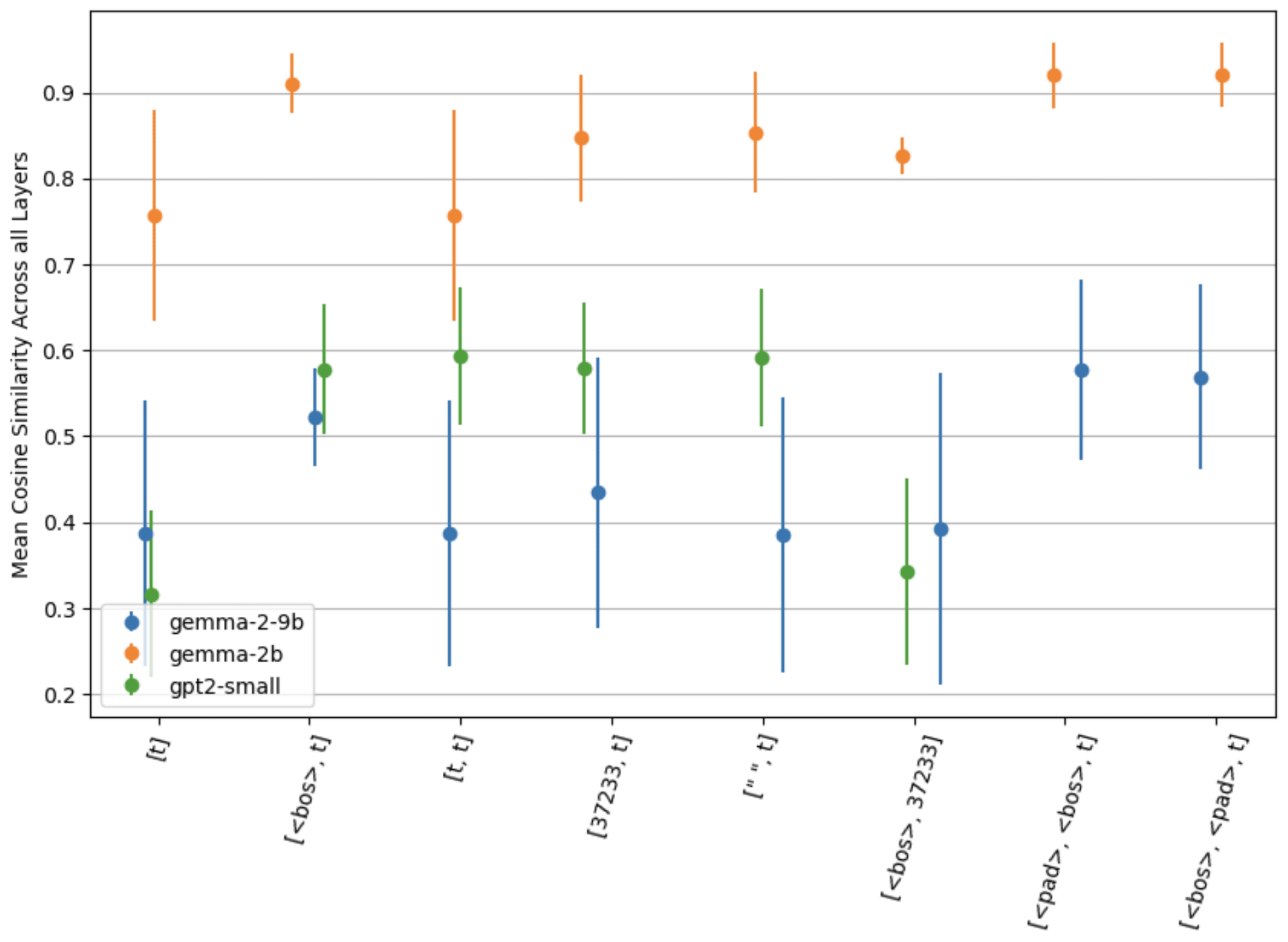
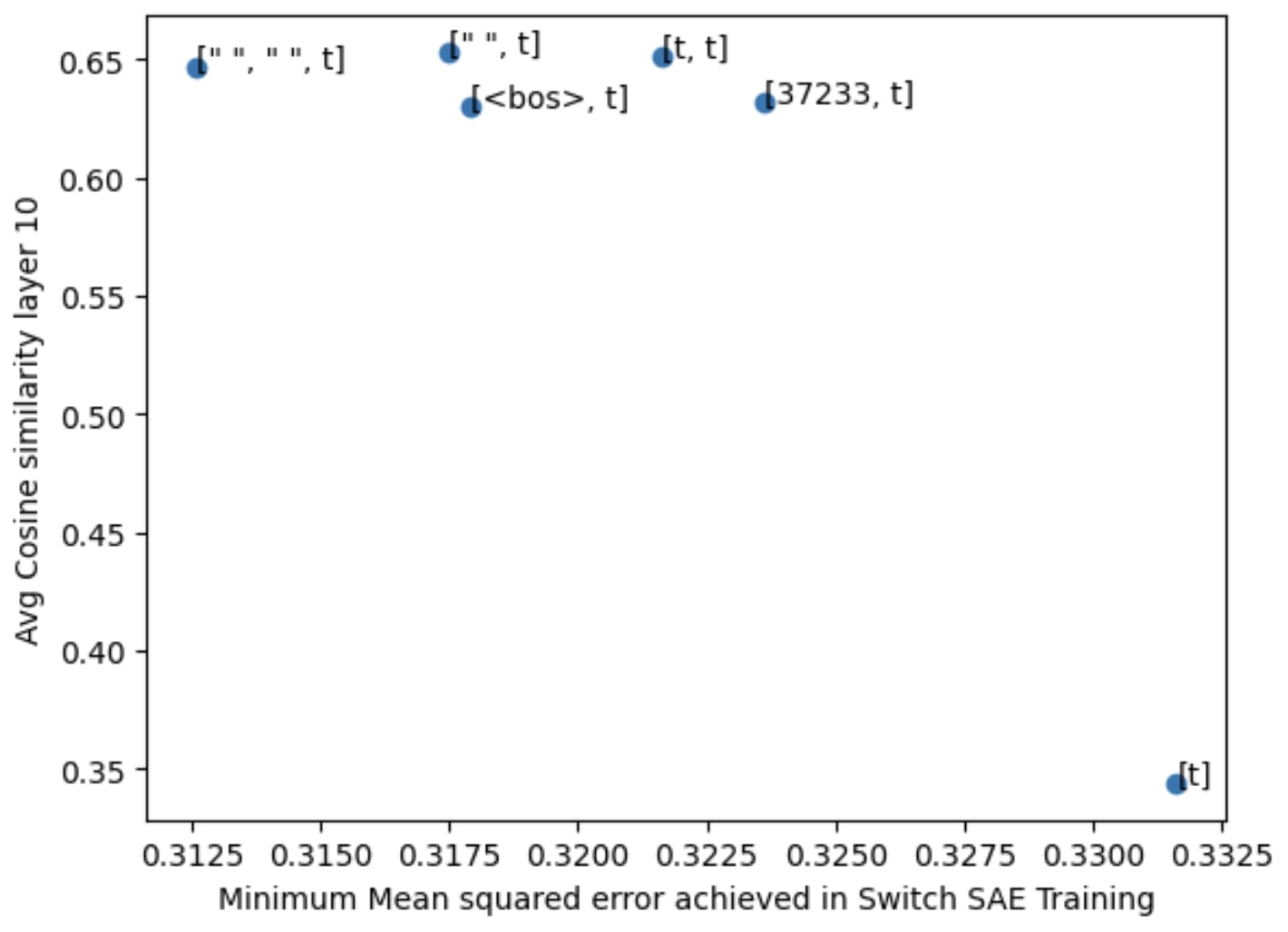
For Gemma models, strategies involving <bos> seem to consistently outperform other strategies, but for all models, all strategies involving 2 or more tokens consistently out-perform [t], including a controlling strategy [<bos>, 37233] which does not include [t] at all.
Finally we show that the choice of unigram strategy can have significant impact on Tokenized SAE training performance by training GPT2 Tokenized SAEs using 6 different unigram strategies and recording the minimum reconstruction MSE. We can see that 2-token strategies all outperform [t].
Conclusion
We hope to have given a theoretical justification for why the [<bos>, t] strategy for creating unigrams outperforms [t], i.e. that activations drawn from the 0th position are already known to be largely semantics-invariant and also very dissimilar to activations from other positions.
0 comments
Comments sorted by top scores.